








Online Unsupervised Feature Learning for Visual Tracking
[1] F. Liu, C. Shen, I. Reid and A. van den Hengel, "Online Unsupervised Feature Learning for Visual Tracking," arXiv preprint arXiv:1310.1690, 2013.
文章针对tracking-by-detection的跟踪框架,利用unsupervised feature learning,生成over-complete的dictionary,然后对image patches进行编码,再利用空间金字塔形成特征向量;最后进行SVM分类器的训练。
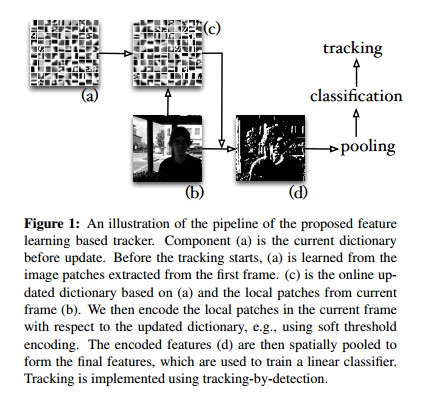
作为文章的主要贡献,作者们提出了一种可以进行在线更新dictionary的算法,初始的dictionary在本文中是从初始的第一帧视频中得到的,通过迭代计算A B的值对字典进行更新,D为字典,X为image patch原始数据,文中提到,为了计算效率,利用soft threshold(ST)*对原始数据X进行编码:
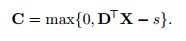
然后利用max-pooling操作来产生最终的特征向量*,最后在进行SVM训练分类。
具体来说,为了进行在线更新,字典的特征维数必须加以限制,同时字典需要控制大小以便可以实时更新。对于经典的字典最优化问题可以由下面的目标方程求解:
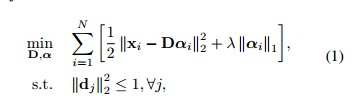
在本文的在线字典学习算法中,假设训练集是i.i.d.采样,每一次从原始数据中用经典的稀疏编码步骤以及上一帧中未更新的字典计算出α,,再通过更新算法更新字典D:

这里(3)中的推倒用的数学方法博主还不太明白,希望大家指教,怎么使用矩阵的trace来代替2范式的呢?接下来(3)中的优化问题通过一次更新D中低j列解决,利用的正交投影到约束集合的方法:

跟踪算法和字典的更新算法总结为下图:

作者为了防止更新过多导致的不稳定(漂移?)情况,同时也是为了保证效率,采用了启发式策略。对D中基赋予权值,定义为编码特征的二范式,表征的是在编码过程中相应基的相对重要性,根据这个权值就可以把基按照重要性由大到小排序,在跟踪过程中当连续两帧中的目标区域与字典中权值最高的一半基的重叠率小于一定阈值(文中取0.9),认为目标的外表发生了变化,则相应的需要更新字典。
最后为了建立discriminative model,使用了least-squared SVM(LS-SVM),给出部分原文:

给自己留下的问题:
*max-pooling operation是什么概念?
Learning Mid-LevelFeatures For Recognition (max-poolingoperation)
*soft-threshold是什么概念?
A Derivation of the Soft-Thresholding Function
*本文的更新算法采用交替更新字典D和洗漱编码α,而稀疏编码α需要根据上一帧中的字典D来更新,那对于算法的初始化时,D和α是如何建立的呢?
*博主是初学者,仅仅自己读文章做个记录,一般都是各种不懂,难免有错,请大家指正,留下的问题也请大家指教。















 732
732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









