






学了一段时间,这篇博客是在我重新快速地看了一些b站的总结视频而参考着写出来的。(列出一些有被我截图的视频链接)
【什么是CNN?】浙大大佬教你怎么卷CNN,卷积神经网络CNN从入门到实战,通俗易懂草履虫听了都点头(人工智能、深度学习、机器学习、计算机视觉)_哔哩哔哩_bilibili
风中摇曳的小萝卜的个人空间-风中摇曳的小萝卜个人主页-哔哩哔哩视频 (bilibili.com)
1. 基本概念
卷积神经网络(Convolutional Neural Network,CNN)是深度学习领域中一种重要而强大的模型,特别适用于图像处理和计算机视觉任务。
1.1 卷积操作
卷积操作是CNN的核心。这是一种局部感知的过程,通过滤波器在输入数据上进行滑动。滤波器逐步捕捉输入中的局部特征,类似于我们通过窗户看世界一样,逐渐理解整体场景。
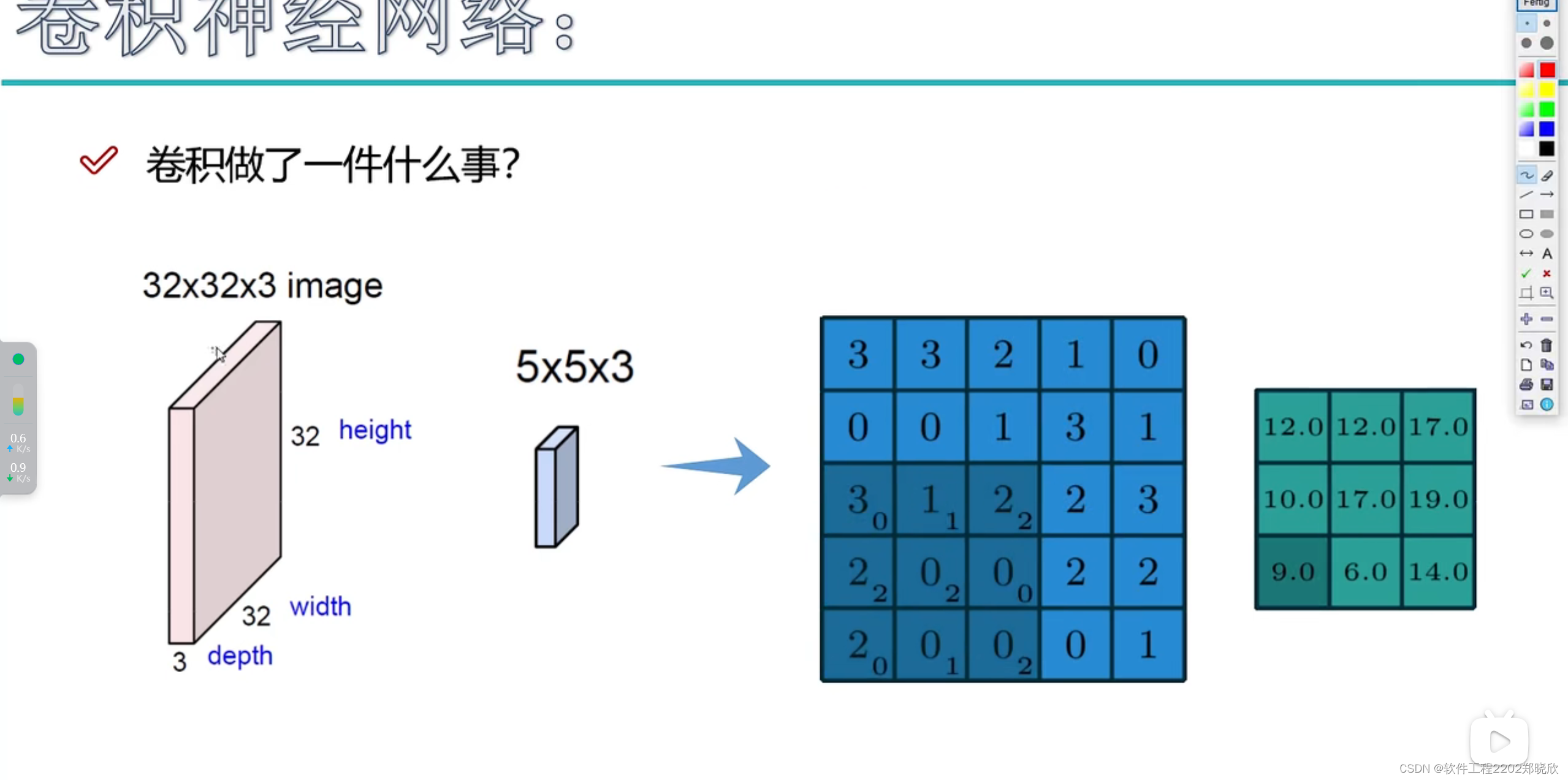
图中粉红色方块是原始的数据,而蓝色的方块最好是理解成3*3*3(因为实际上右边的滤波器是按3*3*3来计算的),这里的蓝色方块的最后一个‘3’(depth),在我的理解里,它应该就是跟这个粉红色方块的‘3’,是需要保持一致的,可根据需要变化的应该是滤波器的长和宽。
卷积运算即是,权重参数矩阵(卷积核大小?)和滤波器所框定的区域进行内积运算(如果有bias,在计算完每一层后记得加上)并把结果填入绿色的方块(特征图)对应位置的过程。
1.2特征图的个数以及运算
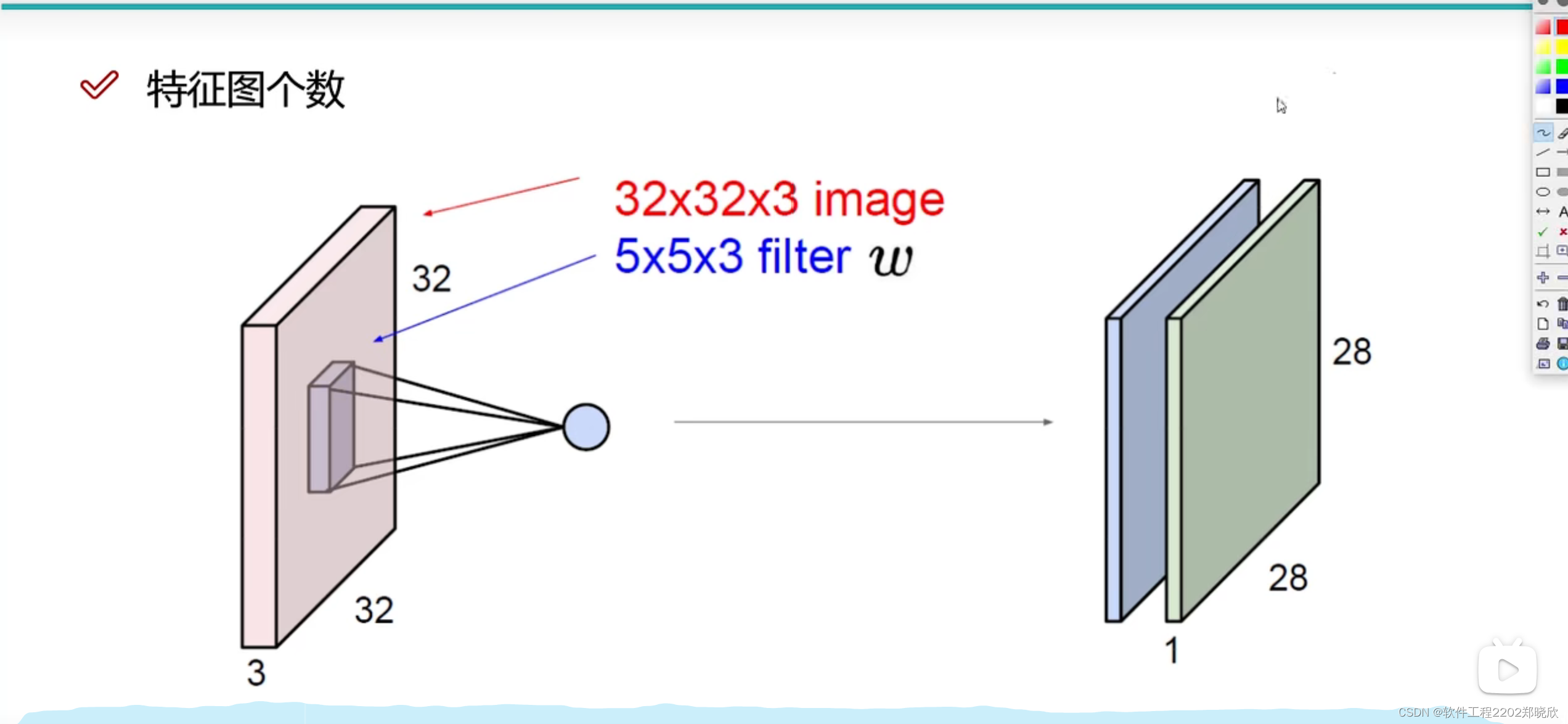
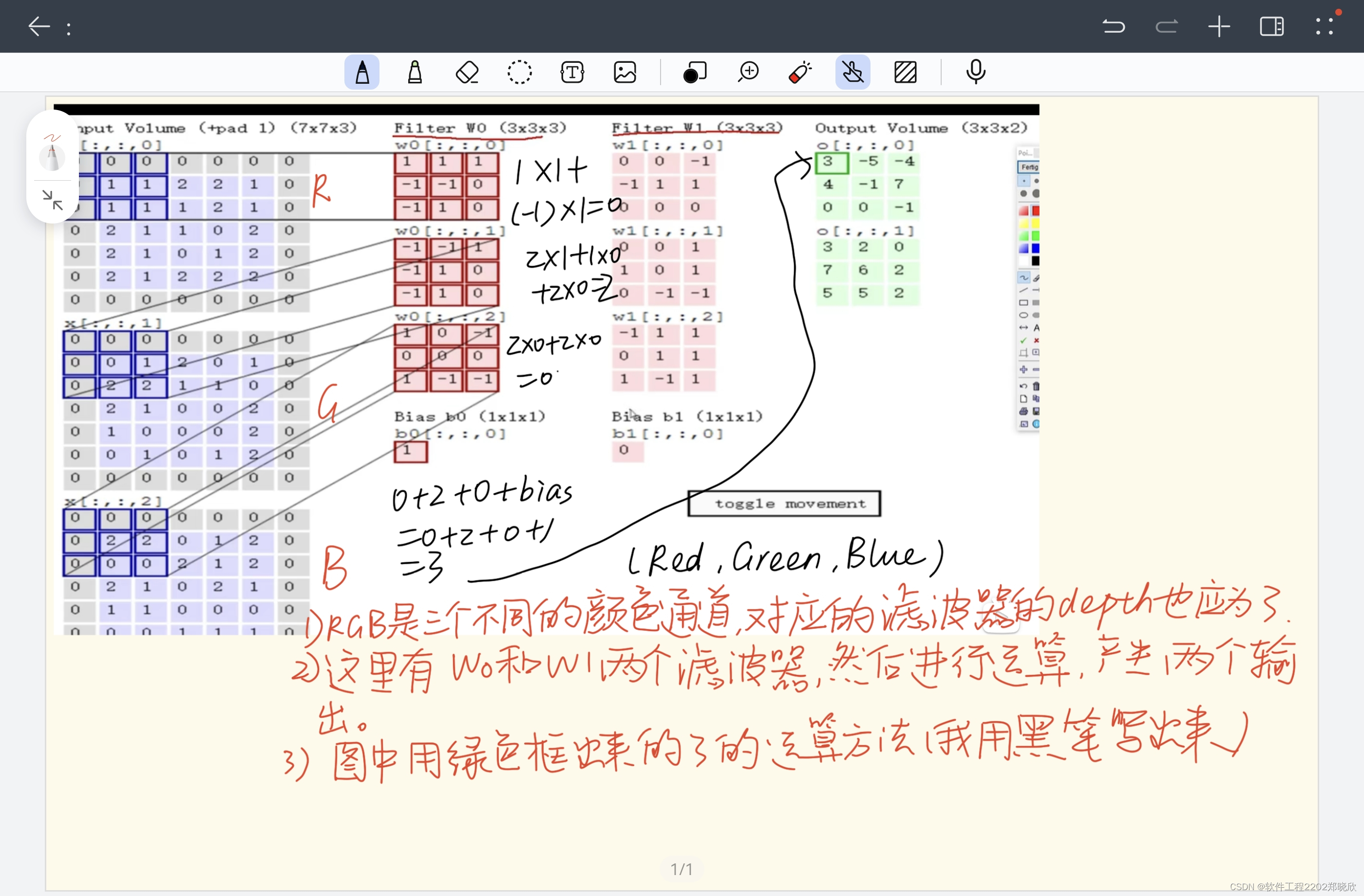
如果有两个滤波器(filter),那么进行卷积、也就是特征提取后就会产生两个不一样的特征图,但是这两个滤波器的规格应该是一致的。(我觉得就是学长当初说的那一句,“滤波器的个数等于输出的通道数”)

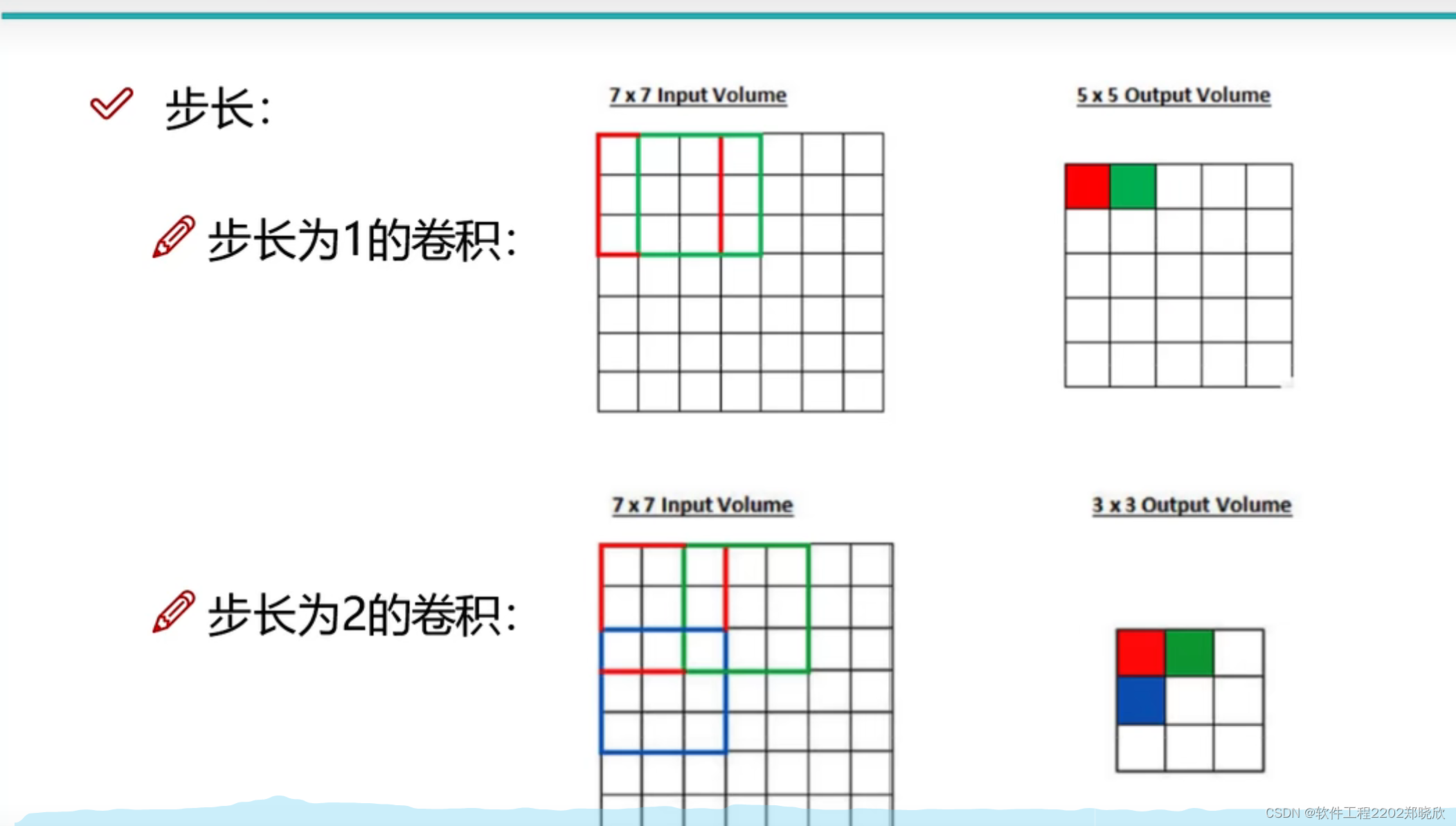
1.3步长与卷积核大小对结果的影响
步长小,得到的特征图比较细腻,但也要考虑效率,步长大得到的特征图则比较粗糙,但相对而言效率比较高。对于卷积核也是一样的!
1.4边缘填充(Pading)以及特征图尺寸的运算
卷积过程中,边界点可能被利用得少,而中间的点对特征图的运算贡献值要大一些,所以为了让所有的值都被利用起来,可以加上边缘值0(加一圈0)进行填充,弥补了一些边界信息缺失的问题。(zeroPading)

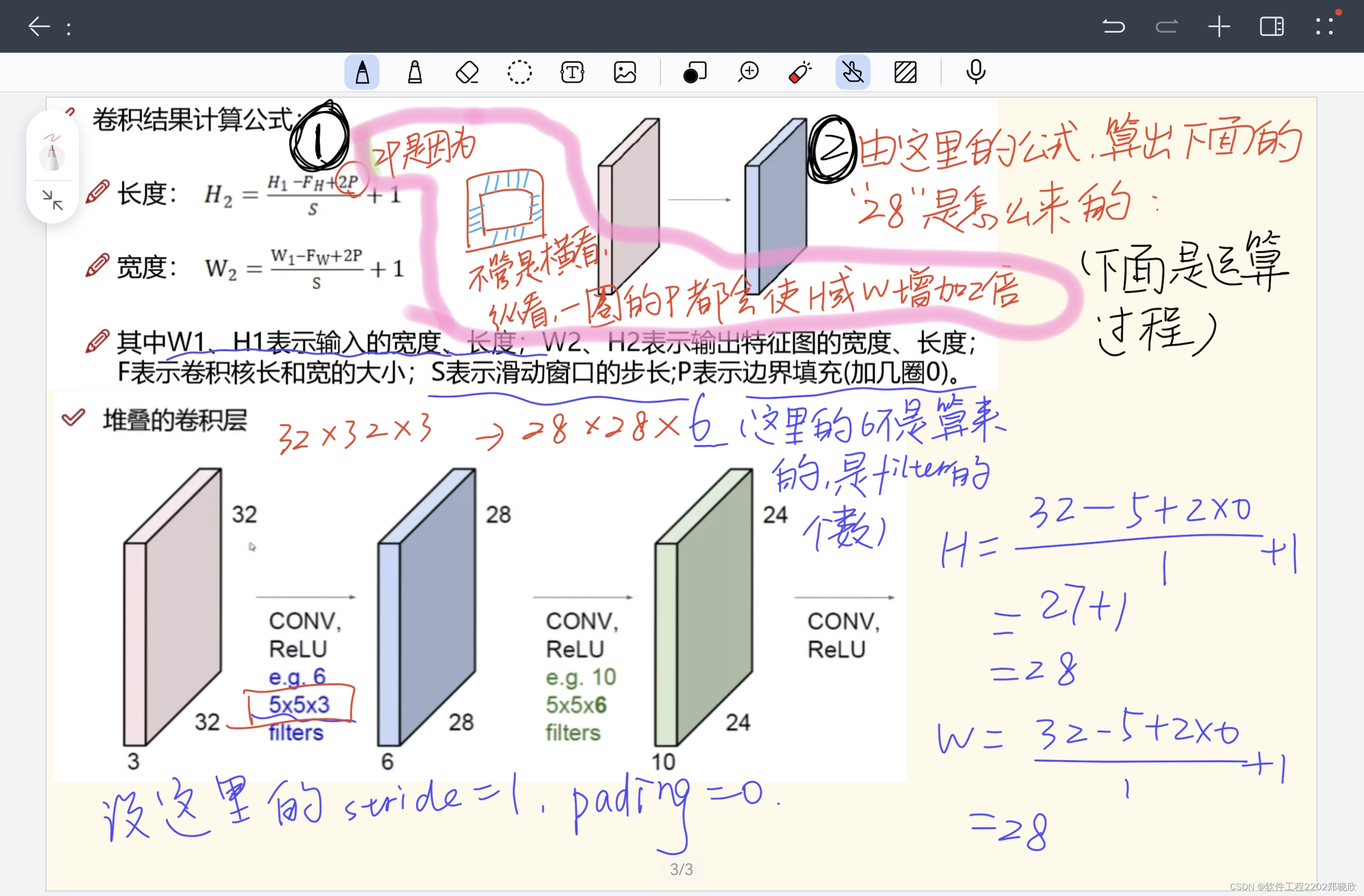
(比如上面的这个图,灰色方块就是边缘填充的部分,而紫色部分则是实际部分。)
1.5激活函数
卷积操作后,激活函数引入了非线性元素。ReLU是一种常用的激活函数,通过保留正值而抑制负值,为网络引入非线性,增强其表达能力。
1.6 池化层(不涉及计算,只是筛选)
紧接着卷积操作,池化层用于下采样,降低特征图的维度。最大池化和平均池化是两种常见的池化方式,有助于保留关键信息并减小计算负担。
MAX POOLING

还有AVERAGE POOLING ,但是在实际应用中,效果没有max pooling 好。
2. 结构设计
2.1 卷积层
卷积层负责提取输入的局部特征。每个卷积层包含多个卷积核,每个卷积核负责捕捉不同的特征。这种共享权重的设计使得网络更具泛化能力。
2.2 池化层
池化层的主要作用是减小特征图的维度,降低计算负担。它通过保留重要信息,实现对图像细节的高效提取。
2.3 全连接层
全连接层将特征图映射到最终输出。把前面的三维的数据拉长为一个特征向量,作为最终的输出。这一层通常用于分类任务,将提取的特征与目标类别建立关联。
ps:
(1)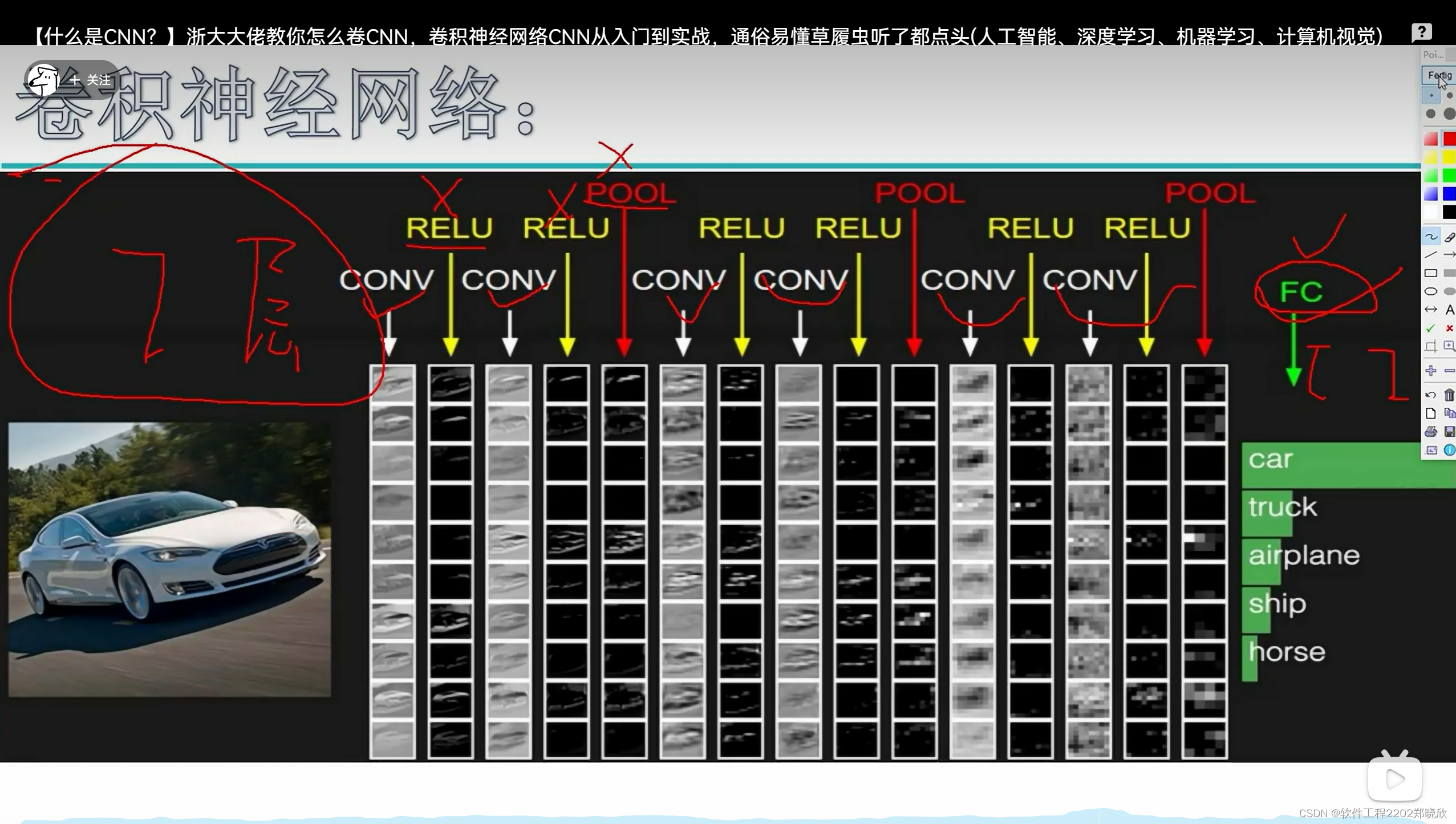
上面这个图是一个七层的神经网络,其中relu(激活函数)和pool(池化)中不涉及参数(运算),所以不算层。只有卷积层和全连接层才算层。(这个概念我记得Lizard那个视频中也讲到过)
(2)
除了上面的内容,还通过视频简单地了解了一下VGG和残差网络Resnet,然后被博主科普了一下“感受野的作用”。
3. 工作原理
CNN通过层层堆叠这些结构,逐渐提取输入数据的抽象特征。卷积操作捕捉局部特征,激活函数引入非线性,池化层降低维度,最终通过全连接层输出结果。这个过程就像是逐步构建对输入的理解模型,从低层次的特征到高层次的抽象表达。

4. 代码实现
#epoch:complete pass through all samples of the training set
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim#这是优化的缩写,这将使我们能够访问优化的内容,我们将使用它来更新权重
import torchvision
import torchvision.transforms as transforms
torch.set_printoptions(linewidth=120)#为我们从pytorch中获得的输出设置行宽
torch.set_grad_enabled(True)#开启了pytorch的梯度跟踪功能,一般在默认情况下就已经开启啦
print(torch.__version__)
print(torchvision.__version__)
def get_num_correct(preds,labels):
return preds.argmax(dim=1).eq(labels).sum().item()
class Network(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6,out_channels=12,kernel_size=5)
self.fc1 = nn.Linear(in_features=12*4*4,out_features=120)
self.fc2 = nn.Linear(in_features=120,out_features=60)
self.out = nn.Linear(in_features=60,out_features=10)
def forward(self,t):
#1.input layer
t = t
#2.hidden conv layer
t = self.conv1(t)
t = F.relu(t)
t = F.max_pool2d(t,kernel_size=2,stride=2)
#3.hidden conv layer
t = self.conv2(t)
t = F.relu(t)
t = F.max_pool2d(t,kernel_size=2,stride=2)
#4.hidden linear layer
t = t.reshape(-1,12*4*4)
t = self.fc1(t)
t = F.relu(t)
#5.hidden linear layer
t = self.fc2(t)
t = F.relu(t)
#6.output layer
t = self.out(t)
return t
train_set = torchvision.datasets.FashionMNIST(
root='./data/FashionMNIST'
,train=True
,download=True
,transform=transforms.Compose([
transforms.ToTensor()
])
)
network = Network()
train_loader = torch.utils.data.DataLoader(train_set,batch_size = 100)
batch = next(iter(train_loader))#Get batch
images,labels = batch
preds = network(images)#Pass the batch
loss = F.cross_entropy(preds,labels)#Calculate the loss
print(loss.item())
print(network.conv1.weight.grad)
print(loss.backward())#Calculate the gradients ,backward是反向传播的简称
print(network.conv1.weight.grad.shape)
optimizer = optim.Adam(network.parameters(),lr = 0.01)#learning rate //为了使这个优化能够更新我们的网络权重,我们需要将网络的参数传递给构造函数
#lr,需要反复调试和尝试。
print(loss.item())
get_num_correct(preds,labels)
print(optimizer.step())#Update the weights,,优化器上的step方法用于更新网络的权重
preds = network(images)
loss = F.cross_entropy(preds,labels)
#交叉熵损失函数,它来自于我们从顶部导入的nn.functional接口
print(loss.item())
get_num_correct(preds,labels)
network = Network()
train_loader = torch.utils.data.DataLoader(train_set,batch_size = 100)
optimizer = optim.Adam(network.parameters(),lr = 0.01)
for epoch in range(5):
total_loss = 0
total_correct = 0
for batch in train_loader:#Get batch
images,labels = batch
preds = network(images)#Pass Batch
loss = F.cross_entropy(preds,labels)#Calculate Loss
optimizer.zero_grad()
loss.backward()#Calculate Gradients
optimizer.step()#Update Weights
total_loss += loss.item()
total_correct += get_num_correct(preds,labels)
print("epoch",epoch,"total_correct:",total_correct,"loss:",total_loss)
'''
epoch 0 total_correct: 47387 loss: 330.6240634024143
epoch 1 total_correct: 51657 loss: 226.34411695599556
epoch 2 total_correct: 52290 loss: 207.49197308719158
epoch 3 total_correct: 52663 loss: 197.28581894934177
epoch 4 total_correct: 52923 loss: 190.03593508899212
'''最后的一点补充:
除了上述内容,我还了解下面的一些知识点。
1.梯度下降算法:(之前看李宏毅的网课就有了一些了解,然后再去B站看了一个视频,加深了理解)

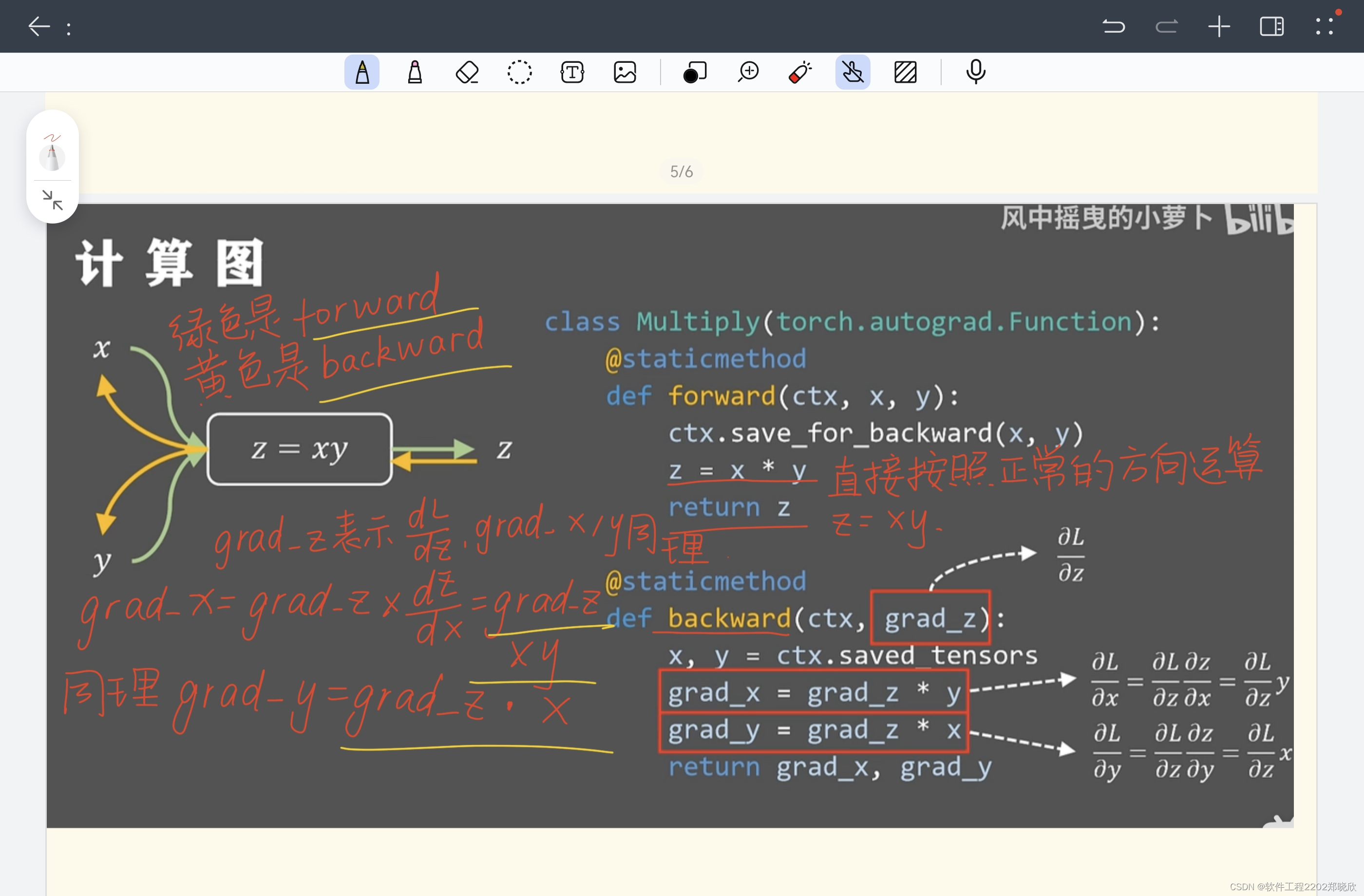
2.前向传播和反向传播
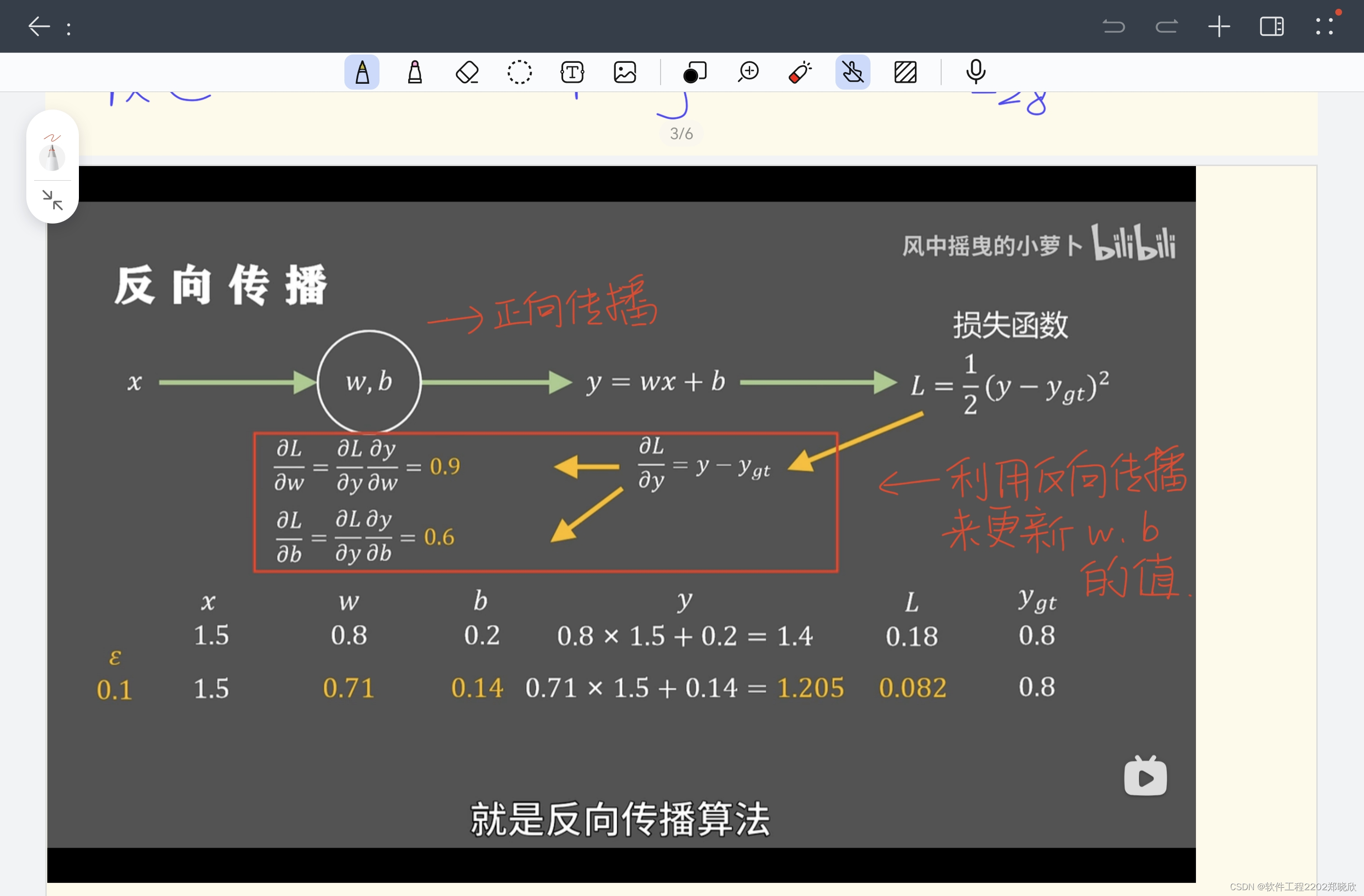
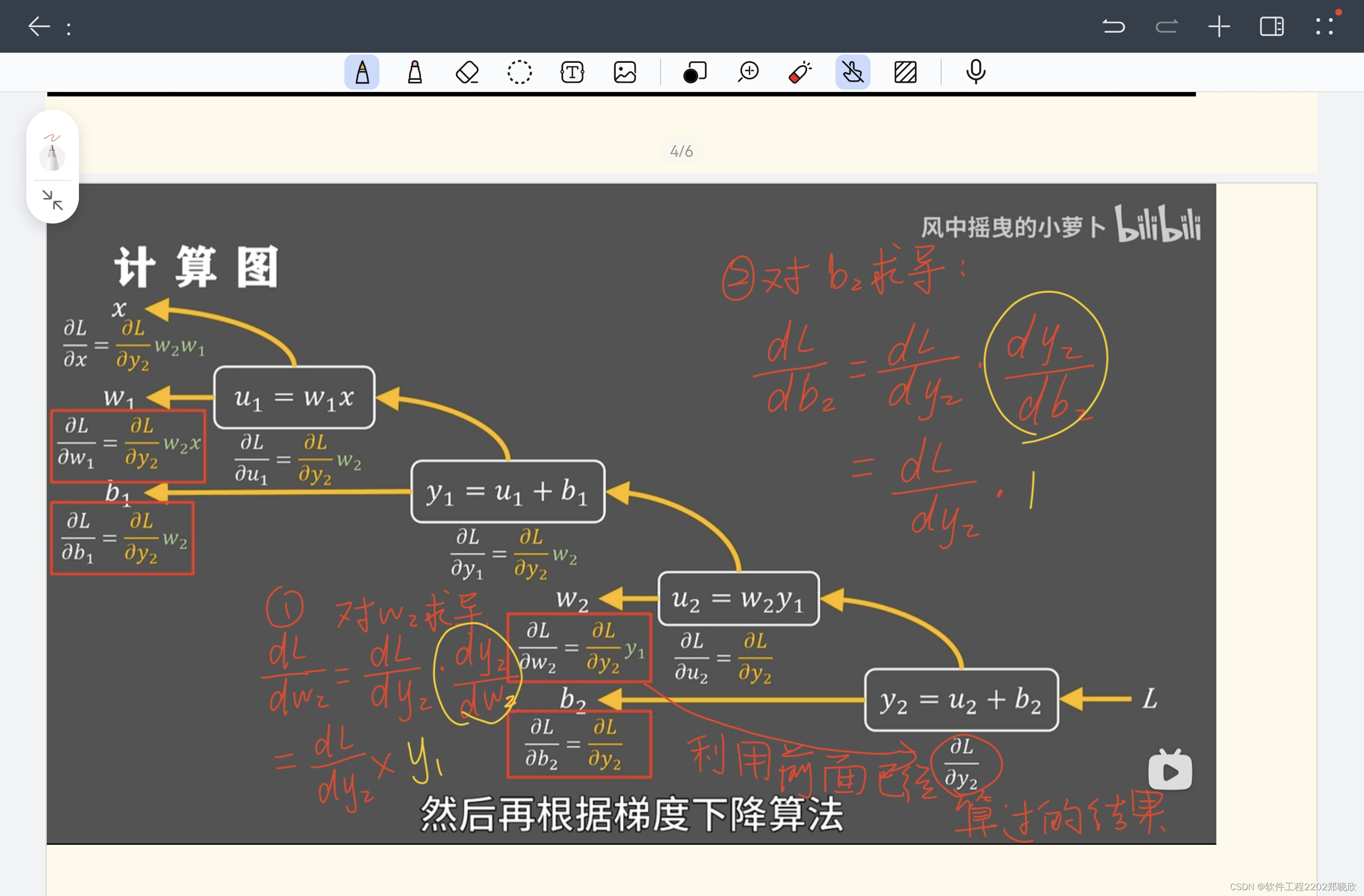

3.激活函数(上面有说过对激活函数不甚了解,现在去了解了)
在卷积神经网络(CNN)中,激活函数的作用是引入非线性,使得网络能够学习更加复杂的模式和特征。具体来说,激活函数的作用有以下几个方面:
-
引入非线性: 激活函数通过对输入进行非线性变换,使得网络可以学习和表示更加复杂的关系。如果没有激活函数,多个层的堆叠就相当于一个线性变换,无法捕捉和表示非线性的特征。
-
增加网络的表达能力: 非线性激活函数允许网络学习非线性映射,从而提高了网络的表达能力。这对于处理复杂的图像、语音或文本数据中的非线性关系至关重要。
-
解决梯度消失问题: 在深层网络中,通过多次进行线性变换,梯度可能会逐渐变得非常小,导致梯度消失问题。激活函数的非线性变换有助于在反向传播时保持一定的梯度,从而更好地进行参数更新。
-
引入稀疏激活性: 有些激活函数(例如ReLU)对于负输入值的输出为零,这就引入了一种稀疏激活性,使得网络中的某些神经元更加活跃,从而提高了网络的稀疏性和泛化能力。
常见的激活函数包括:
- ReLU(Rectified Linear Unit): f(x) = max(0, x),在正值部分保持不变,在负值部分取零。
- Sigmoid: 将输入映射到区间 (0, 1),适用于二分类问题。
- Tanh: 将输入映射到区间 (-1, 1),具有 zero-centered 特性。
ReLU是目前最常用的激活函数,因为它简单且在许多场景中表现良好。
















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









