






 本文探讨了在AI绘画中确保人脸一致性的问题,介绍了LORA模型的不同实现方式,如固定Seed、roop插件、训练模型等,以及ControlNet的Referenceonly方法。作者通过实例展示了如何通过调整模型权重和预处理来达到人脸一致的效果,并对未来AIGC技术的发展前景进行了展望。
本文探讨了在AI绘画中确保人脸一致性的问题,介绍了LORA模型的不同实现方式,如固定Seed、roop插件、训练模型等,以及ControlNet的Referenceonly方法。作者通过实例展示了如何通过调整模型权重和预处理来达到人脸一致的效果,并对未来AIGC技术的发展前景进行了展望。
大家好,我是程序员晓晓。
在AI绘画中,一直都有一个比较困难的问题,就是如何保证每次出图都是同一个人。今天就这个问题分享一些个人实践,大家和我一起来看看吧。
一. 有哪些实现方式
方式1:固定Seed种子值。
固定Seed种子值出来的图片人物确实可以做到一致,但Seed种子值是相对整个画面的,导致这种方式生成的新图片效果差别太小,可能除了人物的脸保存了一致,人物的姿势也保持了一致,甚至画面的背景也保持了一致,出来的图片太过单调。
此时我们虽然可以通过ContolNet来控制人物的姿势,但是效果并不可控。
方式2:使用roop插件
roop插件是我们常见的换脸插件,将生成的图片中人物都使用一张人脸图片去替换,可以很好地做到图片中人脸一致。关于使用roop插件实现换脸可以参考我之前的文章
方式3:针对多张真人照片训练LORA模型
LORA模型可以固定人物特征、动作特征和照片风格。同一个人物的多张真人照片去炼丹训练LORA模型需要一定的技术基础,而且调优费事费力,对很多人来说也不太现实。
方式4:直接利用已有的人物LORA模型
直接使用C站提供的LORA模型,我们也可以生成人脸基本一致的图片。这里的基本一致,不能百分百一致。因为每个人物Lora的训练数据集不一定很全面,主要包括数量、质量、角度等因素不同,出的图很难保证人脸完全一致。
方式5:使用ControlNet预处理Reference only
下面我们重点看一下方式4和方式5,尤其是方式5,是目前实现人脸一致效果的最好方式,不仅适用于人,而且还适用于动物,二次元。
二. LORA模型实现人脸一致的效果
01、LORA模型cuteGirlMix4
我们先通过一个实例看看如何通过LORA实现人脸一致效果。
大模型:majicmixRealistic_v6.safetensors
正向提示词:a beautiful girl, very delicate features, very detailed eyes and mouth, long hair, delicate skin, big eyes,red sweater, necklace,standing in the classroom, upper body photos,best quality, ultra-detailed, masterpiece, finely detail, highres, 8k wallpaper,lora:cuteGirlMix4\_v10:1
反向提示词:(worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((grayscale)), bad anatomy,DeepNegative, skin spots, acnes, skin blemishes,(fat:1.2),facing away, looking away,tilted head, lowres,bad anatomy,bad hands, missing fingers,extra digit, fewer digits,bad feet,poorly drawn hands,poorly drawn face,mutation,deformed,extra fingers,extra limbs,extra arms,extra legs,malformed limbs,fused fingers,too many fingers,long neck,cross-eyed,mutated hands,polar lowres,bad body,bad proportions,gross proportions,missing arms,missing legs,extra digit, extra arms, extra leg, extra foot,teethcroppe,signature, watermark, username,blurry,cropped,jpeg artifacts,text,error
LORA模型cuteGirlMix4权重设置为1。
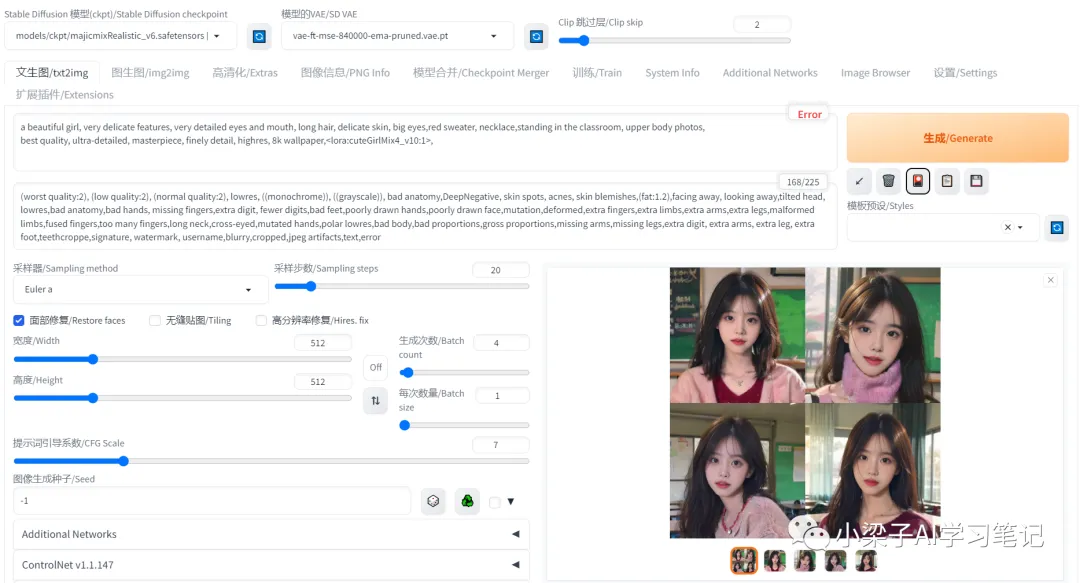

我这里将LORA模型cuteGirlMix4调整到0.6,我们再看一下效果。

4张美女的脸差别有些明显了。
关于LORA模型cuteGirlMix4,官网推荐搭配的模型是Chilloutmix。它的训练集来自国外抖音(tiktok)网红,而不是任何特定的真人,权重建议值是0.4-0.7。我们看到当权重设置为1时,人物的效果还是比较好。
可见,将LORA模型cuteGirlMix4的权重设置为1,可以基本实现人脸的一致。
02、LORA模型chinese-girl
LORA模型chinese-girl是从微博/小红书等网站找到的100+张时尚/穿搭博主的图片制成的lora。建议LORA模型权重小于0.8,采样器为DPM++ SDE karras , 采样迭代步数为25。
我们仍然以上面大模型和提示词为例来看一下效果。
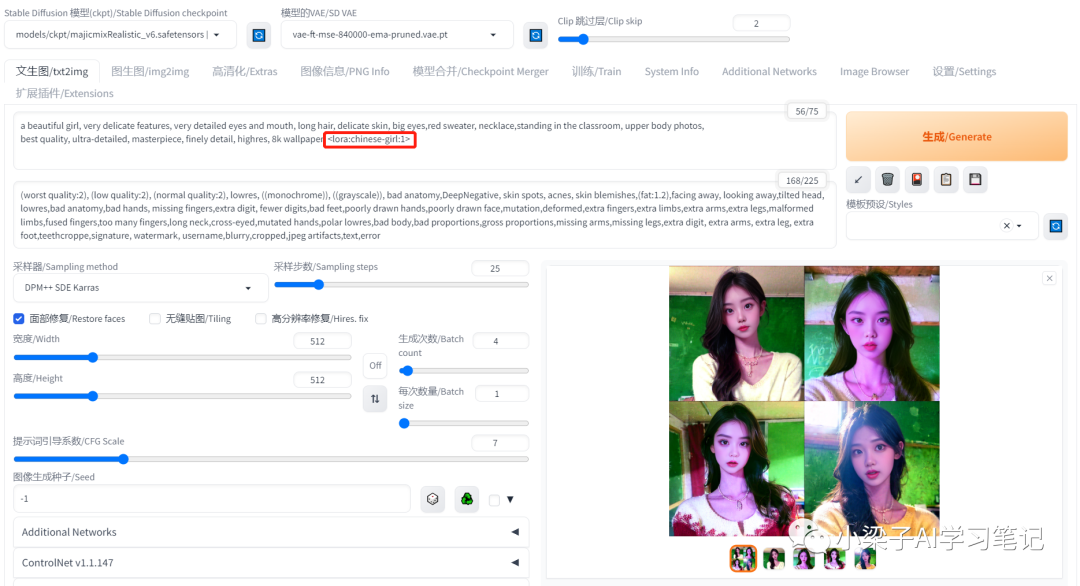

将LORA模型chinese-girl的权重设置成1,生成的图片效果明显不太好。并且将LORA的权重设置为1,美女的脸看起来还是不一样。从图中可以看到只是人脸的轮廓保持了一致。
将LORA模型chinese-girl的权重设置成0.6。

生成图片的效果好很多了,但是4张美女的人脸也不一致了。
从上面我们可以看到:
(1)针对某些人物的LORA,将权重设置为1,可以基本实现人脸一致的效果。
(2)某些人物的LORA建议值范围都小于1,将权重设置为1,生成的图片效果会失真。这样的LORA无法实现人脸一致的效果。
(3)将人物LORA的权重设置小于1,一般无法实现人脸一致的效果。
既然很多人物的LORA权重设置要求小于1,那么我们使用多个LORA,保证多个LORA的权重值之和为1,是否就可以实现人脸一致的效果呢?
例如你拥有60%的LORA A模型特征,20%的LORA B模型特征,20%的LORA C模型特征。这个时候使用如果要实现人脸一致的话,难度相当高。因为这涉及到3个不同的LORA模型的融合,需要大量的生成图片,抽签找到两张脸一样的照片。
大模型:majicmixRealistic_v6.safetensors
正向提示词:a beautiful girl, very delicate features, very detailed eyes and mouth, long hair, delicate skin, big eyes,red sweater, necklace,standing in the classroom, upper body photos,best quality, ultra-detailed, masterpiece, finely detail, highres, 8k wallpaper, lora:cuteGirlMix4\_v10:0.6,lora:koreanDollLikeness\_v10:0.2 ,lora:chilloutmixss30\_v30:0.2

三. 使用ControlNet预处理Reference only实现人脸一致
Reference only是今年5月份ControlNet重大更新中推出的新功能。它不需要任何控制模型即可实现直接使用一张图片作为参考来引导扩散。
我们来使用看一下效果。
大模型:majicmixRealistic_v6.safetensors
正向提示词:a beautiful girl, very delicate features, very detailed eyes and mouth, long hair, delicate skin, big eyes,red sweater, necklace,standing in the classroom, upper body photos,best quality, ultra-detailed, masterpiece, finely detail, highres, 8k wallpaper, lora:cuteGirlMix4\_v10:0.6
采样器:DPM++ SDE Karras
采样迭代步数:28
生成的图片效果如下:

我们使用这张图作为底图,使用ControlNet的预处理
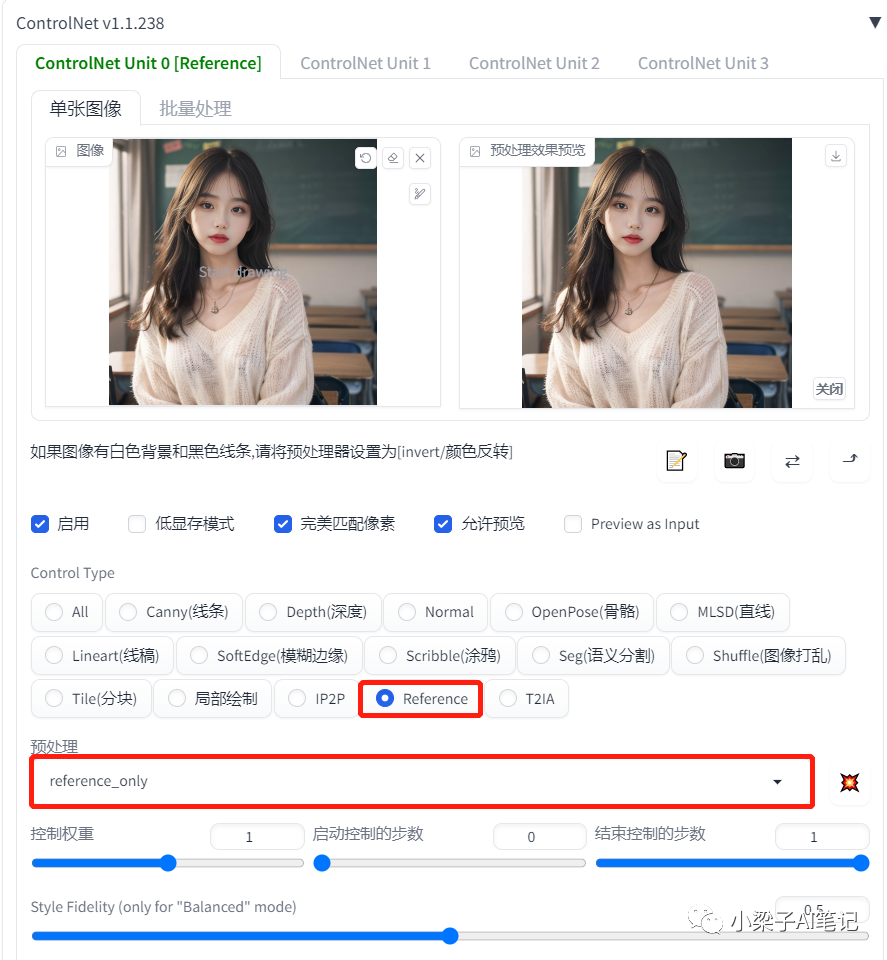
我们修改一下正向提示词:将背景换为海边,衣服换为皮夹克。
a beautiful girl, very delicate features, very detailed eyes and mouth, long hair, delicate skin, big eyes**,leather jacket,necklace, standing by the sea, upper body photos,best quality, ultra-detailed, masterpiece, finely detail, highres, 8k wallpaper,
生成图片的效果如下:

我们修改一下大模型,改变一下画面风格,例如换成anything-v4.5-pruned-fp16.ckpt,提示词和参数设置都保持不变。我们看一下生成图片的效果。

我们再看一个实例:一只奔跑的狗
大模型:majicmixRealistic_v6.safetensors
正向提示词:best quality, ultra-detailed, masterpiece, finely detail, highres, 8k wallpaper,a running dog
采样器:DPM++ SDE Karras
采样迭代步数:28
生成的图片效果如下:

我们使用这张图作为底图,使用ControlNet的预处理。
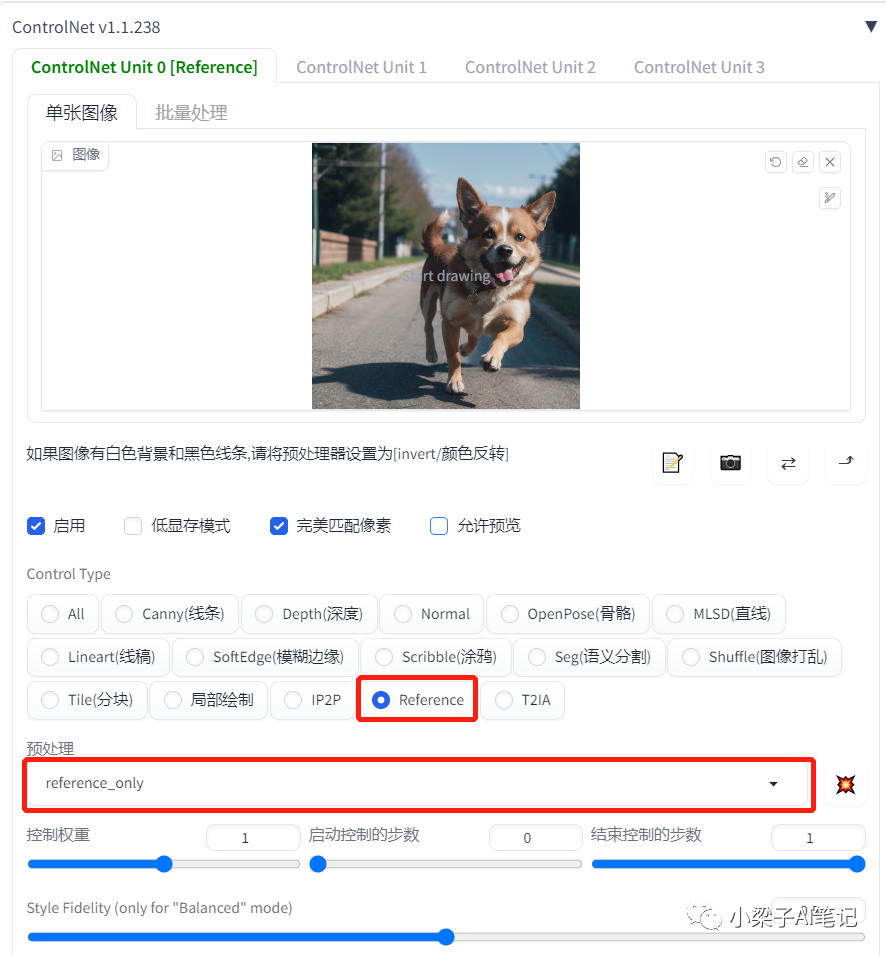
重新生成效果如下:

通过上面的实例,可以看到通过使用ControlNet的预处理reference-only实现人物(动物)的一致效果还是相当不错的。然后我们再通过背景的改变,实现同一个人物在不同场景下的图片效果了。
好了,今天的分享就到这里了,实现人脸一致的效果一直都是非常困难的问题,不管是SD工具,在MD上面也是一样,对于这类问题大家可以多思考,多研究,多实践,对于我们能力的提升还是非常有帮助的。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









