








标题:TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding
论文:https://arxiv.org/pdf/2404.09797.pdf
代码:https://github.com/bzluan/TextCoT
导读
TL;DR: TextCoT 是一种零样本思维链方法,无需精心设计提示样例,并且可以在参数量较小的7B模型上也展现出对多模态理解能力的提升,展现了广泛的适用性和强大的性能提升效果。
本文提出了一种全新的基于多模态大模型的思维链框架,即TextCoT。
TextCoT 解决了多模态大模型在文字密集图像领域的短板,可以即插即用地提升各种多模态大模型提取全局和局部视觉信息的能力,从而更准确地进行问答。
特别地,TextCoT 能够在不进行任何额外训练或对模型架构进行修改的情况下,即插即用地提升多模态大模型在理解文本密集图像任务上的性能。
通过利用文字提示和视觉提示,在文本和视觉两个模态同时进行思维链推理。
无需依赖外部知识或其他模型的信息,便能显著增强模型对图像的理解力。
背景
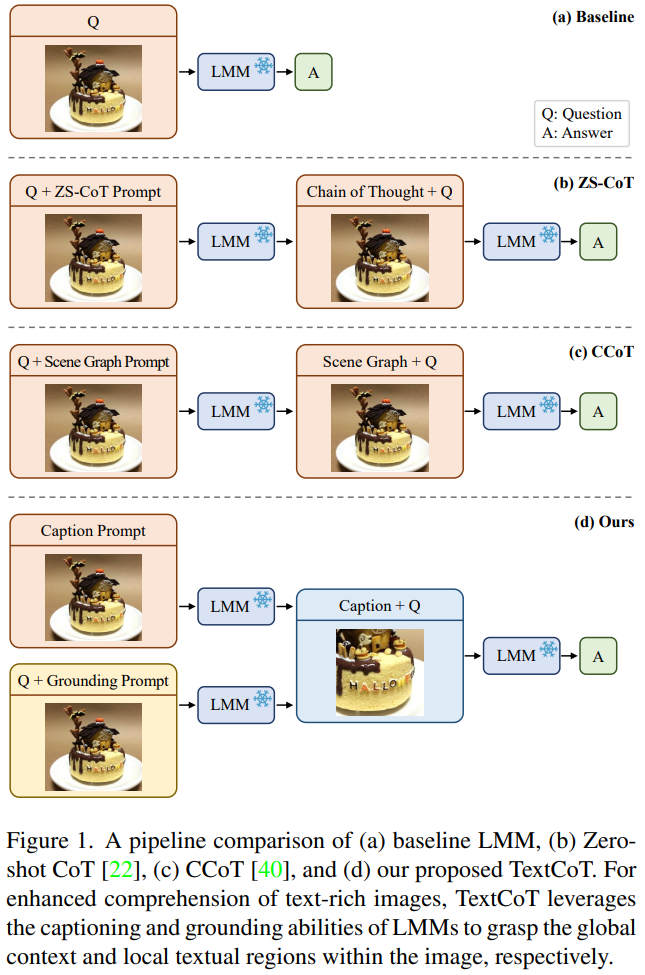
随着多模态大模型的发展,研究者们利用这些模型解决各种任务的能力大幅提升。文字密集的图像通常具有高分辨率,并且信息的粒度较细。
在理解文字密集的图像方面,LMMs 的潜力还远未被充分利用。这些模型在处理高分辨率图像时常常面临困难,这限制了它们在问答任务中的准确性。
因此,如何有效利用多模态大模型理解包含细粒度文本信息的图像成为了一个亟待解决的问题。
方法
论文提出一个创新的思维链框架 TextCoT,专为加强文字密集图像的理解而设计。
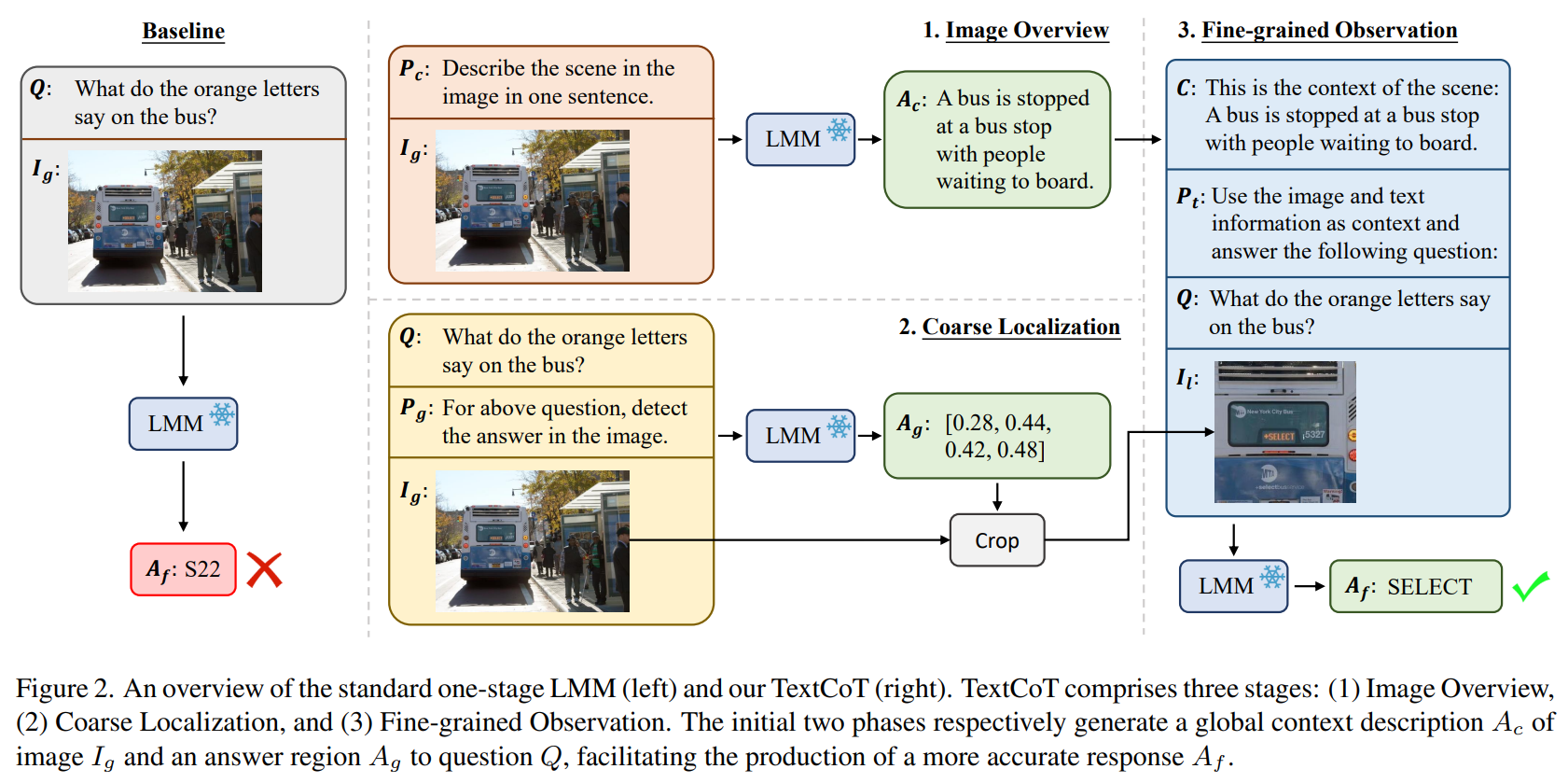
TextCoT 的核心思想是利用 LMMs 的描述能力和定位能力,分别关注图像的全局背景和局部文本区域,从而更准确地回答关于图像的问题。
TextCoT分为三个阶段:图像概览、粗略定位和细粒度观察。
- 在图像概览阶段,模型生成一个全面的场景描述,为后续的细节观察提供背景信息;
- 在粗略定位阶段,模型根据提出的问题确定包含答案的大致区域;
- 最后,在细粒度观察阶段,模型结合全局描述和具体的图像区域,深入探索特定区域以提供精确答案。
效果
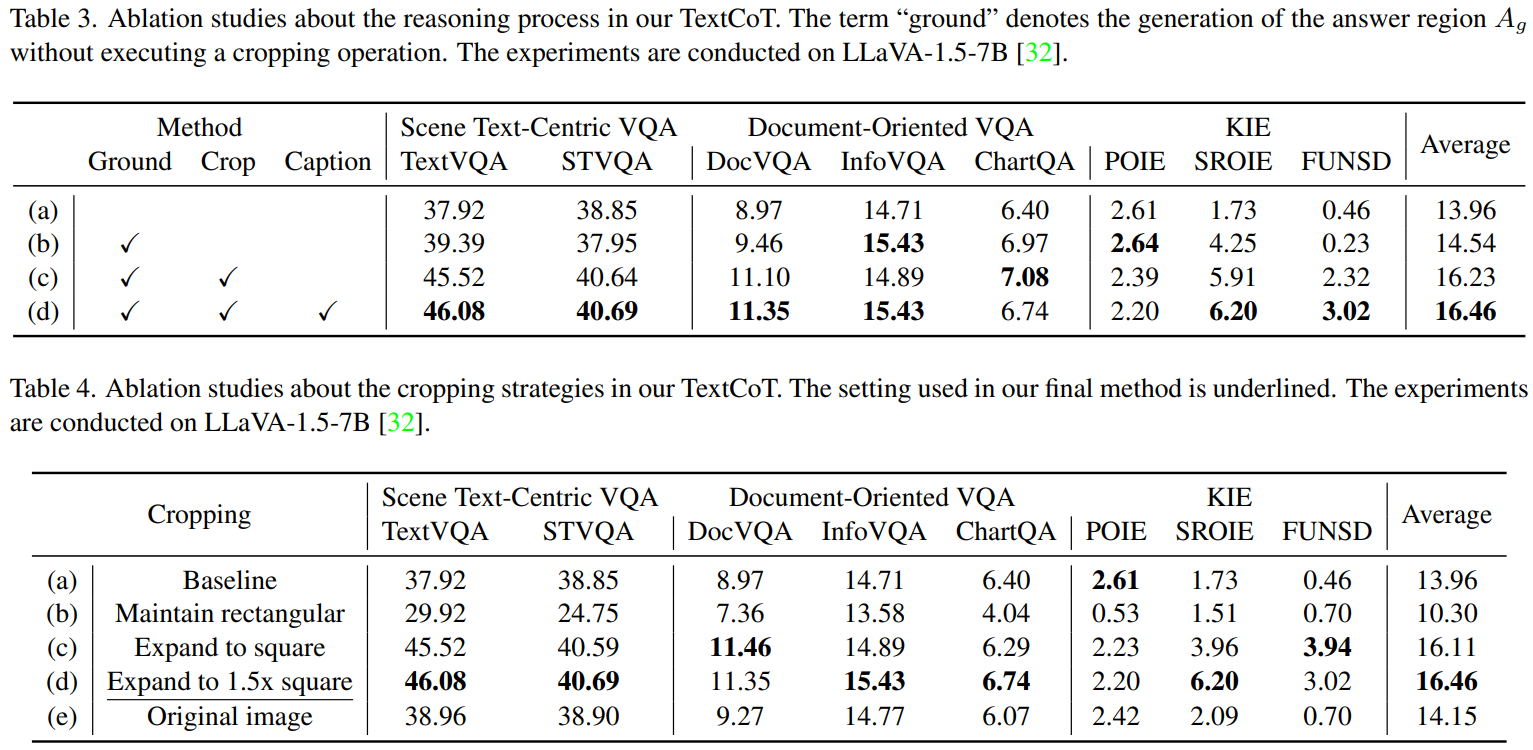
首先,我们看下不同的策略对模型性能的影响。
论文使用5个多模态大模型在8个文字密集场景的图像问答基准数据集上对TextCoT进行了广泛的定量实验。
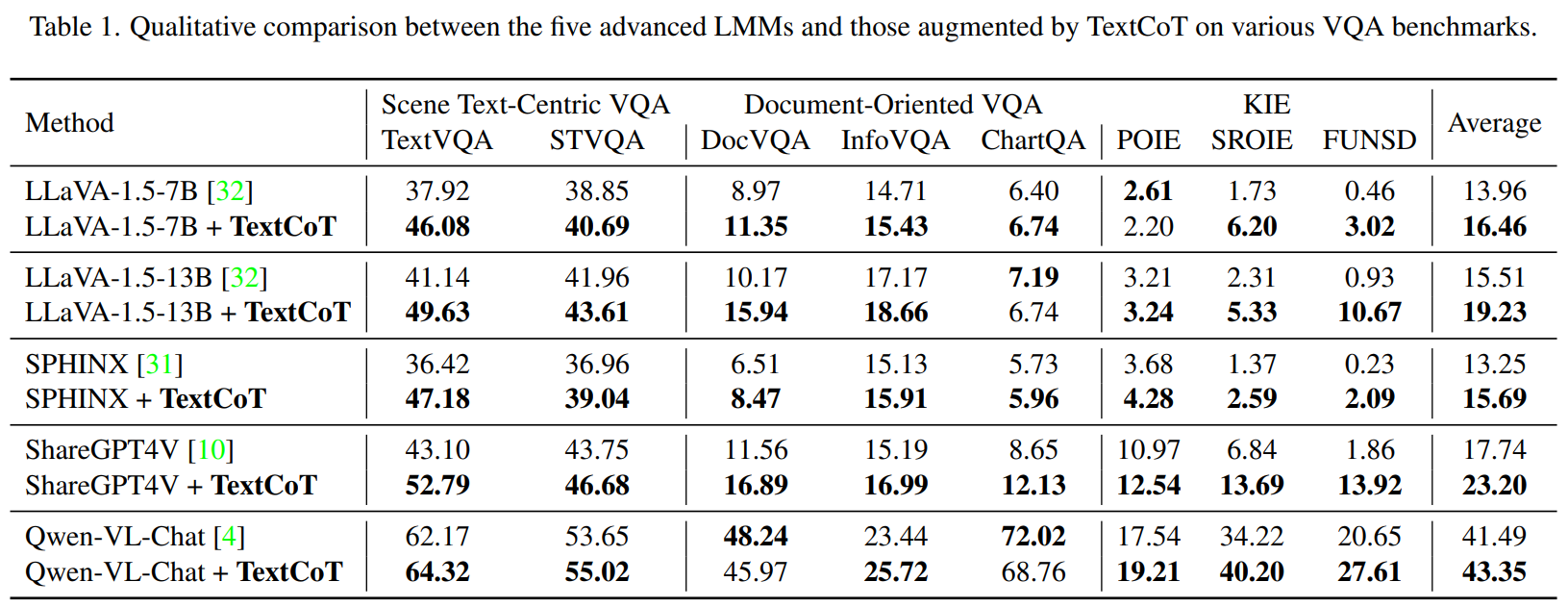
对比基线实验结果表明,TextCoT的使用5个多模态大模型,在几乎所有数据集上都显示出了显著的提升效果和很强的泛化能力。
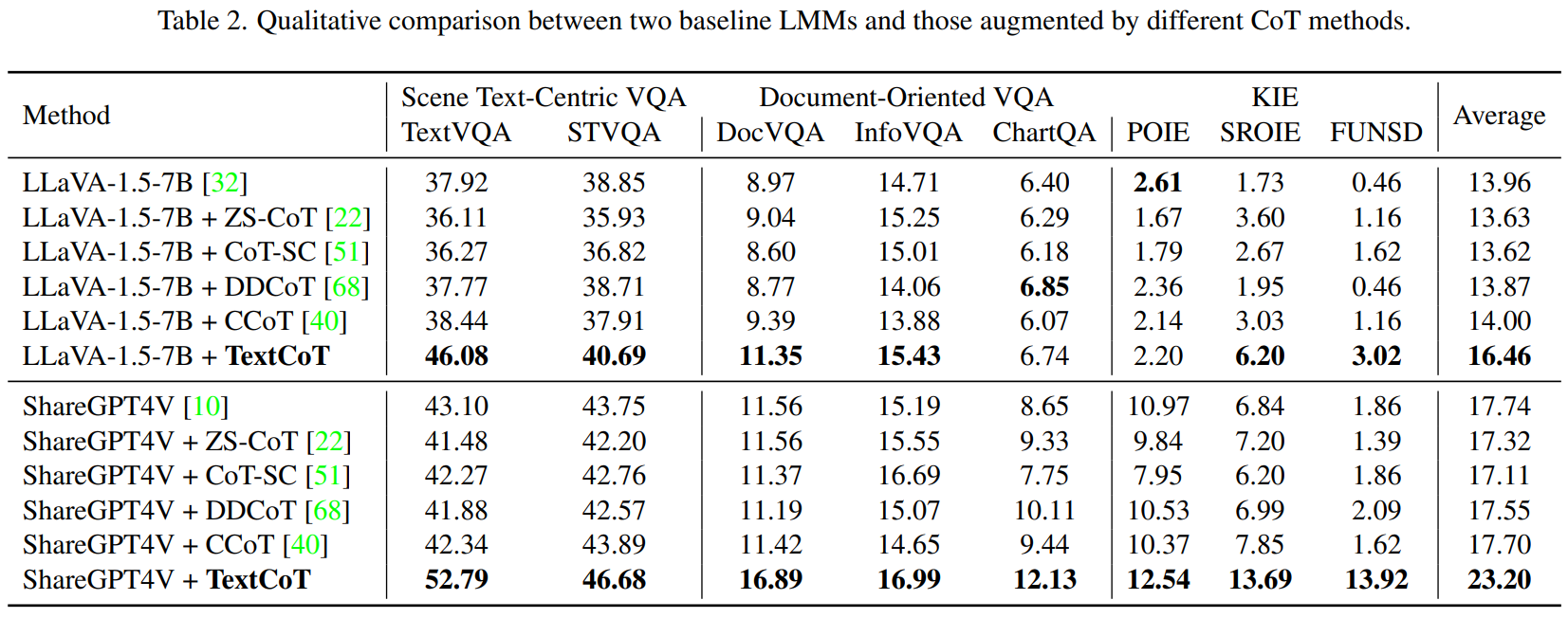
通过和其他CoT方法的对比实验,TextCoT展现了其对图像细粒度信息的提取能力的优势。
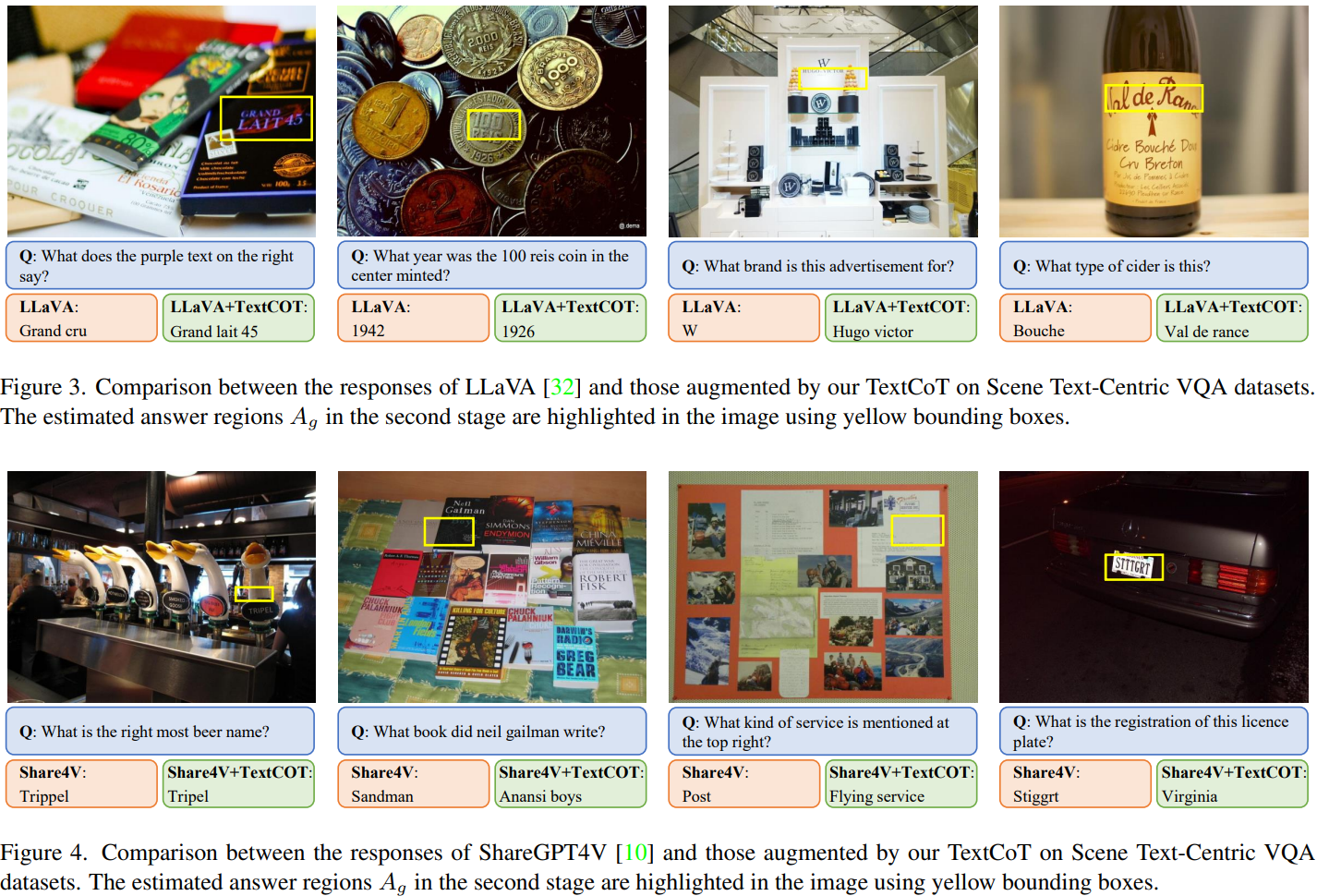
此外,论文还提供了一系列可视化结果,直观展示了TextCoT如何通过更细致地观察图像中的局部文本区域来提高问答准确性。

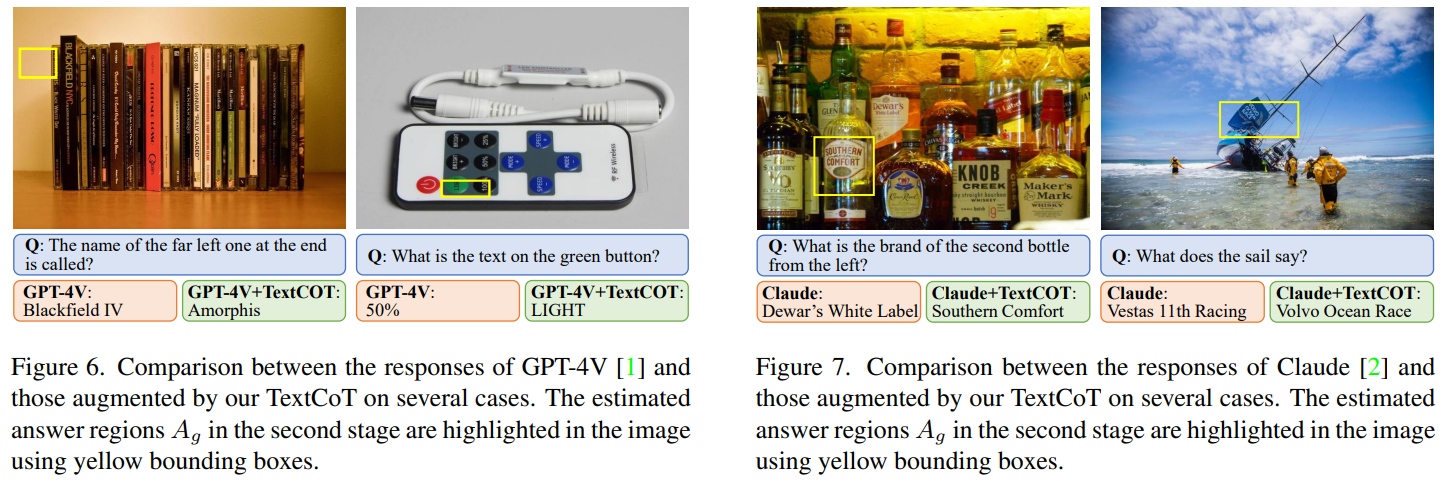
总结
TextCoT 为文字密集的图像理解领域提供了一种新的视角和方法。通过利用LMMs的描述和定位能力,TextCoT 能够有效提取图像中的全局和局部视觉信息,从而提高问答任务的准确性。这项工作不仅展示了 TextCoT 的强大性能,也为未来研究提供了新的方向,即如何进一步发掘和利用 LMMs 在多模态理解方面的潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











