







序言
英文版教材免费下载地址: CASI
笔者本来是打算写来作为期末复习使用的, 但是发现写着写着变成了翻译教材, 实在是太草了; 本来以为提前一个星期动笔一定可以趁复习时顺手做完这本教材的摘要, 现在看来怕是要来不及了[Facepalm]…
笔者认为本书对于深究机器学习领域中的统计理论知识非常重要, 如果以后想要在机器学习方向做深入研究的话, 此书能够大大开拓使用机器学习方法的思路, 尤其是后半部分的章节与机器学习密切相关, 对诸如交叉验证, 自助法, 深度学习中的参数评估做了详细的理论分析, 非常值得好好学习一遍, 可惜课上讲到第12章就结束了;
本文长期更新, 笔者对该教材非常感兴趣, 眼下迫于期末复习无法详细做完所有笔记, 目前只做完了前三节的内容, 后续重点会就机器学习相关章节做一些笔记, 其他章节可能就以总结重点的形式一笔带过, 因为前面的几个章节主要还是基础的统计知识, 大部分可以在教科书上找到, 总之不能像前三节一样费时间写了, 实在是来不及了…
目录
- 序言
- PART 1 经典统计推断 Classic Statistical Inference
- PART 2 早期计算机时代的方法 Early Computer-Age Methods
- 6 经验贝叶斯 Empirical Bayes
- 7 詹姆斯——斯坦因估计与岭回归 James–Stein Estimation and Ridge Regression
- 8 广义线性回归与回归树 Generalized Linear Models and Regression Trees
- 9 生存分析与期望最大化算法 Survival Analysis and the EM Algorithm
- 10 刀切法与自助法 The Jackknife and the Bootstrap
- 11 自助法的置信区间 Bootstrap Confidence Intervals
- 11.1 黎曼对于单参数问题的构建 Neyman’s Construction for One-Parameter Problems
- 11.2 分位数方法 The Percentile Method
- 11.3 偏差矫正后的置信区间 Bias-Corrected Confidence Intervals
- 11.4 二次精确度 Second-Order Accuracy
- 11.5 自助法的 t t t区间 Bootstrap- t t t Intervals
- 11.6 目标贝叶斯区间与置信分布 Objective Bayes Intervals and the Confidence Distribution
- 12 交叉检验与预测误差的 C p C_p Cp估计 Cross-Validation and C p C_p Cp Estimates of Prediction Error
- 13 目标贝叶斯推断与马尔科夫链蒙特卡洛法 Objective Bayes Inference and MCMC
- 14 战后统计推断与方法论 Postwar Statistical Inference and Methodology
- PART 3 二十一世纪的话题 Twenty-First-Century Topics
- 15 大规模假设检验与错误发现率 Large-Scale Hypothesis Testing and FDRs
- 16 稀疏建模与最小绝对收缩和选择运算符 Sparse Modeling and the Lasso
- 17 随机森林与提升方法 Random Forests and Boosting
- 18 神经网络与深度学习 Neural Networks and Deep Learning
- 19 支持向量机与核函数方法 Support-Vector Machines and Kernel Methods
- 19.1 最优分割超平面 Optimal Separating Hyperplane
- 19.2 松弛边际分类器 Soft-Margin Classifier
- 19.3 支持向量机的 SVM Criterion as Loss Plus Penalty
- 19.4 计算与核函数技巧 Computations and the Kernel Trick
- 19.5 使用核函数进行函数拟合 Function Fitting Using Kernels
- 19.6 示例: 用于蛋白质分类的字符串核函数 Example: String Kernels for Protein Classification
- 19.7 支持向量机总结 SVMs: Concluding Remarks
- 19.8 核函数平滑与局部回归 Kernel Smoothing and Local Regression
- 20 模型选择后的推断 Inference After Model Selection
- 21 经验贝叶斯估计策略 Empirical Bayes Estimation Strategies
PART 1 经典统计推断 Classic Statistical Inference
1 算法与推断 Algorithms and Inference
- 统计科学是从经验中进行知识学习的学科, 尤其是那种每次都只有有少量积累的经验, 如:
- (1) 新研发的实验药品成功与否;
- (2) 小行星通往地球路径的不确定测算;
- 样本均值估计 x ˉ = ∑ i = 1 n x i n (1.1) \bar x=\sum_{i=1}^n\frac{x_i}{n}\tag{1.1} xˉ=i=1∑nnxi(1.1)的标准误差估计值为: s e ^ = [ ∑ i = 1 n ( x i − x ˉ ) 2 n ( n − 1 ) ] 1 2 (1.2) \widehat{\rm se}=\left[\sum_{i=1}^n\frac{(x_i-\bar x)^2}{n(n-1)}\right]^{\frac{1}{2}}\tag{1.2} se =[i=1∑nn(n−1)(xi−xˉ)2]21(1.2)
- ( 1.1 ) (1.1) (1.1)中均值计算属于一种推断算法;
-
(
1.2
)
(1.2)
(1.2)中的标准误差值可以表示该推断算法的精确性, 标准误差越小, 精确度越高;
- 标准误差: 指在给定样本 X = { x 1 , x 2 , . . . , x n } \bm{X}=\{x_1,x_2,...,x_n\} X={x1,x2,...,xn}的条件下, 样本统计量 T ( X ) T(\bm{X}) T(X)的标准差;
- 此处 T ( X ) = x ˉ T(\bm{X})=\bar x T(X)=xˉ, 则标准误差估计值 s e ^ \widehat{\rm se} se 计算公式为: [ ∑ i = 1 n 1 n 2 V a r ( x i ) ] 1 2 = [ n ⋅ 1 n 2 ⋅ ( x i − x ˉ ) 2 ( n − 1 ) ] 1 2 = [ ∑ i = 1 n ( x i − x ˉ ) 2 n ( n − 1 ) ] 1 2 \left[\sum_{i=1}^n\frac{1}{n^2}{\rm Var(x_i)}\right]^{\frac{1}{2}}=\left[n\cdot\frac{1}{n^2}\cdot\frac{(x_i-\bar x)^2}{(n-1)}\right]^{\frac{1}{2}}=\left[\sum_{i=1}^n\frac{(x_i-\bar x)^2}{n(n-1)}\right]^{\frac{1}{2}} [i=1∑nn21Var(xi)]21=[n⋅n21⋅(n−1)(xi−xˉ)2]21=[i=1∑nn(n−1)(xi−xˉ)2]21
- 结论: 提供统计推断的一组样本数据, 同样可以用来评估该推断结果的精确性;
1.1 一个回归示例 A Regression Example
- 本节给出一个肾功能随年龄变化的回归分析模型:
y
=
β
^
0
+
β
^
1
x
(1.3)
y={\hat\beta}_0+{\hat \beta}_1x\tag{1.3}
y=β^0+β^1x(1.3)并使用最小二乘法优化目标函数
∑
i
=
1
n
(
y
i
−
β
^
0
−
β
^
1
x
i
)
2
(1.4)
\sum_{i=1}^n(y_i-{\hat\beta}_0-{\hat \beta}_1x_i)^2\tag{1.4}
i=1∑n(yi−β^0−β^1xi)2(1.4)
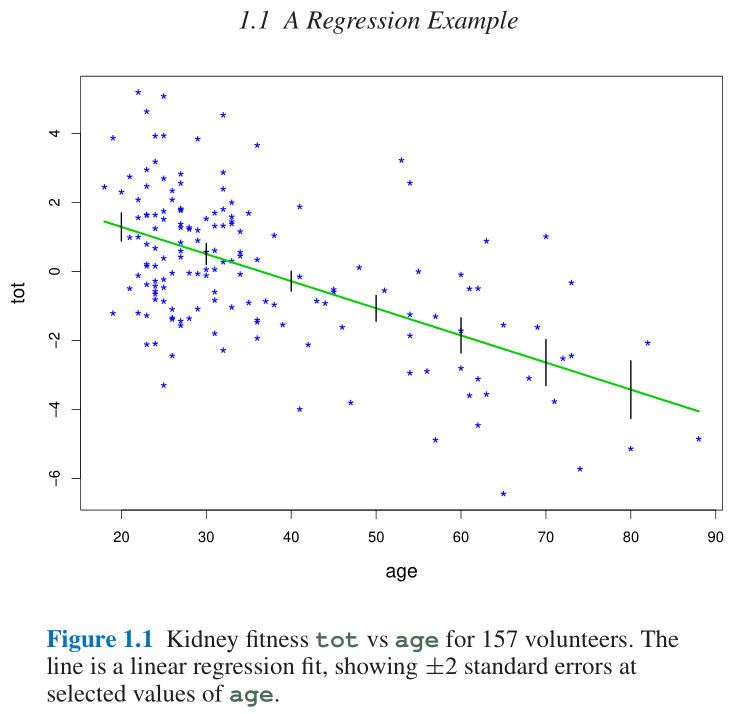
- Figure 1.1中给出的是样本散点图以及使用最小二乘法得到的线性回归拟合直线(绿线);
- 注意到拟合绿线上的垂直黑线表示该点估计值正负两倍的标准误差;
- 具体标准误差值详见Table 1.1;
- 每个拟合预测点 x = 20 , 30 , 40 , 50 , 60 , 70 , 80 x=20,30,40,50,60,70,80 x=20,30,40,50,60,70,80处的标准误差即为 β ^ 0 + β ^ 1 x {\hat\beta}_0+{\hat \beta}_1x β^0+β^1x的标准误差; 应该是通过 [ s e ( β ^ 0 ) 2 + x 2 s e ( β ^ 1 ) 2 ] 1 2 [{\rm se}({\hat\beta}_0)^2 + x^2{\rm se}({\hat\beta}_1)^2]^{\frac{1}{2}} [se(β^0)2+x2se(β^1)2]21的方法计算得到的;
- 最小二乘法中参数
β
^
0
{\hat\beta}_0
β^0与
β
^
1
{\hat \beta}_1
β^1的标准误差分别为:
s
e
(
β
^
0
)
=
σ
^
2
(
1
n
+
x
ˉ
2
S
X
X
)
s
e
(
β
^
1
)
=
σ
^
2
S
X
X
{\rm se}({\hat\beta}_0)={\hat\sigma}^2\left(\frac{1}{n}+\frac{\bar x^2}{\rm SXX}\right)\\{\rm se}({\hat\beta}_1)=\frac{{\hat\sigma}^2}{\rm SXX}
se(β^0)=σ^2(n1+SXXxˉ2)se(β^1)=SXXσ^2其中:
σ
^
2
=
1
n
−
2
∑
i
=
1
n
(
y
i
−
β
^
0
−
β
^
1
x
i
)
2
S
X
X
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
=
∑
i
=
1
n
x
i
(
x
i
−
x
ˉ
)
{\hat\sigma}^2=\frac{1}{n-2}\sum_{i=1}^n(y_i-{\hat\beta}_0-{\hat \beta}_1x_i)^2\\{\rm SXX}=\sum_{i=1}^n(x_i-\bar x)^2=\sum_{i=1}^nx_i(x_i-\bar x)
σ^2=n−21i=1∑n(yi−β^0−β^1xi)2SXX=i=1∑n(xi−xˉ)2=i=1∑nxi(xi−xˉ)
- σ ^ 2 {\hat\sigma}^2 σ^2是最小二乘方差的无偏估计;
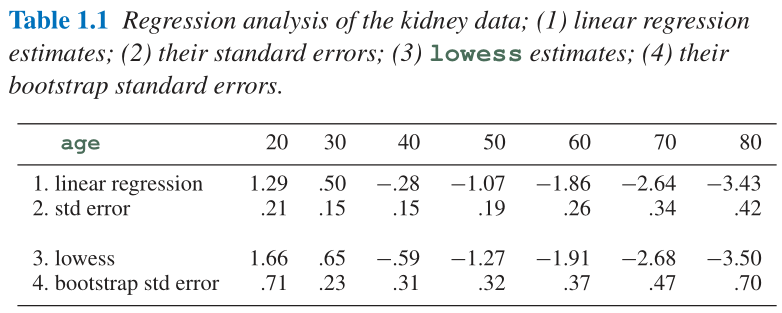
- Figure 1.2与Figure 1.3中分别是肾功能案例的局部加权回归(Lowess)与bootstrap采样下的Lowess拟合结果;
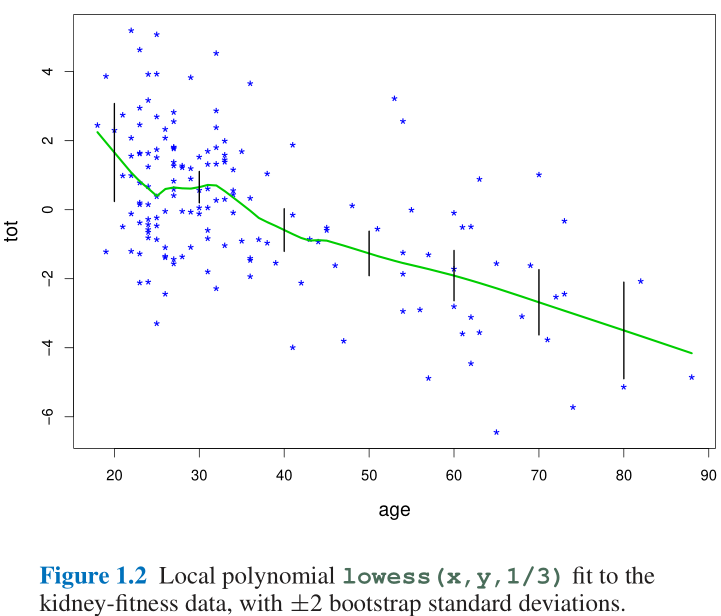
- 关于局部加权回归的具体算法可以参考【算法】局部加权回归(Lowess) ; 大致思路是: 以一个点 x x x为中心, 向前后截取一段长度为 f r a c \rm frac frac的数据, 对于该段数据用权值函数 w w w做一个加权的线性回归, 记 ( x , y ^ ) (x,\hat y) (x,y^)为该回归线的中心值, 其中 y ^ \hat y y^为拟合后曲线对应值, 对于所有的 n n n个数据点可以作出 n n n条加权回归线, 每条回归线的中心值的连线则为这段数据的Lowess回归拟合曲线;
- Figure 1.2与Figure 1.3中的 f r a c \rm frac frac即为 1 3 \frac{1}{3} 31
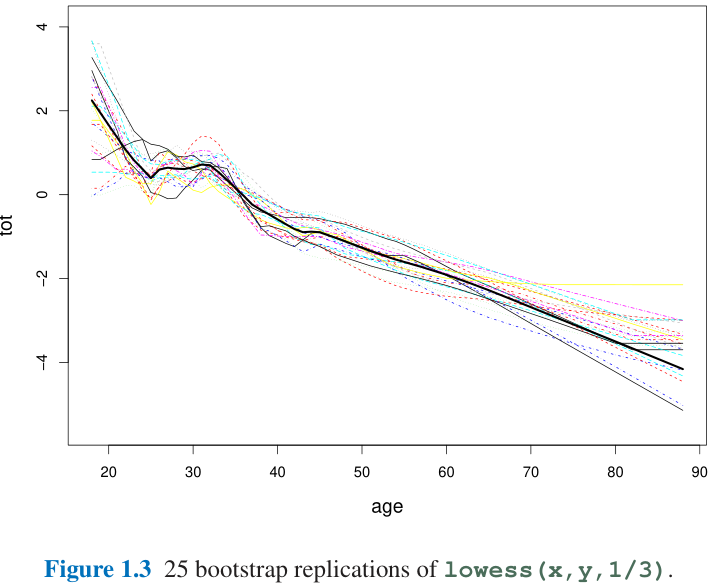
- 注意到Lowess回归很难使用公式来计算其标准误差, 但是可以使用bootstrap多次重采样来近似估计其标准误差, 这就是Figure 1.3所做的事情, 这里作者做了250次重采样, Figure 1.3显示得是前25次重采样得Lowess回归拟合曲线;
- Table 1.1中有Lowess回归的预测值及bootstrap重采样下的标准误差估计值, 可以看到Lowess回归是以较大的标准误差换来了平滑的预测结果;
1.2 假设检验 Hypothesis Testing
本节主要介绍假设检验的方法论进展;
- 本节给出的是一个两种白血病(
A
L
L
\rm ALL
ALL与
A
M
L
\rm AML
AML)患者的样本案例; 72个白血病患者, 45个是ALL, 27个AML, Figure 1.4中给出了这些患者136号基因的活跃度的频数直方图:
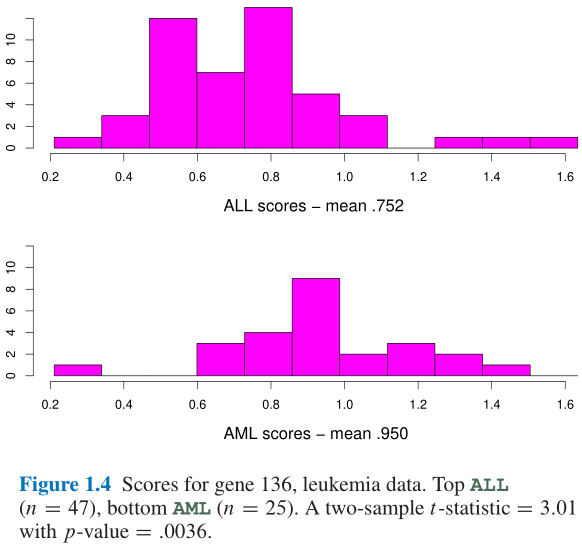
A L L ‾ = 0.752 A M L ‾ = 0.950 (1.5) \overline{\rm ALL}=0.752\quad\overline{\rm AML}=0.950\tag{1.5} ALL=0.752AML=0.950(1.5)
- 似乎
A
M
L
\rm AML
AML的136号基因的活跃度要更高一些; 但是这是否是统计上的一个侥幸现象(a statistical fluke)? 这可以使用两样本的
t
t
t检验来回答:
t
=
A
M
L
‾
−
A
L
L
‾
s
d
^
(1.6)
t=\frac{\overline{\rm AML}-\overline{\rm ALL}}{\widehat {\rm sd}}\tag{1.6}
t=sd
AML−ALL(1.6)
- 其中 s d ^ \widehat {\rm sd} sd 是Formula 1.6分子的标准差;
- 计算结果 t = 3.01 t=3.01 t=3.01是一个标准零分布(null distribution)中的值, 本例中是自由度为70的 t t t分布, 即可得出这是一个双侧显著水平为0.0036的检验, 置信水平是非常高的;
- 但是Figure 1.5中又给出了一个7182个样本量的相同案例统计结果:
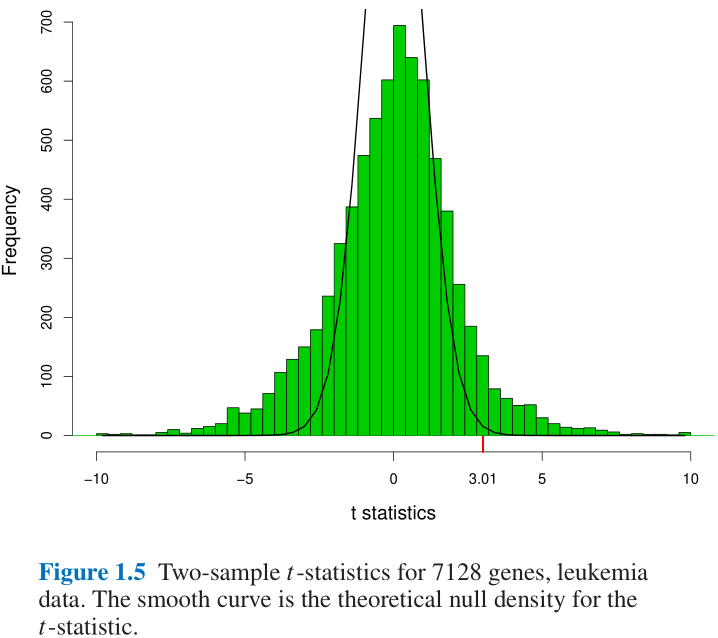
- 注意到自由度为70的 t t t分布近似为正态分布, 使用 3 σ 3\sigma 3σ的估计结果可以知道大于 3.01 3.01 3.01的样本数应当占比约为 1 % 1\% 1%即71个左右的异常值样本;
- 但是Figure 1.5中可以看到实际上会有400多个异常值样本;
- 作者将其归因于样本并非独立同分布, 使得零分布(自由度为70的 t t t分布)的假设是不成立的;
- 因此这里有提出很多后续需要研究的概念:
- Chapter 15中的错误发现率(false-discovery rate);
- 频率学派与与贝叶斯学派的结合;
- Chapter 6中的经验贝叶斯;
- Chapter 20中的同时置信区间: 当需要做 m m m个假设检验时, 想要将显著水平控制在 α \alpha α一下, 则要求单个假设检验的显著水平要在 α m \frac{\alpha}{m} mα以下;
2 频率推断 Frequentist Inference
- 梅尔博士的肾脏学实验:
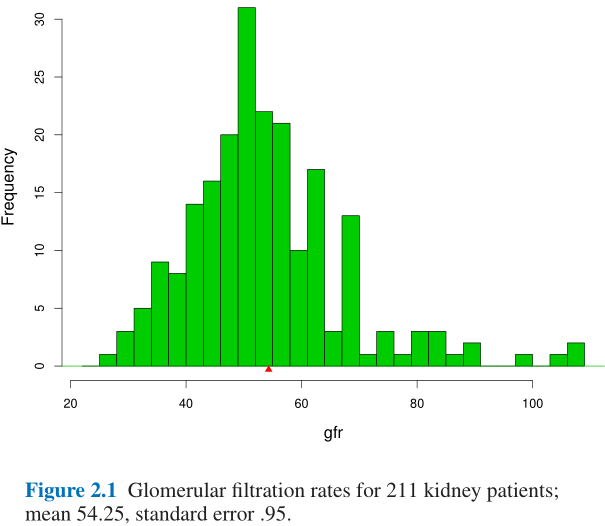
- 检测211个肾脏病患者的 g f r \rm gfr gfr指标, 根据Formula 1.1与Formula 1.2计算得到的均值估计与标准误差估计为 x ˉ = 54.25 \bar x=54.25 xˉ=54.25与 s e ^ = 0.95 \widehat {\rm se}=0.95 se =0.95, 因此可以统计描述可以表达为: 54.25 ± 0.95 (2.1) 54.25\pm0.95\tag{2.1} 54.25±0.95(2.1)其中 ± 0.95 \pm0.95 ±0.95表示对于估计量 x ˉ = 54.25 \bar x=54.25 xˉ=54.25, 频率推断出的精确度; 这说明其实别太对 54.25 54.25 54.25的误差其实很大, 不仅小数位不可信, 连个位数 4 4 4的可信度也很低;
- 频率推断:
- 令 X = ( X 1 , X 2 , . . . , X n ) \bm{X}=(X_1,X_2,...,X_n) X=(X1,X2,...,Xn)是 n n n个从概率分布 F F F中独立抽取出来的 n n n个样本: F → X (2.2) F\rightarrow\bm{X}\tag{2.2} F→X(2.2)这里的 F F F就是 g f r \rm gfr gfr值的未知分布, 而我们得到的观测样本 X = x = ( x 1 , x 2 , . . . , x n ) \bm{X}=\bm{x}=(x_1,x_2,...,x_n) X=x=(x1,x2,...,xn), 而频率推断希望从观测样本上推断出未知分布 F F F的一些性质;
- 假设参数
θ
\theta
θ是
X
\bm{X}
X的数学期望:
θ
=
E
F
(
X
)
(2.3)
\theta=E_F(\bm{X})\tag{2.3}
θ=EF(X)(2.3)
事实上频率推断中会不断采样 X \bm{X} X, 得到观测样本 x \bm{x} x, 从而获得估计值 θ ^ = t ( x ) (2.4) \hat\theta=t(\bm{x})\tag{2.4} θ^=t(x)(2.4),每次采样会得到一个不同的均值估计值 Θ \Theta Θ, 则可以记随机变量 Θ ^ = t ( X ) (2.5) \hat\Theta=t(\bm{X})\tag{2.5} Θ^=t(X)(2.5) - 定义 μ \mu μ为 Θ ^ = t ( X ) \hat\Theta=t(\bm{X}) Θ^=t(X)的数学期望, 即: μ = E F ( Θ ^ ) (2.6) \mu=E_F(\hat\Theta)\tag{2.6} μ=EF(Θ^)(2.6)则参数 θ \theta θ的估计量 θ ^ \hat\theta θ^的偏差与方差分别为 b i a s = μ − θ v a r = E F [ ( Θ ^ − μ ) 2 ] (2.7) {\rm bias}=\mu-\theta\quad{\rm var}=E_F\left[(\hat\Theta-\mu)^2\right]\tag{2.7} bias=μ−θvar=EF[(Θ^−μ)2](2.7)
2.1 频率主义的实际应用 Frequentism in Practice
- 频率主义的工作定义: the probabilistic properties of a procedure of interest are derived and then applied verbatim to the procedure’s output for the observed data.
- 简而言之就是从分布 F F F中计算出估计量 Θ ^ = t ( X ) \hat\Theta=t(\bm{X}) Θ^=t(X)的性质, 即使 F F F是未知的;
- 应用举例:
- (1) The plug-in principle:
- 用原模型分布产生的数据分布来估算模型本身的分布, 然后将预估出来的参数插入到原分布中以做出最优预测;
- 如可以将分布 F F F下的样本均值 X ˉ = ∑ X i n \bar X=\frac{\sum X_i}{n} Xˉ=n∑Xi的标准误差与 v a r F ( X ) {\rm var}_F(X) varF(X)联系起来: s e ( X ˉ ) = [ v a r F ( X ) n ] 1 2 (2.8) {\rm se}(\bar X)=\left[\frac{{\rm var}_F(X)}{n}\right]^{\frac{1}{2}}\tag{2.8} se(Xˉ)=[nvarF(X)]21(2.8)我们只有观测到的样本数据 x = ( x 1 , x 2 , . . . , x n ) \bm{x}=(x_1,x_2,...,x_n) x=(x1,x2,...,xn), 于是只能进行估计: v a r ^ F = ∑ ( x i − x ˉ ) 2 n − 1 (2.9) {\widehat {\rm var}}_F=\sum\frac{(x_i-\bar x)^2}{n-1}\tag{2.9} var F=∑n−1(xi−xˉ)2(2.9)将Formula 2.9嵌入到Formula 2.8中就可以得到Formula 1.2中的估计值 s e ^ \widehat{\rm se} se ;
- 拓展:
- ① 如 θ = E ( X ) \theta=E(X) θ=E(X)的估计量为 ∑ i = 1 n X i n \frac{\sum_{i=1}^nX_i}{n} n∑i=1nXi, 通过R-S Integral可以知道 θ = E ( X 2 ) \theta=E(X^2) θ=E(X2)的估计量为 ∑ i = 1 n X i 2 n \frac{\sum_{i=1}^nX_i^2}{n} n∑i=1nXi2
- ② 关于 v a r ( X ˉ ) {\rm var}(\bar X) var(Xˉ)的估计值, 可以使用 v a r ( X ˉ ) = σ 2 n = 1 n { ∫ x 2 d F ( x ) − [ x d F ( x ) ] 2 } {\rm var}(\bar X)=\frac{\sigma^2}{n}=\frac{1}{n}\left\{\int x^2{\rm d}F(x)-\left[x{\rm d}F(x)\right]^2\right\} var(Xˉ)=nσ2=n1{∫x2dF(x)−[xdF(x)]2}, 则可以得到: v a r ^ ( X ˉ ) = 1 n { ∫ x 2 d F n ( x ) − [ x d F n ( x ) ] 2 } \widehat {\rm var}(\bar X)=\frac{1}{n}\left\{\int x^2{\rm d}F_n(x)-\left[x{\rm d}F_n(x)\right]^2\right\} var (Xˉ)=n1{∫x2dFn(x)−[xdFn(x)]2}
- (2) Taylor-series approximations: 如果统计量
θ
^
=
t
(
x
)
\hat\theta=t(\bm{x})
θ^=t(x)比
x
ˉ
\bar x
xˉ复杂得多, 则可以回归到局部线性近似, 使用delta method来进行参数估计;
- 如KaTeX parse error: Undefined control sequence: \gat at position 1: \̲g̲a̲t̲\theta={\bar x}…的导数为 d θ ^ d x ˉ = 2 x ˉ \frac{{\rm d}\hat\theta}{{\rm d}\bar x}=2\bar x dxˉdθ^=2xˉ, 视 2 x ˉ 2\bar x 2xˉ为一个常数则可以得到 s e ( x ˉ 2 ) = 2 ∣ x ˉ ∣ s e ^ (2.10) {\rm se}({\bar x}^2)=2\left|\bar x\right|\widehat{se}\tag{2.10} se(xˉ2)=2∣xˉ∣se (2.10)其中 s e ^ \widehat{se} se 在Formula 1.2中给出;
- 这个结论的一般情况是: v a r ( g ( x ˉ ) ) = v a r ( g ( x ˉ ) − g ( θ ) ) = [ g ′ ( θ ) ] 2 ( v a r ( x ˉ − θ ) ) = [ g ′ ( θ ) ] 2 ( v a r ( x ˉ ) ) {\rm var}(g(\bar x))={\rm var}(g(\bar x)-g(\theta))=\left[g^\prime(\theta)\right]^2({\rm var}(\bar x-\theta))=\left[g^\prime(\theta)\right]^2({\rm var}(\bar x)) var(g(xˉ))=var(g(xˉ)−g(θ))=[g′(θ)]2(var(xˉ−θ))=[g′(θ)]2(var(xˉ))
- (3) Parametric families and maximum likelihood theory: 这部分详见Chapter 4和Chapter 5中的最大似然估计的标准误差, 以及参数族分布, 会结合费雪理论, Taylor-series approximations以及The plug-in principle;
- (4) Simulation and the bootstrap: 即仿真模拟与重采样方法;
- (5) Pivotal statistics: 枢轴统计量;
- 枢轴统计量 θ = t ( x ) \theta=t(\bm{x}) θ=t(x)是一个分布与未知分布 F F F无关的一个统计量; 以两样本 t t t检验为例: x 1 = ( x 11 , x 12 , . . . , x 1 n 1 ) x 2 = ( x 21 , x 22 , . . . , x 2 n 2 ) (2.11) \bm{x}_1=(x_{11},x_{12},...,x_{1n_1})\quad\bm{x}_2=(x_{21},x_{22},...,x_{2n_2})\tag{2.11} x1=(x11,x12,...,x1n1)x2=(x21,x22,...,x2n2)(2.11)其中 X 1 i ∼ N ( μ 1 , σ 2 ) i = 1 , 2 , . . . , n 1 (2.12) X_{1i}\sim\mathcal{N}(\mu_1,\sigma^2)\quad i=1,2,...,n_1\tag{2.12} X1i∼N(μ1,σ2)i=1,2,...,n1(2.12) X 2 i ∼ N ( μ 2 , σ 2 ) i = 1 , 2 , . . . , n 2 (2.13) X_{2i}\sim\mathcal{N}(\mu_2,\sigma^2)\quad i=1,2,...,n_2\tag{2.13} X2i∼N(μ2,σ2)i=1,2,...,n2(2.13)我们希望检验零假设 H 0 : μ 1 = μ 2 (2.14) H_0:\mu_1=\mu_2\tag{2.14} H0:μ1=μ2(2.14)则显然的检验统计量 θ ^ = x ˉ 2 − x ˉ 1 \hat\theta={\bar x}_2-{\bar x}_1 θ^=xˉ2−xˉ1的分布为 θ ^ ∼ N ( 0 , σ 2 ( 1 n 1 + 1 n 2 ) ) (2.15) \hat\theta\sim\mathcal{N}\left(0,\sigma^2\left(\frac{1}{n_1}+\frac{1}{n_2}\right)\right)\tag{2.15} θ^∼N(0,σ2(n11+n21))(2.15)在零假设下我们希望将 σ 2 \sigma^2 σ2的无偏估计量嵌入: σ ^ 2 = 1 n 1 + n 2 − 2 [ ∑ 1 n 1 ( x 1 i − x ˉ 1 ) 2 + ∑ 1 n 2 ( x 2 i − x ˉ 2 ) 2 ] (2.16) {\hat\sigma}^2=\frac{1}{n_1+n_2-2}\left[\sum_1^{n_1}(x_{1i}-{\bar x}_1)^2+\sum_1^{n_2}(x_{2i}-{\bar x}_2)^2\right]\tag{2.16} σ^2=n1+n2−21[1∑n1(x1i−xˉ1)2+1∑n2(x2i−xˉ2)2](2.16)
- 但是 t t t检验给出的方法更加优雅, 直接使用 t t t统计量: t = x ˉ 2 − x ˉ 1 s d ^ w h e r e s d ^ = σ ^ ( 1 n 1 + 1 n 2 ) (2.17) t=\frac{{\bar x}_2-{\bar x}_1}{\widehat{sd}}\quad{\rm where}\space\widehat{\rm sd}={\hat\sigma}(\frac{1}{n_1}+\frac{1}{n_2})\tag{2.17} t=sd xˉ2−xˉ1where sd =σ^(n11+n21)(2.17)此时在零假设 H 0 H_0 H0下, t t t是一个枢轴量, 分布为自由度 n 1 + n 2 − 2 n_1+n_2-2 n1+n2−2的 t t t分布, 而与参数 σ \sigma σ取值无关;
- 拓展: 一般方法为 n ( X ˉ − E X ) σ ^ → N ( 0 , 1 ) \frac{\sqrt{n}(\bar X-EX)}{\hat\sigma}\rightarrow\mathcal{N}(0,1) σ^n(Xˉ−EX)→N(0,1)其中 σ ^ \hat\sigma σ^使用The plug-in principle;
2.2 频率学派最优性 Frequentist Optimality
- 最大似然估计量的标准误差(或方差)一般都是最小的;
- 假设检验中设 α \alpha α为犯第一类错误的概率(舍真), β \beta β为犯第二类错误的概率(取假), 在样本量固定的情况下, 很难使得 α \alpha α和KaTeX parse error: Undefined control sequence: \ at position 1: \̲ ̲beta同时下降, 因此一般最优性可以通过 α c < α β c < β (2.23) \alpha_c<\alpha\quad\beta_c<\beta\tag{2.23} αc<αβc<β(2.23)来取得, 即尽量使两种错误的概率在一个很小的范围内;
- Neyman-Pearson Lemma(NP引理): 参考数理统计笔记:假设检验(II)N-P引理 ;
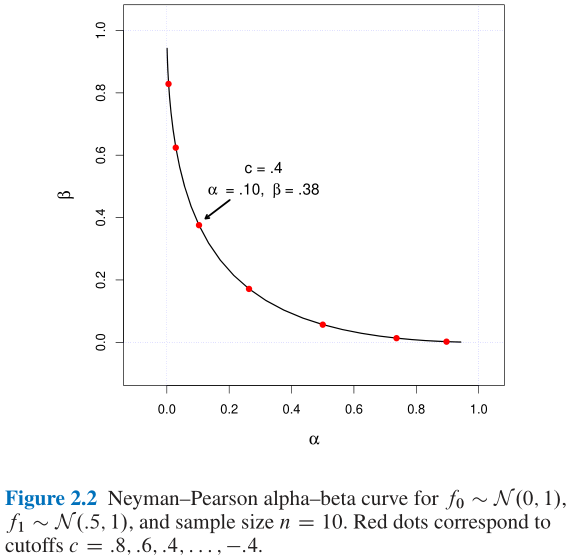
- Figure 2.2中就给出了cut-off值在 0.4 0.4 0.4的情况下, 取得的最优假设检验结果;
- 频率推断的最优性一般是固定一个显著水平 α \alpha α, 使得 β \beta β尽可能的小;
- 似然比检验的方法: https://zhuanlan.zhihu.com/p/104583619 ;
3 贝叶斯推断 Bayesian Inference
- 贝叶斯推断与频率推断即便不是对立的, 也至少是正交的两种概念, 它揭示了频率推断中令人担忧的缺陷, 却也让自身陷入过度使用的批判之中;
- 贝叶斯推断与频率推断的基础都是建立在某种概率密度分布族上: F = { f μ ( x ) ; x ∈ X , μ ∈ Ω } (3.1) \mathcal{F}=\{f_\mu(x);x\in\mathcal{X},\mu\in\Omega\}\tag{3.1} F={fμ(x);x∈X,μ∈Ω}(3.1)其中 X \mathcal{X} X为样本空间, 未观测到的参数 μ \mu μ是在参数空间 Ω \Omega Ω中的一个点, 统计学家通过从 f μ ( x ) f_\mu(x) fμ(x)中观测 x x x来推断 μ \mu μ的数值;
- 最常见的正态分布: f μ ( x ) = 1 2 π e − 1 2 ( x − μ ) 2 (3.2) f_\mu(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{1}{2}(x-\mu)^2}\tag{3.2} fμ(x)=2π1e−21(x−μ)2(3.2)样本空间 X \mathcal{X} X与参数空间 Ω \Omega Ω都为 R 1 \mathcal{R}^1 R1
- 另一种常见的泊松分布: f μ ( x ) = μ x x ! e − μ (3.3) f_\mu(x)=\frac{\mu^x}{x!}e^{-\mu}\tag{3.3} fμ(x)=x!μxe−μ(3.3)样本空间 X = { 0 , 1 , 2 , . . . } \mathcal{X}=\{0,1,2,...\} X={0,1,2,...}, 参数空间 Ω = ( 0 , + ∞ ) \Omega=(0,+\infty) Ω=(0,+∞)
- 贝叶斯推断与频率推断不同之处在于它除了概率分布族 F \mathcal{F} F依赖一个重要的假设, 即先验密度知识: g ( μ ) (3.4) g(\mu)\tag{3.4} g(μ)(3.4)其中 g ( μ ) g(\mu) g(μ)表示在观测 x x x之前就可以获得的与 μ \mu μ相关的分布信息; 如在Formula 3.2中我们至少可以知道 μ \mu μ是一个正数, 且过去的经验告诉我们 μ \mu μ没有出现过10以上的值, 那么就可以假设 μ \mu μ满足 { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } \{1,2,3,4,5,6,7,8,9,10\} {1,2,3,4,5,6,7,8,9,10}上的均匀离散分布;
- 贝叶斯推断根据观测到的 x x x得到 μ \mu μ的后验分布 g ( μ ∣ x ) g(\mu|x) g(μ∣x);
- Bayes’ Rule(贝叶斯法则): g ( μ ∣ x ) = g ( μ ) f μ ( x ) f ( x ) μ ∈ Ω (3.5) g(\mu|x)=\frac{g(\mu)f_\mu(x)}{f(x)}\quad\mu\in\Omega\tag{3.5} g(μ∣x)=f(x)g(μ)fμ(x)μ∈Ω(3.5)其中 f ( x ) f(x) f(x)是 x x x的边际密度函数: f ( x ) = ∫ Ω f μ ( x ) g ( μ ) d μ (3.6) f(x)=\int_\Omega f_\mu(x)g(\mu){\rm d}\mu\tag{3.6} f(x)=∫Ωfμ(x)g(μ)dμ(3.6)
- 注意到Formula 3.5中当 μ \mu μ在 Ω \Omega Ω上变化时, x x x是一个固定的观测值, 于是可以将Formula 3.5改写为: g ( μ ∣ x ) = c x L x ( μ ) g ( μ ) (3.7) g(\mu|x)=c_xL_x(\mu)g(\mu)\tag{3.7} g(μ∣x)=cxLx(μ)g(μ)(3.7)其中 L x L_x Lx是似然函数, 即 f μ ( x ) f_\mu(x) fμ(x)中 x x x固定, μ \mu μ变化, 一般来说 L x ( μ ) = ∏ i = 1 n f μ ( x ) L_x(\mu)=\prod_{i=1}^nf_\mu(x) Lx(μ)=∏i=1nfμ(x); c x c_x cx是用于调整概率密度函数求积为 1 1 1的系数;
- 推论: g ( μ 1 ∣ x ) g ( μ 2 ∣ x ) = g ( μ 1 ) f μ 1 ( x ) g ( μ 2 ) f μ 2 ( x ) (3.8) \frac{g(\mu_1|x)}{g(\mu_2|x)}=\frac{g(\mu_1)f_{\mu_1}(x)}{g(\mu_2)f_{\mu_2}(x)}\tag{3.8} g(μ2∣x)g(μ1∣x)=g(μ2)fμ2(x)g(μ1)fμ1(x)(3.8)即后验密度比等于先验密度比乘以似然比, 这是贝叶斯法则的精髓所在;
3.1 两个示例 Two Examples
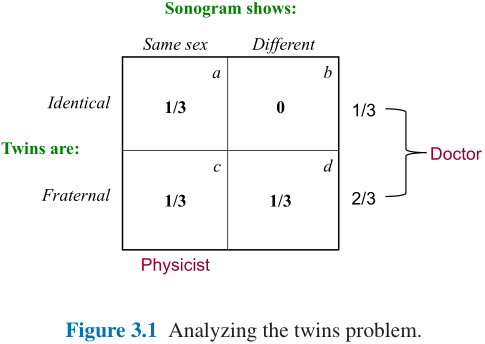
- 第一个示例(Physicist’s Twins问题): 双胞胎分同卵(Identical)和异卵(Fraternal), 以及两个胎儿性别是否相同, 由此分为Figure 3.1的四种情况:
 \
\
- 同卵必然性别相同, 异卵则性别是否相同的概率相等;
- 由此可以计算出在已知性别相同的条件下, 同卵和异卵的概率是相等的: g ( I d e n t i c a l ∣ S a m e ) g ( F r a t e r n a l ∣ S a m e ) = g ( I d e n t i c a l ) g ( F r a t e r n a l ) ⋅ f I d e n t i c a l ( S a m e ) f F r a t e r n a l ( S a m e ) = 1 / 3 2 / 3 ⋅ 1 1 / 2 = 1 (3.9) \frac{g({\rm Identical|Same})}{g({\rm Fraternal|Same})}=\frac{g({\rm Identical})}{g({\rm Fraternal})}\cdot\frac{f_{\rm Identical}({\rm Same})}{f_{\rm Fraternal}({\rm Same})}=\frac{1/3}{2/3}\cdot\frac{1}{1/2}=1\tag{3.9} g(Fraternal∣Same)g(Identical∣Same)=g(Fraternal)g(Identical)⋅fFraternal(Same)fIdentical(Same)=2/31/3⋅1/21=1(3.9)
- 但是在频率推断的情况下, 只看似然函数值的大小, 所以当观测到性别相同的情况时(即
x
=
0
x=0
x=0):
- 若 μ = 1 \mu=1 μ=1, 即同卵双胞胎, 则 f μ ( x ) = 1 f_\mu(x)=1 fμ(x)=1;
- 若 μ = 1 \mu=1 μ=1, 即异卵双胞胎, 则 f μ ( x ) = 1 2 f_\mu(x)=\frac{1}{2} fμ(x)=21;
- 那么就会偏向于推断是同卵双胞胎;
- 我们一般倾向于使用贝叶斯推断, 因为它使用了更多的(可靠的)先验信息;
- 当样本增多时, 先验分布就会越来越没有用处, 直到最终频率推断与贝叶斯推断趋于相同;
- 第二个示例(学生课程成绩): Table 3.1中展示了22个学生在两门课程上的成绩情况;
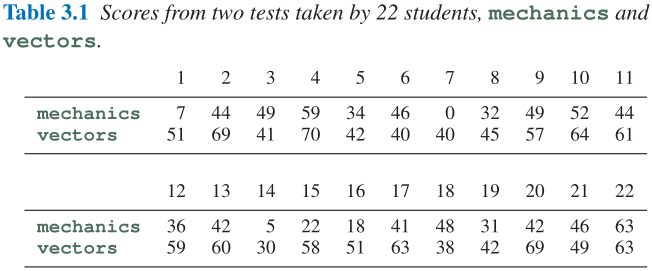
- 可以得到两门课程得分的相关系数值 θ ^ = 0.498 \hat\theta=0.498 θ^=0.498: θ ^ = ∑ i = 1 22 ( m i − m ˉ ) ( v i − v ˉ ) [ ∑ i = 1 22 ( m i − m ˉ ) 2 ∑ i = 1 22 ( v i − v ˉ ) 2 ] (3.10) \hat\theta=\frac{\sum_{i=1}^{22}(m_i-\bar m)(v_i-\bar v)}{\left[\sum_{i=1}^{22}(m_i-\bar m)^2\sum_{i=1}^{22}(v_i-\bar v)^2\right]}\tag{3.10} θ^=[∑i=122(mi−mˉ)2∑i=122(vi−vˉ)2]∑i=122(mi−mˉ)(vi−vˉ)(3.10)
- 因为只观测到了22个学生, 我们希望能够了解到所有学生的真实相关系数 θ \theta θ的后验贝叶斯测算的精确度;
- 如果假设 ( m , v ) (m,v) (m,v)的联合分布时二元正态分布, 则 θ ^ \hat\theta θ^的密度函数可以通过 θ \theta θ进行显式表达: f θ ( θ ^ ) = ( n − 2 ) ( 1 − θ 2 ) n − 1 2 ( 1 − θ ^ 2 ) n − 4 2 π ∫ 0 ∞ d w ( cosh w − θ θ ^ ) n − 1 (3.11) f_\theta(\hat\theta)=\frac{(n-2)(1-\theta^2)^{\frac{n-1}{2}}(1-{\hat\theta}^2)^{\frac{n-4}{2}}}{\pi}\int_0^\infty\frac{{\rm d}w}{(\cosh w-\theta\hat\theta)^{n-1}}\tag{3.11} fθ(θ^)=π(n−2)(1−θ2)2n−1(1−θ^2)2n−4∫0∞(coshw−θθ^)n−1dw(3.11)虽然这看似很复杂, 其实在计算机眼中这与初等函数没有太大区别;
- 如果假设
θ
\theta
θ是区间
[
−
1
,
1
]
[-1,1]
[−1,1]上的均匀分布, 即
g
(
θ
)
=
1
2
−
1
≤
θ
≤
1
(3.12)
g(\theta)=\frac{1}{2}\quad-1\le\theta\le1\tag{3.12}
g(θ)=21−1≤θ≤1(3.12)即为flat prior, 那么Figure 3.2中给出了后验分布的情况, 此时最大似然估计取在密度最高处, 即
0.498
0.498
0.498;
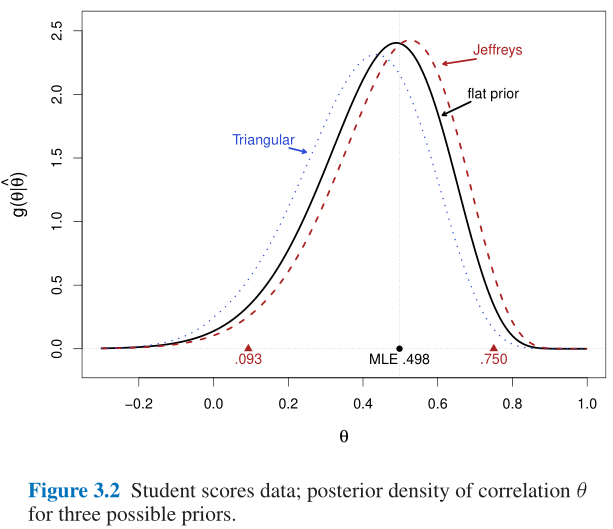
- 当先验分布为均匀分布时, 后验分布的众数(密度最大点)即为最大似然估计量;
- 注意到Figure 3.2中还提到了另外两种先验:
- (1) Jeffreys prior: g J e f f ( θ ) = 1 1 − θ 2 (3.13) g^{\rm Jeff}(\theta)=\frac{1}{1-\theta^2}\tag{3.13} gJeff(θ)=1−θ21(3.13)这源自于无信息先验理论; 这将在下一小节中提到, 虽然Formular 3.13其实并不符合密度函数的性质(求积为1, 这里求积为无穷), 但是当使用贝叶斯法则时仍然可以提供正确的结果;
- (2) Triangular prior: g ( θ ) = 1 − ∣ θ ∣ (3.14) g(\theta)=1-|\theta|\tag{3.14} g(θ)=1−∣θ∣(3.14)这是一种原始的压缩(shrinkage)先验, 使得后验分布趋向于零, 所以估计值会略小于 0.498 0.498 0.498;
- 这里好像作者相对于老版书删除了一些内容, 之后有空将课堂笔记补上:
- 贝叶斯的参数估计: 如最大后验估计(MAP), MMSE, MAE, 以及如何评估参数估计的精确度(MSE);
- 关于MSE的求法(在第四章的Note章节):
M
S
E
=
E
[
(
θ
^
−
θ
)
2
]
=
v
a
r
i
a
n
c
e
+
b
i
a
s
2
(4.47)
{\rm MSE}=E[(\hat\theta-\theta)^2]={\rm variance}+{\rm bias}^2\tag{4.47}
MSE=E[(θ^−θ)2]=variance+bias2(4.47)
- 举个两个例子: 在二项分布
x
i
∼
B
(
n
,
θ
)
x_i\sim B(n,\theta)
xi∼B(n,θ)的情况下:
- θ M L E = x ˉ = ∑ i = 1 n x i n \theta_{\rm MLE}=\bar x=\frac{\sum_{i=1}^nx_i}{n} θMLE=xˉ=n∑i=1nxi, 这是无偏的, 所以直接计算方差即可: M S E ( θ ^ M L E ) = v a r ( ∑ i = 1 n x i n ) = 1 n 2 v a r ( x i ) = 1 n θ ( 1 − θ ) {\rm MSE}(\hat\theta_{\rm MLE})={\rm var}\left(\frac{\sum_{i=1}^nx_i}{n}\right)=\frac{1}{n^2}{\rm var}(x_i)=\frac{1}{n}\theta(1-\theta) MSE(θ^MLE)=var(n∑i=1nxi)=n21var(xi)=n1θ(1−θ)
- θ B = 1 + ∑ i = 1 n x i n + 2 \theta_{\rm B}=\frac{1+\sum_{i=1}^nx_i}{n+2} θB=n+21+∑i=1nxi, 这是有偏的, 那么除了其自身的方差 n θ ( 1 − θ ) ( n + 2 ) 2 \frac{n\theta(1-\theta)}{(n+2)^2} (n+2)2nθ(1−θ)外, 还要加上偏差期望的平方: b i a s 2 = E [ ( 1 + ∑ i = 1 n x i n + 2 − ∑ i = 1 n x i n ) 2 ] = ( n θ + 1 n + 2 − θ ) 2 {\rm bias}^2=E\left[\left(\frac{1+\sum_{i=1}^nx_i}{n+2}-\frac{\sum_{i=1}^nx_i}{n}\right)^2\right]=\left(\frac{n\theta+1}{n+2}-\theta\right)^2 bias2=E[(n+21+∑i=1nxi−n∑i=1nxi)2]=(n+2nθ+1−θ)2
- 举个两个例子: 在二项分布
x
i
∼
B
(
n
,
θ
)
x_i\sim B(n,\theta)
xi∼B(n,θ)的情况下:
- 关于MSE的求法(在第四章的Note章节):
M
S
E
=
E
[
(
θ
^
−
θ
)
2
]
=
v
a
r
i
a
n
c
e
+
b
i
a
s
2
(4.47)
{\rm MSE}=E[(\hat\theta-\theta)^2]={\rm variance}+{\rm bias}^2\tag{4.47}
MSE=E[(θ^−θ)2]=variance+bias2(4.47)
- 贝叶斯的参数置信区间;
- 贝叶斯的假设检验: 贝叶斯因子 B ( x ) B(\bm{x}) B(x);
3.2 无信息先验分布 Uninformative Prior Distributions
- 贝叶斯推断在给定先验分布时是非常好用的, 但是这个先验存在的假设条件太强, 使得未必存在先验知识可用, 因此提出无信息先验分布来解决这个问题; 所谓无信息先验即这样一个先验在应用到贝叶斯法则中后不会使得推断结果发生偏差;
原文: … implying that the use of such a prior in Bayes’ rule does not tacitly bias the resulting inference.
-
拉普拉斯认为均匀分布是无信息的(Laplace’s principle), 但是后来被维恩与费雪所推翻, 如参数 θ \theta θ一个均匀的先验分布将不再是均匀分布, 如果将参数调整为KaTeX parse error: Undefined control sequence: \gamme at position 1: \̲g̲a̲m̲m̲e̲=e^\theta, 则后验分布变为: Pr ( θ > 0 ∣ θ ^ ) = Pr ( γ > 1 ∣ θ ^ ) (3.15) \Pr(\theta>0|\hat\theta)=\Pr(\gamma>1|\hat\theta)\tag{3.15} Pr(θ>0∣θ^)=Pr(γ>1∣θ^)(3.15)将取决于 θ \theta θ与 γ \gamma γ是否被取自一个均匀的先验分布, 任何一个选择都不被认为是无信息的;
-
Jeffreys prior: Laplace’s principle的一种复杂版本;
- 费雪信息量: I μ = E μ [ ( ∂ ∂ μ log f μ ( x ) ) 2 ] (3.16) \mathcal{I}_\mu=E_\mu\left[\left(\frac{\partial}{\partial\mu}\log f_\mu(x)\right)^2\right]\tag{3.16} Iμ=Eμ[(∂μ∂logfμ(x))2](3.16)
- Jeffreys prior定义为: g J e f f ( μ ) = I μ 1 2 (3.17) g^{\rm Jeff}(\mu)=\mathcal{I}_\mu^{\frac{1}{2}}\tag{3.17} gJeff(μ)=Iμ21(3.17)事实上 I \mathcal{I} I约等于最大似然估计 μ ^ \hat\mu μ^的方差 σ μ 2 \sigma_\mu^2 σμ2的倒数, 因此也可以表示为: g J e f f ( μ ) = 1 σ μ (3.18) g^{\rm Jeff}(\mu)=\frac{1}{\sigma_\mu}\tag{3.18} gJeff(μ)=σμ1(3.18)
- 这里提到Formula 3.11中哪个复杂的 θ ^ \hat\theta θ^估计值的标准差为: σ θ = c ( 1 − θ 2 ) (3.19) \sigma_\theta=c(1-\theta^2)\tag{3.19} σθ=c(1−θ2)(3.19)事实上这里的系数 c c c对贝叶斯法则(Formular 3.5与Formular 3.6是没有影响的);、
- Figure 3.2中的参数 θ \theta θ的贝叶斯置信区间为 [ 0.093 , 0.750 ] [0.093,0.750] [0.093,0.750], 即 ∫ 0.093 0.750 g J e f f ( θ ∣ θ ^ ) d θ = 0.95 (3.20) \int_{0.093}^{0.750}g^{\rm Jeff}(\theta|\hat\theta){\rm d}\theta=0.95\tag{3.20} ∫0.0930.750gJeff(θ∣θ^)dθ=0.95(3.20)
- Chapter 4中会讨论多参数分布族, 比如观测到的10个独立样本均值是不相同的: x i ∼ N ( μ i , 1 ) i = 1 , 2 , . . . , 10 (3.21) x_i\sim\mathcal{N}(\mu_i,1)\quad i=1,2,...,10\tag{3.21} xi∼N(μi,1)i=1,2,...,10(3.21)此时这10个问题的不仅每一个Jeffreys prior都是flat(这样就可以分开考虑每一个问题), 而且它们的联合Jeffreys prior也是flat: g ( μ 1 , μ 2 , . . . , μ 10 ) = c o n s t a n t (3.22) g(\mu_1,\mu_2,...,\mu_{10})=\rm constant\tag{3.22} g(μ1,μ2,...,μ10)=constant(3.22)显然计算机时代更多得是考虑Formular 3.21而非Formular 3.11这样的问题, 事实上无信息先验, 包括Jeffreys prior都是实际应用中非常流行的方法, 这使得贝叶斯学派与频率学派相互影响, 后者的目的是控制前者可能发生的推断偏差;
3.3 频率推断的缺陷 Flaws in Frequentist Inference
本节以一个案例分析来说明频率推断的缺陷;
- 电压计案例:
- 一个工程师测量12个管道的电压, 使用一个标准刻度的电压计: x ∼ N ( μ , 1 ) (3.23) x\sim\mathcal{N}(\mu,1)\tag{3.23} x∼N(μ,1)(3.23)其中 x x x是测量结果, μ \mu μ是真实地电压值, 测量结果从82~99波动, 均值 x ˉ = 92 \bar x=92 xˉ=92, 工程师将均值作为 μ \mu μ的无偏估计值来报告;
- 第二天他发现电压计出了问题, 任何高于100伏的测量结果都只会显示为100伏, 于是频率学派的统计家告诉工程师 x ˉ = 92 \bar x=92 xˉ=92已经不再是无偏估计量了, 因为Formula 3.23不再能完全描述这组样本的概率分布, 事实上 x ˉ = 92 \bar x=92 xˉ=92已经偏小了;
- 显然我们直到电压计的问题并没有影响观测样本的准确性, 这使得工程师非常困扰, 此时贝叶斯学派的统计学家来解救工程师, 根据后验分布 g ( μ ∣ x ) = g ( μ ) f μ ( x ) f ( x ) , 其 中 g(\mu|\bm{x})=\frac{g(\mu)f_\mu(\bm{x})}{f(\bm{x})}, 其中 g(μ∣x)=f(x)g(μ)fμ(x),其中\bm{x} 为 观 测 到 的 测 量 结 果 , 因 此 后 验 分 布 = = 只 与 观 测 到 样 本 为观测到的测量结果, 因此后验分布==只与观测到样本 为观测到的测量结果,因此后验分布==只与观测到样本\bm{x}$有关, 与其他没有观测到的数据是无关的==;
- 此时使用Jeffreys prior: g ( μ ) = c o n s t a n t g(\mu)=\rm constant g(μ)=constant仍然得到 μ \mu μ的估计值为 x ˉ = 92 \bar x=92 xˉ=92, 与电压计是否出了故障是无关的;
- Figure 3.3中给出了一种相对自然的案例: 一个正在进行的实验, 每个月会观测到一个独立的正态分布变量:
x
i
∼
N
(
μ
,
1
)
(3.24)
x_i\sim\mathcal{N}(\mu,1)\tag{3.24}
xi∼N(μ,1)(3.24)

- 此时我们给出一个假设检验: H 0 : μ = 0 v . s . H 1 : μ > 0 H_0:\mu=0\space{\rm v.s.}\space H_1:\mu>0 H0:μ=0 v.s. H1:μ>0, 则Figure 3.3中绘制的散点是检验统计量: Z i = ∑ j = 1 i x j i (3.25) Z_i=\frac{\sum_{j=1}^ix_j}{\sqrt{i}}\tag{3.25} Zi=i∑j=1ixj(3.25)即一种基于直到第 i i i个月的数据计算出的 z z z值: Z i ∼ N ( i μ , 1 ) (3.26) Z_i\sim\mathcal{N}(\sqrt{i}\mu,1)\tag{3.26} Zi∼N(iμ,1)(3.26)
- 到第30个月时, 发现 Z 30 = 1.66 Z_{30}=1.66 Z30=1.66, 刚好超过了 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1)的 95 % 95\% 95%分位点 1.645 1.645 1.645, 于是观察员宣布可以以0.05的显著水平拒绝零假设;
- 然而不幸的是, 观察员没有遵守协定, 而想在第20个月时终止了这个昂贵的实验, 然后这是徒劳, 因为 Z 2 0 = 0.79 Z_20=0.79 Z20=0.79并没有达到预定的显著水平, 于是仍然按照原计划实验进行到第30个月; 于是实验停止的条件变为了 Z 2 0 Z_20 Z20或 Z 3 0 Z_30 Z30的显著水平达标; 通过计算可以发现此时拒绝零假设(当零假设为真时)的概率是 0.074 0.074 0.074而非 0.05 0.05 0.05;
- 此时贝叶斯学派的统计学家就出来说, 全数据集 x = ( x 1 , x 2 , . . . , x 30 ) \bm{x}=(x_1,x_2,...,x_{30}) x=(x1,x2,...,x30)的似然函数为: L x ( μ ) ∏ i = 1 30 e − 1 2 ( x i − μ ) 2 (3.27) L_{\bm{x}}(\mu)\prod_{i=1}^{30}e^{-\frac{1}{2}(x_i-\mu)^2}\tag{3.27} Lx(μ)i=1∏30e−21(xi−μ)2(3.27)将保持不变, 无论该实验是否提早停止了;
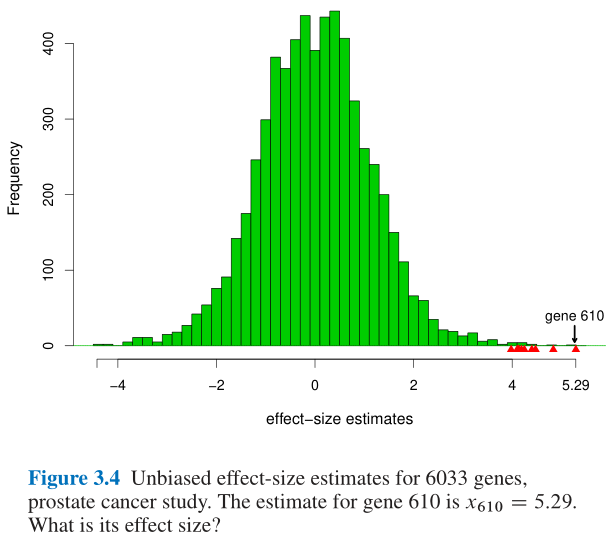
- Figure 3.4又给出了另一个案例: 此处不再赘述, 详见教材P33;
3.4 贝叶斯学派与频率学派的比较清单 A Bayesian/Frequentist Comparison List
- Figure 3.5: 贝叶斯推断是纵向进行的, 而频率推断是横向进行的;
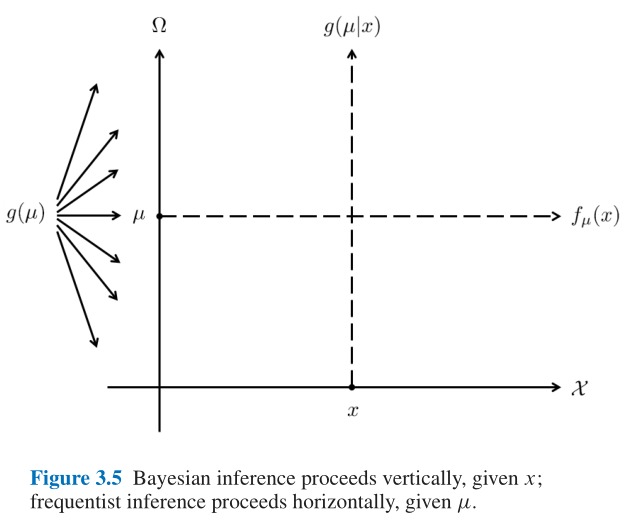
- 贝叶斯学派: 固定 x x x, 根据后验分布 g ( μ ∣ x ) g(\mu|x) g(μ∣x);
- 频率学派: 固定 μ \mu μ, 调整 x x x;
- 比较清单:
- (1) 贝叶斯推断需要先验分布 g ( μ ) g(\mu) g(μ);
- (2) 频率用一种算法 t ( x ) t(x) t(x)来取代先验来解决特定问题;
- (3) 现代的方法, 如逻辑回归与回归树, 将融合入频率学派, 这就要比贝叶斯学派更加灵活;
- (4) 给定先验分布 g ( μ ) g(\mu) g(μ)后, 后验分布 g ( μ ∣ x ) g(\mu|x) g(μ∣x)是唯一确定的;
- (5) 贝叶斯学派将身家性命都赌在先验分布是正确的前提假设下了, 这是很危险的做法; 频率学派则相对保守, 他们尽力地做更好, 但是至少不会做得太差, 无论 μ \mu μ长什么样子;
- (6) 贝叶斯学派一次性回答完所有可能的问题, 而频率学派着重于最需要解决地问题;
- (7) 相对来说贝叶斯学派的方法更简单, 也更吸引人;
- (8) 在没有可信的先验信息时, 也可以使用无信息先验来解决问题;
4 费雪推断与最大似然估计 Fisherian Inference and Maximum Likelihood Estimation
4.1 似然与最大似然 Likelihood and Maximum Likelihood
- 对数似然函数: l x ( μ ) = log { f μ ( x ) } (4.1) l_x(\mu)=\log\{f_\mu(x)\}\tag{4.1} lx(μ)=log{fμ(x)}(4.1)
- 最大似然估计量: M L E : μ ^ = arg max μ ∈ Ω { l x ( μ ) } (4.2) {\rm MLE}:\hat\mu=\argmax_{\mu\in\Omega}\{l_x(\mu)\}\tag{4.2} MLE:μ^=μ∈Ωargmax{lx(μ)}(4.2)
- 事实上 μ ^ \hat\mu μ^未必存在, 或者可能存在多个最大值点, 但是此处仍然假设 μ ^ \hat\mu μ^是唯一存在的;
- 对于最大似然估计量的函数值 θ = T ( μ ) \theta=T(\mu) θ=T(μ), 可以使用plug-in principle进行最大似然估计: θ ^ = T ( μ ^ ) (4.3) \hat\theta=T(\hat\mu)\tag{4.3} θ^=T(μ^)(4.3)
- 最大似然估计流行的三个原因:
- (1) MLE算法可以自动化运行, 很容易写成脚本;
- (2) MLE的频率学性质非常好, 在大样本的情况下几乎是无偏的, 且MLE的方差也基本是最小的;
- 根据Cram-Rao lower bound定理, 估计量 θ ^ \hat\theta θ^的下届为: v a r θ ( θ ^ ) ≥ 1 n I θ (4.33) var_\theta(\hat\theta)\ge\frac{1}{n\mathcal{I}_\theta}\tag{4.33} varθ(θ^)≥nIθ1(4.33), 恰为MLE渐近分布的方差;
- (3) MLE又合理的贝叶斯转换形式, 在贝叶斯法则(Formualr 3.7)中有: g ( μ ∣ x ) = c x g ( μ ) e l x ( μ ) (4.4) g(\mu|x)=c_xg(\mu)e^{l_x(\mu)}\tag{4.4} g(μ∣x)=cxg(μ)elx(μ)(4.4)我们发现如果先验分布 g ( μ ) g(\mu) g(μ)是均匀分布的常数, 则 μ ^ \hat\mu μ^是后验密度 g ( μ ∣ x ) g(\mu|x) g(μ∣x)的最大值点;
- 但是当未知参数很多时, MLE的效果就会很差;
4.2 费雪信息量与最大似然估计 Fisher Information and the MLE
- 定义得分函数: l ˙ x ( θ ) = ∂ ∂ θ log f θ ( x ) = ( ˙ f ) θ f θ ( x ) (4.14) \dot{l}_x(\theta)=\frac{\partial}{\partial\theta}\log f_\theta(x)=\frac{\dot(f)_\theta}{f_\theta(x)}\tag{4.14} l˙x(θ)=∂θ∂logfθ(x)=fθ(x)(˙f)θ(4.14)其中函数上方加一个点表示对 θ \theta θ求偏导;
- (1) 得分函数的期望为零: ∫ X l ˙ x ( θ ) f θ ( x ) d x = ∫ ( X ) f ˙ θ ( x ) d x = ∂ ∂ θ ∫ X f θ ( x ) d x = ∂ ∂ θ 1 = 0 (4.15) \int_{\mathcal{X}}\dot{l}_x(\theta)f_\theta(x){\rm d}x=\int_{\mathcal(X)}\dot{f}_\theta(x){\rm d}x=\frac{\partial}{\partial\theta}\int_{\mathcal{X}}f_\theta(x){\rm d}x=\frac{\partial}{\partial\theta}1=0\tag{4.15} ∫Xl˙x(θ)fθ(x)dx=∫(X)f˙θ(x)dx=∂θ∂∫Xfθ(x)dx=∂θ∂1=0(4.15)
- (2) 定义费雪信息量: I θ = ∫ X l ˙ x ( θ ) 2 f θ ( x ) d x (4.16) \mathcal{I}_\theta=\int_{\mathcal{X}}\dot{l}_x(\theta)^2f_\theta(x){\rm d}x\tag{4.16} Iθ=∫Xl˙x(θ)2fθ(x)dx(4.16)则有得分函数的分布为: l ˙ x ( θ ) ∼ ( 0 , I θ ) (4.17) \dot{l}_x(\theta)\sim(0,\mathcal{I}_\theta)\tag{4.17} l˙x(θ)∼(0,Iθ)(4.17)即得分函数的均值为零, 方差为费雪信息量;
- (3) 最大似然估计量 θ ^ \hat\theta θ^近似服从均值为 θ \theta θ, 方差为 1 I θ \frac{1}{\mathcal{I}_\theta} Iθ1的正态分布: θ ^ ∼ ˙ N ( θ , 1 I θ ) (4.18) \hat\theta\dot{\sim}\mathcal{N}(\theta,\frac{1}{\mathcal{I}_\theta})\tag{4.18} θ^∼˙N(θ,Iθ1)(4.18)
- (4) 得分函数关于 θ \theta θ再求一次偏导(即对数似然函数关于 θ \theta θ的二次偏导)的期望值为KaTeX parse error: Expected 'EOF', got '}' at position 20: …thcal{I}_\theta}̲:KaTeX parse error: Expected group after '\right' at position 40: …x(\theta)\right}̲=-\mathcal{I}_\…
- 总体(样本容量为 n n n)信息量是单个样本信息量的 n n n倍;
- 关于Cram-Rao lower bound定理的证明: ∫ ( t ( x ) − θ ) 2 f θ ( x ) d x ∫ l ˙ x ( θ ) 2 f θ ( x ) d x ≥ [ ∫ ( t ( x ) − θ ) l ˙ x ( θ ) f θ ( x ) d x ] = 1 \int(t(\bm{x})-\theta)^2f_\theta(\bm{x})\mathrm{d}\bm{x}\int\dot{l}_{\bm{x}}(\theta)^2f_\theta(\bm{x})\mathrm{d}\bm{x}\ge\left[\int(t(\bm{x})-\theta)\dot{l}_{\bm{x}}(\theta)f_\theta(\bm{x})\mathrm{d}\bm{x}\right]=1 ∫(t(x)−θ)2fθ(x)dx∫l˙x(θ)2fθ(x)dx≥[∫(t(x)−θ)l˙x(θ)fθ(x)dx]=1其中 x = ( x 1 , x 2 , . . . , x n ) \bm{x}=(x_1,x_2,...,x_n) x=(x1,x2,...,xn)为样本数据集, 这里使用的是柯西不等式;
4.3 条件推断 Conditional Inference
- 一个简单的示例:
- 假定一组独立同分布样本:
x
i
∼
N
(
θ
,
1
)
i
=
1
,
2
,
.
.
.
,
n
(4.34)
x_i\sim\mathcal{N}(\theta,1)\quad i=1,2,...,n\tag{4.34}
xi∼N(θ,1)i=1,2,...,n(4.34)取
θ
\theta
θ的估计量
θ
^
=
x
ˉ
\hat\theta=\bar x
θ^=xˉ, 观察员通过抛硬币的方式来决定究竟进行多少次采样:
n
=
25
p
r
o
b
a
b
i
l
i
t
y
1
2
n
=
100
p
r
o
b
a
b
i
l
i
t
y
1
2
(4.35)
n=25\quad{\rm probability}\space\frac{1}{2}\\n=100\quad{\rm probability}\space\frac{1}{2}\tag{4.35}
n=25probability 21n=100probability 21(4.35)最终采样结果是
n
=
25
n=25
n=25, 那么问题来了,
θ
^
=
x
ˉ
\hat\theta=\bar x
θ^=xˉ的标准差是多少?
- 如果是 1 / 25 = 0.2 1/\sqrt{25}=0.2 1/25=0.2, 那么费雪就会赞成你, 这是一个条件推断;
- 如果是 [ ( 0.01 + 0.04 ) / 2 ] 1 / 2 = 0.158 [(0.01+0.04)/2]^{1/2}=0.158 [(0.01+0.04)/2]1/2=0.158, 这就是非条件的频率学派做出的回答;
- 另一个示例:
- 对于线性回归分析中, 我们想要计算线性回归方程 y = r x , y ( x ) y=r_{\bm{x},\bm{y}}(x) y=rx,y(x)的精确性, 其中 x \bm{x} x与 y \bm{y} y分别为观测到的平行样本;
- 考虑这个问题时我们通常是固定 x \bm{x} x就是我们所观察到的值, 然后再去计算回归方程的精确性; 这也是条件推断的例子;
- 费雪认为条件推断是更加合理的:
- (1) More relevant inferences: 这显然是相关性更高的推断方式;
- (1) Simpler inferences: 至少在计算上也是更加容易的, 如在线性回归示例中我们无需考虑不同协变量的相关性;
4.4 置换与随机化 Permutation and Randomization
- 费雪学派的方法论因为过度依赖正态样本的假设而被批判;
- 以之前提到的白血病案例, 47个 A L L \rm ALL ALL与25个 A M L \rm AML AML患者(Figure 1.1), 两样本 t t t检验的结果为 t t t值3.13, 双侧显著水平为 0.0025 0.0025 0.0025, 这些都是基于高斯或者正态的假设;
- 费雪提出使用置换方法处理这72个患者样本, 即每次随机分为47个和25个的不相交集合, 然后重复
B
B
B次
t
t
t值计算, 得到了
B
B
B个不同的
t
t
t值序列
t
1
∗
,
t
2
∗
,
.
.
.
,
t
B
∗
t_1^*,t_2^*,...,t_B^*
t1∗,t2∗,...,tB∗, 则双侧置换显著水平就是:
c
o
u
n
t
(
{
∣
t
i
∗
∣
≥
t
}
)
B
\frac{{\rm count}(\{|t_i^*|\ge t\})}{B}
Bcount({∣ti∗∣≥t})
- 即是多次实验取均值, 这样得出的结果是 t t t值3.13, 置换显著水平为 0.0022 0.0022 0.0022
- 费雪对置换显著水平的可信度做出解释:
- 假设我们零下架是72个独立同分布的样本: x i ∼ f μ ( x ) i = 1 , 2 , . . . , n x_i\sim f_\mu(x)\quad i=1,2,...,n xi∼fμ(x)i=1,2,...,n这里没有正态假设, 但是我们还是默认 f μ ( x ) f_\mu(x) fμ(x)就是 N ( θ , σ 2 ) \mathcal{N}(\theta,\sigma^2) N(θ,σ2);
- 假设 o \bm{o} o是观测样本集合 x \bm{x} x的次序统计量, 不妨设是从小到大排列的结果, 然后去除了各自的 A L L \rm ALL ALL和 A M L \rm AML AML标签; 那么就有 72 ! / ( 47 ! 25 ! ) 72!/(47!25!) 72!/(47!25!)中方法通过划分 o \bm{o} o成为不相交的子集(子集元素个数分别为47与25个), 来获得 x \bm{x} x, 且这些概率是相同的;
5 参数化模型与指数分布族 Parametric Models and Exponential Families
5.1 单变量分布族 Univariate Families

5.2 多元正态分布 The Multivariate Normal Distribution
- 多元正态分布的密度函数:
- (1) 独立同分布;
- (2) 非独立且分布不同的;
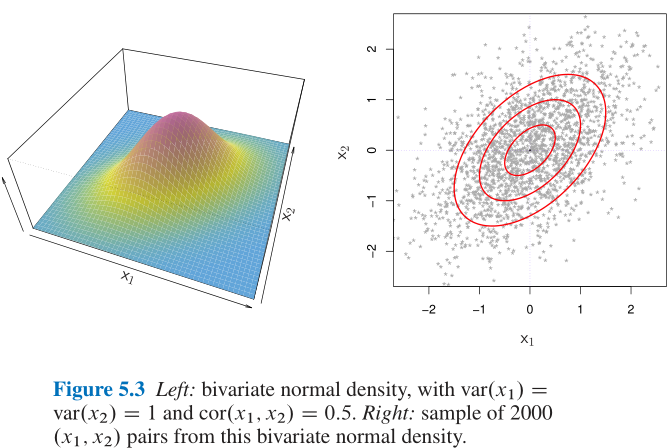
- 关于多元变量分割的问题, 值得好好看看, 非常的有意思, 但是推导也很复杂;
5.3 多参数分布族的费雪信息量的边界 Fisher’s Information Bound for Multiparameter Families
- 费雪信息量向多元推广的结果;
- 最大似然估计量在多参数下的推广及结论;
5.4 多项分布 The Multinomial Distribution

5.5 指数分布族 Exponential Families
- 指数分布族的性质;
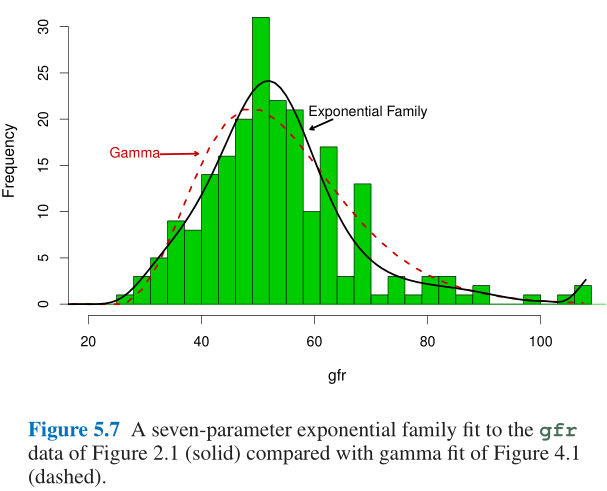
PART 2 早期计算机时代的方法 Early Computer-Age Methods
6 经验贝叶斯 Empirical Bayes
- 经验贝叶斯是起源于二十世纪四十年代的理论;
- 经验贝叶斯面临的问题与其说是理论计算, 不如说是数据集的缺乏;
- Chapter 15-21中的现代方法为经验贝叶斯提供更多有利的解决方案;
6.1 罗宾公式 Robbins’ Formula
- 车险理赔案例:
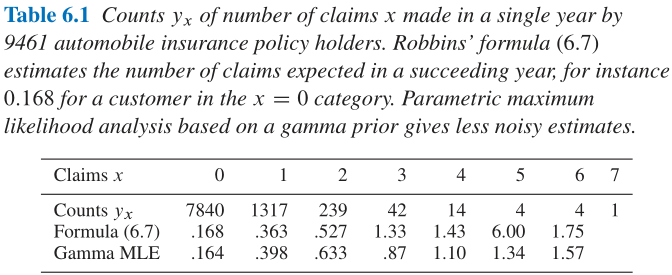
- Table 6.1
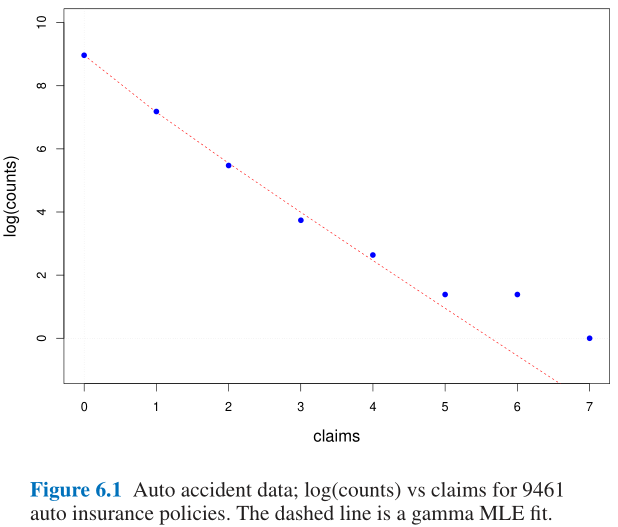
- Figure 6.1
6.2 消失的物种问题 The Missing-Species Problem
- 一个科学家在无人岛上被困了一年, 于是他在这一年时间里观察蝴蝶, 得到了Table 6.2中的数据, x x x表示被观察到的次数, y y y表示蝴蝶的类别的数量, 如有118种蝴蝶只被观察到1次, 而有3种蝴蝶被观察到24次; 一年后这位科学家获救离开了这座无人岛;
- 那么如果这个科学家再被困一年, 他还能发现多少新的蝴蝶物种?

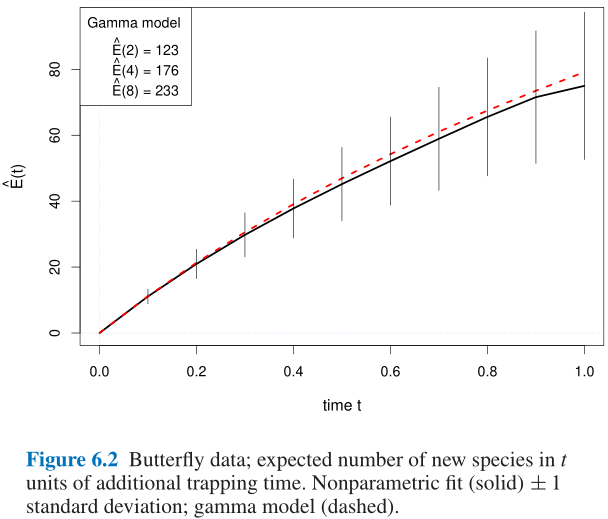
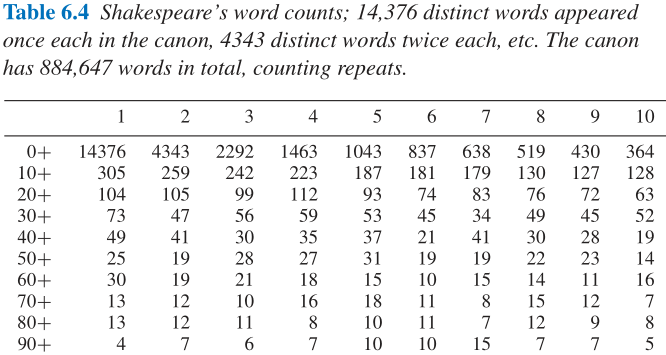
6.3 一个医学问题示例 A Medical Example
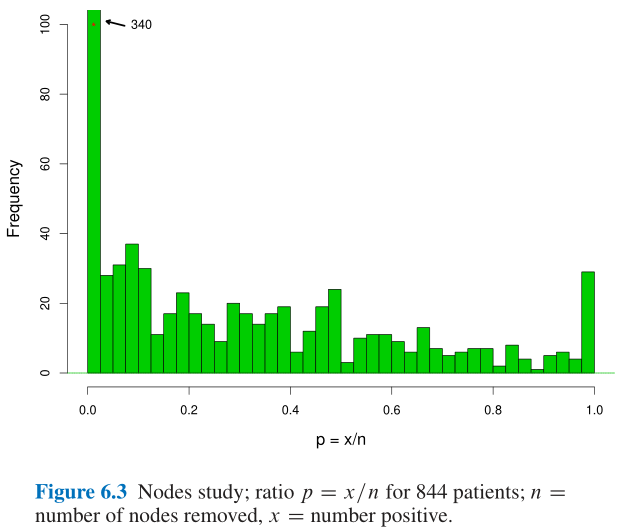
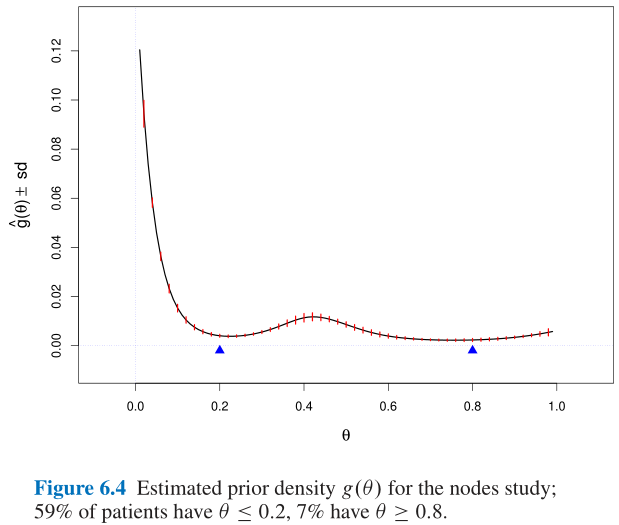
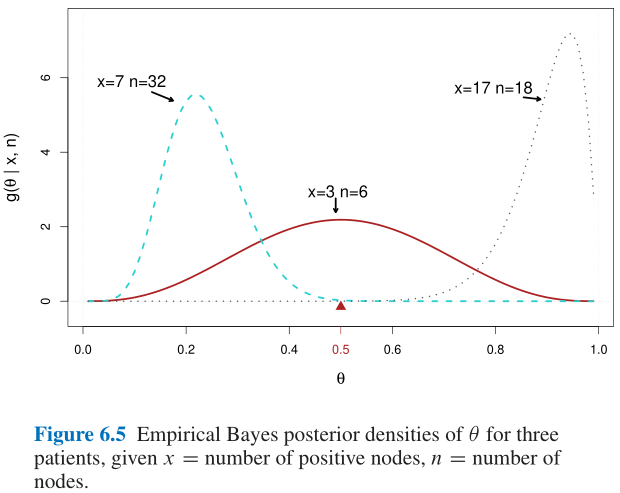
6.4 间接证据1 Indirect Evidence 1
7 詹姆斯——斯坦因估计与岭回归 James–Stein Estimation and Ridge Regression
- 最大似然估计的近似无偏性其实在多参数情况下容易使得估计效果非常差, 有时候我们需要舍弃一些无偏性而博取更多的延展性(确切地说就是为了减小拟合结果的均方误差), 在机器学习上可以认为最大似然估计在多参数的情况下容易发生过拟合导致模型在测试集上的预测效果非常的差;
7.1 詹姆斯——斯坦因估计量 The James–Stein Estimator
- JS估计量就是先验贝叶斯方法的产物, 该估计量的目的是牺牲最大似然估计的无偏性以使得估计量具有较好的均方误差;
7.2 棒球运动员 The Baseball Players

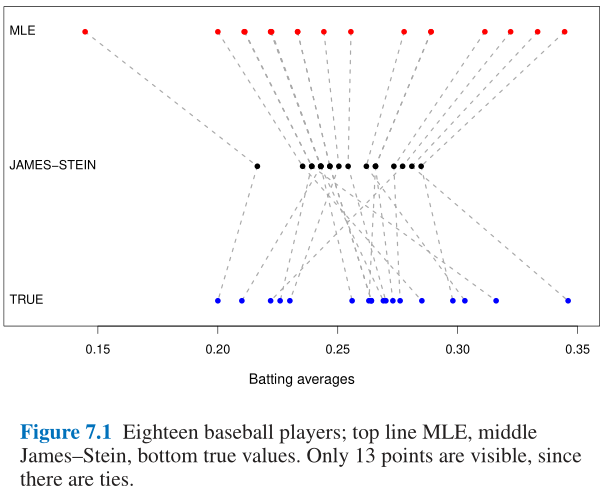
7.3 岭回归 Ridge Regression
- 岭回归简述:
- 岭回归是用于共线性数据分析的一种有偏估计方法, 它通过放弃最小二乘估计中部分的无偏性, 以损失部分精度为代价, 获得更可靠的回归系数;
- 虽然最小二乘估计量是所有线性估计量中方差最小的, 但是这个方差仍然可能较大, 而我们可以找到一个有偏估计量, 它的精度却远远高于无偏估计量, 岭回归就是通过在回归方程中引入有偏常数来实现这一点:
- 线性回归方程: y = X β + ϵ \bm{y}=\bm{X}\beta+\bm{\epsilon} y=Xβ+ϵ通常使用 β ^ = arg min β { ∥ y − X β ∥ 2 } \hat\beta=\argmin_{\beta}\left\{\left\|\bm{y}-\bm{X}\beta\right\|^2\right\} β^=βargmin{∥y−Xβ∥2}来估计 β \beta β的值: β ^ = ( X ⊤ X ) − 1 X ⊤ y \hat\beta=(\bm{X}^\top\bm{X})^{-1}\bm{X}^\top\bm{y} β^=(X⊤X)−1X⊤y但是当 X ⊤ X \bm{X}^\top\bm{X} X⊤X的行列式接近零时, ( X ⊤ X ) − 1 (\bm{X}^\top\bm{X})^{-1} (X⊤X)−1的误差会非常大, 传统的最小二乘法将不再适合用于参数估计; 此时我们可以引入一个正则项, 得到: β ^ = arg min β { ∥ y − X β ∥ 2 + ∥ Γ β ∥ 2 } \hat\beta=\argmin_{\beta}\left\{\left\|\bm{y}-\bm{X}\beta\right\|^2+\left\|\bm{\Gamma}\beta\right\|^2\right\} β^=βargmin{∥y−Xβ∥2+∥Γβ∥2}来解决这个问题; 如设 Γ = α I \bm{\Gamma}=\alpha\bm{I} Γ=αI, 那么就可以得到 β ^ = ( X ⊤ X + α I ) − 1 X ⊤ y \hat\beta=(\bm{X}^\top\bm{X}+\alpha\bm{I})^{-1}\bm{X}^\top\bm{y} β^=(X⊤X+αI)−1X⊤y这样就可以解决上面的问题, 且当 α \alpha α增大, 估计值 β ^ \hat\beta β^的相对于真实值的偏差也会越来越大, 这就是岭回归法;
7.4 间接证据2 Indirect Evidence 2
8 广义线性回归与回归树 Generalized Linear Models and Regression Trees
8.1 逻辑回归 Logistic Regression
- 逻辑回归(logistic regression)是一种专门用于频数或频率型数据的回归分析方法; 其中的logit参数 λ \lambda λ定义为: λ = log { π 1 − π } (8.4) \lambda=\log\left\{\frac{\pi}{1-\pi}\right\}\tag{8.4} λ=log{1−ππ}(8.4)其中 π \pi π为计数事件发生的频率, 即二项分布 B i ( n , p ) Bi(n,p) Bi(n,p)中的概率参数 p p p; 当 π \pi π从 0 0 0变化到 1 1 1时, logit参数 λ \lambda λ从 − ∞ -\infty −∞变化到 + ∞ +\infty +∞;
- 究其本质, 逻辑回归就是假设应变量 π \pi π与自变量 x x x间的关系并非线性, 因此构造 λ \lambda λ使得 λ \lambda λ与 x x x之间的存在线性关系, 然后通过拟合 λ \lambda λ与 x x x, 再根据 λ \lambda λ与 π \pi π之间的关系来解决 π \pi π与 x x x之间的回归方程;
- 从结果上来看, 逻辑回归的目标函数是最小化Kullback–Leibler距离; 因此也是可以与Lasso回归等添加正则项的方法相结合; 本质上逻辑回归中的训练参数与线性回归中的训练参数是一致的, 正则项可以设为待定参数的某种模数;
- 逻辑回归是广义线性模型的一种特殊情况;
- 逻辑回归中的link function是:
g
(
y
)
=
e
y
e
y
+
1
g(y)=\frac{e^y}{e^y+1}
g(y)=ey+1ey
- link function的反函数称为logit function: g − 1 ( θ ) = log { θ 1 − θ } g^{-1}(\theta)=\log\left\{\frac{\theta}{1-\theta}\right\} g−1(θ)=log{1−θθ}其中 θ 1 − θ \frac{\theta}{1-\theta} 1−θθ称为odds;
- 估计参数 θ \theta θ的表达式可以写作: θ ( X ) = g ( X β ) = e X β 1 + e X β = 1 1 + e − X β \theta(\bm{X})=g(\bm{X}\beta)=\frac{e^{\bm{X}\beta}}{1+e^{\bm{X}\beta}}=\frac{1}{1+e^{-\bm{X}\beta}} θ(X)=g(Xβ)=1+eXβeXβ=1+e−Xβ1
- 逻辑回归的本质是在最小化KL距离;
8.2 广义线性模型 Generalized Linear Models
- 这部分简单来说就是针对指数分布族: f ( y ) = e λ y − b ( λ ) f(y)=e^{\lambda y-b(\lambda)} f(y)=eλy−b(λ)构建自然参数 λ \lambda λ与充分统计量 y y y之间的线性回归;
- 如逻辑回归就是将二项分布 B ( n , π ) B(n,\pi) B(n,π)的自然参数 λ = log π 1 − p i \lambda=\log\frac{\pi}{1-pi} λ=log1−piπ与自然参数 y = x y=x y=x之间构建线性回归; 同理泊松回归针对的即为泊松分布 P o i ( θ ) {\rm Poi}(\theta) Poi(θ)下的自然参数 λ = log θ \lambda=\log\theta λ=logθ与充分统计量 y = x y=x y=x之间构建线性回归;

8.3 泊松分布 Poisson Regression
-
其实可以发现, 所谓的link function就是Table 8.4中的自然参数 λ \lambda λ的表达式, 它的反函数就是link function, 所以泊松回归的link function就是 λ ( X β ) = e X β \lambda(\bm{X}\beta)=e^{\bm{X}\beta} λ(Xβ)=eXβ, 其中 Y ∼ P o i s s o n ( λ ) Y\sim{\rm Poisson}(\lambda) Y∼Poisson(λ);
-
对于泊松回归的误差值可以用 Z = s i g n ( y − μ ^ ) D ( y , μ ^ ) 1 2 (8.41) Z={\rm sign}(y-\hat\mu)D(y,\hat\mu)^{\frac{1}{2}}\tag{8.41} Z=sign(y−μ^)D(y,μ^)21(8.41)来衡量, 其中 D ( y , μ ^ ) D(y,\hat\mu) D(y,μ^)可以从Table 8.4中获得计算公式, 在本节的谱线红移案例中可以将 S = ∑ j k Z j k 2 S=\sum_{jk}Z_{jk}^2 S=∑jkZjk2作为总误差值, 其实这个数值非常的大( S = 610 S=610 S=610), 所以在实际回归分析中需要通过加入更多的高次项, 来扩充解释变量 X \bm{X} X的维度;
8.4 回归树 Regression Trees
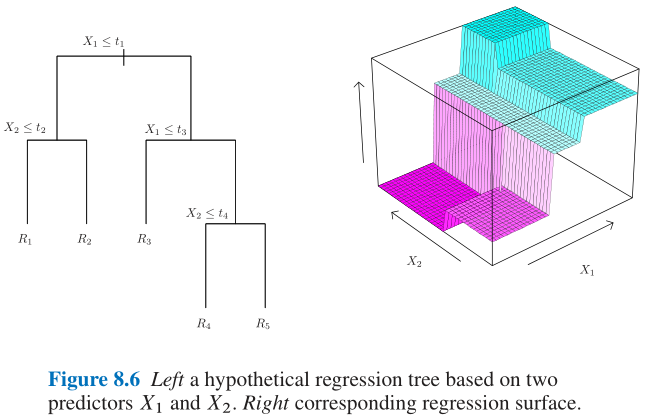
-
书上介绍的是CART算法, 即每次分枝的目标函数是使得两个新叶子节点下的两个样本的样本方差值之和尽可能的小; 最终停止条件由交叉验证结果决定, 回归预测值由叶子节点中的所有样本均值决定; 还是比较简单的;
-
回归树的性质:
- (1) 回归树是具有较强的可解释性;
- (2) 回归树得到的regression surface是不连续的, 如Figure 8.6所示;
- (3) 与广义线性模型想必, 回归树是完全无参的(nonparametric);
9 生存分析与期望最大化算法 Survival Analysis and the EM Algorithm
- 本章李卫明没有讲;
- 生存分析大致是几何分布问题, 即事件第一次发生的时间点分布;
- 期望最大化算法即经典的EM算法, 这个在网上可以寻找到大量的实例;
9.1 寿命表与危险率 Life Tables and Hazard Rates
9.2 删失数据与卡普兰——梅尔估计 Censored Data and the Kaplan–Meier Estimate
9.3 对数排名检验 The Log-Rank Test
9.4 比例危险模型 The Proportional Hazards Model
9.5 数据缺失与期望最大化算法 Missing Data and the EM Algorithm
10 刀切法与自助法 The Jackknife and the Bootstrap
- jackknif: 利用计算机来进行标准误差计算的无公式化方法;
- bootstrap: 进一步利用计算机来实现一大批包括标准误差在内的推断的自动化计算;
10.1 刀切法估计的标准误差 The Jackknife Estimate of Standard Error
- 注意Jackknife相对于Bootstrap的标准误差要反直觉一些:
- 后者直接就是标准差的计算方法, 除以 B − 1 B-1 B−1;
- 前者则是乘以 n n − 1 \frac{n}{n-1} n−1n;
- jackknife的标准误差本质是方向导数;
10.2 无参自助法 The Nonparametric Bootstrap
- 无参自助法意思是直接以采得的样本构建虚拟分布 F ^ \hat F F^(比如 n n n个样本则得到分布列为 n n n的等权离散分布), 从该虚拟分布中重采样进行分析;
- 有参自助法则是基于已知样本服从的分布 F F F(如已知样本是来自正态分布), 但是 F F F中存在未知参数(如正态分布的均值参数未知), 可使用已知样本将未知参数估计出来(使用最大似然估计), 然后从确定参数的 F F F中进行重采样分析;
10.3 重采样计划 Resampling Plans
- 本节讲述的是非等权重重采样的结果, 事实上jackknife可以视为一种非等权重重采样的bootstrap;
10.4 有参自助法 The Parametric Bootstrap
- 见本章第一节关于有参自助法的描述;
10.5 影响函数与鲁棒估计 Influence Functions and Robust Estimation
- 非常困难, 完全不能理解;
11 自助法的置信区间 Bootstrap Confidence Intervals
11.1 黎曼对于单参数问题的构建 Neyman’s Construction for One-Parameter Problems
- 本节就是在讲置信区间的传统求解方法(默认正态分布, 正负1.96个标准误差);
11.2 分位数方法 The Percentile Method
-
常规的正常的置信区间分位数求法;
-
这里提到可以用bootstrap方法来估计分位数;
11.3 偏差矫正后的置信区间 Bias-Corrected Confidence Intervals
- 事实上bootstrap方法所得到的置信区间偏高, 需要做相应的调整;
11.4 二次精确度 Second-Order Accuracy
- 这里主要是 B C a \rm BC_a BCa方法, 即上一节 B C \rm BC BC方法的改良版本;
11.5 自助法的 t t t区间 Bootstrap- t t t Intervals
- **Bootstrap- t t t**区间是通过多次重采样, 得出 t t t统计量在仿真结果上的分位数结果, 然后根据这个分位数来决定置信区间;
11.6 目标贝叶斯区间与置信分布 Objective Bayes Intervals and the Confidence Distribution
- 贝叶斯置信区间的求法, 重点就是要找到Formular 11.63中的置信密度(confidence)函数 g ~ x ( θ ) \tilde{g}_\bm{x}(\theta) g~x(θ), 然后在这个置信密度函数上两边分别割掉面积为 0.025 0.025 0.025的长尾, 中间剩下的区间就是 95 % 95\% 95%的置信区间;
12 交叉检验与预测误差的 C p C_p Cp估计 Cross-Validation and C p C_p Cp Estimates of Prediction Error
- 本章着重研究如何对预测模型的预测结果进行精确性的估计:
- (1) 方法一: 传统的交叉验证, 这种方法广泛使用, 且是完全无参数化的(nonparametric);
- (2) 方法二: 两种应用场景相对较少的, 但是效果非常好的参数化方法;
- ① 马洛斯 C p C_p Cp估计量: Mallows’ C p C_p Cp estimate;
- ② 赤池信息准则(AIC): Akaike Information Criterion;
12.1 预测规则 Prediction Rules
-
典型的预测问题一般是根据一个有 N N N个样本对的训练集: d = { ( x i , y i ) , i = 1 , 2 , . . . , N } (12.1) \bm{d}=\{(x_i,y_i),i=1,2,...,N\}\tag{12.1} d={(xi,yi),i=1,2,...,N}(12.1)其中 x i x_i xi是一个包含 p p p个预测因子(predictors)的向量, y i y_i yi是一个真实的标签值(response); 通过训练集 d \bm{d} d学习到一个预测规则(prediction rule) r d ( x ) r_\bm{d}(x) rd(x), 使得可以在样本空间 X \mathcal{X} X上进行预测: y ^ = r d ( x ) x ∈ X (12.2) \hat y=r_\bm{d}(x)\quad x\in\mathcal{X}\tag{12.2} y^=rd(x)x∈X(12.2)推断任务是评估该预测规则 r d ( x ) r_\bm{d}(x) rd(x)的精确度;
-
常用的预测误差评估方法:
- (1) 平方误差: D ( y , y ^ ) = ( y − y ^ ) 2 (12.4) D(y,\hat y)=(y-\hat y)^2\tag{12.4} D(y,y^)=(y−y^)2(12.4)
- (2) 分类误差: D ( y , y ^ 2 ) = { 1 i f y ≠ y ^ 0 i f y = y ^ (12.5) D(y,\hat y2)=\left\{\begin{aligned}1\quad{\rm if}\space y\neq\hat y\\0\quad{\rm if}\space y=\hat y\end{aligned}\right.\tag{12.5} D(y,y^2)={1if y=y^0if y=y^(12.5)
- 假设训练集 d \bm{d} d中的每一对数据 ( x i , y i ) (x_i,y_i) (xi,yi)都是从某个定义在 R p + 1 \mathcal{R}^{p+1} Rp+1上的分布 F F F中随机采样得到的: ( x i , y i ) ∼ i i d F i = 1 , 2 , . . . , N (12.6) (x_i,y_i)\overset{iid}{\sim}F\quad i=1,2,...,N\tag{12.6} (xi,yi)∼iidFi=1,2,...,N(12.6)
- true error rate: r d ( x ) r_\bm{d}(x) rd(x)的真实误差率 E r r d {\rm Err}_\bm{d} Errd定义如下: E r r d = E F { D ( y 0 , y ^ 0 ) } (12.7) {\rm Err}_\bm{d}=E_F\{D(y_0,\hat y_0)\}\tag{12.7} Errd=EF{D(y0,y^0)}(12.7)其中 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)是从分布 F F F中独立于训练集 b m d bm{d} bmd随机采样得到的一个随机样本; 预测值 y ^ 0 = r d ( x 0 ) \hat y_0=r_\bm{d}(x_0) y^0=rd(x0)通过训练得到的预测规则 r d r_\bm{d} rd生成;
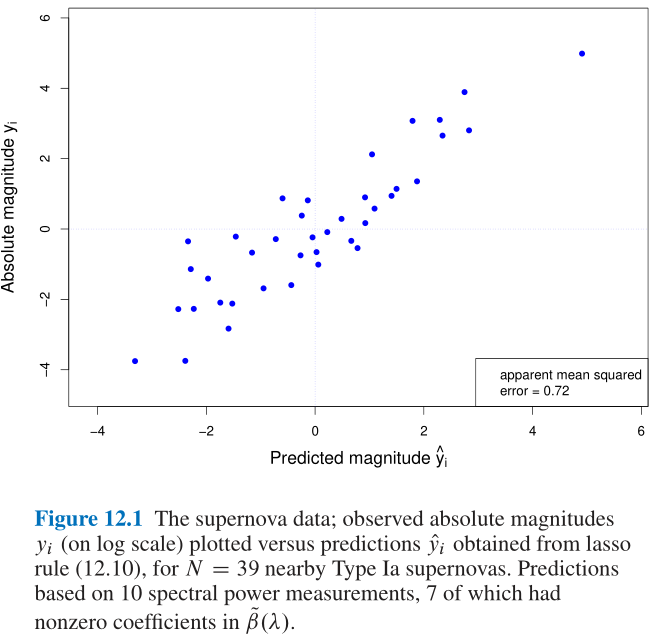
- Figure 12.1中给出了一组超新星数据的散点图;
12.2 交叉检验 Cross-Validation
- 留一法与K折法;
12.3 协方差惩罚 Covariance Penalties
- 协方差惩罚指预测模型在训练集上和测试集上误差值之间的差距, 测试集上的误差当然要比训练集上大, 因为训练集的目标就是减少损失函数值(误差值为两倍的协方差), 正如P.219的引理Formula 12.39所示;
12.4 训练, 验证与短暂预测因子 Training, Validation, and Ephemeral Predictors
- 跳过, 暂时觉得用处不大;
13 目标贝叶斯推断与马尔科夫链蒙特卡洛法 Objective Bayes Inference and MCMC
13.1 目标先验分布 Objective Prior Distributions
13.2 共轭先验分布 Conjugate Prior Distributions
13.3 模型选择与贝叶斯信息标准 Model Selection and the Bayesian Information Criterion
13.4 基比斯采样与马尔科夫链蒙特卡洛法 Gibbs Sampling and MCMC
13.5 示例: 人口混合建模 Example: Modeling Population Admixture
14 战后统计推断与方法论 Postwar Statistical Inference and Methodology
PART 3 二十一世纪的话题 Twenty-First-Century Topics
15 大规模假设检验与错误发现率 Large-Scale Hypothesis Testing and FDRs
15.1 大规模检验 Large-Scale Testing
15.2 错误发现率 False-Discovery Rates
15.3 经验贝叶斯与大规模检验 Empirical Bayes Large-Scale Testing
15.4 局部错误发现率 Local False-Discovery Rates
15.5 零分布下的选择 Choice of the Null Distribution
15.6 相关性 Relevance
16 稀疏建模与最小绝对收缩和选择运算符 Sparse Modeling and the Lasso
16.1 前向逐步回归 Forward Stepwise Regression
16.2 最小绝对收缩和选择运算符 The Lasso
16.3 拟合Lasso模型 Fitting Lasso Models
16.4 最小角度回归 Least-Angle Regression
16.5 拟合广义Lasso模型 Fitting Generalized Lasso Models
16.6 Lasso的后选择推断 Post-Selection Inference for the Lasso
16.7 联系与拓展 Connections and Extensions
17 随机森林与提升方法 Random Forests and Boosting
17.1 随机森林 Random Forests
17.2 使用平方误差损失函数来提升 Boosting with Squared-Error Loss
17.3 梯度提升 Gradient Boosting
17.4 最初的提升算法 Adaboost: the Original Boosting Algorithm
17.5 联系与拓展 Connections and Extensions
18 神经网络与深度学习 Neural Networks and Deep Learning
- 神经网络概述:
- 20世纪80年代, 神经网络的提出震惊了应用统计学界;
- 神经网络是一种高度参数化的(highly parametrized)模型;
- Figuer 18.1中是最简单的前馈神经网络示意图:
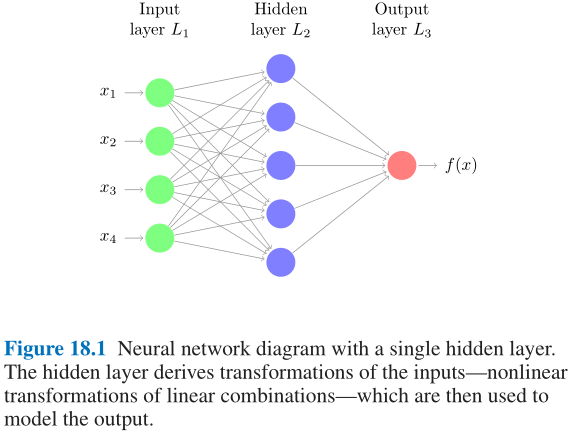
- 其中模型输入包含4个预测因子(predictors), 隐层节点共计5个, 最终输出为单个标量值; 具体计算公式如下:
- 模型输入张量: ( x 1 , x 2 , x 3 , x 4 ) (x_1,x_2,x_3,x_4) (x1,x2,x3,x4)
- 计算隐层状态: a l = g ( w l 0 ( 1 ) + ∑ j = 1 4 w l j ( 1 ) x j ) a_l=g(w_{l0}^{(1)}+\sum_{j=1}^4w_{lj}^{(1)}x_j) al=g(wl0(1)+∑j=14wlj(1)xj)
- 计算输出标量: o = h ( w 0 ( 2 ) + ∑ l = 1 5 w l ( 2 ) a l ) o=h(w_0^{(2)}+\sum_{l=1}^5w_l^{(2)}a_l) o=h(w0(2)+∑l=15wl(2)al)
- 上述公式中:
- 称 g g g与 h h h为激活函数, 通常为非线性函数; 常见的激活函数有Sigmoid, ReLU, Softmax;
- 称 a l a_l al称为神经元(neurons); 神经元从数据中学习新特征的过程称为监督学习(supervised learning);
- 每个神经元通过训练参数 { w l j ( 1 ) } 1 p \{w_{lj}^{(1)}\}_1^p {wlj(1)}1p相互联系, 其中上标 ( 1 ) (1) (1)表示这是第 1 1 1层, 下标 l j lj lj表示这是第 j j j个变量的第 l l l个训练参数; 特别地, 截距项 w l 0 ( 1 ) w_{l0}^{(1)} wl0(1)称偏差(bias);
- 其中模型输入包含4个预测因子(predictors), 隐层节点共计5个, 最终输出为单个标量值; 具体计算公式如下:
- 本质上神经网络就是一种非线性模型, 与其他线性模型的推广(广义线性模型等)并没有什么区别, 但是它确实给学界注入新鲜能量;
- 20世纪90年代, 随着boosting方法(Chapter 17)与支持向量机(Chapter 19)的兴起, 神经网络由于其解释性的缺乏逐渐没落;
- 2010年之后, 神经网络又突然以深度学习(deep learning)的身份重生, 再次制霸各类分类预测领域, 如图像与音像数据分类, 自然语言处理等;
18.1 神经网络与手写数字问题 Neural Networks and the Handwritten Digit Problem
- 本节从光学字符识别(optical character recognition, 下简称为OCR)任务中进行牛刀小式(积累一个俚语表达: cut one’s baby teeth);
- Figure 18.2是经典手写数字数据集MNIST中的样例(该数据集可以直接通过Python的keras库模块中的相关模块获得:
from keras.datasets import mnist, sklearn库中也有相应的接口):

- 每张手写数字图像为 28 × 28 = 784 28\times28=784 28×28=784像素的黑白图片: x ∈ R 28 × 28 x\in\mathbb{R}^{28\times28} x∈R28×28
- 每个像素点的取值范围是 { 0 , 1 , 2 , . . . , 255 } \{0,1,2,...,255\} {0,1,2,...,255}的八位二进制表示;
- 每张手写数字图像的分类标签 C ( x ) ∈ { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 } C(x)\in\{0,1,2,3,4,5,6,7,8,9\} C(x)∈{0,1,2,3,4,5,6,7,8,9};
- 训练集有 60000 60000 60000张图像, 测试集有 10000 10000 10000张图像;
- 神经网络的目的即是学习概率函数 Pr ( y = j ∣ x ) , j = 0 , 1 , 2 , . . . , 9 \Pr(y=j|x),j=0,1,2,...,9 Pr(y=j∣x),j=0,1,2,...,9
- Figure 18.3中的3层隐层架构神经网络就是典型的用于处理这种手写数字识别的经典神经网络配置:
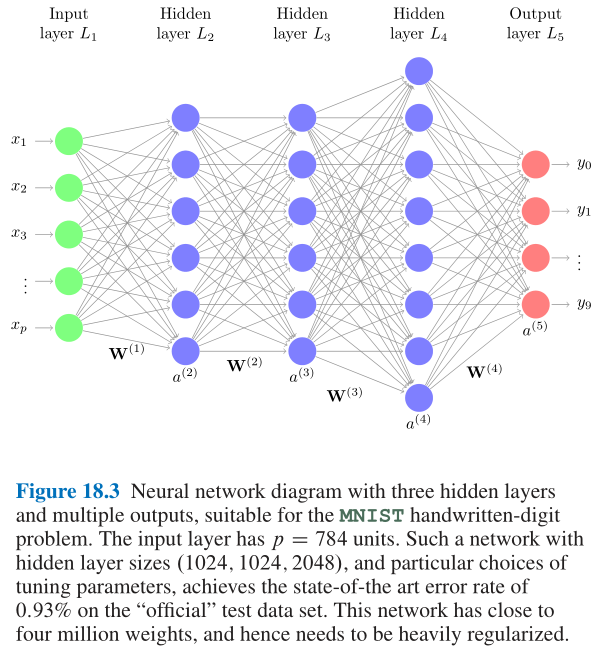
- 第 1 1 1层到第 2 2 2层可以表达为: z l ( 2 ) = w l 0 ( 1 ) + ∑ j = 1 p w l j ( 1 ) x j (18.1) z_l^{(2)}=w_{l0}^{(1)}+\sum_{j=1}^pw_{lj}^{(1)}x_j\tag{18.1} zl(2)=wl0(1)+j=1∑pwlj(1)xj(18.1) a l ( 2 ) = g ( 2 ) ( z l ( 2 ) ) (18.2) a_l^{(2)}=g^{(2)}(z_l^{(2)})\tag{18.2} al(2)=g(2)(zl(2))(18.2)同理第 k − 1 k-1 k−1层到第 k k k层可以表达为: z l ( k ) = w l 0 ( k − 1 ) + ∑ j = 1 p k − 1 w l j ( k − 1 ) a j ( k − 1 ) (18.3) z_l^{(k)}=w_{l0}^{(k-1)}+\sum_{j=1}^{p_k-1}w_{lj}^{(k-1)}a_j^{(k-1)}\tag{18.3} zl(k)=wl0(k−1)+j=1∑pk−1wlj(k−1)aj(k−1)(18.3) a l ( k ) = g ( k ) ( z l ( k ) ) (18.4) a_l^{(k)}=g^{(k)}(z_l^{(k)})\tag{18.4} al(k)=g(k)(zl(k))(18.4)将上述公式使用张量表达则可以改写作: z ( k ) = W ( k − 1 ) a ( k − 1 ) (18.5) z^{(k)}=\bm{W}^{(k-1)}a^{(k-1)}\tag{18.5} z(k)=W(k−1)a(k−1)(18.5) a ( k ) = g ( k ) ( z ( k ) ) (18.6) a^{(k)}=g^{(k)}(z^{(k)})\tag{18.6} a(k)=g(k)(z(k))(18.6)其中 W ( k − 1 ) \bm{W}^{(k-1)} W(k−1)就是从网络层 L k − 1 L_{k-1} Lk−1到网络层 L k L_k Lk的权重矩阵, 注意这里已经把偏差截距项 w l 0 ( k − 1 ) w_{l0}^{(k-1)} wl0(k−1)加到 W ( k − 1 ) \bm{W}^{(k-1)} W(k−1)中了, 因此 a ( k ) a^{(k)} a(k)张量的第一个位置是常数 1 1 1;
- 该神经网络的最后输出层是多分类输出, 常见的激活函数为Softmax: g ( K ) ( z m ( K ) ; z ( K ) ) = e z m ( K ) ∑ l = 1 M e z l ( K ) (18.7) g^{(K)}(z_m^{(K)};z^{(K)})=\frac{e^{z_m^{(K)}}}{\sum_{l=1}^Me^{z_l^{(K)}}}\tag{18.7} g(K)(zm(K);z(K))=∑l=1Mezl(K)ezm(K)(18.7)
18.2 拟合神经网络 Fitting a Neural Network
- 拟合神经网络本质是在最小化损失函数与正则项的累和: m i n i m i z e W { 1 n ∑ i = 1 n L [ y i , f ( x i ; W ) ] + λ J ( W ) } (18.8) \mathop{\rm minimize}\limits_{\mathcal{W}}\left\{\frac{1}{n}\sum_{i=1}^nL[y_i,f(x_i;\mathcal{W})]+\lambda J(\mathcal{W})\right\}\tag{18.8} Wminimize{n1i=1∑nL[yi,f(xi;W)]+λJ(W)}(18.8)其中 J ( W ) J(\mathcal{W}) J(W)
- Formular 18.8说明:
- f ( x ; W ) f(x;\mathcal{W}) f(x;W)是神经网络的抽象的表达, 其中 W \mathcal{W} W是神经网络中所有权重矩阵构成的参数集合;
- L [ y , f ( x ) ] L[y,f(x)] L[y,f(x)]为损失函数, 其中 f ( x ) f(x) f(x)即为神经网络的预测值, y y y为真实值(ground truth);
- J ( W ) J(\mathcal{W}) J(W)是一个与权重矩阵构成的参数集合 W \mathcal{W} W相关的非负正则项;
- λ ≥ 0 \lambda\ge0 λ≥0是超参数, 用于控制正则项的权重; 实际情况中可能会有多个正则项, 每个正则项对应不同的超参数 λ \lambda λ;
- 在Chapter 7中的Formular 7.41中提到岭回归的二次正则项: J ( W ) = 1 2 ∑ k = 1 K − 1 ∑ j = 1 p k ∑ l = 1 p k + 1 { w l j ( k ) } 2 (18.9) J(\mathcal{W})=\frac{1}{2}\sum_{k=1}^{K-1}\sum_{j=1}^{p_k}\sum_{l=1}^{p_k+1}\left\{w_{lj}^{(k)}\right\}^2\tag{18.9} J(W)=21k=1∑K−1j=1∑pkl=1∑pk+1{wlj(k)}2(18.9)另外Chapter 16中提到的Lasso回归的惩罚项也是流行的方法;
- 如果是二分类问题, 则可以取损失函数 L L L为Formular 8.14所示的二项偏差(binomial deviance), 此时神经网络等价于带惩罚项的逻辑回归;
- 事实上找到Formular 18.8的全局最优点是非常困难的, 因此我们通常试图取寻找较好的局部最优解, 大部分优化方法都是在梯度下降的基础做一些增强(积累一个俚语表达: bells and whistles);
- 梯度计算: 反向传播(backpropagation);
- Algorithm 18.1中是反向传播算法的详细说明:

- 反向传播算法说明:
- (1) 给定训练集中的一对样本 ( x , y ) (x,y) (x,y), 首先进行在神经网络中进行前馈计算, 此时每层的节点 a l ( k ) a_l^{(k)} al(k)中都被激活, 包括最后的输出层;
- (2) 然后计算输出层的误差项 δ l ( K ) \delta_l^{(K)} δl(K), 这就是简单的预测误差, 如Formular 18.10所示;
- (3) 对于非输出层的隐层, 也可以计算误差项 δ l ( k ) , k = K − 1 , K − 2 , . . . , 2 \delta_l^{(k)},k=K-1,K-2,...,2 δl(k),k=K−1,K−2,...,2, 方法是将输出的误差值反向传播, 以下一层误差值作为该层的输入, 不断将误差传播到输入层, 如Formular 18.11所示;
- (4) 此处的技巧如Formular 18.12所示, 即可以通过残差 δ \delta δ快速计算偏导值;
- 反向传播算法说明:
- 梯度下降:
- (1) 随机梯度下降(SGD): Stochastic Gradient Descent, 每次选取若干参数进行梯度下降, 而非每次优化所有参数, 可以大大降低梯度计算的代价;
- (2) 加速梯度方法(AGM): Accelerated Gradient Methods, 每次梯度下降在约定的下降方向上额外增加步长, 如经典的momentum方法;
- (3) 模拟退火: Rate Annealing, 优化的步长应当逐渐减小;
- 其他调参:
- (1) 隐层节点数量以及隐层的数量;
- (2) 非线性激活函数的选择: sigmoid, tanh, ReLU, leaky recitified linear;
- (3) 正则方法: 使用 l 1 l_1 l1范数还是 l 2 l_2 l2范数作为正则项;
- (4) 提前停止(early stopping): 防止过拟合
18.3 自动编码器 Autoencoders
- 自动编码器有些类似主成分分析的过程, 其目的是将输入特征(难于处理, 维度较高)通过编码与解码得到输出特征(具有良好性质, 便于处理);
18.4 深度学习 Deep Learning
- 这部分讲得太浅, 主要由图像识别展开, 只有CNN中的池化层和卷积层的介绍;
18.5 学习一个深度网络 Learning a Deep Network
- 确实没有讲什么有用的内容, 都是很陈旧的知识了;

















 3757
3757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









