









环境描述
操作系统:windows10
开发语言:python3.7.6
深度学习后端:tensorflow2.1.0
深度学习前端:keras(tensorflow内嵌的keras)
显卡:GTX1050TI(安装cuda)
一、准备数据
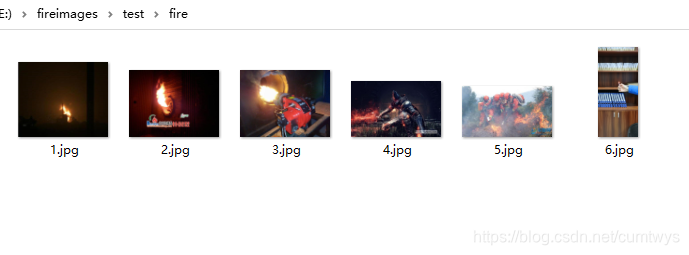
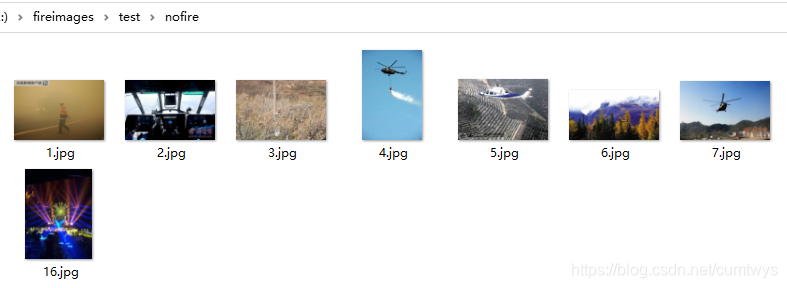
从百度或谷歌上搜火、火焰、火灾等图片,建立两个文件夹(因为是二分类问题,有火or无火)fire和nofire。效果如下:
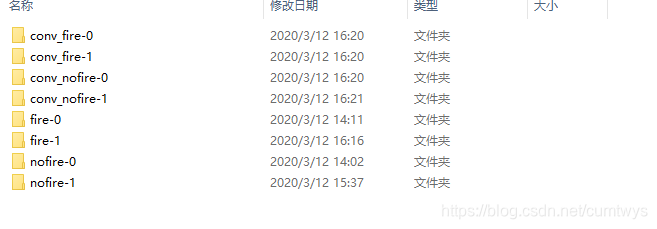
截图的文件夹分为conv和不带conv的文件夹,其实是火和无火的图片是经过多次添加的,因为训练数据的过程中会发现某些图片识别效果不是很好,所以得在训练样本中增加特定的图片(比如初次训练的时候没有增加枯草的图片进行训练,然后验证的时候会发现训练结果会误把枯草识别成火,因为数据应该是多次修正和新增的),conv文件夹其实就是将不带conv文件夹内的图片进行统一尺寸和格式(因为网上下载的数据基本上不可能统一尺寸,为了使用深度学习工具进行训练和张量运算,因此要统一尺寸)。
如下图,火的数据:
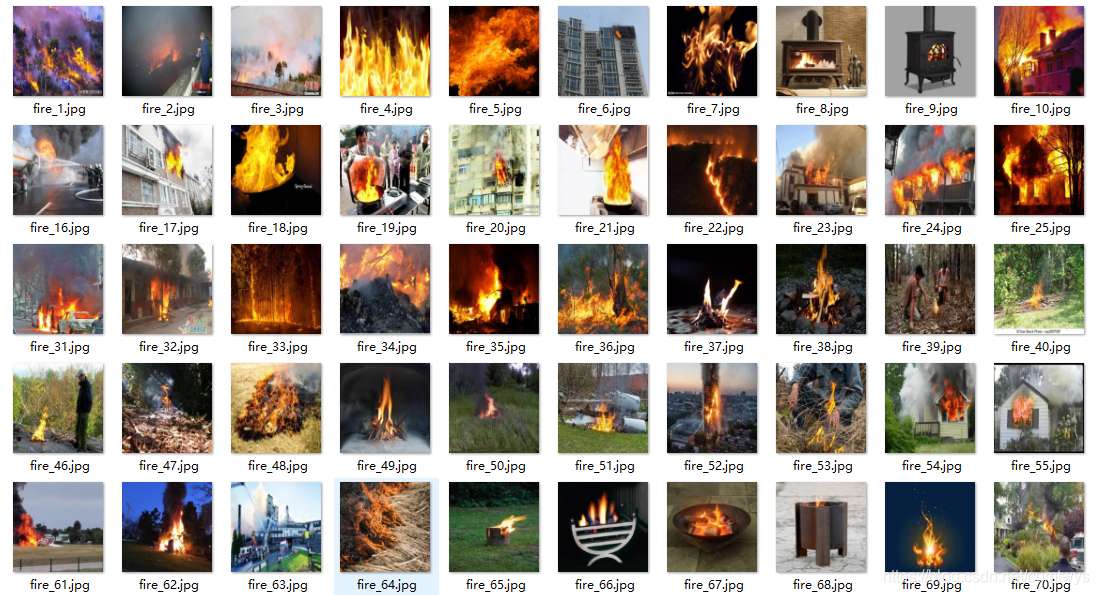
无火的数据如下:

将图片统一尺寸代码如下(需要自行修改图片路径):
from PIL import Image
import os.path
import glob
def convertjpg(jpgfile,outdir,width=300,height=300):
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(jpgfile)))
except Exception as e:
print(e)
for jpgfile in glob.glob('E:/fireimages/sources/nofire-1/*.jpg'):
convertjpg(jpgfile,'E:/fireimages/sources/conv_nofire-1')二、调整数据
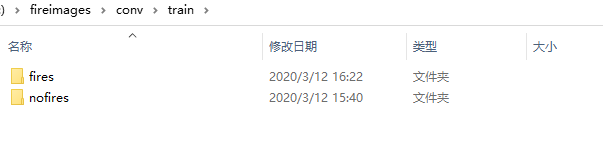
新建train和val两个文件夹,将统一尺寸后的图片基本上按照5:1的比例分配到train和val两个文件夹内,train里面包含fire和nofire两个文件夹,val同理,如下图:

三、使用googlenet(inceptionV3模型进行训练)
上代码,自行修改路径:
from tensorflow import keras
from keras.applications.inception_v3 import InceptionV3
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras import layers
import os
from keras import optimizers
from keras.utils import to_categorical
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
from keras.applications.inception_v3 import InceptionV3,preprocess_input
from keras.layers import GlobalAveragePooling2D,Dense
from keras.models import Model
from keras.utils.vis_utils import plot_model
from keras.optimizers import Adagrad
# 动物数据预处理
train_dir = 'E:/fireimages/conv1/train'
val_dir = 'E:/fireimages/conv1/val'
# 不使用数据增强
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
# 使用数据增强
# train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=30., width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
# val_datagen = ImageDataGenerator(rescale=1./255, rotation_range=30., width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
# 使用迭代器生成图片张量
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(300, 300), batch_size=10, class_mode='binary')
val_generator = train_datagen.flow_from_directory(val_dir, target_size=(300, 300), batch_size=10, class_mode='binary')
# resnet_base = InceptionV3(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 构建基础模型
base_model = InceptionV3(weights='imagenet',include_top=False, input_shape=(300, 300, 3))
# 增加新的输出层
x = base_model.output
# GlobalAveragePooling2D 将 MxNxC 的张量转换成 1xC 张量,C是通道数
x = GlobalAveragePooling2D()(x)
x = Dense(512,activation='relu')(x)
predictions = Dense(1,activation='sigmoid')(x)
model = Model(inputs=base_model.input,outputs=predictions)
'''
这里的base_model和model里面的iv3都指向同一个地址
'''
def setup_to_transfer_learning(model,base_model):
for layer in base_model.layers:
layer.trainable = False
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])
def setup_to_fine_tune(model,base_model):
GAP_LAYER = 17
for layer in base_model.layers[:GAP_LAYER+1]:
layer.trainable = False
for layer in base_model.layers[GAP_LAYER+1:]:
layer.trainable = True
model.compile(optimizer=Adagrad(lr=0.0001),loss='binary_crossentropy',metrics=['accuracy'])
setup_to_transfer_learning(model,base_model)
history_tl = model.fit_generator(generator=train_generator,
epochs=5,
validation_data=val_generator,
validation_steps=5,
class_weight='auto'
)
model.save('E:/fireimages/fire-inceptionV3-more21.h5')
setup_to_fine_tune(model,base_model)
history_ft = model.fit_generator(generator=train_generator,
epochs=5,
validation_data=val_generator,
validation_steps=5,
class_weight='auto')
model.save('E:/fireimages/fire-inceptionV3-more22.h5')
四、训练
在vscode内进行训练,结果如下:训练集合验证集效果都还不错。
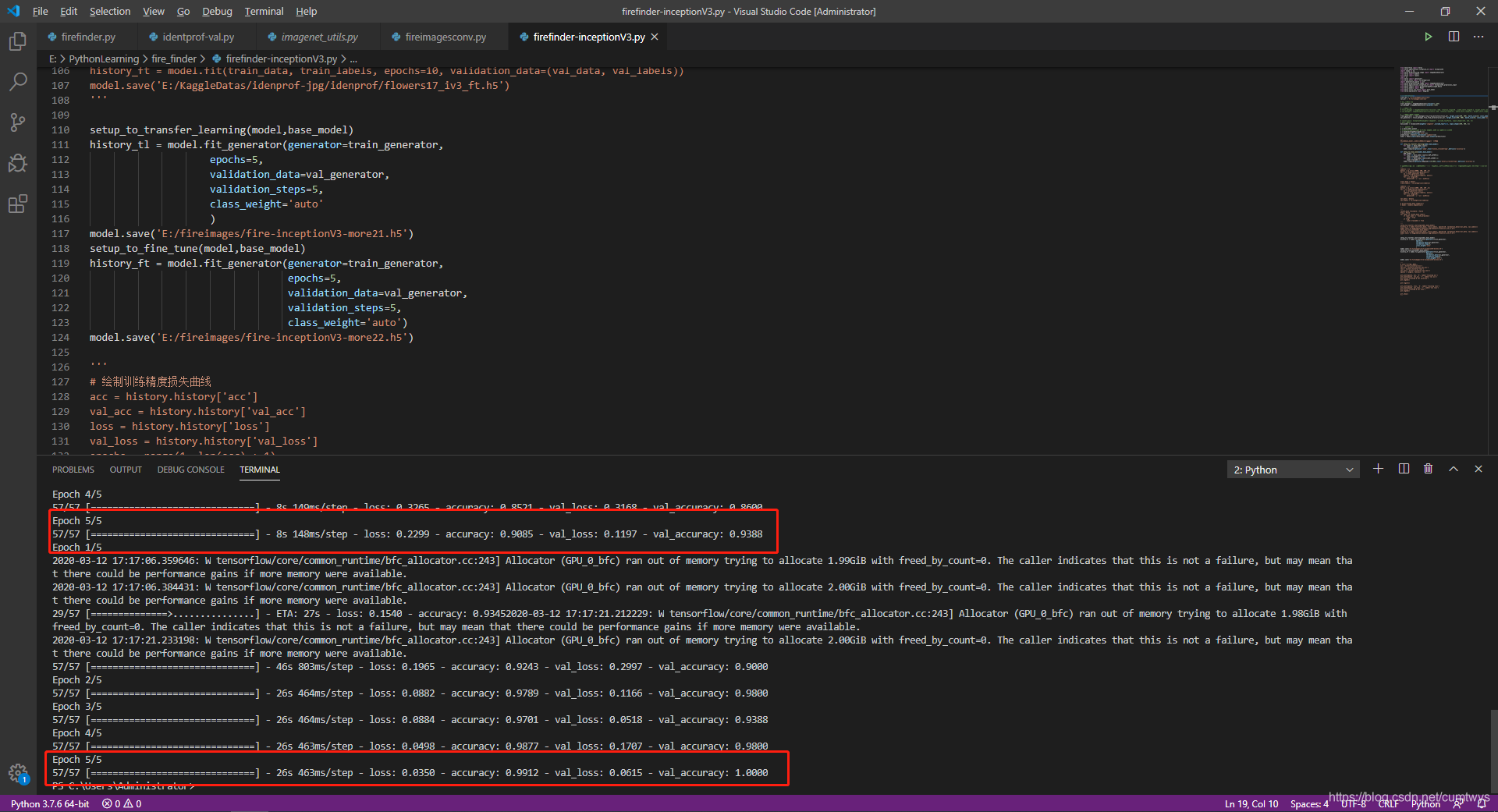
可见最后一轮的验证精度居然达到了惊人的100%。
五、测试数据
上代码:
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras import layers
from keras import optimizers
import matplotlib.pyplot as plt
from keras.applications import VGG16
from tensorflow import keras
from keras import models
import numpy as np
from keras.preprocessing import image
from keras.applications.imagenet_utils import preprocess_input, decode_predictions
import os
import tkinter as tk
from tkinter import filedialog
# model = models.load_model('E:/KaggleDatas/dogvscat/dc.h5')
model = models.load_model('E:/fireimages/fire-inceptionV3-more22.h5')
root = tk.Tk()
root.withdraw()
print('press enter to discern your image.')
print('press e to exit.')
for i in range(1000):
cmd = input('input command.')
if cmd == '':
# 选择文件
path = filedialog.askopenfilename()
img = image.load_img(path)
img = img.resize((300, 300))
# img = img.scale()
x = image.img_to_array(img)
x /= 255
x = np.expand_dims(x, axis=0)
# x = preprocess_input(x, mode='torch')
y = model.predict(x)
# print(y)
j = 0
for data in y[0]:
if data <= 0.3:
print('fire {:.2f}'.format(data))
else:
print('nofire {:.2f}'.format(data))
elif cmd == 'e':
break此处设定了阈值,当概率小于0.3的时候默认为是有火,否则无火,百度随便下载几张和训练验证集不相同的图片进行验证,效果如下:
在VS控制台按下回车选择图片进行验证,效果如下:
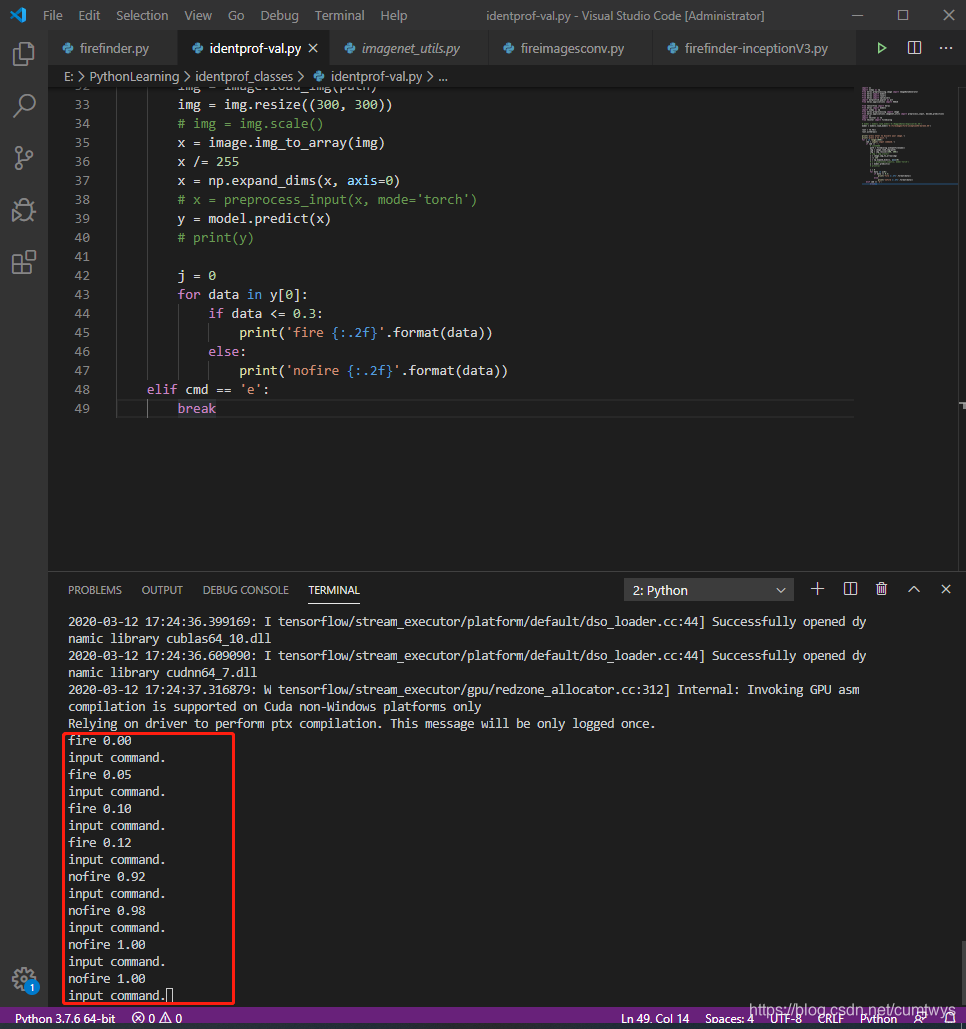
经过测试,发现通过手机拍照的拿着打火机点火的图片未识别出火焰,可能与图片资源有关,因此后续需要继续增加火焰数据集增加手拿打火机点火的照片,然后放到训练集里进行训练,手机拍出来的照片与横竖也有些关系,与照片尺寸也有关系(手机拍出来的尺寸较大)缩放到300*300后会损失不少像素,因此需要继续增强数据集。
六、下一步需要增加视频采集的火焰检测
计划每秒采集两帧图片进行火焰识别,待续……
七、源码下载地址
https://download.csdn.net/download/cumtwys/12638116
源码内包含了用opencv从摄像头拉流截取一帧图像进行火焰识别和分析的功能。
八、火焰训练数据集下载地址如下(无解压密码)
https://download.csdn.net/download/cumtwys/12834601

















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









