






- 实验目的
• 1、理解无监督学习中NMF降维算法原理;
• 2、掌握Sklearn实现基于NMF方法及应用;
• 3、对比PCA和NMF两种方法,并进行总结。
- 实验内容与要求
- 非负矩阵分解
非负矩阵分解(Non-negative Matrix Factorization,NMF)是在矩阵中所有元素均为非负数约束条件之下的矩阵分解方法。基本思想是给定一个非负矩阵V,NMF能够找到一个非负矩阵和一个非负矩阵H,使得矩阵W和H的乘积近似等于矩阵V中的值。
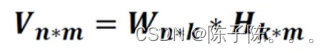
·W矩阵:基础图像矩阵,相当于从原矩阵V中抽取出来的特征
·H矩阵:系数矩阵
·NMF能够广泛应用于图像分析、文本挖掘和语音处理等领域。
- 矩阵分解优化
矩阵分解优化目标: 最小化W矩阵H矩阵的乘积和原始矩阵之间的差别,目标函数如下:

3、sklearn中非负矩阵分解:
在sklearn库中,可以使用sklearn.decomposition.NMF加载NMF算法,主要参数有
·n_components: 用于指定分解后矩阵的单个维度k;
·init: W矩阵和H矩阵的初始化方式,默认为'nndsvdar'
4、NMF人脸数据特征提取:
目标:已知Olivetti人脸数据共400个,每个数据是64*64大小。由于NMF分解得到的W矩阵相当于从原始矩阵中提取的特征,那么就可以使用NMF对400个人脸数据进行特征提取。通过设置k的大小,设置提取的特征的数目。在本实验中设置k=6随后将提取的特征以图像的形式展示出来。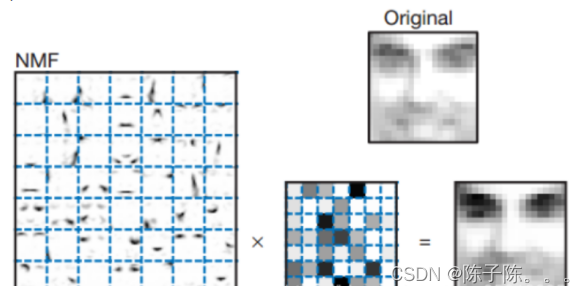
- 实验程序与结果
import matplotlib.pyplot as plt
from sklearn import decomposition
from sklearn.datasets import fetch_olivetti_faces
from numpy.random import RandomState
# 设置图像展示时的排列情况,2行3列
n_row, n_col = 2, 3
# 设置提取的特征的数目
n_components = n_row * n_col
# 设置人脸数据图片的大小
image_shape = (64, 64)
# 加载人脸数据集
dataset = fetch_olivetti_faces(shuffle=True, random_state=RandomState(0))
faces = dataset.data # 加载数据,并打乱顺序
# 设置图像的展示方式
def plot_gallery(title, images, n_col=n_col, n_row=n_row):
plt.figure(figsize=(2. * n_col, 2.26 * n_row)) # 创建图片,并指定大小
plt.suptitle(title, size=16) # 设置标题及字号大小
for i, comp in enumerate(images):
plt.subplot(n_row, n_col, i + 1) # 选择画制的子图
vmax = max(comp.max(), -comp.min())
plt.imshow(comp.reshape(image_shape), cmap=plt.cm.gray, interpolation='nearest', vmin=-vmax, vmax=vmax) # 对数值归一化,并以灰度图形式显示
plt.xticks(())
plt.yticks(()) # 去除子图的坐标轴标签
plt.subplots_adjust(0.01, 0.05, 0.99, 0.93, 0.04, 0.)
# 创建特征提取的对象NMF和PCA
estimators = [
('Eigenfaces - PCA using randomized SVD', decomposition.PCA(n_components=n_components, whiten=True)),
('Non-negative components - NMF', decomposition.NMF(n_components=n_components, init='nndsvda', tol=5e-3))
]
# 降维后数据点的可视化
for name, estimator in estimators:
estimator.fit(faces) # 调用PCA或NMF提取特征
components_ = estimator.components_ # 获取提取特征
plot_gallery(name, components_[:n_components]) # 按照固定格式进行排列
plt.show() # 可视化
四、实验结果分析

在此实验我使用PCA和NMF对Olivetti人脸数据集进行了特征提取,特征提取后,将特征展示为图像,上图分别展示了使用PCA和NMF提取的特征图像。
(1)PCA(主成分分析):
PCA是一种线性降维技术,主要通过选择主要特征(主成分)来降低数据维度。提取的特征图像(称为Eigenfaces)包含了一些全局结构,显示出面部的整体轮廓和大体特征。这些特征包含了最大方差的数据,因此能够很好地表示数据的整体信息。
(2)NMF(非负矩阵分解):
NMF是一种基于非负约束的降维方法,通过将数据分解为两个非负矩阵的乘积来提取特征。提取的特征图像更加局部化,显示出面部的具体部位,如眼睛、鼻子、嘴巴等。NMF的非负约束使得特征更加具有可解释性,能分解出局部的面部特征。
PCA和NMF的不同之处:
·PCA提取的特征是全局的,包含了最大方差的信息,因此能够很好地表示整体结构,PCA提取的特征展示了面部的整体轮廓,能捕捉到最大方差的信息。
·NMF提取的特征是局部的,非负约束使得其特征更具可解释性,NMF提取的特征展示了面部的局部特征,能够具体分解出眼睛、鼻子、嘴巴等具体部位,特征更加具体。
五、实验问题解答与体会
通过本实验,我清晰地看到了不同特征提取方法的效果差异。PCA由于其线性降维的特性,更适合捕捉全局信息,而NMF由于其非负约束,更适合分解出局部特征。在实际应用中,可以根据具体需求选择合适的特征提取方法。例如,在人脸识别中,如果需要整体特征,可以选择PCA;如果需要具体部位的特征,可以选择NMF。















 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









