










CVPR 2016
Anticipating Visual Representations from Unlabeled Video
http://www.guokr.com/article/441589/
预测未来? 本文使用CNN网络,通过学习大量未标记视频数据,来预测未来发生的事情。虽然效果不完美,但是方向还是很吸引人的,相信不远的将来该方向会有更大的进步。
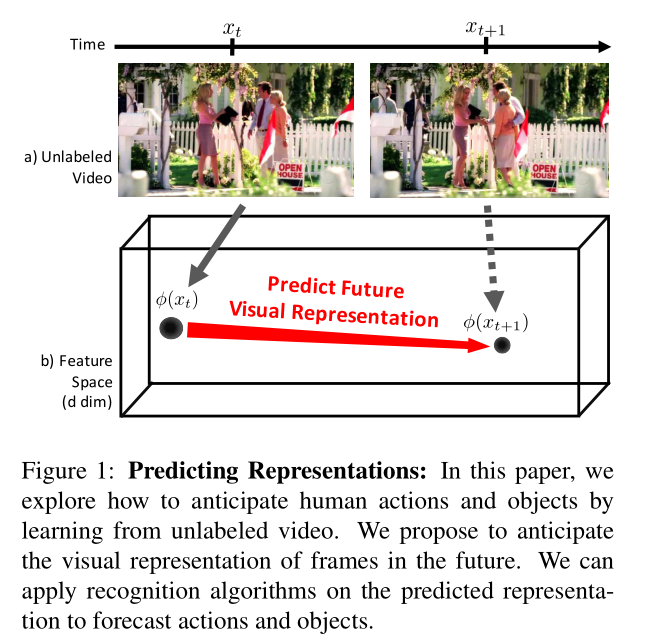
本文的网络结构如下:
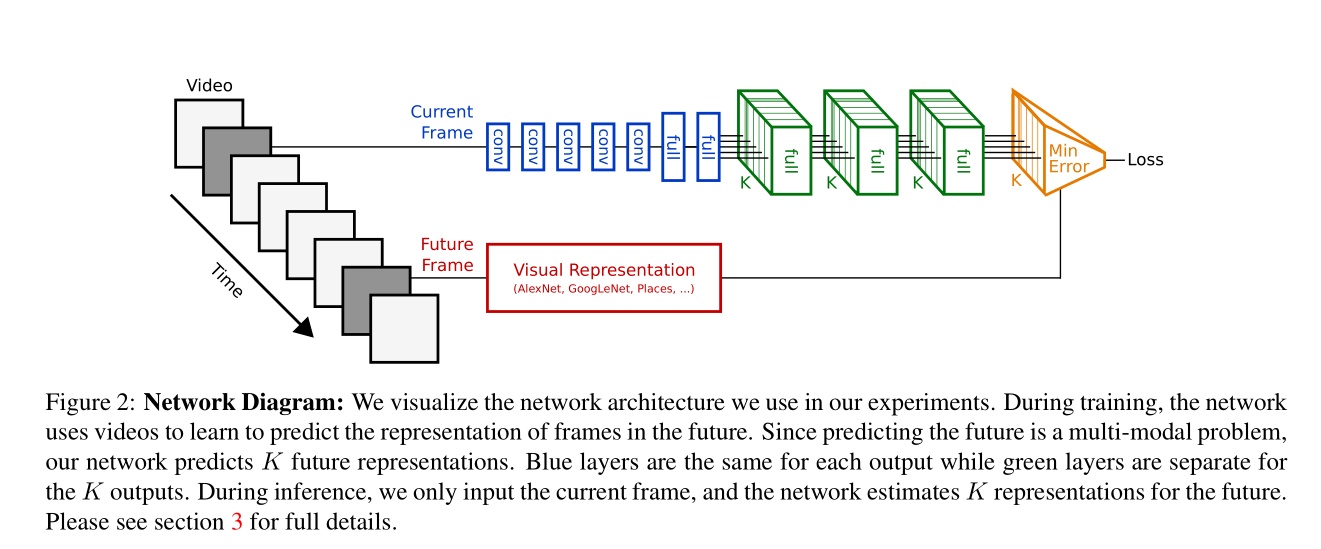
因为未来具有多种可能性,所以我们使用相同的CNN卷积网络提取特征,然后使用不同的分类网络,对应K个未来的可能性。 这种结构模型最大的优点就是可以利用海量未标记的视频。
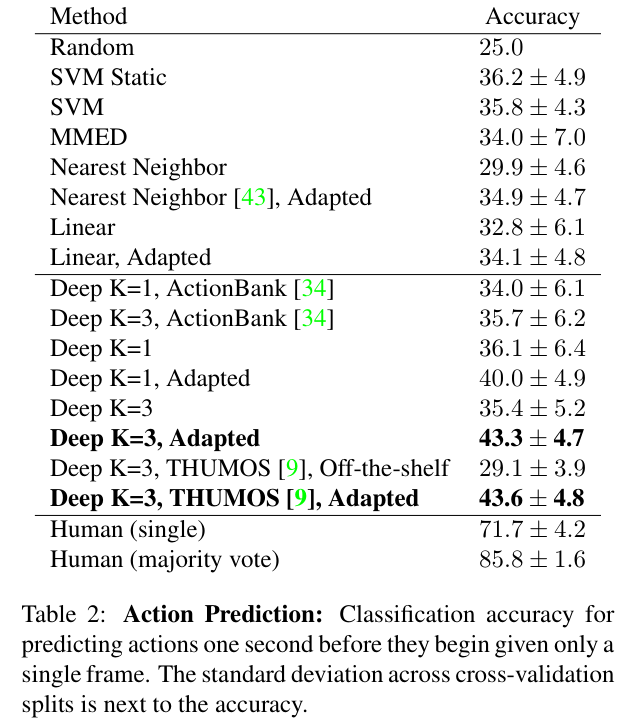
与人类准确率数据对比


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









