






最近做了个有趣的研究,通过一条街道中连续的街景图像构建空间图表示。
https://github.com/MMHHRR/Restoration_Topology![]() https://github.com/MMHHRR/Restoration_Topology在过去的研究里面,很少考虑到由于场景连续变化对人类感知造成的影响。即使使用CNN或者机器学习这些方法,其实在预测的时候基本上都是单张图片单张图片进行的。这就可能导致由于场景变化对感知的影响被忽略。
https://github.com/MMHHRR/Restoration_Topology在过去的研究里面,很少考虑到由于场景连续变化对人类感知造成的影响。即使使用CNN或者机器学习这些方法,其实在预测的时候基本上都是单张图片单张图片进行的。这就可能导致由于场景变化对感知的影响被忽略。
在我们的研究中,我们首次提出通过提取连续的街景图像的物理元素,构建一个图表征整条街道的空间结构。可以参考我们最近在Arxiv上面的文章。
https://arxiv.org/abs/2311.17361![]() https://arxiv.org/abs/2311.17361
https://arxiv.org/abs/2311.17361
这张图梳理了如何构建图的过程。首先使用语义分割提取街道的物理元素,然后将多个街道的图相加构建一个大图(街道层面)。最后使用CGN提取5维度的相连,表示街道的空间结构。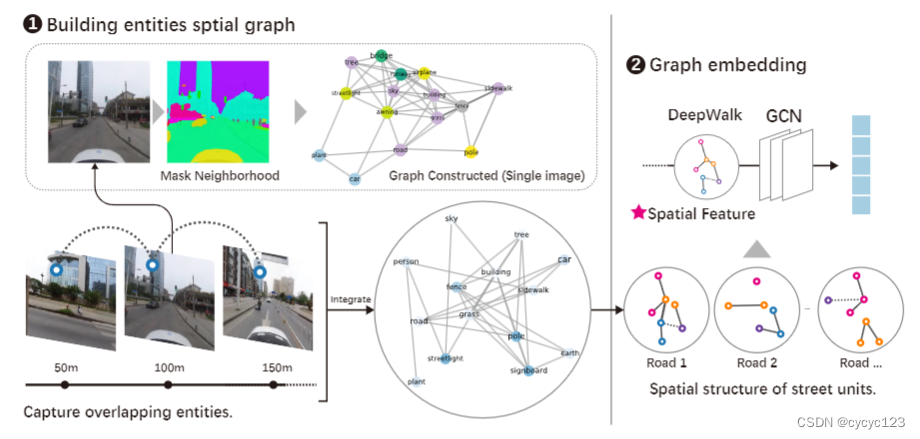
---------------------------------------------------分割线-------------------------------------------------------
1. 首先获取街道实体元素的Mask
def get_mask(image):
inputs = feature_extractor(image, return_tensors="pt").to(model.device)
# 对输入图片进行分割
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
predictions = torch.argmax(logits, dim=1).cpu().numpy().squeeze().astype('uint8') # shape (batch_size, height/4, width/4)
return predictions2. 从单张街景构建图,然后将同一街道的街景图进行组合
def combine_graphs(all_predictions):
G = nx.Graph() # 创建空的大图
all_nodes = [] # 创建空列表用于存储所有节点
for predictions in all_predictions:
mask = predictions
labels = list(np.unique(predictions))
# 创建空的小图
current_graph = nx.Graph()
# 添加节点到小图
for label in labels:
nodes = np.argwhere(mask == label)
centroid = np.mean(nodes, axis=0)
count = len(nodes)
total_count = mask.size
proportion = count / total_count * 100
current_graph.add_node(
label,
centroid=centroid,
label=class_names[label - 1],
proportion=proportion,
)
all_nodes.extend(current_graph.nodes) # 将节点添加到all_nodes列表中
# 添加边到小图
for i, (label_i, data_i) in enumerate(current_graph.nodes(data=True)):
for j, (label_j, data_j) in enumerate(current_graph.nodes(data=True)):
if i >= j:
continue
dist = np.linalg.norm(data_i["centroid"] - data_j["centroid"])
if dist < 42:
current_graph.add_edge(label_i, label_j)
# 将小图中的节点和边合并到大图中
G.add_edges_from(current_graph.edges)
G.add_nodes_from(all_nodes) # 添加所有节点到大图
return G3. 对图进行编码,输出一个5维向量
def get_embedding(G):
# 获取节点数量
num_nodes = G.number_of_nodes()
# 定义嵌入层将特征从 1 维映射到 5 维
in_channels = 5 # 输入特征维度
hidden_channels = 16 # 隐层特征维度
out_channels = 5 # 输出特征维度
edge_index = from_networkx(G).edge_index
data = Data(edge_index=edge_index, num_nodes=num_nodes)
# 定义 GCN 模型
class GCN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super(GCN, self).__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, out_channels)
def forward(self, edge_index):
x = torch.randn(num_nodes, in_channels) # 随机初始化节点特征
x = F.relu(self.conv1(x, edge_index))
x = self.conv2(x, edge_index)
x = F.dropout(x, training=self.training)
x = torch.mean(x, dim=0) # 将所有节点的特征求平均得到图的嵌入向量
x = torch.nn.Linear(x.shape[0], out_channels)(x) # 将嵌入向量映射为输出特征维度
return x
# 初始化 GCN 模型并传入数据进行计算
model = GCN(in_channels, hidden_channels, out_channels)
embedding = model(data.edge_index)
return embedding---------------------------------------------------分割线-------------------------------------------------------
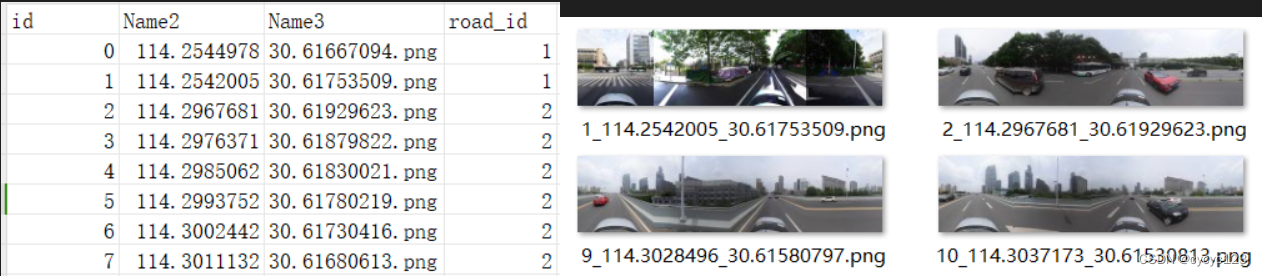
这里给出一个具体的数据结构类型。(生成街道图表示需要一个csv文件和街景图像,csv文件的格式如下所示:每张图的id,经纬度信息要和图像名称一一对应。最主要的是道路的road_id,这个可以使用ArcGIS直接生成就好)
完整代码如下:
import os
import csv
from tqdm import tqdm
import pandas as pd
import networkx as nx
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from torch_geometric.data import Data
from torch_geometric.utils import to_networkx
from torch_geometric.utils import from_networkx
from torch_geometric.nn import GCNConv
# # 加载模型
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").cuda()
model.eval()
# Get list of class names as column names
class_names = list(model.config.id2label.values())[1:]
def get_mask(image):
inputs = feature_extractor(image, return_tensors="pt").to(model.device)
# 对输入图片进行分割
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
predictions = torch.argmax(logits, dim=1).cpu().numpy().squeeze().astype('uint8') # shape (batch_size, height/4, width/4)
return predictions
def combine_graphs(all_predictions):
G = nx.Graph() # 创建空的大图
all_nodes = [] # 创建空列表用于存储所有节点
for predictions in all_predictions:
mask = predictions
labels = list(np.unique(predictions))
# 创建空的小图
current_graph = nx.Graph()
# 添加节点到小图
for label in labels:
nodes = np.argwhere(mask == label)
centroid = np.mean(nodes, axis=0)
count = len(nodes)
total_count = mask.size
proportion = count / total_count * 100
current_graph.add_node(
label,
centroid=centroid,
label=class_names[label - 1],
proportion=proportion,
)
all_nodes.extend(current_graph.nodes) # 将节点添加到all_nodes列表中
# 添加边到小图
for i, (label_i, data_i) in enumerate(current_graph.nodes(data=True)):
for j, (label_j, data_j) in enumerate(current_graph.nodes(data=True)):
if i >= j:
continue
dist = np.linalg.norm(data_i["centroid"] - data_j["centroid"])
if dist < 42:
current_graph.add_edge(label_i, label_j)
# 将小图中的节点和边合并到大图中
G.add_edges_from(current_graph.edges)
G.add_nodes_from(all_nodes) # 添加所有节点到大图
return G
def get_embedding(G):
# 获取节点数量
num_nodes = G.number_of_nodes()
# 定义嵌入层将特征从 1 维映射到 5 维
in_channels = 5 # 输入特征维度
hidden_channels = 16 # 隐层特征维度
out_channels = 5 # 输出特征维度
edge_index = from_networkx(G).edge_index
data = Data(edge_index=edge_index, num_nodes=num_nodes)
# 定义 GCN 模型
class GCN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super(GCN, self).__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, out_channels)
def forward(self, edge_index):
x = torch.randn(num_nodes, in_channels) # 随机初始化节点特征
x = F.relu(self.conv1(x, edge_index))
x = self.conv2(x, edge_index)
x = F.dropout(x, training=self.training)
x = torch.mean(x, dim=0) # 将所有节点的特征求平均得到图的嵌入向量
x = torch.nn.Linear(x.shape[0], out_channels)(x) # 将嵌入向量映射为输出特征维度
return x
# 初始化 GCN 模型并传入数据进行计算
model = GCN(in_channels, hidden_channels, out_channels)
embedding = model(data.edge_index)
return embedding
data = pd.read_csv("E:/Dataset/GNN_Perception/wuhan_badu_SVI/name.csv")
df = pd.DataFrame(data)
folder_path = "E:/Dataset/GNN_Perception/wuhan_badu_SVI/baidu2023_pinjie"
for i in tqdm(range(3)):
result = df[df['road_id'] == i]
predict_set = []
for idx in result.index:
resultssss = result.at[idx, 'Name3']
for filename in os.listdir(folder_path):
file_id = filename.split('_')[2]
if file_id in resultssss:
image = Image.open(os.path.join(folder_path, filename))
predict_set.append(get_mask(image))
G = combine_graphs(predict_set)
embedding = get_embedding(G)
print(embedding)














 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









