2025年Java面试行情呈现出“高需求、高竞争、高技能门槛”的特点,具体分析如下:
一、市场需求与岗位分布
1. 岗位数量庞大
Java开发岗位在北上广深等一线城市日增数千个,二线城市需求也显著增长。
企业级系统(如金融、电商、政务平台)、大数据(Hadoop/Spark生态)、物联网(智能家居、车载系统)等领域仍是Java的主战场。
- 金融、电信等传统行业依赖Java构建高并发系统,新兴领域如云原生、AI和工业互联网也在拓展Java的应用边界。
2. 技能分层明显
初级岗位趋于饱和,企业更倾向招聘具备2-3年经验的中高级开发者,要求熟练掌握Spring全家桶、微服务架构、分布式系统设计等核心技术。部分企业对全栈能力(如前端框架React/Vue)和新兴技术(如Docker/K8s、Flink)的需求显著增加。
二、薪资水平与地域差异
1. 一线城市薪资领先
- 北京、上海Java开发平均月薪达19.9K,资深架构师可达30-50K;大数据岗位平均薪资22.7K,部分头部企业校招起薪20-25K。
- 杭州、成都等新一线城市,3年经验开发者薪资普遍15-20K,全栈或架构师可达20K+。
2. 经验决定天花板
应届生起薪8-12K(二线城市),5年以上经验架构师跳槽涨薪30%以上,金融领域架构师年薪可达50W+。
三、技术趋势与面试要求
1. 核心技术栈深度
必考框架:Spring全家桶(Spring Boot 3.x与Java 17+深度整合)、MyBatis、分布式事务(如Seata)。
高频考点:JVM调优、多线程并发、MySQL索引优化、Redis高可用方案。
2. 新兴技术加分项
云原生(Serverless、Service Mesh)、实时数仓(Flink)、AI工具(如飞算JavaAI自动化生成代码)成为竞争力提升的关键。
熟悉GraalVM、Quarkus等轻量级框架的开发者更受青睐。
四、面试挑战与应对策略
1. 面试难度升级
企业更看重**实战经验**,要求能独立完成电商、医疗等真实项目,并解决性能优化、高并发场景问题。
八股文(如JVM内存模型、设计模式)需结合项目案例回答,避免纯理论背诵。
2. 常见面试题型
- 基础题:Java集合框架、多线程同步机制、JVM垃圾回收算法。
- 场景题:设计秒杀系统、分布式ID生成方案、SQL慢查询优化。
- 行为题:团队协作经验、技术选型逻辑、职业规划。
五、给求职者的建议
1. 技能提升路径
基础扎实:掌握Java核心语法、设计模式,每日坚持代码实践。
项目为王:通过GitHub开源项目或培训机构实战(如网时代教育的电商系统)积累经验。
技术拓展:学习前端基础、容器化技术、大数据工具链,提升全栈能力。
2. 面试准备技巧
模拟面试:针对高频题(如Spring循环依赖、Redis缓存穿透)反复演练。
利用AI工具:如飞算JavaAI辅助需求分析和代码生成,提升开发效率。
2025年Java岗位虽竞争激烈,但市场需求持续旺盛,技术扎实、项目经验丰富的开发者仍能获得高薪机会。建议结合企业需求动态调整技能树,并善用AI工具提升竞争力。
Java面试题整理
本Java面试题收集了Java相关技术栈的面试题,旨在帮助大家找到心仪的工作。内容大部分来自互联网进行整 理汇总。 另外打铁还需自身硬,希望通过这个手册能够帮助大家查漏补缺。
如果你是初学者希望这个手册可以给你提供一个相对完善的学习路径,如果你是工作多年的程序员,希 望这个手册可以让你重温核心知识点。
整理不易,目前全手册共计
24万
字。
Java相关

44.
反射机制的优缺点:
优点:
1
、
能够运行时动态获取类的实例,提高灵活性;
2
、
与动态编译结合
缺点:
1
、
使用反射性能较低,需要解析字节码,将内存中的对象进行解析。
解决方案:
1
、通过
setAccessible(true)
关闭
JDK
的安全检查来提升反射速度;
2
、多次创建一个类的实例时,有缓存会快很多
3
、
ReflectASM
工具类,通过字节码生成的方式加快反射速度
2
、
相对不安全,破坏了封装性(因为通过反射可以获得私有方法和属性)
45. Java
中
IO
流分为几种
?
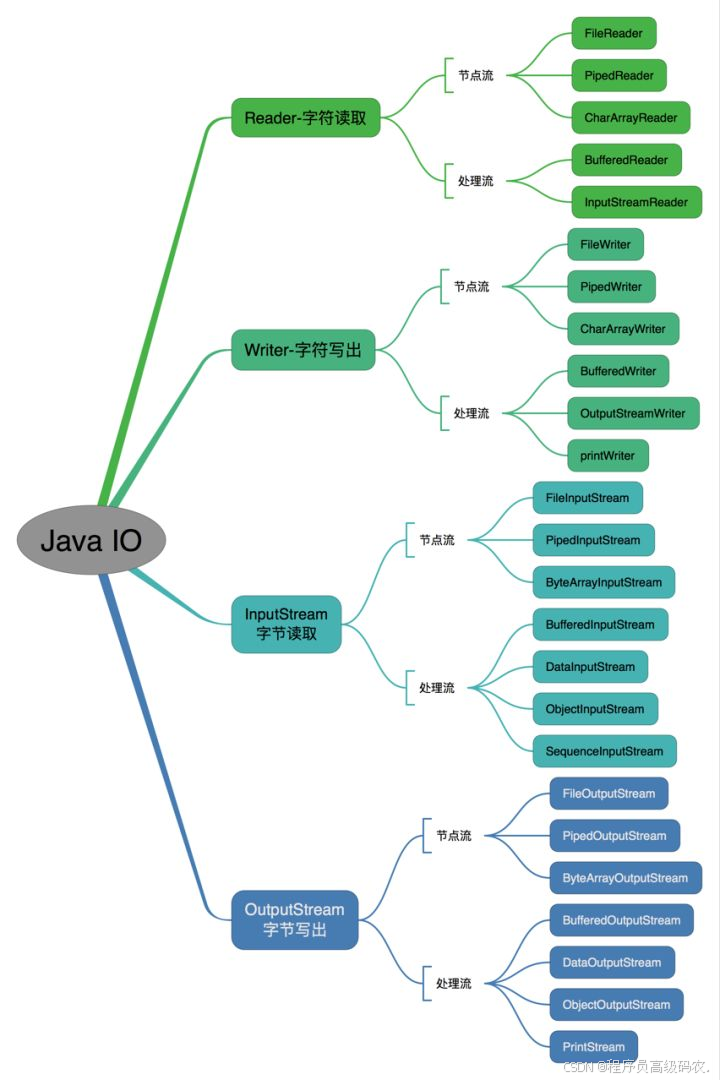
按照流的流向分,可以分为输入流和输出流;
按照操作单元划分,可以划分为字节流和字符流;
按照流的角色划分为节点流和处理流。
Java Io
流共涉及
40
多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的
联系,
Java I0
流的
40
多个类都是从如下
4
个抽象类基类中派生出来的。
InputStream/Reader:
所有的输入流的基类,前者是字节输入流,后者是字符输入流。
OutputStream/Writer:
所有输出流的基类,前者是字节输出流,后者是字符输出流。
按操作方式分类结构图:
Java并发编程

78. Hashtable
的
size()
方法中明明只有一条语句
"return count"
,
为什么还要做同步?
这是我之前的一个困惑,不知道大家有没有想过这个问题。某个方法中如果有多条语句,并且都在操作 同一个类变量,那么在多线程环境下不加锁,势必会引发线程安全问题,这很好理解,但是
size()方法明 明只有一条语句,为什么还要加锁?
关于这个问题,在慢慢地工作、学习中,有了理解,主要原因有两点:
1
、同一时间只能有一条线程执行固定类的同步方法,但是对于类的非同步方法,可以多条线程同时访 问。所以,这样就有问题了,可能线程
A
在执行
Hashtable
的
put
方法添加数据,线程
B则可以正常调用 size()
方法读取
Hashtable
中当前元素的个数,那读取到的值可能不是最新的,可能线程
A添加了完了数 据,但是没有对
size++
,线程
B
就已经读取
size
了,那么对于线程
B
来说读取到的
size
一定是不准确的。
而给
size()
方法加了同步之后,意味着线程
B
调用
size()
方法只有在线程
A
调用
put方法完毕之后才可以调 用,这样就保证了线程安全性
2
、
CPU
执行代码,执行的不是
Java
代码,这点很关键,一定得记住。
Java代码最终是被翻译成机器码执 行的,机器码才是真正可以和硬件电路交互的代码。即使你看到
Java
代码只有一行,甚至你看到
Java代 码编译之后生成的字节码也只有一行,也不意味着对于底层来说这句语句的操作只有一个。一句"return count"假设被翻译成了三句汇编语句执行,一句汇编语句和其机器码做对应,完全可能执行完第一句, 线程就切换了。
79. Linux
环境下如何查找哪个线程使用
CPU
最长
这是一个比较偏实践的问题,这种问题我觉得挺有意义的。可以这么做:
1
、
获取项目的
pid
,
jps
或者
ps -ef | grep java
,这个前面有讲过
2
、
top -H -p pid
,顺序不能改变
这样就可以打印出当前的项目,每条线程占用
CPU
时间的百分比。注意这里打出的是
LWP,也就是操作 系统原生线程的线程号,我笔记本山没有部署
Linux
环境下的
Java工程,因此没有办法截图演示,网友朋 友们如果公司是使用
Linux
环境部署项目的话,可以尝试一下。
使用
"top -H -p pid"+"jps pid"
可以很容易地找到某条占用
CPU
高的线程的线程堆栈,从而定位占用CPU 高的原因,一般是因为不当的代码操作导致了死循环。
最后提一点,
"top -H -p pid"
打出来的
LWP
是十进制的,
"jps pid"打出来的本地线程号是十六进制的,转 换一下,就能定位到占用
CPU
高的线程的当前线程堆栈了。
JVM面试题

55. invokedynamic
指令是干什么的?
属于比较高级的题目。没看过虚拟机的一般是不知道的。所以如果你不太熟悉,不要气馁,加油!(小 拳拳锤你胸口)。
invokedynamic
是
Java7之后新加入的字节码指令,使用它可以实现一些动态类型语言的功能。我们使用 的
Lambda
表达式,在字节码上就是
invokedynamic指令实现的。它的功能有点类似反射,但它是使用 方法句柄实现的,执行效率更高。
56. safepoint
是什么?
STW
并不会只发生在内存回收的时候。现在程序员这么卷,碰到几次
safepoint的问题几率也是比较大 的。
当发生
GC
时,用户线程必须全部停下来,才可以进行垃圾回收,这个状态我们可以认为
JVM是安全的 (safe),整个堆的状态是稳定的。
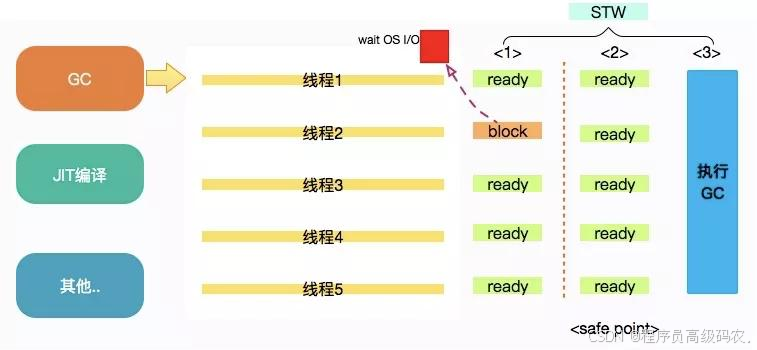
如果在
GC
前,有线程迟迟进入不了
safepoint
,那么整个
JVM
都在等待这个阻塞的线程,造成了整体GC 的时间变长。
数据结构与算法

55.
基数排序
基数排序又是一种和前面排序方式不同的排序方式,基数排序不需要进行记录关键字之间的比较。基数 排序是一种借助多关键字排序思想对单逻辑关键字进行排序的方法。所谓的多关键字排序就是有多个优 先级不同的关键字。比如说成绩的排序,如果两个人总分相同,则语文高的排在前面,语文成绩也相同 则数学高的排在前面。。。如果对数字进行排序,那么个位、十位、百位就是不同优先级的关键字,如 果要进行升序排序,那么个位、十位、百位优先级一次增加。基数排序是通过多次的收分配和收集来实 现的,关键字优先级低的先进行分配和收集。
实现代码:
public class
RadixSort
{
public static
void
radixSort
(
int
[]
arr
) {
if
(
arr
==
null
&&
arr
.
length
==
0
)
return
;
int
maxBit
=
getMaxBit
(
arr
);
for
(
int
i
=
1
;
i
<=
maxBit
;
i
++
) {
List
<
List
<
Integer
>>
buf
=
distribute
(
arr
,
i
);
//
分配
collecte
(
arr
,
buf
);
//
收集
}
}
/**
*
分配
* @param arr
待分配数组
* @param iBit
要分配第几位
* @return
*/
public static
List
<
List
<
Integer
>>
distribute
(
int
[]
arr
,
int
iBit
) {
List
<
List
<
Integer
>>
buf
=
new
ArrayList
<
List
<
Integer
>>
();
for
(
int
j
=
0
;
j
<
10
;
j
++
) {
buf
.
add
(
new
LinkedList
<
Integer
>
());
}
for
(
int
i
=
0
;
i
<
arr
.
length
;
i
++
) {
buf
.
get
(
getNBit
(
arr
[
i
],
iBit
)).
add
(
arr
[
i
]);
}
return
buf
;
}
/**
*
收集
* @param arr
把分配的数据收集到
arr
中
* @param buf
*/
public static
void
collecte
(
int
[]
arr
,
List
<
List
<
Integer
>>
buf
) {
int
k
=
0
;
for
(
List
<
Integer
>
bucket
:
buf
) {
for
(
int
ele
:
bucket
) {
arr
[
k
++
]
=
ele
;
}
}
}
/**
*
获取最大位数
* @param x
* @return
*/
public static
int
getMaxBit
(
int
[]
arr
) {
int
max
=
Integer
.
MIN_VALUE
;
for
(
int
ele
:
arr
) {
int
len
=
(
ele
+
""
).
length
();
if
(
len
>
max
)
max
=
len
;
}
return
max
;
}
/**
*
获取
x
的第
n
位,如果没有则为
0.
* @param x
* @param n
* @return
*/
public static
int
getNBit
(
int
x
,
int
n
) {
String
sx
=
x
+
""
;
if
(
sx
.
length
()
<
n
)
return
0
;
else
return
sx
.
charAt
(
sx
.
length
()
-
n
)
-
'0'
;
}
}
###
56.
排序算法的各自的使用场景和适用场合。
1. 从平均时间来看,快速排序是效率最高的,但快速排序在最坏情况下的时间性能不如堆排序和归并 排序。而后者相比较的结果是,在
n
较大时归并排序使用时间较少,但使用辅助空间较多。
2. 上面说的简单排序包括除希尔排序之外的所有冒泡排序、插入排序、简单选择排序。其中直接插入 排序最简单,但序列基本有序或者
n较小时,直接插入排序是好的方法,因此常将它和其他的排序 方法,如快速排序、归并排序等结合在一起使用。
3.
基数排序的时间复杂度也可以写成
O(d*n)
。因此它最使用于n值很大而关键字较小的的序列。若关 键字也很大,而序列中大多数记录的最高关键字均不同,则亦可先按最高关键字不同,将序列分成 若干小的子序列,而后进行直接插入排序。
4.
从方法的稳定性来比较,基数排序是稳定的内排方法,所有时间复杂度为O(n^2)的简单排序也是稳 定的。但是快速排序、堆排序、希尔排序等时间性能较好的排序方法都是不稳定的。稳定性需要根 据具体需求选择。
5. 上面的算法实现大多数是使用线性存储结构,像插入排序这种算法用链表实现更好,省去了移动元 素的时间。具体的存储结构在具体的实现版本中也是不同的。
附:基于比较排序算法时间下限为
O(nlogn)
的证明:
基于比较排序下限的证明是通过决策树证明的,决策树的高度
Ω(nlgn),这样就得出了比较排序的下 限。
首先要引入决策树。 首先决策树是一颗二叉树,每个节点表示元素之间一组可能的排序,它予以京进行 的比较相一致,比较的结果是树的边。 先来说明一些二叉树的性质,令
T
是深度为
d
的二叉树,则
T最多 有
2^
片树叶。 具有
L
片树叶的二叉树的深度至少是
logL
。 所以,对
n
个元素排序的决策树必然有
n!片树叶 (因为
n
个数有
n!
种不同的大小关系),所以决策树的深度至少是
log(n!)
,即至少需要log(n!)次比较。 而 log(n!)=logn+log(n-1)+log(n-2)+...+log2+log1 >=logn+log(n-1)+log(n-2)+...+log(n/2) >=(n/2)log(n/2) >=(n/2)logn-n/2 =O(nlogn)
所以只用到比较的排序算法最低时间复杂度是
O(nlogn)
。
网络协议面试题

48.
什么是
Session
session
是浏览器和服务器会话过程中,服务器会分配的一块储存空间给
session
。
服务器默认为客户浏览器的
cookie
中设置
sessionid
,这个
sessionid
就和
cookie对应,浏览器在向服务 器请求过程中传输的
cookie
包含
sessionid
,服务器根据传输
cookie
中的
sessionid 获取出会话中存储 的信息,然后确定会话的身份信息。
49. Cookie
和
Session
对于
HTTP
有什么用?
HTTP
协议本身是无法判断用户身份。所以需要
cookie
或者
session
50. Cookie
与
Session
区别
1
、
Cookie
数据存放在客户端上,安全性较差,
Session
数据放在服务器上,安全性相对更高
2
、
单个
cookie
保存的数据不能超过
4K
,
session
无此限制
3
、
session一定时间内保存在服务器上,当访问增多,占用服务器性能,考虑到服务器性能方面,应当 使用
cookie
。
数据库

81.
在
MongoDB
中如何排序
MongoDB
中的文档排序是通过
sort()
方法来实现的。
sort() 方法可以通过一些参数来指定要进行排序的 字段,并使用
1
和
-1
来指定排序方式,其中
1
表示升序,而
-1
表示降序。
>db.connectionName.find({key:value}).sort({columnName:1})
82.
什么是聚合
聚合操作能够处理数据记录并返回计算结果。聚合操作能将多个文档中的值组合起来,对成组数据执行 各种操作,返回单一的结果。它相当于
SQL
中的
count(*)
组合
group by
。对于
MongoDB 中的聚合操 作,应该使用
aggregate()
方法。
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
83.
在
MongoDB
中什么是副本集
在
MongoDB
中副本集由一组
MongoDB
实例组成,包括一个主节点多个次节点,
MongoDB客户端的所 有数据都写入主节点
(Primary),副节点从主节点同步写入数据,以保持所有复制集内存储相同的数据,提 高数据可用性。
框架相关面试题

微服务

30.
微服务是如何对外提供统一接口的
(zuul
具体使用
)
因为每一个微服务都是独立运行的,都有自己独立的IP和端口,而当他们需要统一对外提供服务这时候 就需要 SpringCloud
网关
zuul
网关也是
netflix
公司旗下的项目
使用它也很简单 在
pom
依赖中 引入 Spring-cloud-starter-netflix-zuul 在
SpringBoot
启动类中 开启 @EnableZuulProxy 然后在配置文件中定义 路由规则:
routes:
路由名称
:
path: /
映射路径
/**
serviceId: Eureka
中的服务名称
zuul
也提供了过滤器功能,如果要做一些
token
检查 或者 过滤时可以使用
用法 就是写一个类 继承
ZuulFilter
类
会要求我们实现几个方法
filterType:
过滤器什么时候执行
pre
前置
post
过程中
after
之后
shouldFilter:
过滤器是否执行 可以写判断方法 返回
boolean
值
true
执行,
false
不执行此过滤器
filterOrder:
过滤器的执行顺序 排序号
run:
具体过滤器的方法
31. Zuul
的过滤功能
如果说,路由功能是
Zuul
的基操的话,那么
过滤器
就是
Zuul
的利器了。毕竟所有请求都经过网关
(Zuul)
,那么我们可以进行各种过滤,这样我们就能实现
限流
,
灰度发布
,
权限控制
等等。
简单实现一个请求时间日志打印
要实现自己定义的
Filter
我们只需要继承
ZuulFilter
然后将这个过滤器类以
@Component
注解加
入
Spring
容器中就行了。
在给你们看代码之前我先给你们解释一下关于过滤器的一些注意点。
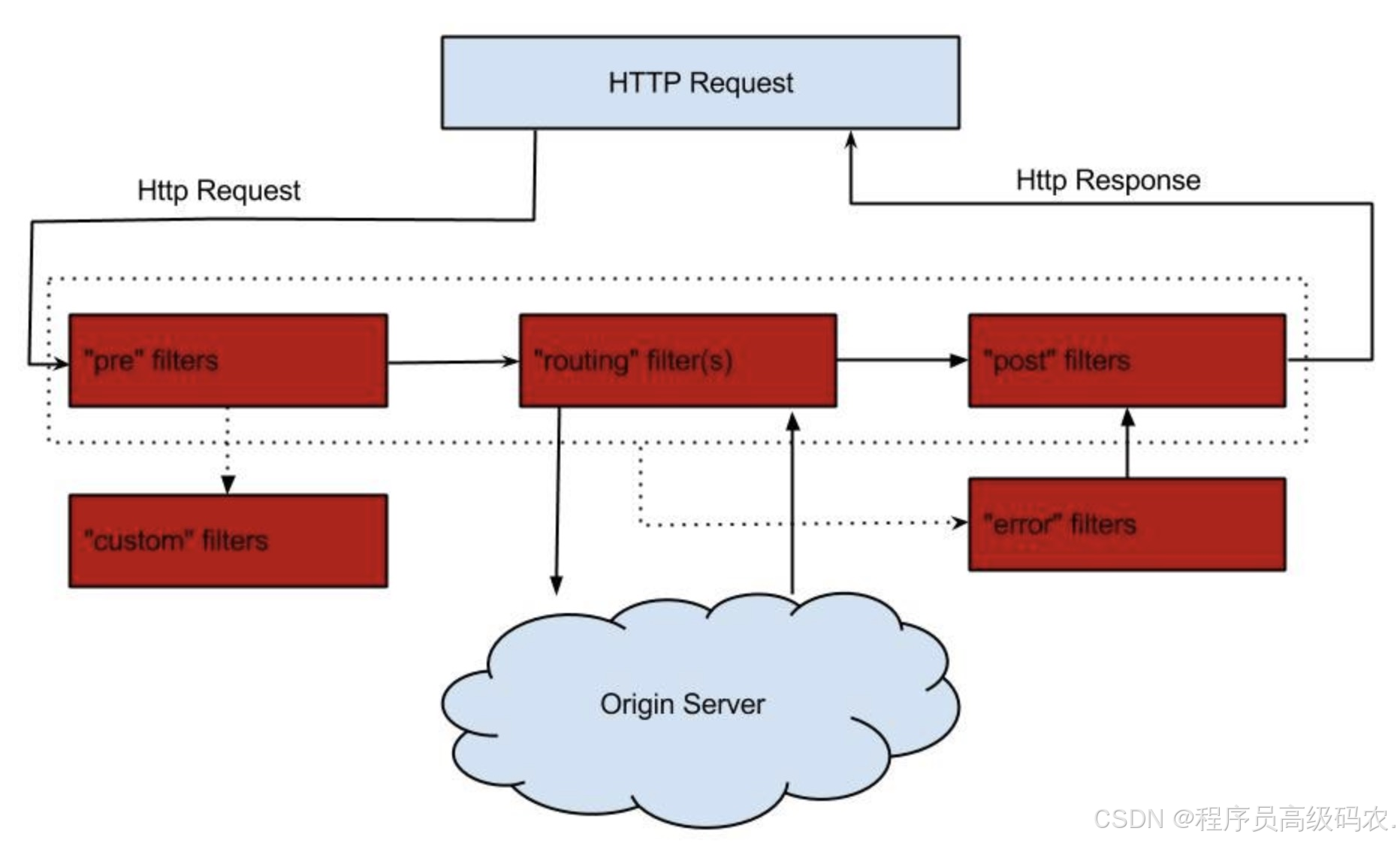
过滤器类型:
Pre
、
Routing
、
Post
。前置
Pre
就是在请求之前进行过滤,
Routing 路由过滤器就是 我们上面所讲的路由策略,而
Post
后置过滤器就是在
Response 之前进行过滤的过滤器。你可以观察 上图结合着理解,并且下面我会给出相应的注释。
//
加入
Spring
容器
@Component
public class
PreRequestFilter
extends
ZuulFilter
{
//
返回过滤器类型 这里是前置过滤器
@Override
public
String
filterType
() {
return
FilterConstants
.
PRE_TYPE
;
}
//
指定过滤顺序 越小越先执行,这里第一个执行
//
当然不是只真正第一个 在
Zuul
内置中有其他过滤器会先执行
//
那是写死的 比如
SERVLET_DETECTION_FILTER_ORDER = -3
@Override
public
int
filterOrder
() {
return
0
;
}
//
什么时候该进行过滤
//
这里我们可以进行一些判断,这样我们就可以过滤掉一些不符合规定的请求等等
@Override
public
boolean
shouldFilter
() {
return
true
;
}
//
如果过滤器允许通过则怎么进行处理
@Override
public
Object
run
()
throws
ZuulException
{
//
这里我设置了全局的
RequestContext
并记录了请求开始时间
RequestContext ctx
=
RequestContext
.
getCurrentContext
();
ctx
.
set
(
"startTime"
,
System
.
currentTimeMillis
());
return
null
;
}
}
// lombok
的日志
@Slf4j
//
加入
Spring
容器
@Component
public class
AccessLogFilter
extends
ZuulFilter
{
//
指定该过滤器的过滤类型
//
此时是后置过滤器
@Override
public
String
filterType
() {
return
FilterConstants
.
POST_TYPE
;
}
// SEND_RESPONSE_FILTER_ORDER
是最后一个过滤器
//
我们此过滤器在它之前执行
@Override
public
int
filterOrder
() {
return
FilterConstants
.
SEND_RESPONSE_FILTER_ORDER
-
1
;
}
@Override
public
boolean
shouldFilter
() {
return
true
;
}
//
过滤时执行的策略
@Override
public
Object
run
()
throws
ZuulException
{
RequestContext context
=
RequestContext
.
getCurrentContext
();
HttpServletRequest request
=
context
.
getRequest
();
//
从
RequestContext
获取原先的开始时间 并通过它计算整个时间间隔
Long
startTime
=
(
Long
)
context
.
get
(
"startTime"
);
//
这里我可以获取
HttpServletRequest
来获取
URI
并且打印出来
String
uri
=
request
.
getRequestURI
();
long
duration
=
System
.
currentTimeMillis
()
-
startTime
;
log
.
info
(
"uri: "
+
uri
+
", duration: "
+
duration
/
100
+
"ms"
);
return
null
;
}
}
上面就简单实现了请求时间日志打印功能,你有没有感受到
Zuul
过滤功能的强大了呢?
没有?好的、那我们再来。
令牌桶限流
当然不仅仅是令牌桶限流方式,
Zuul
只要是限流的活它都能干,这里我只是简单举个例子
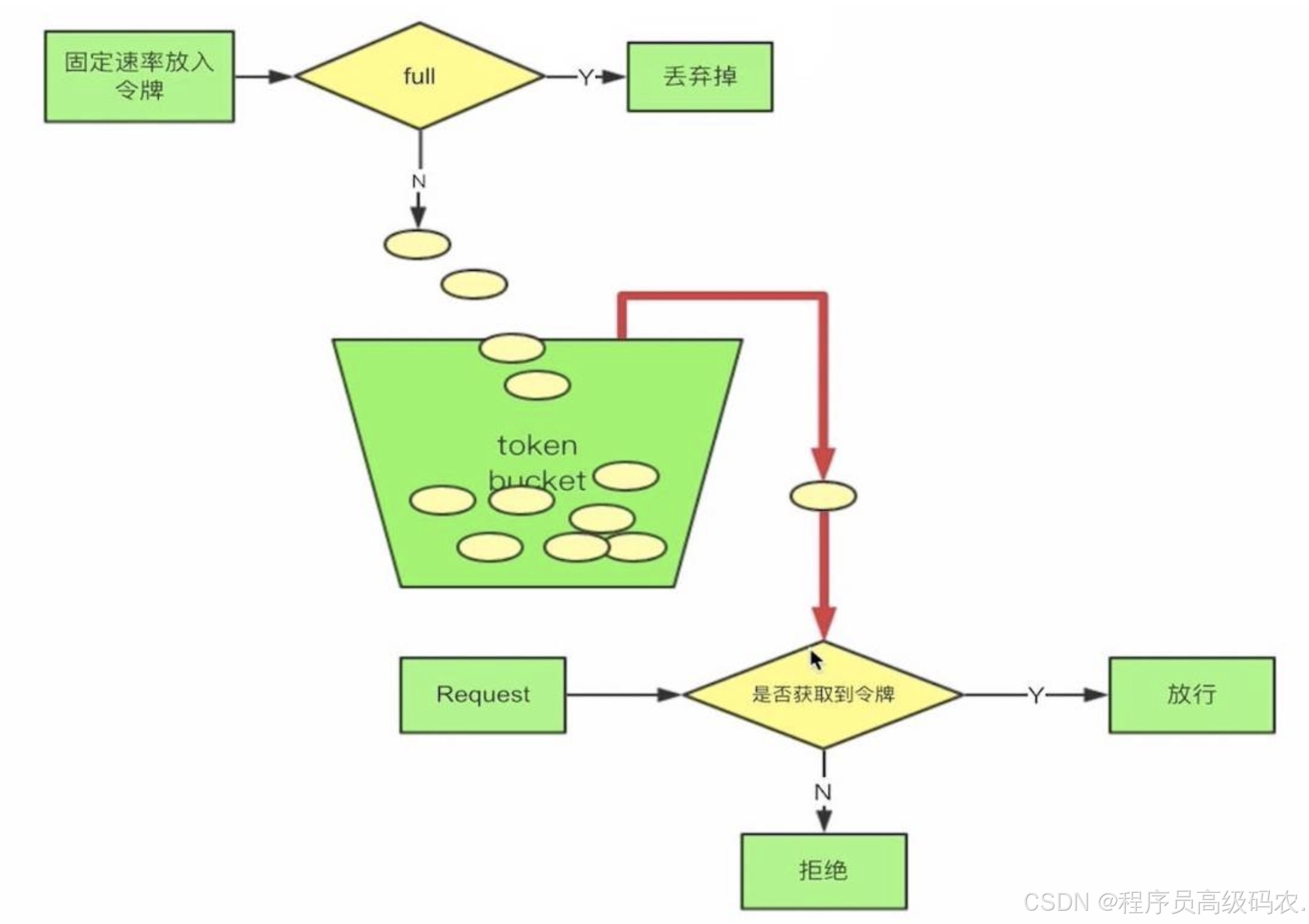
我先来解释一下什么是
令牌桶限流
吧。
首先我们会有个桶,如果里面没有满那么就会以一定 固定的速率 会往里面放令牌,一个请求过来首先要 从桶中获取令牌,如果没有获取到,那么这个请求就拒绝,如果获取到那么就放行。很简单吧,啊哈 哈、 下面我们就通过
Zuul
的前置过滤器来实现一下令牌桶限流。
package
com
.
lgq
.
zuul
.
filter
;
import
com
.
google
.
common
.
util
.
concurrent
.
RateLimiter
;
import
com
.
netflix
.
zuul
.
ZuulFilter
;
import
com
.
netflix
.
zuul
.
context
.
RequestContext
;
import
com
.
netflix
.
zuul
.
exception
.
ZuulException
;
import
lombok
.
extern
.
slf4j
.
Slf4j
;
import
org
.
springframework
.
cloud
.
netflix
.
zuul
.
filters
.
support
.
FilterConstants
;
import
org
.
springframework
.
stereotype
.
Component
;
@Component
@Slf4j
public class
RouteFilter
extends
ZuulFilter
{
//
定义一个令牌桶,每秒产生
2
个令牌,即每秒最多处理
2
个请求
private static final
RateLimiter RATE_LIMITER
=
RateLimiter
.
create
(
2
);
@Override
public
String
filterType
() {
return
FilterConstants
.
PRE_TYPE
;
}
@Override
public
int
filterOrder
() {
return
-
5
;
}
@Override
public
Object
run
()
throws
ZuulException
{
log
.
info
(
"
放行
"
);
return
null
;
}
@Override
public
boolean
shouldFilter
() {
RequestContext context
=
RequestContext
.
getCurrentContext
();
if
(
!
RATE_LIMITER
.
tryAcquire
()) {
log
.
warn
(
"
访问量超载
"
);
//
指定当前请求未通过过滤
context
.
setSendZuulResponse
(
false
);
//
向客户端返回响应码
429
,请求数量过多
context
.
setResponseStatusCode
(
429
);
return
false
;
}
return
true
;
}
}
这样我们就能将请求数量控制在一秒两个,有没有觉得很酷?
中间件相关

46. 说说你们公司ES的集群架构,索引数据大小,分片有多少,以及
一些调优手段?
根据实际情况回答即可,如果是我的话会这么回答:
我司有多个ES集群,下面列举其中一个。该集群有20个节点,根据数据类型和日期分库,每个索引根据 数据量分片,比如日均1亿+数据的,控制单索引大小在200GB以内。
下面重点列举一些调优策略,仅是我做过的,不一定全面,如有其它建议或者补充欢迎留言。
部署层面:
1)最好是64GB内存的物理机器,但实际上32GB和16GB机器用的比较多,但绝对不能少于8G,除非数 据量特别少,这点需要和客户方面沟通并合理说服对方。
2)多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
3)尽量使用SSD,因为查询和索引性能将会得到显著提升。
4)避免集群跨越大的地理距离,一般一个集群的所有节点位于一个数据中心中。
5)设置堆内存:节点内存/2,不要超过32GB。一般来说设置export ES_HEAP_SIZE=32g环境变量,比 直接写-Xmx32g -Xms32g更好一点。
6)关闭缓存swap。内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个100微 秒的操作可能变成10毫秒。 再想想那么多10微秒的操作时延累加起来。不难看出swapping对于性能是 多么可怕。
7)增加文件描述符,设置一个很大的值,如65535。Lucene使用了大量的文件,同时,Elasticsearch 在节点和HTTP客户端之间进行通信也使用了大量的套接字。所有这一切都需要足够的文件描述符。
8)不要随意修改垃圾回收器(CMS)和各个线程池的大小。
9)通过设置gateway.recover_after_nodes、gateway.expected_nodes、
gateway.recover_after_time可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数 个小时缩短为几秒钟。
索引层面:
1)使用批量请求并调整其大小:每次批量数据 5–15 MB 大是个不错的起始点。
2)段合并:Elasticsearch默认值是20MB/s,对机械磁盘应该是个不错的设置。如果你用的是SSD,可 以考虑提高到100-200MB/s。如果你在做批量导入,完全不在意搜索,你可以彻底关掉合并限流。另外 还可以增加 index.translog.flush_threshold_size 设置,从默认的512MB到更大一些的值,比如 1GB,这可以在一次清空触发的时候在事务日志里积累出更大的段。
3)如果你的搜索结果不需要近实时的准确度,考虑把每个索引的index.refresh_interval 改到30s。
4)如果你在做大批量导入,考虑通过设置index.number_of_replicas: 0 关闭副本。
5)需要大量拉取数据的场景,可以采用scan & scroll api来实现,而不是from/size一个大范围。
存储层面:
1)基于数据+时间滚动创建索引,每天递增数据。控制单个索引的量,一旦单个索引很大,存储等各种 风险也随之而来,所以要提前考虑+及早避免。
2)冷热数据分离存储,热数据(比如最近3天或者一周的数据),其余为冷数据。对于冷数据不会再写 入新数据,可以考虑定期force_merge加shrink压缩操作,节省存储空间和检索效率
47. 在并发情况下,Elasticsearch如果保证读写一致?
可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才 允许写操作。但即使大多数可用,也可能存在因为网络等原因
导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;
如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分 片,确保文档是最新版本。
Linux

ping
命令
ping
命令查看网络连通性的命令和
windows
上的功能一样
ifconfig
命令
ifconfig
命令属于
net-tools
软件包
,
使用前需要安装
net-tools
net-tools
的安装
:
yum -y install net-tools
ifconfig查看ip地址
netstat
命令
netstat
命令也属于
net-tools
软件包
netstat -tulp | grep 1521 #查看oracle监听器程序是否正常启动
rpm
命令
rpm
是
linux
上的安装命令,用来安装
.rpm
格式的安装包
rpm -ivh .rpm文件的路径 #表示安装软件包
rpm -qa #查看已安装的软件
rpm -qa | grep mysql #查看已经安装的mysql软件包
rpm -e --nodeps 安装包名 #卸载软件包 -e表示卸载 --nodeps表示不理会的依赖关系
OK,本文就这样。


























 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









