






作者 | 生锅 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1906094612185063479
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
Light-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
论文地址:https://arxiv.org/abs/2503.10460
研究背景
研究问题:这篇文章要解决的问题是如何在资源受限的情况下训练长链式思维(Long Chain-of-Thought, COT)模型。具体来说,现有的DeepSeek-R1系列模型由于参数众多(如671亿参数),训练和部署成本高昂,难以在实际应用中部署。因此,本文提出了一种利用公共数据和模型的方法,旨在训练出性能优越且资源消耗较低的长COT模型。
研究难点:该问题的研究难点包括:
数据集的选择和预处理:需要收集和清洗大量的数学问题数据,确保数据的多样性和难度适中。
训练策略的设计:如何有效地利用数据集进行多阶段训练,逐步提升模型的能力。
强化学习的应用:如何在长COT模型上成功应用强化学习,进一步提升模型性能。
相关工作:该问题的研究相关工作有:
DeepSeek-R1系列模型:OpenAI发布的长COT推理模型,参数众多,性能优越,但训练和部署成本高。
其他长COT模型的研究:包括使用不同大小的模型进行复制和优化,但在数学竞赛中的表现仍有待提高。
研究方法
这篇论文提出了Light-R1系列模型,用于解决长COT模型训练的资源受限问题。具体来说,
1.数据准备:首先,收集了约100万个数学问题作为种子集,过滤掉没有标准答案的问题,并进行多样性标签和过采样处理。然后,对开源数据集进行污染评估和去除,确保数据质量。
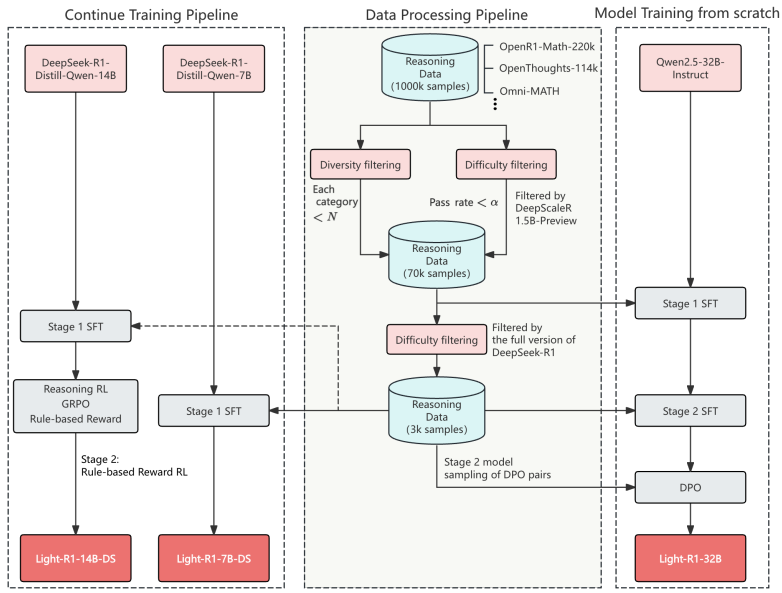
2.多阶段课程训练:设计了三个阶段的多阶段课程训练策略:
SFT阶段1:在76k个过滤后的数学问题上进行训练。
SFT阶段2:在3k个最具挑战性的数学问题上进行微调。
DPO优化:使用偏好优化算法,基于验证的回答对进行优化。
3.强化学习:在DeepSeek-R1-Distill-Qwen-14B模型上应用强化学习,采用两步过程:
离线数据选择:使用Light-R1-7B-DS模型采样RL训练提示,保留通过率在0.25到0.625之间的提示。
在线强化学习:应用GRPO算法对过滤后的数据集进行优化,采用修改后的长度奖励和重要性采样权重裁剪技术,稳定训练过程。
实验设计
数据收集:从多个来源收集约100万个数学问题,过滤掉没有标准答案的问题,并进行多样性标签和过采样处理。
数据清洗:对开源数据集进行污染评估和去除,确保数据质量。使用DeepScaleR-1.5B-Preview模型生成初步的链式思维回答,过滤出通过率低于某一阈值的问题。
训练过程:分三个阶段进行训练:
SFT阶段1:在76k个过滤后的数学问题上进行训练。
SFT阶段2:在3k个最具挑战性的数学问题上进行微调。
DPO优化:使用偏好优化算法,基于验证的回答对进行优化。
1. 强化学习:在DeepSeek-R1-Distill-Qwen-14B模型上应用强化学习,采用两步过程:
离线数据选择:使用Light-R1-7B-DS模型采样RL训练提示,保留通过率在0.25到0.625之间的提示。
在线强化学习:应用GRPO算法对过滤后的数据集进行优化,采用修改后的长度奖励和重要性采样权重裁剪技术,稳定训练过程。
结果与分析
课程训练效果:通过多阶段课程训练,Light-R1-32B模型在数学推理任务中表现优异,超过了DeepSeek-R1-Distill-Qwen-32B模型。具体表现为:
在AIME24和AIME25测试中,分别达到了76.6和64.6的分数。
尽管在科学问答(GPQA)任务上表现有所下降,但仍显示出较强的泛化能力。
1. 强化学习效果:在14B模型的数学推理任务中,应用强化学习后,Light-R1-14B-DS模型表现出色,达到了74.0和60.2的AIME24和AIME25分数,超过了许多32B模型和DeepSeek-R1-Distill-Llama-70B模型。此外,强化学习还提升了模型的跨域泛化能力。
总体结论
本文提出的Light-R1系列模型通过多阶段课程训练和强化学习,成功训练了长链式思维模型,并在数学推理任务中取得了优异的性能。该方法不仅降低了资源消耗,还提高了模型的可访问性和可实施性。未来的工作将进一步探索长COT模型的增强泛化能力和RL训练效率的优化。
关键问答
Light-R1 是什么?它解决的主要问题是什么?
Light-R1 是一个开源的、用于训练长链思考 (Long COT) 模型的套件,它采用可重现且成本效益高的方法进行训练。它主要解决了 DeepSeek-R1 等全容量模型参数量巨大(通常超过 70B,DeepSeek-R1 参数量为 671B),导致计算成本过高、难以在边缘设备和实时应用中部署的问题。Light-R1 致力于开发参数量在几十亿以下、但仍能执行扩展长 COT 的紧凑型模型。
Light-R1 的核心训练方法是什么?
Light-R1 的核心训练方法是“课程训练”(Curriculum Training) 策略。这种方法通过逐步增加训练数据的难度来训练模型,并结合多阶段的后训练 (Post-Training)。具体包括两个阶段的监督微调 (SFT) 和一个 DPO(直接偏好优化)阶段,以及对部分模型的强化学习 (RL) 优化。
Light-R1 的训练数据是如何准备的?
Light-R1 的训练数据准备过程包括数据收集、数据去污和数据生成。首先从多种开源来源收集数学问题和答案,形成一个种子数据集。然后对数据进行去重和格式标准化,并进行多样性过滤。接着进行数据去污,移除与评估基准(如 AIME24/25、MATH-500 等)重复或相似的问题。最后,通过难度过滤(使用 DeepScaleR-1.5B-Preview 和 DeepSeek-R1 模型评估难度)和 DeepSeek-R1 模型生成长 COT 响应,构建了两个阶段的 SFT 数据集:第一阶段约 7.6 万个样本,第二阶段约 3 千个更具挑战性的样本。
Light-R1 的课程 SFT 和 DPO 训练具体是如何进行的?
Light-R1 的课程后训练分为三个阶段:
SFT 阶段 1:在包含约 7.6 万个已过滤数学问题的较大数据集上进行训练。
SFT 阶段 2:在包含约 3 千个最具挑战性问题的较小数据集上进行微调。
DPO 优化:使用经过验证的响应对(由 DeepSeek-R1 生成的正确长 COT 答案作为“优选”响应,由 SFT-stage-2 模型生成但验证为错误的响应作为“拒绝”响应)进行基于偏好的优化。DPO 阶段采用了 NCA loss 和序列并行化技术来处理长响应。
Light-R1 的评估方法稳定可靠吗?
Light-R1 的评估方法被认为是稳定可靠的。它遵循 DeepSeek-AI (2025) 的做法,使用采样温度 0.6 进行评估,并且为了减少随机性带来的偏差,每个问题生成 64 个响应来估计 pass@1 分数。研究人员验证了这种做法,并指出使用较少的样本(如 16 个或更少)会带来较大的分数偏差。Light-R1 的评估代码和日志均已发布,并能够复现 DeepSeek-R1-Distill 模型和 QwQ 的评估结果。
Light-R1 系列模型的性能如何?特别是与 DeepSeek-R1-Distill 模型相比?
Light-R1 系列模型在数学推理任务上表现出色。例如,Light-R1-32B 模型(基于 Qwen2.5-32B-Instruct 训练)在数学推理方面优于 DeepSeek-R1-Distill-Qwen-32B。特别是,利用 Stage 2 的 3k 高质量数据对 DeepSeek-R1-Distill 模型进行微调,显著提升了不同参数量(7B, 14B, 32B)的 DeepSeek-R1-Distill 模型的性能,甚至在一些基准上达到了新的最先进水平 (SOTA)。
Light-R1 是如何将强化学习应用于长 COT 模型的?效果如何?
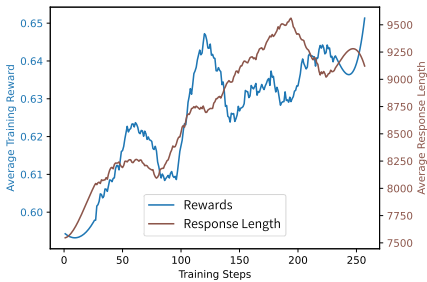
Light-R1 成功地将强化学习 (RL) 应用于 14B 的长 COT 模型 (Light-R1-14B-DS),这是首次公开记录的在已进行长 COT 微调的 14B 模型上通过 RL 显著提升性能的工作。RL 过程采用两阶段方法:首先进行离线数据选择,过滤掉过易或过难的训练数据;然后使用 GRPO 算法在过滤后的数据集上进行在线强化学习。训练过程中采用了修改版长度奖励和重要性采样权重截断等技术来稳定训练。结果显示,RL 训练不仅提升了模型性能(如 Light-R1-14B-DS 在 AIME 基准上达到 SOTA),还实现了响应长度和奖励分数的同步增长,克服了小型模型 RL 训练中可能出现的长度坍塌问题。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 225
225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









