







1. 异或号^表示以…开始 , 若在[]中表示取反操作
import re
text = "hello"
res = re.search("^h", text)
res1 = re.search("^e", text)
print(res.group())
print(res1)
输出结果为
h
None
Process finished with exit code 0
2. $表示以…结尾
post = "xxx@163.com"
res = re.search("\w+@163\.com$", post)
print(res.group())
输出结果为
xxx@163.com
Process finished with exit code 0
3. |表示匹配多个字符串或表达式
url = "https"
url1 = "thhp"
res = re.match("(http|https|ftp)$", url)
res1 = re.match("(http|https|ftp)$", url1)
print(res.group())
输出结果为
https
None
Process finished with exit code 0
4. 贪婪模式和非贪婪模式
贪婪模式会匹配符合正则表达式的尽可能长的字符串,而非贪婪模式则会匹配符合正则表达式的尽可能短的字符串
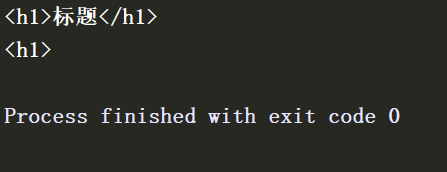
text = "<h1>标题</h1>"
#贪婪模式
res = re.match("<.+>", text)
#非贪婪模式
res1 = re.match("<.+?>", text)
print(res.group())
print(res1.group())
输出结果为















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









