





建立机器学习模型是一个重复的过程。 这通常是死记硬背,是“循环中最快的胜利”游戏,因为您可以越快地进行迭代,就越容易探索新的理论并获得良好的答案。 这就是当今实际的企业使用AI由大型企业主导的原因之一,而大型企业可能会为此投入大量资源。
Rapids是由Nvidia孵化的几个开源项目的保护伞,该项目将整个处理流程放在GPU上,消除了I / O绑定的数据传输,同时还大大提高了每个步骤的速度。 它还为数据提供了一种通用格式,从而减轻了在不同系统之间交换数据的负担。 在用户级别,Rapids模仿了Python API,以简化该用户群的过渡。
 Tidyverse食谱
Tidyverse食谱
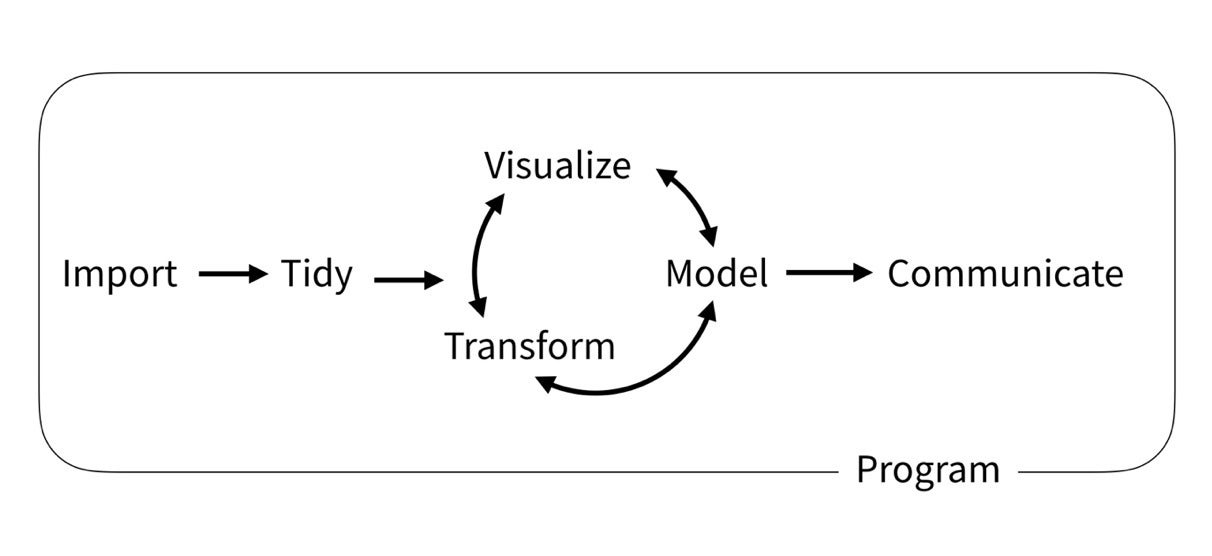
典型的机器学习工作流程
急流生态系统架构
Rapids项目旨在在很大程度上复制Python的机器学习和数据分析API,但复制的是GPU,而不是CPU。 这意味着Python开发人员已经拥有了在GPU上运行所需的一切,而无需了解CUDA编程和并行操作的底层细节。 Pythonista的开发人员可以在未启用GPU的计算机上开发代码,然后进行一些调整,即可在所有可用的GPU上运行它们。
[ 也在InfoWorld上:用于AI开发的6种最佳编程语言 ]
Nvidia CUDA工具包为数学库,并行算法和图形分析提供了较低级别的原语。 该架构的核心是基于Apache Arrow的GPU数据帧,该数据帧提供了与编程语言无关的列式内存数据结构。 用户通过cuDF和类似Pandas的API与GPU数据框进行交互。 Dask是用于并行计算的Python库,它模仿上游Python API并与CUDA库一起用于并行计算。 将Dask视为适用于Python的Spark。
 快速
快速
急流生态系统架构
cuDF,cuML和cuGraph这三个主要项目是独立开发的,但设计为可无缝协同工作。 作为该项目的一部分,也正在开发到更广泛的Python生态系统的桥梁。
急流安装
在AWS的Linux机器上通过Anaconda进行的安装非常简单,由于0.11版中的依赖项发生了变化,因此造成了一些麻烦。 安装C / C ++库以使用libcudf并不是那么容易,我建议坚持使用Python API和Conda安装过程。 Rapids包含Jupyter笔记本,也可以在Google的免费Colab上获得,从而使入门变得简单。 我使用Jupyter笔记本0.10版在Google Colab上运行代码,其中包括Nvidia Tesla T4 GPU。
 IDG
IDG
Rapids的GPU数据框
数据框架是任何数据科学工作流程的核心。 这是发生功能工程的地方,并且是花费大量时间的地方,因为数据科学家会整理脏数据。 cuDF是Rapids项目,用于基于GPU的类似熊猫的数据框。 cuDF的基础是libcudf,它是一个C ++库,实现用于导入Apache Arrow数据的低级基元,在数组上执行逐元素的数学运算以及对GPU内内存矩阵执行排序,联接,分组,归约及其他操作。 libcudf的基本数据结构是GPU数据框(GDF),该数据框又以Apache Arrow的列式数据存储为模型。
 快速
快速
cuDF技术栈
Rapids Python库为用户提供了类似于数据框的高级界面,例如Pandas中的数据框。 在许多情况下,Pandas代码在cuDF上保持不变。 如果不是这种情况,通常只需要进行较小的更改。
[ 也在InfoWorld上:深度学习与机器学习:了解差异 ]
cuDF中的用户定义函数
结束基本数据操作后,有时有时需要使用用户定义的函数(UDF)处理行和列。 cuDF提供了PyData样式的API,可以编写代码来处理更多的过程粒度数据结构,例如数组,序列和移动窗口。 当前仅支持数字和布尔类型。 使用Numba JIT编译器编译UDF,该编译器使用LLVM的子集将数字函数编译为CUDA机器代码。 这样可以大大加快GPU的运行时间。
cuDF中的字符串
尽管GPU非常适合快速处理浮点向量,但通常不会将它们用于处理字符串数据,而现实情况是,大多数数据都是以字符串形式出现的。 cuStrings是一个GPU字符串处理库,用于在字符串数组中拆分,应用正则表达式,连接,替换标记等。 与cuDF的其他功能一样,它是作为C / C ++库(libnvStrings)实现的,并由旨在模仿熊猫的Python层包装。 尽管未针对在GPU上执行优化字符串数据类型,但代码的并行执行应提供比基于CPU的字符串处理更快的速度。
从cuDF进出数据
数据帧I / O由专用库cuIO处理。 支持所有最常见的格式,包括Arrow,ORC,Parquet,HDF5和CSV。 如果您有幸在DGX-2硬件上运行,可以使用GPU Direct Storage集成将数据直接从高速存储移动到GPU,而无需使用CPU。 至关重要的用户仍将欣赏GPU在解压缩大型数据集时所提供的加速以及与Python生态系统的紧密集成。
GPU Direct Storage目前处于测试阶段,发布后将在大多数Tesla GPU上提供。 您可以只用一行代码就可以从NumPy数组,Pandas DataFrames和PyArrow表创建GPU数据框。 其他项目可以通过__cuda_array_interface__与Numba生态系统内的库交换数据。 用于神经网络库的DLPack也是受支持的接口。
使用cuDF的最大缺点可能是Python外部缺乏互操作性。 我认为,像Arrow所做的那样,专注于C / C ++ API的强大基础将能够建立更广阔的生态系统并使整个项目受益。
拉皮兹的cuML
cuML的既定目标是成为“由GPU支持的Python Scikit学习”。 从理论上讲,这意味着您只需要更改import语句,并可能需要调整一些参数来解决在CPU上运行时的差异,在这种情况下,有时使用蛮力方法会更好。 很难低估基于GPU的Scikit学习的好处。 加速是巨大的,数据分析师的生产率可以提高很多倍。 C ++ API尚未准备好在其Python绑定之外进行广泛使用,但这有望改善。
cuML还包括用于通过Dask帮助超参数调整的API,Dask是一个用于在多个节点之间扩展Python的库。 许多机器学习算法可以有效地并行化,并且cuML正在积极开发多GPU和多节点,多GPU算法。
 快速
快速
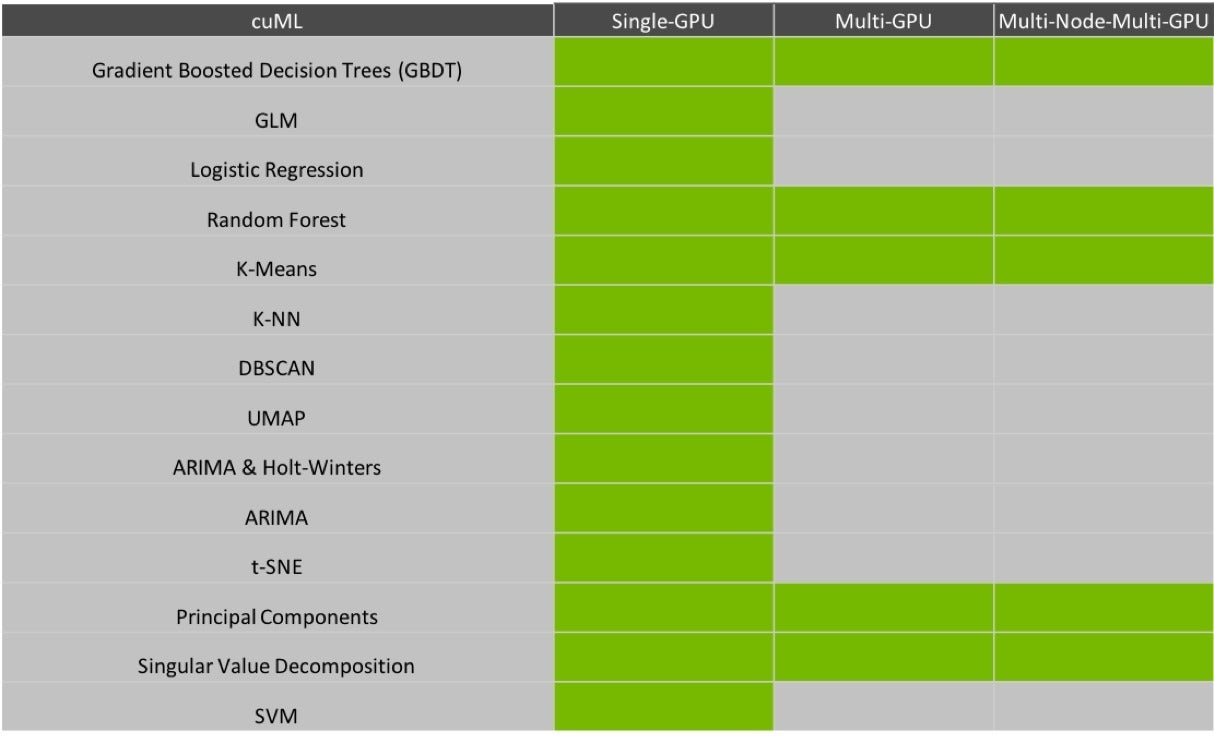
cuML算法
[ 也在InfoWorld上:2020年的人工智能预测 ]
拉皮兹的cuGraph
cuGraph是Rapids生态系统的第三个成员,与其他人一样,cuGraph与cuDF和cuML完全集成。 它提供了图形算法,基元和实用程序的良好选择,所有这些都具有GPU加速的性能。 在cuGraph中,API的选择比Rapids的其他部分更为广泛,它们都可以使用NetworkX,Pregel,GraphBLAS和GQL(图形查询语言)。
 快速
快速
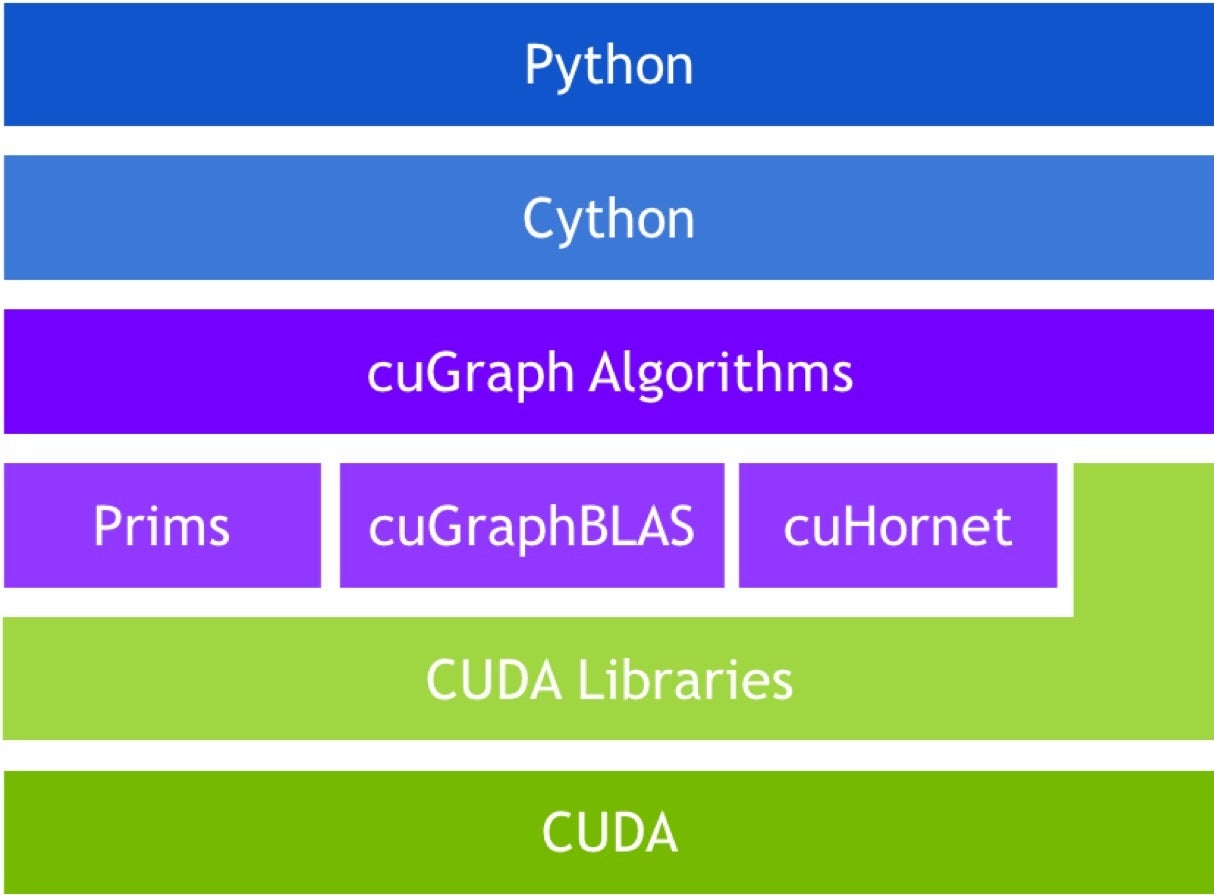
cuGraph堆栈
cuGraph在本质上更像是一个工具包,而不是cuML。 图形技术在学术界和工业界都是一个快速发展的空间。 因此,通过设计,cuGraph使开发人员可以访问C ++层和图基元,从而鼓励第三方使用cuGraph开发产品。 几所大学做出了贡献,得克萨斯州A&M(GraphBLAS),佐治亚理工学院(Hornet)和加州大学戴维斯分校(Gunrock)的项目已经“产品化”,并归类于cuGraph。 每个项目提供一组不同的功能,所有功能都由GPU加速,并且都由相同的cuDF数据帧支持。
NetworkX是Rapids团队针对其本机界面使用的Python API。 通过该接口可以使用多种算法。 尽管只有页面排名是多GPU,但团队仍在积极开发其他版本的多GPU版本。
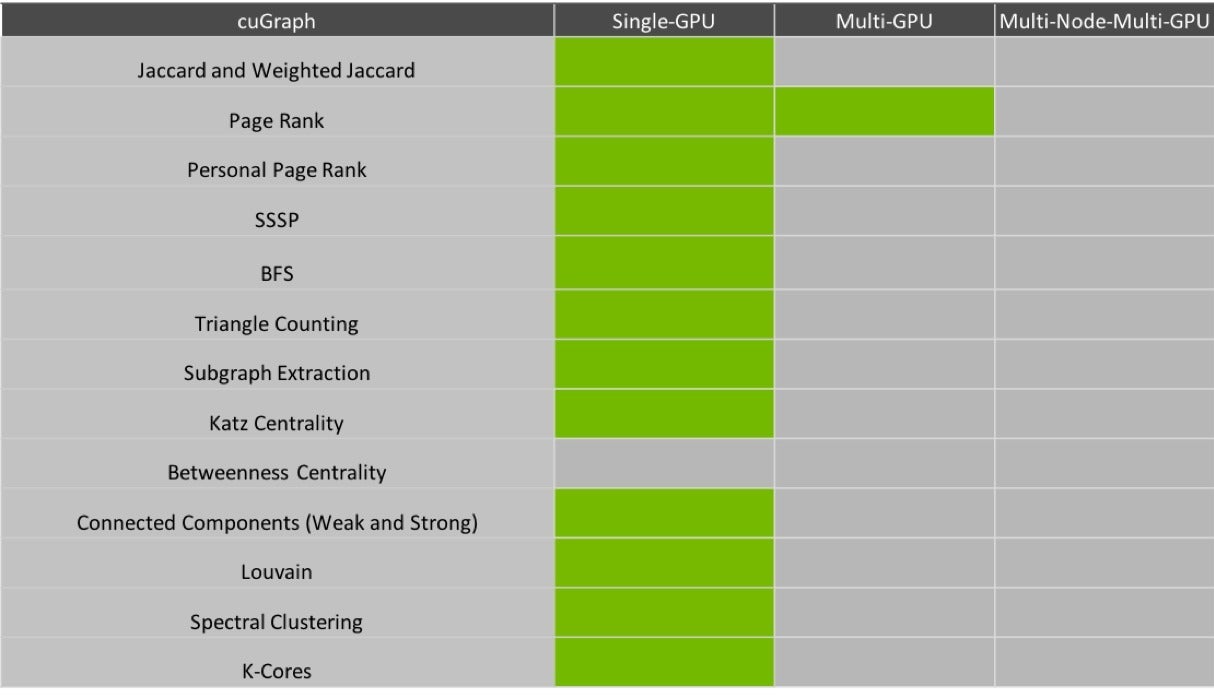 快速
快速
cuGraph算法
我发现有趣的cuGraph子项目之一是cugraphBLAS,它致力于以线性代数的语言标准化图算法的构件。 基于GraphBLAS( graphblas.org ),这是一种用于稀疏动态图处理的自定义数据结构。
Hornet的另一个cuGraph子项目,Hornet提供了一种包含图形数据的独立于系统的格式,类似于Apache arrow提供了一种独立于系统的方式处理数据框的方式。 Hornet支持大多数流行的图形格式,包括SNAP,mtx,metis和edge。
为了与接近Python社区的精神保持一致,Python的本机NetworkX包可用于研究复杂的网络。 这包括使用CUDA原语重新实现的图形和多图形的数据结构,使您可以重用许多标准图形算法并执行网络结构和分析措施。 大多数算法都是单GPU,例如NetworkX。 尽管如此,仅在GPU上运行它们就能显着提高速度,而工作仍在继续转向多GPU实施。
[ 同样在InfoWorld上:什么是CUDA? GPU的并行编程 ]
在急流路线图上
鉴于基于GPU的分析提供了巨大的速度,因此在将来的版本中将引入一些新项目。
DLPack和array_interface用于深度学习
多层神经网络是移至GPU的首批工作负载之一,针对该机器学习用例存在大量的代码体。 以前,DLPack是深度学习库之间数据交换的实际标准。 如今,通常支持array_interface。 急流都支持。
cuSignal
像Rapids的其他大多数项目一样,cuSignal是现有Python库(在本例中为SciPy Signal库)的GPU加速版本。 原始的SciPy信号库基于NumPy,已由其GPU加速的cuSignal中的CuPy取代。 这是Rapids设计理念在工作中的一个很好的例子。 除了少数自定义CUDA内核外,GPU的端口主要涉及替换import语句和调整一些功能参数。
将信号处理引入Rapids部门是明智之举。 信号处理无处不在,在工业和国防领域具有许多立即有用的商业应用。
空间
时空操作是GPU加速的理想选择,它们可以解决我们在日常生活中面临的许多现实问题,例如分析交通模式,土壤健康/质量和洪水风险。 移动设备(包括无人机)收集的许多数据都具有地理空间成分,而空间分析是智慧城市的核心。
与其他组件一样,cuSpatial也是一个基于CUDA原语和Thrust矢量处理库构建的C ++库,使用cuDF进行数据交换。 C ++库的使用者可以使用C ++阅读器读取点,折线和面数据。 Python用户最好使用Shapely或Fiona之类的现有Python包来填充NumPy数组,然后使用cuSpatial Python API或转换为cuDF数据帧。
用于数据可视化的cuxfilter
数据的可视化对于分析工作流以及呈现或报告结果都是至关重要的。 然而,尽管GPU可以处理数据本身的所有魔力,将数据发送到浏览器并不是一件容易的事。 受Crossfilter JavaScript库启发的cuxfilter旨在通过提供一个堆栈来弥合差距,以使第三方可视化库能够显示cuDF数据帧中的数据。
随着团队挑选出最佳的架构和连接器模式,cuxfilter进行了几次迭代。 最新的迭代利用了Jupyter笔记本电脑,Bokeh服务器和PyViz面板,而集成实验包括来自Uber,Falcon和PyDeck的项目。 该组件尚未准备就绪,但准备在Rapids 0.13中发布。 有很多活动部件,我没有亲身尝试它,但是,如果它能如期实现,那将是Rapids工具包的一个重要补充。
[ 同样在InfoWorld上:选择PyTorch进行深度学习的5个理由 ]
使用Dask扩展和扩展
Dask是Python的分布式任务调度程序,在Python中的作用类似于Apache Spark在Scala中发挥的作用。 Dask-cuDF是一个库,提供分区的,GPU支持的数据帧。 当您计划使用cuML或正在加载大于GPU内存或分布在多个文件中的数据集时,Dask-cuDF效果很好。
就像Spark RDD(弹性分布式数据集)一样,Dask-cuDF分布式数据帧的行为几乎与本地一样,因此您可以尝试使用本地计算机并在需要扩展时迁移到分布式模型。 Dask-cuML提供了cuML多节点功能,当您没有DGX工作站的预算时,它是一个不错的选择。















 1376
1376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









