





机器学习 训练验证测试
In my previous article, we have discussed about the need to train and test our model and we wrote a code to split the given data into training and test sets.
在上一篇文章中,我们讨论了训练和测试模型的必要性,并编写了代码将给定的数据分为训练和测试集。
Before moving to the validation portion, we need to see what is the need to use validation procedure before performing the testing procedure in the given data set. At times when we are dealing with a huge amount of data there is a certain chance that maybe the data used by our model during learning produced a biased result and in this case as we use the test set to check the accuracy of our model the following 2 cases can arise:
在转到验证部分之前,我们需要了解在给定数据集中执行测试过程之前,需要使用验证过程进行哪些操作。 有时,当我们处理大量数据时,很有可能我们的模型在学习过程中使用的数据会产生有偏差的结果,在这种情况下,由于我们使用测试集来检查模型的准确性,因此以下可能出现2种情况:
Under fitting of the test data
测试数据拟合
Over fitting of the test data
测试数据过度拟合
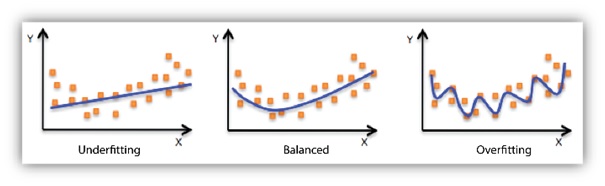
Image source: https://docs.aws.amazon.com/machine-learning/latest/dg/images/mlconcepts_image5.png
图片来源: https : //docs.aws.amazon.com/machine-learning/latest/dg/images/mlconcepts_image5.png
So then how do we deal with such a problem? Well, the answer is pretty simple if we can somehow use a 3rd data set to validate the results obtained from the training set so that we can adjust the various hyperparameters like learning rate and batch values to get a balanced result on the validation set which will, in turn, increase the accuracy of our model in estimating the target values from the test set.
那么,我们该如何处理这个问题呢? 那么,答案很简单,如果我们能够以某种方式使用三档数据集来验证训练组所取得的成果,使我们可以调整各种超参数就像学率和批量值来得到验证集一个平衡的结果,其反过来,将提高我们的模型从测试集中估算目标值的准确性。

Image source: https://rpubs.com/charlydethibault/348566
图片来源: https : //rpubs.com/charlydethibault/348566
Here, you can see that the validation set is nothing but a subset of the training data set that we create. Here do remember that when we create a partition from a dataset. The data present in the datasets are shuffled randomly to remove biased results.
在这里,您可以看到验证集不过是我们创建的训练数据集的子集。 这里要记住,当我们根据数据集创建分区时。 数据集中存在的数据会随机洗牌以消除有偏见的结果。
So, let us write a simple code to create a validation data set in python:
因此,让我们编写一个简单的代码来在python中创建一个验证数据集:
File: headbrain.CSV
文件: headbrain.CSV
Here is the code:
这是代码:
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 1 22:18:11 2018
@author: Raunak Goswami
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#reading the data
"""here the directory of my code and the headbrain.csv
file is same make sure both the files are stored in the same folder
or directory"""
data=pd.read_csv('headbrain.csv')
#this will show the first five records of the whole data
data.head()
#this will create a variable x which has the feature values i.e brain weight
x=data.iloc[:,2:3].values
#this will create a variable y which has the target value i.e brain weight
y=data.iloc[:,3:4].values
#splitting the data into training and test
"""
the following statement written below will split x and y into 2 parts:
1.training variables named x_train and y_train
2.test variables named x_test and y_test
The splitting will be done in the ratio of 1:4 as we have mentioned
the test_size as 1/4 of the total size
"""
from sklearn.cross_validation import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=1/4,random_state=0)
#Here we again split the training data further
##into training and validating sets.
#observe that the size of the validating set is
#1/4 of the training set and not of the whole dataset
from sklearn.cross_validation import train_test_split
x_training,x_validate,y_training,y_validate=train_test_split(x_train,y_train,test_size=1/4,random_state=0)
After running this python code on your Spyder tool provided by the Anaconda distribution just cross check your variable explorer:
在Anaconda发行版提供的Spyder工具上运行此python代码后,只需交叉检查变量浏览器即可:

On the image above you can see that we have split the train variables into training variables and validate variables.
在上图中,您可以看到我们已将训练变量分为训练变量并验证了变量。
So, guys that is it for today hope you liked this article. Have a great day ahead.
所以,今天的家伙们希望您喜欢这篇文章。 祝您有美好的一天。
翻译自: https://www.includehelp.com/ml-ai/validation-before-testing.aspx
机器学习 训练验证测试















 1891
1891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









