







索引
说明主要用于自我复习 不足之处还请见谅
常见字符串函数
1,strlen
size_t strlen ( const char * str );
字符串已经 ‘\0’ 作为结束标志,strlen函数返回的是在字符串中 ‘\0’ 前面出现的字符个数(不包含 ‘\0’ )。
参数指向的字符串必须要以 ‘\0’ 结束。
注意函数的返回值为size_t,是无符号的( 易错 )
2, strcpy
char* strcpy(char * destination, const char * source );
源字符串必须以 ‘\0’ 结束。
会将源字符串中的 ‘\0’ 拷贝到目标空间。
目标空间必须足够大,以确保能存放源字符串。
目标空间必须可变
3,strcat
将原来的字符串添加到目标字符串后面并且新的字符串以\0结尾
源字符串必须有’\0’;
4,strcmp
比较字符串主要就是根据字典序进行排序
5,strstr
char * strstr ( const char *str1, const char * str2);
返回str2在str1中出现的第一个地址,如果str1中不存在str2那么便返回NULL
memcpy与memmove
void * memcpy ( void * destination, const void * source, size_t num );
函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。这个函数在遇到 ‘\0’ 的时候并不会停下来。
如果source和destination有任何的重叠,复制的结果都是未定义的
void * memmove ( void * destination, const void * source, size_t num );
和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。如果源空间和目标空间出现重叠,就得使用memmove函数处理
例如假设有一个数组a,如果是memcpy(a,a+3)的话那么这个操作是未被定义的,具体的复制方式以及复制能否成功主要还是看编译器是否支持。但是如果使用memmove确实可以直接使用的
memcpy模拟实现
由于不知道复制的类型,所以我们模拟的时候都是先将指针强制转换成char*然后再解引用
void* my_memcpy(const void* e1, const void* e2,size_t num)
{
assert(e1 && e2);
void* ret = e1;
while (num--)
{
*(char*)e1 = *(char*)e2;
e1 = (char*)e1+1;
e2 = (char*)e2+1;
}
return ret;
}
memmove函数的模拟实现
void* my_memmove(const void* e1, const void* e2,size_t num)
{
assert(e1 && e2);
void* ret = e1;//待会要返回的就是ret;
if (e1 > e2)//如果e1>e2那么就是从e2从后开始往前拷贝
//因为这样才不会覆盖
//否则从前开始拷贝
{
e1 = (char*)e1 + num - 1;
e2 = (char*)e2 + num - 1;
while (num--)
{
*(char*)e1 = *(char*)e2;
e1 = (char*)e1 - 1;
e2 = (char*)e2 - 1;
}
}
else
{
while (num--)
{
*(char*)e1 = *(char*)e2;
e1 = (char*)e1+1;
e2 = (char*)e2+1;
}
}
return ret;
}
qsort函数的简单模拟实现
void qsort( void *base, size_t num, size_t width, int (__cdecl *compare )(const void *elem1, const void *elem2 ) );
bace:表示需要排序数组的起始地址
num:表示一共需要排序的元素个数
width:表示需要排序的元素字节大小
最后一个参数是比较函数
我使用的是冒泡函数进行模拟的。
普通版冒泡排序
void bubble_sort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
for(int j = 0;j<n-1-i;j++)
{
if (a[j] > a[j + 1])
Swap(&a[j + 1], &a[j]);
}
}
}
其实我们可以发现,不管什么排序,排序的大致步骤是不变的,变化的就是比较的方式以及交换的方式也就是
if (a[j] > a[j + 1])
Swap(&a[j + 1], &a[j]);
然后想办法替换掉这两句代码但是作用不变就可以了
由于事先并不知道需要排序的类型,所以都是用char*进行强制类型转换
//大致框架是没变的,主要是比较的方式变化了,然后交换的方式也变了
//if (a[j] > a[j + 1])
//Swap(&a[j + 1], &a[j]);
if (compare((char*)bace + j * width, (char*)bace + (j + 1) * width)>0)
{
//交换两个元素此时传进去的是两个地址
Swap_sort((char*)bace + j * width, (char*)bace + (j + 1) * width,width);//一定要传width否则不知道
//具体交换多少个字节
全部代码:
void bubble_sort(void* bace, int n, int width, int(*compare)(const void* e1, const void* e2))
{
for (int i = 0; i < n - 1; i++)
{
for(int j = 0;j<n-1-i;j++)
{
//大致框架是没变的,主要是比较的方式变化了,然后交换的方式也变了
//if (a[j] > a[j + 1])
//Swap(&a[j + 1], &a[j]);
if (compare((char*)bace + j * width, (char*)bace + (j + 1) * width)>0)
{
//交换两个元素此时传进去的是两个地址
Swap_sort((char*)bace + j * width, (char*)bace + (j + 1) * width,width);//一定要传width否则不知道
//具体交换多少个字节
}
}
}
}
注 如果要使用qsort这个库函数的时候,compare我们自己写的时候要注意参数一定得是void,否则会报错
当比较的数是int时
int compare_int(const void* e1, const void* e2)
{
return *(int*)e1 - *(int*)e2;
}
当比较的数是字符串时
int compare_by_str(const void* e1, const void* e2)
{
return strcmp(((struct Stu*)e1)->name, ((struct Stu*)e2)->name);
}
结构体面试题之为什么要结构体对齐
struct Test
{
int a;
char b;
char c;
};
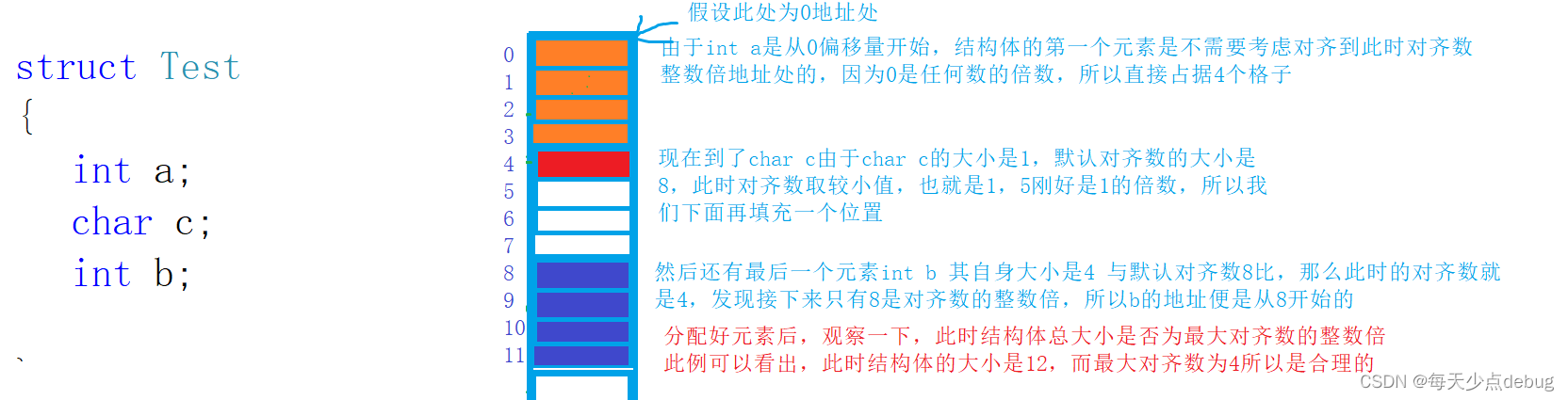
如果没有内存对齐,那么结构体大小就是4+1+4 = 9但是我把他放在vs编译器上测试发现大小是12。内存如何对齐?为什么要对齐?
1,结构体内存对齐的规则
- 第一个成员在与结构体变量偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
VS中默认的值为8(Linux环境下没有默认对齐数) - 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
为什么存在内存对齐
- 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 - 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问
总体来说:结构体的内存对齐是拿空间来换取时间的做法
所以在设计结构体的时候,我们既要满足对齐,又要节省空间,我们应当让
占用空间小的成员尽量集中在一起
修改默认对齐数
#pragma pack(X)//设置默认对齐数为X
struct S2
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
位段
C语言允许在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为“位段”或称“位域”( bit field) 。利用位段能够用较少的位数存储数据。
1.位段的成员必须是 int、unsigned int 或signed int 。
2.位段的成员名后边有一个冒号和一个数字
数字表示占有几个比特位
1,位段的内存分配
在window环境下的VS编译器下:
位段先开辟四个字节还是一个字节是根据首个位段成员类型开辟的,如果首个成员是int 那么便开辟四个字节,然后根据成员自身大小填充已经分配的空间,下一个位段成员观察此时剩余空间大小是否够容纳自己,如果能,则继续填充,如果不能的话,直接与初始一样,开辟新的空间(注意假设开辟新空间是要求内存对齐的)直到该位段的最后一个成员,需要注意的是,整个位段的大小是成员类型大小中最大值的整数倍。
先看一个例子
[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imblo.sdnjIpVimg.cn/14379e46ttps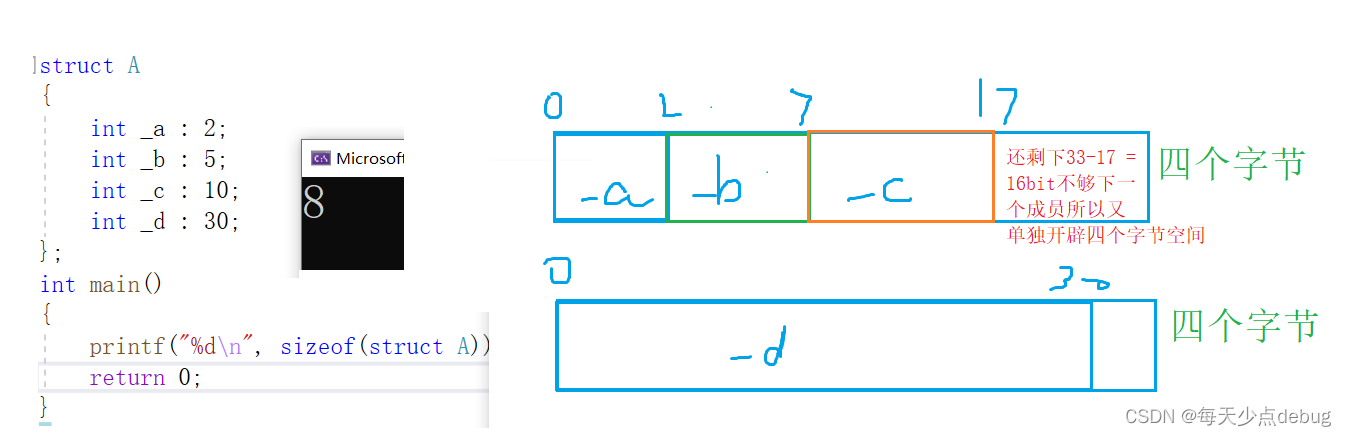 ]
]
db454549b69f1558ea20c05e.png)注在开辟新的空间之前一定要考虑是否内存对齐,上述例子刚好开辟下一个空间时恰好内存对齐
具体空间开辟
我的一个问题
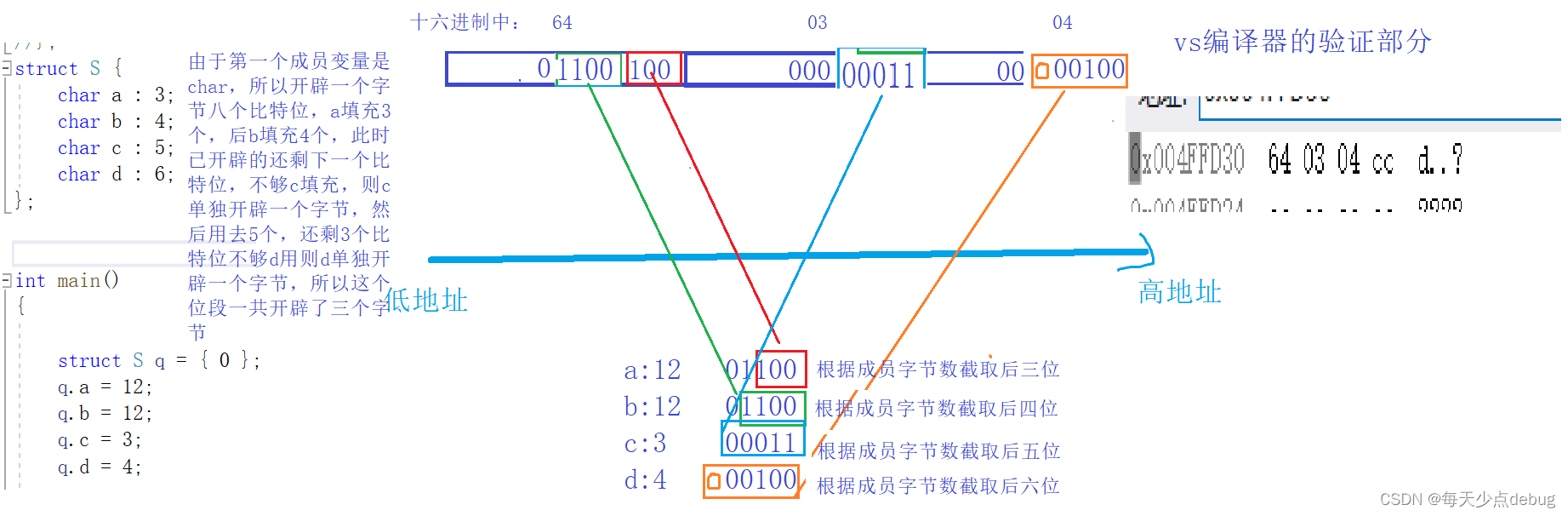
struct A
{
int _a : 3;
char _b : 5;
int _c : 2;
char _d : 7;
};
有一个位段是这样的,如果按照上述规则的计算此位段的大小应该是4但是我用vs编译器发现是16个字节然后我将
struct A
{
int _a : 3;
int _b : 5;
int _c : 2;
char _d : 7;
};
第二个元素类型变成int此时计算位段的大小又会是8个字节,我不免产生疑惑了,为什么会这样?难道是遇到不同类型变量空间直接不管剩下的空间是否满足填充,都要重新开辟空间吗(开辟空间还是满足内存对齐)?我至今不太理解,这个问题我解决了就会更新,要是有大佬看到了就更完美了hh
位段存在的跨平台问题
位段在不同的平台上有不同的规则:
1、int 位段被当成有符号数还是无符号数是不确定的。
2、位段中的成员从左到右分配还是从右到左分配是不确定的。
3、当一个结构包含两个位段,第二个位段成员比较大,无法容纳第一个位段剩余的位时,是舍弃剩余的位还是利用,也是不确定的。
所以跟结构体相比,位段更节省空间,但是有跨平台的问题。
枚举的优点
enum Day//星期
{
Mon,
Tues,
Wed,
};
enum Day是枚举类型
{}中的内容是枚举类型的 可能取值也叫做枚举常量
这些取值默认是从0开始的依次递增1,也可以在最初定义的时候就赋值
eg
enum Day//星期
{
Mon,
Tues,
Wed,
Thur = 80,
};
- 增加代码的可读性和可维护性
- 和#define定义的标识符比较枚举有类型检查,更加严谨。
- 防止了命名污染(封装)
- 便于调试
- 使用方便,一次可以定义多个常量
联合体
多个成员共同使用同一快空间,但是每次使用变量只能使用一个,联合体的大小 至少是最大成员的大小。
当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
联合体内的成员是共用一块空间的,如果改变其中一块也是会间接改变另外一个成员变量值的,因为他们是公用一块空间
给一个例子证明一下这个

联合体空间的大小最大成员大小不是最大对齐数的整数倍的时候
eg
union Un1
{
char c[5];
int i;
};
因为此时数组c的大小是5,而此时结构体中的最大对齐数是4,所以要内存对齐,此时该联合体的总大小应该是最大对齐数的整数倍.
















 2671
2671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











