





ai模型
如今,人工智能(AI)的偏见备受争议。 从不恰当地标记人脸的图像分类器到雇用在甄选求职者时歧视女性的机器人,人工智能似乎在继承自动复制的人类最坏习惯。
风险在于我们将使用AI来创建一支种族主义,性别歧视,口臭的机器人大军,然后它们会再次困扰我们。 这是一个道德困境。 如果AI天生就有偏见,依靠它会不会有危险? 我们最终会塑造最糟糕的未来吗?
机器将是机器
首先让我澄清一件事:AI只是一台机器。 我们可能将其拟人化,但它仍然是一台机器。 这个过程与我们和孩子们在湖边玩石头的过程并没有什么不同,突然之间,一块呆板的石头变成了可爱的宠物石头。
即使与您的孩子一起玩耍,我们通常也不会忘记,无论多么可爱的宠物石头仍然只是一块石头。 我们应该对AI做同样的事情:无论人类如何喜欢它的对话或外观,我们都不应忘记它仍然只是一台机器。
例如,前段时间,我从事机器人项目: 教师机器人 。 这个想法是为查询有关开源数据科学软件KNIME Analytics Platform的文档和功能的信息生成自动的信息性答案。 与所有的bot项目一样,一个重要的问题是说话的风格。
有许多可能的说话或写作风格。 对于机器人,您可能希望它友好,但又不要过分友好-视情况而定,有时又要果断。 博客文章“用60个词来描述写作或口语风格 ”列出了60种不同的机器人说话风格的细微差别:从健谈和对话到抒情和文学,从有趣,雄辩到正式,乃至我所不喜欢的,都不连贯。 我的机器人应该采用哪种说话风格?
我追求两种可能的风格: 礼貌和自信 。 礼貌到诗意的极限。 主张不礼貌接壤。 两者都是自由文本生成问题。
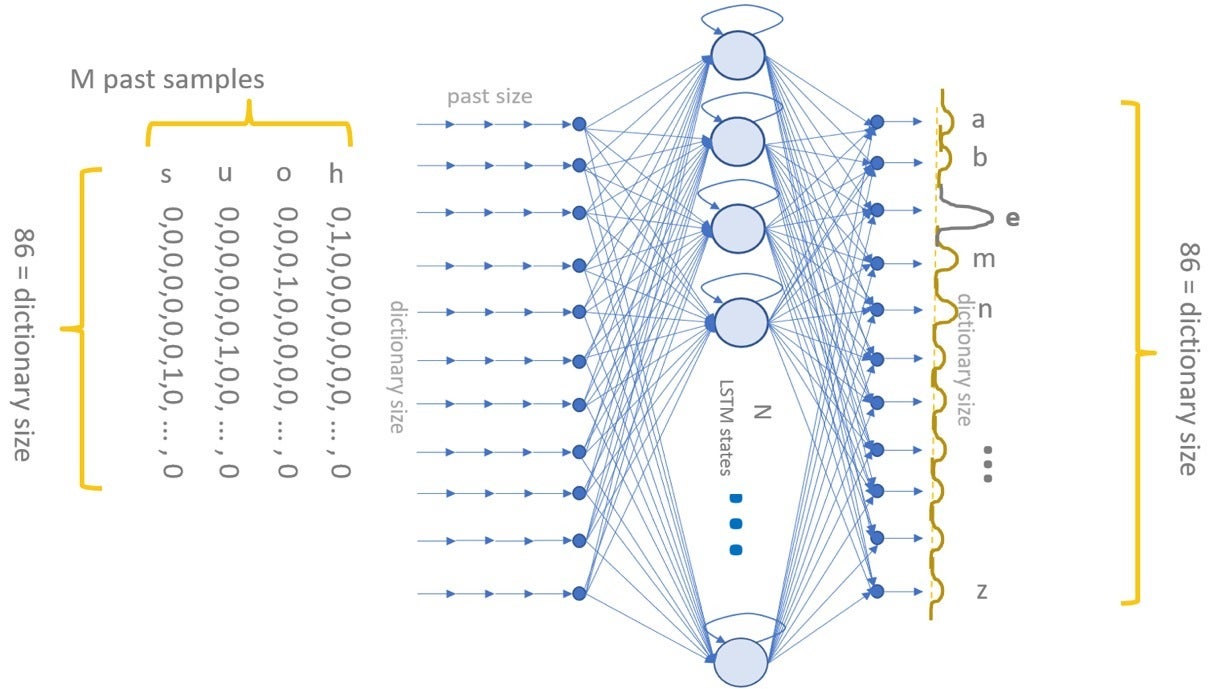
作为这个教师机器人项目的一部分,几个月前,我实现了一个简单的深度学习神经网络,该网络具有一个隐藏的长短期记忆(LSTM)单元层,可以生成自由文本。
网络将采用M个字符序列作为输入,并在输出层预测下一个最可能出现的字符。 因此,给定输入层字符“ hous”的顺序,网络将预测“ e”为下一个最可能出现的字符。 在免费句子的语料库上进行训练后,该网络学会一次生成单词甚至句子一个字符。
我并不是从头开始构建深度学习网络,而是(按照当前在互联网上查找现有示例的趋势)在KNIME Hub上搜索了类似的解决方案,以生成免费文本。 我找到了一个,其中一个类似的网络接受了关于现有真实山名的培训,从而为一系列户外服装新产品生成了虚假的,无版权的山样候选名称。 我下载了网络并根据自己的需要对其进行了定制,例如,通过将多对多转换为多对一的体系结构。
该网络将接受适当的自由文本集培训。 在部署过程中,将提供M = 100个初始字符的触发语句,然后网络将继续自行组装其自己的自由文本。
 尼米
尼米
基于LSTM的深度学习网络,可生成免费文本。
人工智能偏见的一个例子
试想一下,客户或用户有不合理但扎根的期望,并要求不可能。 我该怎么回答? 机器人应该如何回答? 首要任务是训练网络要有主见-在不礼貌的极限下要有主见。 在哪里可以找到一套坚定而自信的语言来训练我的网络?
我最终在一组说唱歌曲文本上训练了我的基于LSTM的深度学习网络。 我认为说唱歌曲可能包含该任务所需的所有足够自信的文本。
我得到的是一个非常肮脏的网络; 如此之多,以至于每次我向观众介绍这个案例研究时,我都必须邀请所有未成年人离开房间。 您可能会认为我创建了一个性别歧视,种族主义,不尊重他人(即公开偏见)的AI系统。 看来我做到了
以下是网络生成的说唱歌曲之一。 手动插入了前100个触发字符。 这些是红色的。 网络生成的文本为灰色。 当然,触发语句对于为其余文本设置适当的语气很重要。 对于这种特殊情况,我首先从英语中可以找到的最无聊的句子开始:软件许可说明。
有趣的是,在所有可能的单词和短语中,神经网络选择在这首歌中包括“支付费用”,“昂贵”,“银行”和“诚实”。 语气可能不相同,但是内容尝试符合触发语句。
 尼米
尼米
AI生成的说唱歌曲的示例。 红色的触发语句是软件许可文档的开头。
有关此网络的构建,培训和部署的更多详细信息,请参见文章“ AI生成的说唱歌曲” 。
语言可能不是最优雅和正式的,但它具有令人愉悦的节奏,这主要是由于韵律。 注意,要使网络生成押韵文字,过去输入样本序列的长度M必须足够。 押韵适用于M = 100,但不适用于过去的M = 50。
消除AI的偏见
为了重新训练我的行为不端网络,我创建了一个新的训练集,其中包括莎士比亚的三部戏剧作品:两部悲剧(“李尔王”和“奥赛罗”)和一部喜剧(“无所事事”)。 然后,我在这个新的训练集上对网络进行了训练。
部署后,该网络现在会产生类似莎士比亚的文本,而不是说唱歌曲,这在语音清洁度和礼貌性方面都有明显的提高。 没有更多的亵渎! 不再有粗话!
同样,让我们从软件许可证文本的开头触发免费文本的生成,并根据我们的网络了解莎士比亚将如何进行。 以下是网络生成的莎士比亚文字:红色,为手动插入的前100个触发字符; 网络生成的文本为灰色。
即使在这种情况下,触发语句也为接下来的单词设置了语调:“小偷”,“保存并诚实”以及令人难忘的“先生,现在耐心在哪里”都与阅读软件许可证相对应。 但是,这次的演讲风格大不相同。
有关该网络的构建,培训和部署的更多详细信息,请参见“ 如何使用深度学习编写莎士比亚” 。
现在,请记住,生成类似莎士比亚文字的神经网络与生成说唱歌曲的神经网络相同。 完全相同的。 它只是训练了一组不同的数据:一方面是说唱歌曲,另一方面是莎士比亚的戏剧作品。 结果,产生的自由文本非常不同-生产中产生的文本的偏差也是如此。
 尼米
尼米
AI生成的莎士比亚文字示例。 红色的触发语句是软件许可文档的开头。
总而言之,我创建了一个非常肮脏,激进且有偏见的AI系统,也创建了一个非常优雅,正式,几乎富有诗意的AI系统-至少就演讲风格而言。 它的优点在于两者都基于相同的AI模型-两个神经网络之间的唯一区别是训练数据。 偏差实际上是在数据中,而不是在AI模型中。
偏向,偏向
的确,人工智能模型只是一台机器,就像一块宠物石头最终只是一块石头一样。 这是一台根据训练集中的数据调整其参数(学习)的机器。 训练集中的性别歧视数据产生了性别歧视AI模型。 训练集中的种族数据会产生种族AI模型。 由于数据是由人类创建的,因此它们也经常带有偏差。 因此,所得的AI系统也将存在偏差。 如果目标是建立一个干净,诚实,无偏见的模型,则应在训练之前清除训练数据并消除所有偏差。
罗萨丽娅Silipo是在主要数据科学家KNIME 。 她是50多个技术出版物的作者,包括她的最新著作《 实践数据科学:案例研究的集合》 。 她拥有生物工程学博士学位,并且在为物联网,客户智能,金融行业和网络安全等广泛领域的公司从事数据科学项目上花费了25年。 在Twitter , LinkedIn和KNIME博客上关注Rosaria。
-
新技术论坛提供了一个以前所未有的深度和广度探索和讨论新兴企业技术的场所。 选择是主观的,是基于我们选择的技术,我们认为这些技术对InfoWorld读者来说是重要的,也是他们最感兴趣的。 InfoWorld不接受发布的营销担保,并保留编辑所有贡献内容的权利。 将所有查询发送到 newtechforum@infoworld.com 。
翻译自: https://www.infoworld.com/article/3514578/how-to-keep-bias-out-of-your-ai-models.html
ai模型















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









