





自助式分析大数据
Qubole被称为用于分析,人工智能和机器学习的云原生数据平台,为客户参与,数字转换,数据驱动的产品,数字营销,现代化和安全智能提供解决方案。 它声称具有快速实现价值的速度,多云支持,10倍的管理员生产力,1:200的运营商与用户比率以及更低的云成本。
 信息世界
信息世界
根据我对平台的简要经验,Qubole实际要做的是集成许多开源工具和一些专有工具,从而为数据分析师,数据工程师创建基于云的自助式大数据体验和数据科学家。
Qubole将带您从ETL开始,进行探索性数据分析和模型构建,再到按生产规模部署模型。 在此过程中,它可以自动执行许多云操作,例如资源调配和扩展,否则可能需要大量的管理员时间。 对于任何特定的公司或用例,这种自动化是否实际上将使管理员的生产率提高10倍,还是使运营商与用户的比例达到1:200尚不清楚。
Qubole倾向于强调“活动数据”的概念。 基本上,大多数数据湖(实际上是文件存储,其中填充了来自许多来源的数据,全部都集中在一个地方而不是一个数据库中),具有很少的数据被主动用于分析。 Qubole估计大多数数据湖的活动性为10%,非活动状态为90%,并预测它可以逆转该比率。
Qubole的竞争对手包括Databricks,AWS和Cloudera。 还有许多其他产品只能与Qubole的某些功能竞争。
Databricks在集群管理器和Spark的基础上构建笔记本,仪表板和作业; 当我在2016年对其进行评论时 ,我发现它对数据科学家来说是一个有用的平台。Databricks最近开放了其Delta Lake产品的开源,该产品提供ACID事务,可伸缩的元数据处理以及对数据湖的统一流和批处理数据处理,以使其更加可靠。并帮助他们进行Spark分析。
AWS有各种各样的数据产品,实际上Qubole支持与其中许多产品集成。 现在包括Hortonworks在内的Cloudera提供数据仓库和机器学习服务以及数据中心服务。 Qubole声称Databricks和Cloudera都缺乏财务治理,但是您可以自己在单云级别或通过使用多云管理产品来实施治理。
 IDG
IDG
Qubole体系结构概述。 请注意,其中包含的六个开源大数据产品显示在蓝色框的下半部分。
Qubole的工作原理
Qubole将其所有工具集成在基于云和基于浏览器的环境中。 我将在本文的下一部分中讨论环境的各个部分。 在本节中,我将重点介绍工具。
Qubole将成本控制作为其集群管理的一部分。 您可以指定群集使用实例类型的特定组合,包括现货实例(如果可用)以及用于自动缩放的最小和最大节点数。 您还可以指定任何群集在没有负载的情况下继续运行的时间长度,以避免出现“僵尸”实例。
火花
在他8月份的InfoWorld文章“ Qubole如何解决Apache Spark的挑战”中 ,Qubole的首席执行官Ashish Suchoo讨论了Spark的好处和陷阱,以及Qubole如何补救诸如配置,性能,成本和资源管理之类的难题。 对于数据科学家来说,Spark是Qubole的关键组件,可以轻松快速地进行数据转换和机器学习。
普雷斯托
Presto是一个开放源代码的分布式SQL查询引擎,用于对从千兆字节到PB大小在内的各种大小的数据源运行交互式分析查询。 Presto查询的运行速度比Hive查询快得多。 同时,Presto可以查看和使用Hive元数据和数据架构。
蜂巢
Apache Hive是Hadoop生态系统中一个受欢迎的开源项目,该项目有助于使用SQL读取,写入和管理驻留在分布式存储中的大型数据集。 可以将结构投影到已经存储的数据上。 配置单元查询执行通过Apache Tez,Apache Spark或MapReduce运行。 Hive on Qubole可以进行工作负载感知的自动缩放和直接写入; 开源Hive缺乏这些面向云的优化。
Qubole的创建者也是Apache Hive的创建者。 他们在Facebook上创立了Hive,并于2008年开源。
量子
Quantum是Qubole自己的无服务器,自动缩放,交互式SQL查询引擎,同时支持Hive DDL和Presto SQL。 Quantum是一种即用即付的服务,它对于散布在很长一段时间内的零星查询模式具有成本效益,并且具有严格的模式来防止意外支出。 昆腾使用Presto,并补充了Presto服务器群集。 量子查询仅限于45分钟的运行时间。
空气流动
Airflow是基于Python的平台,可通过编程方式创作,安排和监视工作流程。 工作流程是任务的有向无环图(DAG)。 您可以通过用Python代码编写管道来配置DAG。 Qubole提供Airflow作为其服务之一; 它通常用于ETL。
新的QuboleOperator可以像其他任何现有Airflow操作器一样使用。 在工作流中执行操作员期间,它将向Qubole Data Service提交命令,并等待命令完成。 Qubole支持文件和Hive表传感器,Airflow可以使用它们来以编程方式监视工作流。
要查看Airflow用户界面,您首先需要启动一个Airflow集群,然后打开集群页面以查看Airflow网站。
Ruby
RubiX是Qubole的轻量级数据缓存框架,可以由使用Hadoop文件系统接口的大数据系统使用。 RubiX旨在与Amazon S3和Azure Blob存储等云存储系统一起使用,并在本地磁盘上缓存远程文件。 Qubole已将RubiX开源 。 在Qubole中启用RubiX只需选中一个复选框即可。
Qubole是做什么的?
Qubole提供了一个用于分析和数据科学的端到端平台。 该功能分布在十几个模块中。
浏览模块可让您查看数据表,添加数据存储并设置数据交换。 在AWS上,您可以查看数据连接,S3存储桶和Qubole Hive数据存储。
通过“分析”和“工作台”模块,您可以对数据集运行临时查询。 Analyze是旧界面,而Workbench是新界面,当我尝试它时仍处于beta中。 这两个界面都允许您将数据字段拖放到SQL查询中,并选择用于运行操作的引擎:Quantum,Hive,Presto,Spark,数据库,shell或Hadoop。
Smart Query是Hive和Presto的基于表单SQL查询构建器。 模板允许您重复使用参数化SQL查询。
笔记本电脑是基于Spark的Zeppelin或(测试版)Jupyter笔记本电脑,用于数据科学。 仪表板提供了一个界面,用于共享您的浏览记录,而不允许您访问笔记本。
通过Scheduler,您可以定期自动运行查询,工作流,数据导入和导出以及命令。 这可以补充您可以在“分析”和“工作台”模块中运行的即席查询。
群集模块允许您管理Hadoop / Hive,Spark,Presto,Airflow和深度学习(beta)服务器的群集。 使用情况可让您跟踪集群并查询使用情况。 通过控制面板,您可以自己配置平台,也可以在拥有系统管理权限的情况下配置其他平台。
Qubole端到端演练
我经历了导入数据库,创建Hive模式以及使用Hive和Presto以及分别在Spark笔记本中分别分析结果的演练。 我还查看了用于相同过程的Airflow DAG,以及用于通过无关数据集上的Spark进行机器学习的笔记本。
 IDG
IDG
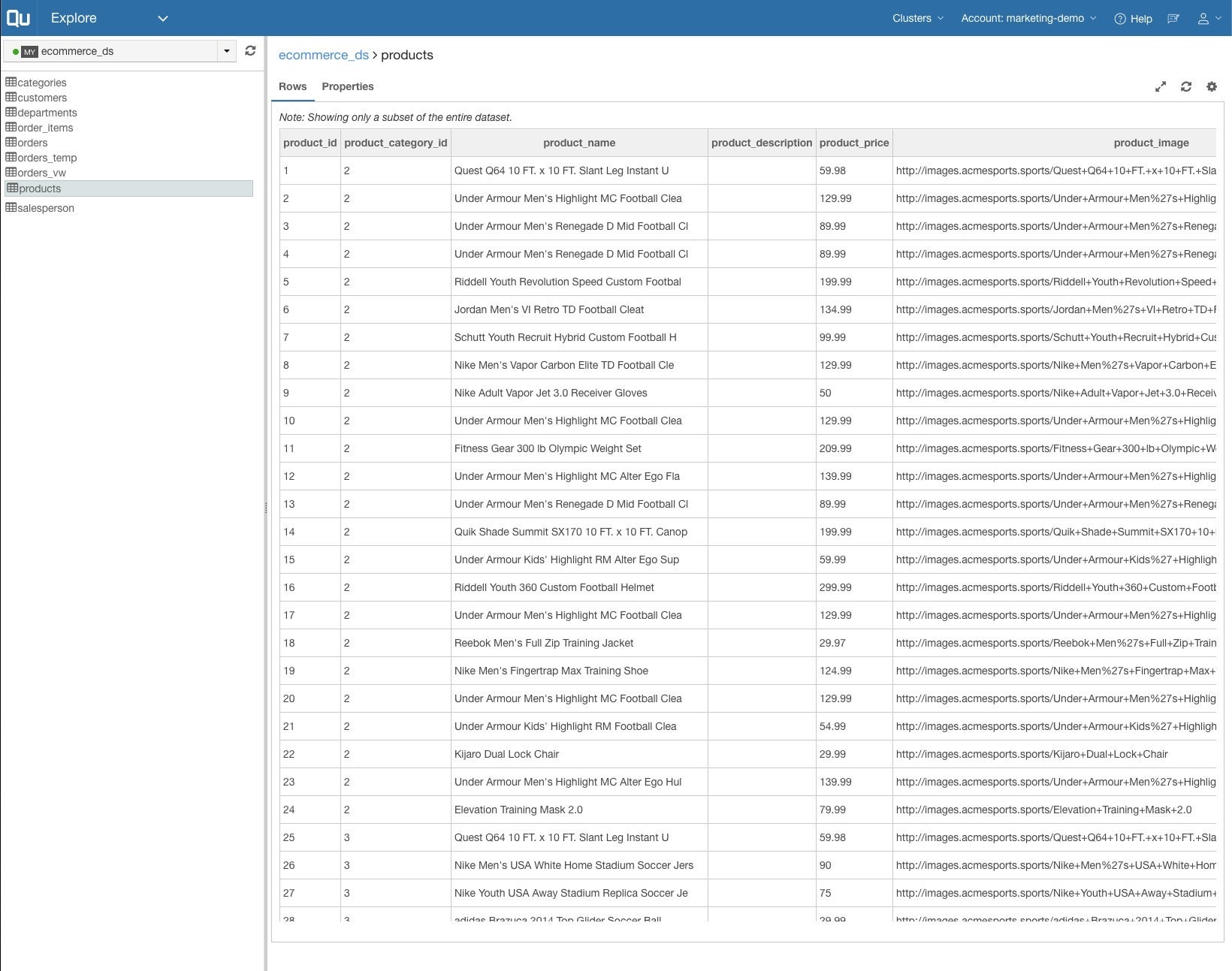
在Qubole的“浏览”模块中,您可以管理和检查数据源。 在这里,我们正在查看要导入以进行分析MySQL表的几行。
 IDG
IDG
在将数据导入Hive之前,您需要创建模式。
 IDG
IDG
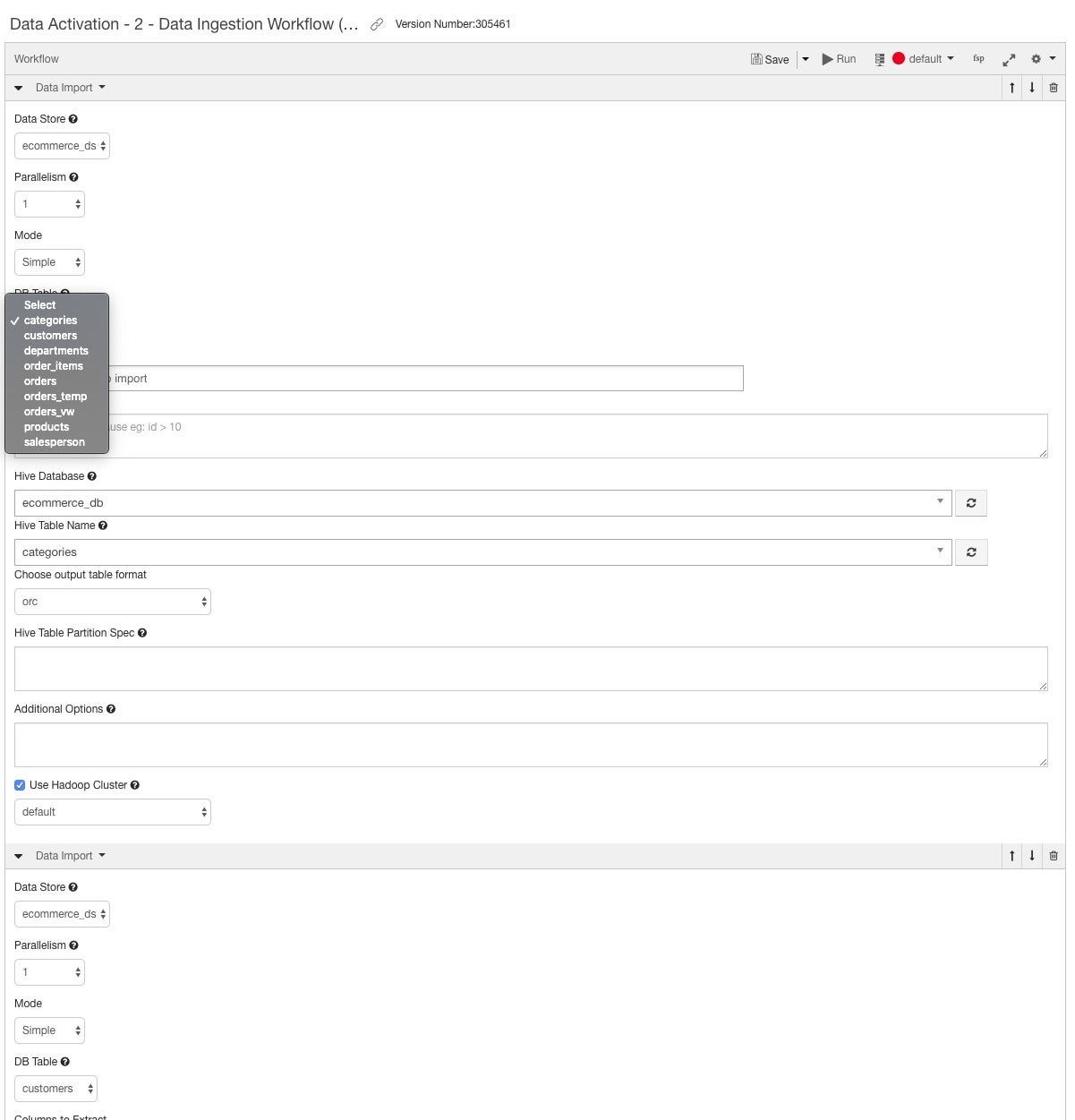
要为Hive定义数据导入,请为要加载的每个表设置导入工作流。 Qubole可以帮助您浏览数据存储和表,从而为您提供帮助。 ORC格式是针对Hive的优化的面向列的数据存储格式。
 IDG
IDG
与Hive自己SQL查询引擎相比,Presto通常是一种针对Hive数据运行临时SQL查询的更有效方式。 在这里,我们通过解析Web日志以获取对产品页面的引用,并对每个产品的视图数进行计数。 第3行中的正则表达式将Web URL重新格式化为品牌加产品名称。 access_logs表是通过将Web日志解析为具有另一个正则表达式的字段而构建的外部表。
 IDG
IDG
在此Presto查询中,我们将产品和订购项目表结合在一起,以构造按数量订购的项目清单。
 IDG
IDG
Presto可以轻松处理嵌套SQL选择。 在此,内部查询不包括已取消和欺诈的订单,将orders和order_items表联接起来,并对订单求和以计算收入。 外部查询将产品表与内部查询的结果连接起来,并按产品名称报告收入。
 IDG
IDG
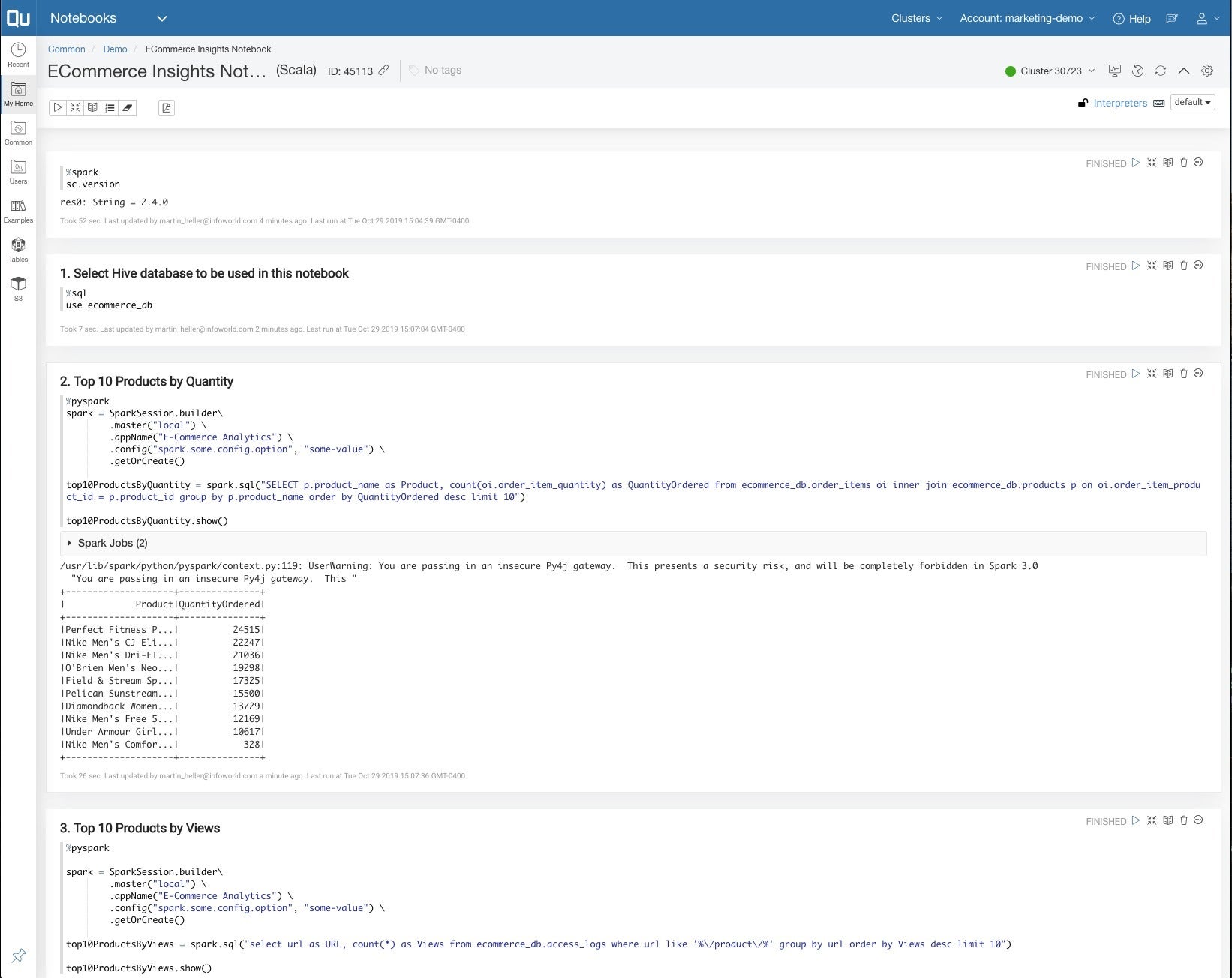
运行独立的Presto查询的替代方法是在Spark中运行相同SQL。 在这里,我们使用一个Zeppelin笔记本,该笔记本中包含Spark,SQL和PySpark中的单元格,以运行与在Presto中测试的相同的查询。 有关不安全的Py4j网关的消息仅是警告,对于Qubole隔离的网络配置而言,实际上并不重要。
 IDG
IDG
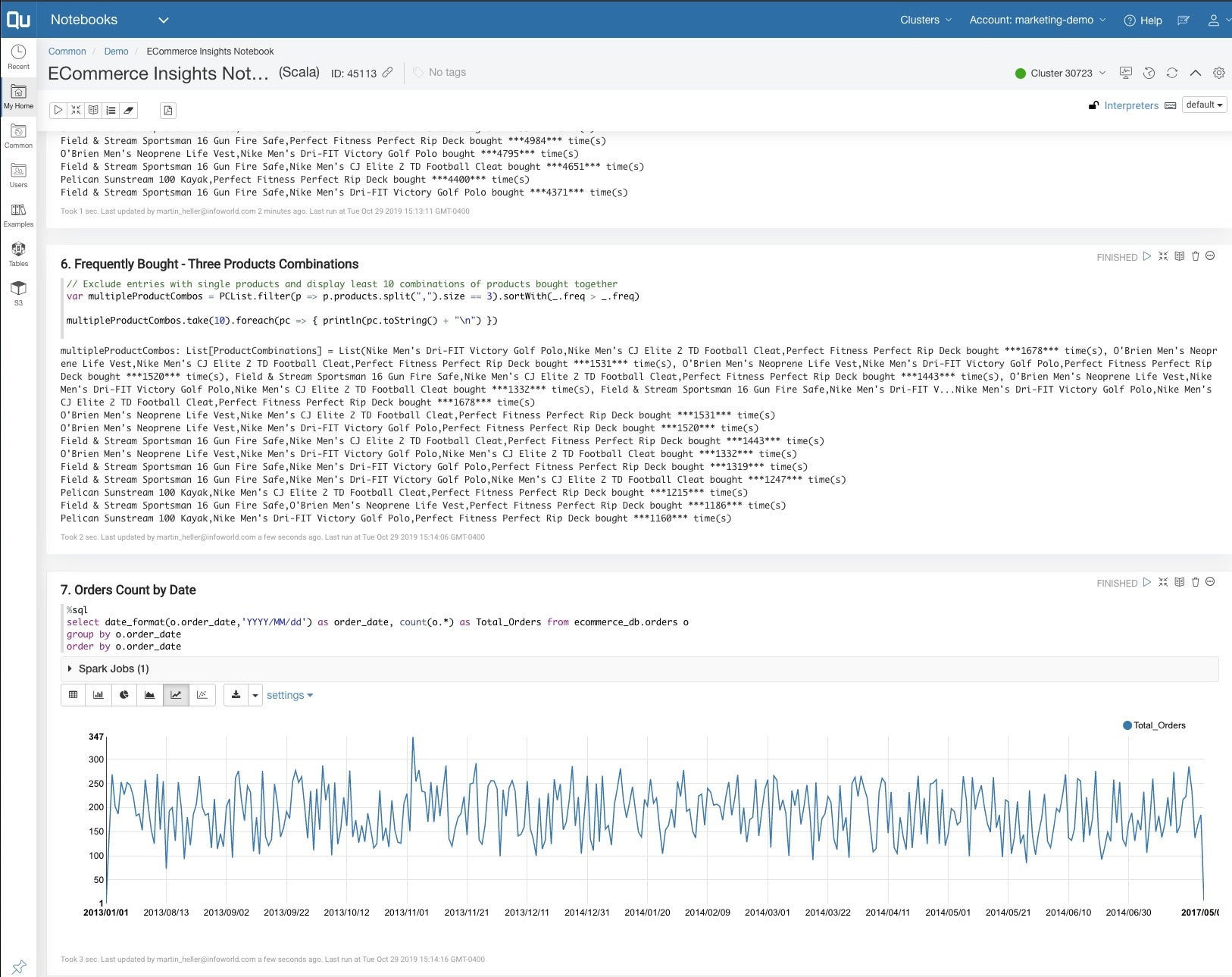
底部的Zeppelin笔记本单元(7)通过运行Spark SQL每天对订单进行计数。 Zeppelin笔记本电脑可以绘制结果图形并在表格中显示。 该单元可以导出到仪表板以供管理人员使用。
 IDG
IDG
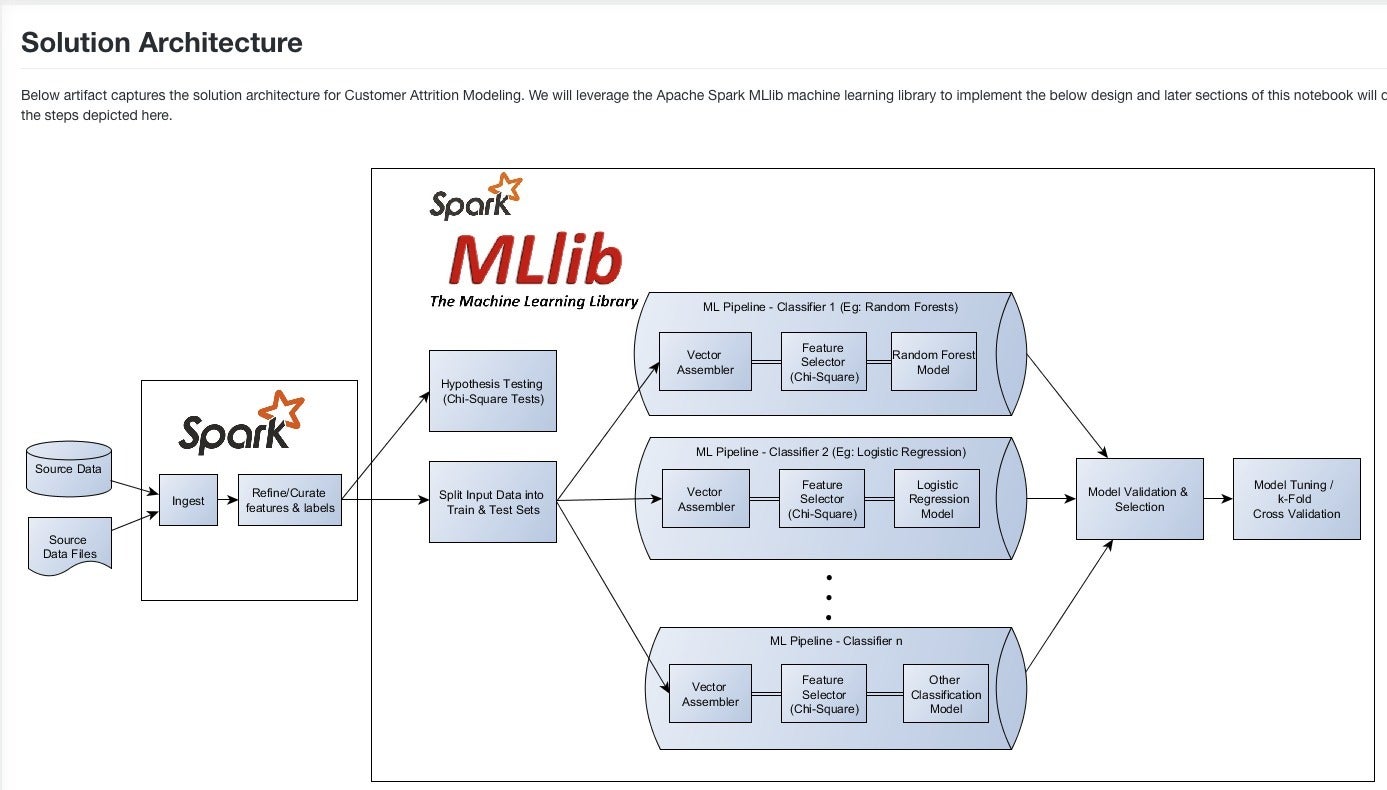
Spark笔记本通常用于MLlib的机器学习。 该图显示了摄取数据,执行特征工程,训练三种机器学习模型,选择最佳模型以及调整最佳模型的端到端过程。 UC Irvine提供的此处使用的数据集包含电信公司客户流失数据,并且这些模型试图预测给定客户是否会“流失”。
 IDG
IDG
Spark单元中显示的代码使三个模型适合同一训练数据集。 这些模型是随机森林,逻辑回归和梯度增强树(GBT)。 训练所有三个模型花费了40秒。 GBT模型产生的预测变量具有较高的假阳性率和较低的真实阳性率(C),因此需要反转(C')才能发挥作用,如下部单元格所示。
 IDG
IDG
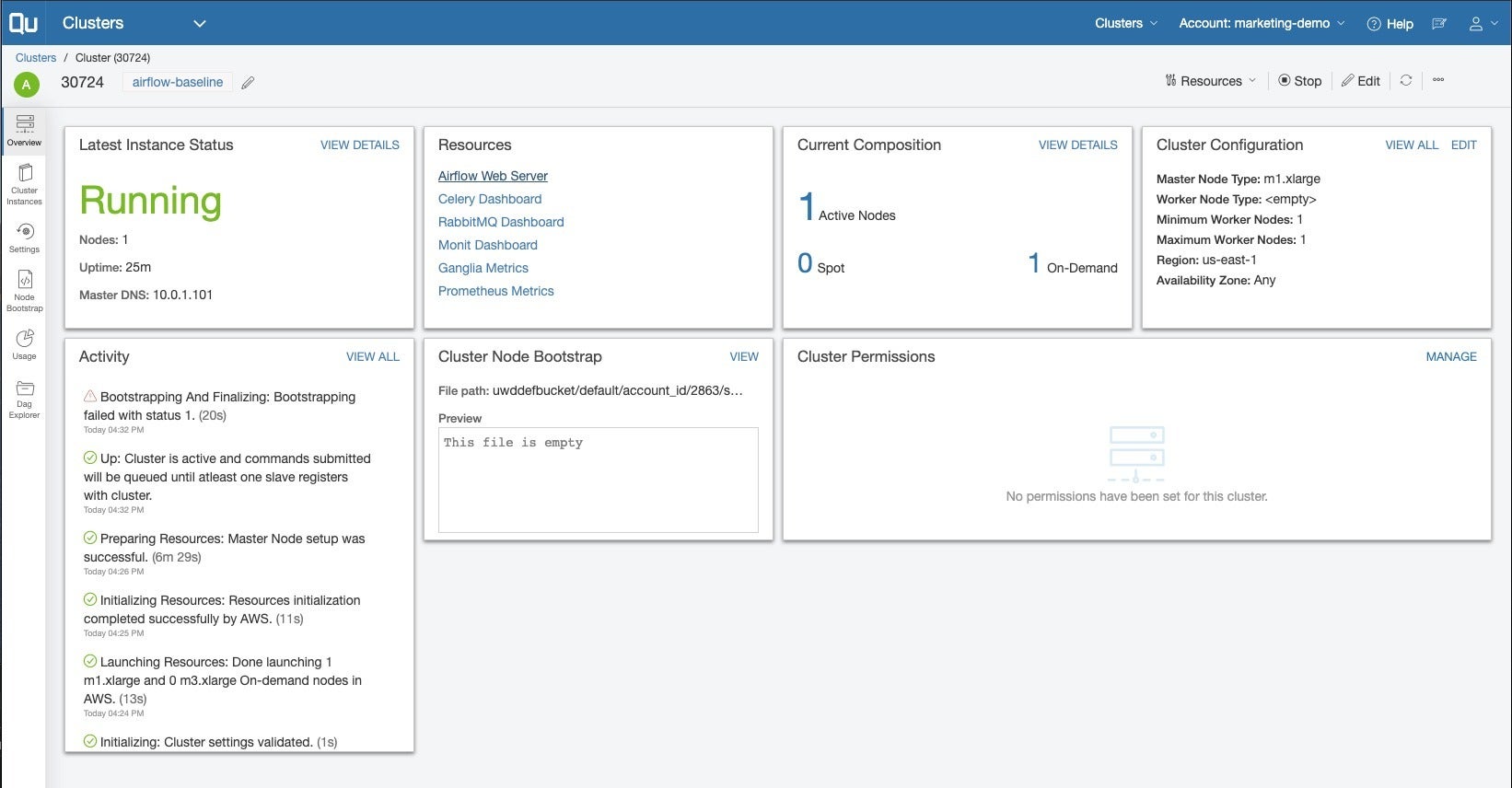
气流群集的概述页面。 可以通过资源框中的“ Airflow Web服务器”链接访问Airflow的用户界面。 Airflow的集成并不像我们在Qubole的其他组件中看到的那样紧密。
 IDG
IDG
气流代码是用Python编写的。 此Airflow DAG再现了与之前在手动Hive和Presto步骤以及在使用Spark的Zeppelin笔记本电脑中运行的工作流程相同的工作流程。 第19行的配置安排DAG每天运行。 请注意,每个动作的内容都包含在HQL脚本中,并且DAG大量使用QuboleOperator模块。
 IDG
IDG
可以使用多种表示形式查看Airflow DAG。 在这里,我们在图形视图中看到了电子商务数据集的导入和分析。 请注意所有单元格的绿色轮廓,表明它们已成功运行。
 IDG
IDG
树视图是查看气流DAG的另一种方法。 请注意,在此视图中,流程或多或少从右到左,从下到上运行,并且状态颜色应用于右侧的框。 这个特定的DAG从第9行的起始圆开始,向上和向左移动,但在两个连接步骤中向下和向外拆分。
Qubole的深度学习
我们已经看到Qubole中的数据科学达到了经典机器学习的水平,但是深度学习又如何呢? 在Qubole中完成深度学习的一种方法是在笔记本中插入Python步骤,以导入诸如TensorFlow之类的深度学习框架,并将其用于Spark已经设计的数据集。 另一个假设您的Qubole安装在AWS上运行,则从笔记本或Airflow调出Amazon SageMaker 。
您在Qubole中所做的大多数事情都不需要在GPU上运行,但是深度学习通常确实需要GPU,以允许训练在合理的时间内完成。 Amazon SageMaker通过在单独的集群中运行深度学习步骤来解决此问题,您可以根据需要配置这些集群中的节点和GPU。 Qubole还提供了机器学习集群(测试版); 在AWS上,它们允许使用Nvidia GPU加速g型和p型工作器节点;在Google Cloud Platform和Microsoft Azure上,它们允许等效的加速工作器节点。
云中的大数据工具包
Qubole是用于分析和机器学习的云原生数据平台,可帮助您将数据集导入数据湖,使用Hive构建架构以及使用Hive,Presto,Quantum和Spark查询数据。 它同时使用笔记本电脑和Airflow来构建工作流程。 它还可以调出其他服务并使用其他库,例如Amazon SageMaker服务和TensorFlow Python库进行深度学习。
Qubole通过控制集群中实例的混合,按需启动和自动扩展集群以及在不使用集群时自动关闭集群,来帮助您管理云支出。 它运行在AWS,Microsoft Azure,Google Cloud Platform和Oracle Cloud上。
总体而言,Qubole是利用(或“激活”)数据湖,隔离的数据库和大数据的一种非常好的方法。 您可以选择带有示例数据的AWS,Azure或GCP, 免费试用14天的Qubole驱动器 。 您还可以使用自己的云基础架构帐户和自己的数据为最多五个用户和一个月安排一次免费的功能齐全的试用版。
-
费用:免费提供测试和试用帐户。 企业平台,每个QCU(Qubole计算单元)每小时$ 0.14。
平台: Amazon Web Services,Google Cloud Platform,Microsoft Azure,Oracle Cloud。
翻译自: https://www.infoworld.com/article/3449896/qubole-review-self-service-big-data-analytics.html
自助式分析大数据















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









