






本学习笔记参考了以下文章:
项目目录预览 - NGCF-PyTorch - GitCode
--SIGIR 2019 开源论文:基于图神经网络的协同过滤算法 - 知乎 (zhihu.com)
NGCF:
一、NGCF介绍
在设计嵌入层时,我们通常都会将用户和物品分开处理,这就忽略了本质上用户-物品之间的联系,嵌入层显然不包含这一联系。NGCF的提出,正是解决了用户和物品交互信息的传播信号(collaborative signal in user-item interactions)无法在嵌入层中表现这一问题。
NGCF模型框架包括三个主要部分:
( 1 )embedding layer:提供并初始化用户嵌入和项目嵌入的嵌入层;
( 2 )multiple embedding propagation layers:多个嵌入传播层,通过注入高阶连接关系来细化嵌入;
( 3 )prediction layer:预测层,聚合来自不同传播层的精化嵌入,并输出用户-项目对的亲和度分数。
其中传播层最为重要,是NGCF的核心,它又分为两个部分:信息构造、信息聚合。
二、高阶连通性(high-order connectivity)在NGCF中的作用
问题:在日常生活中,用户和项目的交互通常是非常庞大的,这就使得提取协作信号变得非常复杂。高阶连通性作为一种在交互图结构中编码协作信号的自然方式非常适合表现这种关系。这也是NGCF中较为关键的思想。在后面还会有所提及。
三、原理


Embedding Layer
这里对 User 和 Item 分别初始化相应的 Embedding Matrix,然后通过 User 或者 Item 的 ID 进行 Embedding Lookup 将它们映射到一个向量表示。

注意,这里初始化的 Embedding 可以认为是 0 阶表示,即:

Embedding Propagation Layers



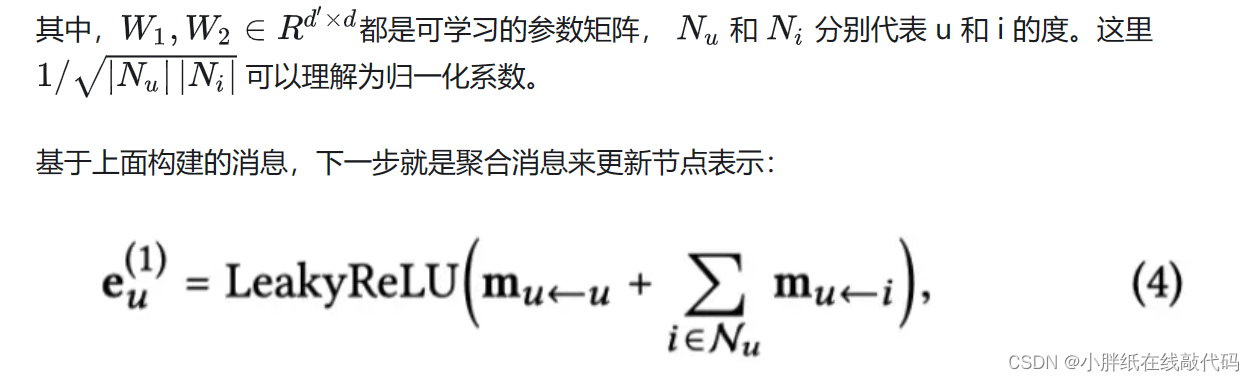

Figure 3 清晰地展示了如何在高阶传播中融合高阶邻居的信息。

上面的传播过程也可以写成矩阵的形式,这样在代码实现的时候可以高效的对节点 Embedding 进行更新。



Model Prediction
模型的预测非常简单,将 L 阶的节点表示分别拼接起来作为最终的节点表示,然后通过内积进行预测。


实际这里采用了类似 18 ICML Representation Learning on Graphs with Jumping Knowledge Networks 的做法来防止 GNN 中的过平滑问题。GNN 的过平滑问题是指,随着 GNN 层数增加,GNN 所学习的 Embedding 变得没有区分度。过平滑问题与本文要捕获的高阶连接性有一定的冲突,所以这里需要在克服过平滑问题。
最终的损失函数就是经典的 BPR 损失函数:

对照

论文中分别采用Gowalla、Yelp2018和Amazon-book三个数据,结果显示NGCF取得了不错的效果。
代码框架
# 导入所需模块
import torch
from torch import nn
class NGCF(nn.Module):
def __init__(self, user_num, item_num, factor_num, num_layers, dropout):
super().__init__() # 调用nn.Module的初始化方法
# 嵌入层,用于获取用户和商品的嵌入
self.embed_user = torch.nn.Embedding(user_num, factor_num)
self.embed_item = torch.nn.Embedding(item_num, factor_num)
# 初始化多个GCN层
self.layers = torch.nn.ModuleList()
for _ in range(num_layers): # num_layers是GCN的层数
# GCNLayer是自定义的GCN层,factor_num是因子数量,dropout是丢失率
self.layers.append(GCNLayer(factor_num, factor_num, dropout))
def forward(self, user, item, norm_adj):
# 输入用户,商品,归一化的邻接矩阵,进行前向传播
# 获取用户和商品的嵌入
user_embedding = self.embed_user(torch.LongTensor([user]))
item_embedding = self.embed_item(torch.LongTensor([item]))
# 存放各层的嵌入
all_embeddings = [torch.cat([user_embedding, item_embedding])]
# 对GCN的每一层进行操作
for gcn in self.layers:
all_embeddings += [gcn(all_embeddings[-1], norm_adj)]
# 用最后一层的嵌入进行预测
prediction = self.predict(all_embeddings[-1])
return prediction'''
Created on March 24, 2020
@author: Tinglin Huang (huangtinglin@outlook.com)
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class NGCF(nn.Module):
def __init__(self, n_user, n_item, norm_adj, args):
super(NGCF, self).__init__()
self.n_user = n_user
self.n_item = n_item
self.device = args.device
self.emb_size = args.embed_size
self.batch_size = args.batch_size
self.node_dropout = args.node_dropout[0]
self.mess_dropout = args.mess_dropout
self.batch_size = args.batch_size
self.norm_adj = norm_adj
self.layers = eval(args.layer_size)
self.decay = eval(args.regs)[0]
"""
*********************************************************
Init the weight of user-item.
"""
self.embedding_dict, self.weight_dict = self.init_weight()
"""
*********************************************************
Get sparse adj.
"""
self.sparse_norm_adj = self._convert_sp_mat_to_sp_tensor(self.norm_adj).to(self.device)
def init_weight(self):
# xavier init
initializer = nn.init.xavier_uniform_
embedding_dict = nn.ParameterDict({
'user_emb': nn.Parameter(initializer(torch.empty(self.n_user,
self.emb_size))),
'item_emb': nn.Parameter(initializer(torch.empty(self.n_item,
self.emb_size)))
})
weight_dict = nn.ParameterDict()
layers = [self.emb_size] + self.layers
for k in range(len(self.layers)):
weight_dict.update({'W_gc_%d'%k: nn.Parameter(initializer(torch.empty(layers[k],
layers[k+1])))})
weight_dict.update({'b_gc_%d'%k: nn.Parameter(initializer(torch.empty(1, layers[k+1])))})
weight_dict.update({'W_bi_%d'%k: nn.Parameter(initializer(torch.empty(layers[k],
layers[k+1])))})
weight_dict.update({'b_bi_%d'%k: nn.Parameter(initializer(torch.empty(1, layers[k+1])))})
return embedding_dict, weight_dict
def _convert_sp_mat_to_sp_tensor(self, X):
coo = X.tocoo()
i = torch.LongTensor([coo.row, coo.col])
v = torch.from_numpy(coo.data).float()
return torch.sparse.FloatTensor(i, v, coo.shape)
def sparse_dropout(self, x, rate, noise_shape):
random_tensor = 1 - rate
random_tensor += torch.rand(noise_shape).to(x.device)
dropout_mask = torch.floor(random_tensor).type(torch.bool)
i = x._indices()
v = x._values()
i = i[:, dropout_mask]
v = v[dropout_mask]
out = torch.sparse.FloatTensor(i, v, x.shape).to(x.device)
return out * (1. / (1 - rate))
def create_bpr_loss(self, users, pos_items, neg_items):
pos_scores = torch.sum(torch.mul(users, pos_items), axis=1)
neg_scores = torch.sum(torch.mul(users, neg_items), axis=1)
maxi = nn.LogSigmoid()(pos_scores - neg_scores)
mf_loss = -1 * torch.mean(maxi)
# cul regularizer
regularizer = (torch.norm(users) ** 2
+ torch.norm(pos_items) ** 2
+ torch.norm(neg_items) ** 2) / 2
emb_loss = self.decay * regularizer / self.batch_size
return mf_loss + emb_loss, mf_loss, emb_loss
def rating(self, u_g_embeddings, pos_i_g_embeddings):
return torch.matmul(u_g_embeddings, pos_i_g_embeddings.t())
def forward(self, users, pos_items, neg_items, drop_flag=True):
A_hat = self.sparse_dropout(self.sparse_norm_adj,
self.node_dropout,
self.sparse_norm_adj._nnz()) if drop_flag else self.sparse_norm_adj
ego_embeddings = torch.cat([self.embedding_dict['user_emb'],
self.embedding_dict['item_emb']], 0)
all_embeddings = [ego_embeddings]
for k in range(len(self.layers)):
side_embeddings = torch.sparse.mm(A_hat, ego_embeddings)
# transformed sum messages of neighbors.
sum_embeddings = torch.matmul(side_embeddings, self.weight_dict['W_gc_%d' % k]) \
+ self.weight_dict['b_gc_%d' % k]
# bi messages of neighbors.
# element-wise product
bi_embeddings = torch.mul(ego_embeddings, side_embeddings)
# transformed bi messages of neighbors.
bi_embeddings = torch.matmul(bi_embeddings, self.weight_dict['W_bi_%d' % k]) \
+ self.weight_dict['b_bi_%d' % k]
# non-linear activation.
ego_embeddings = nn.LeakyReLU(negative_slope=0.2)(sum_embeddings + bi_embeddings)
# message dropout.
ego_embeddings = nn.Dropout(self.mess_dropout[k])(ego_embeddings)
# normalize the distribution of embeddings.
norm_embeddings = F.normalize(ego_embeddings, p=2, dim=1)
all_embeddings += [norm_embeddings]
all_embeddings = torch.cat(all_embeddings, 1)
u_g_embeddings = all_embeddings[:self.n_user, :]
i_g_embeddings = all_embeddings[self.n_user:, :]
"""
*********************************************************
look up.
"""
u_g_embeddings = u_g_embeddings[users, :]
pos_i_g_embeddings = i_g_embeddings[pos_items, :]
neg_i_g_embeddings = i_g_embeddings[neg_items, :]
return u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings
结论
本文提出了基于图神经网络的协同过滤算法 NGCF,它可以显式地将 User-Item 的高阶交互编码进 Embedding 中来提升 Embedding 的表示能力进而提升整个推荐效果。NGCF 的关键就在于 Embedding Propagation Layer 来学习 User 和 Item 的 Embedding,后面的预测部分只是简单的内积。可以说,NGCF 较好地解决了协同过滤算法的第一个核心问题。另外,本文的 Embedding Propagation 实际上没有考虑邻居的重要性,如果可以像 Graph Attention Network 在传播聚合过程中考虑邻居重要性的差异,NGCF 的效果应该可以进一步提升。
LightGCN
一、NGCF与LightGCN主要区别
NGCF从图卷积网络(GCN)中获得灵感,遵循相同的传播规则来改进嵌入:特征变换、邻域聚合和非线性激活。但它的设计相当沉重和繁琐——许多操作直接从GCN继承而来,没有理由。因此,它们不一定对CF任务有用。
LightGCN对NGCF做了简化,仅包含了GCN中最重要的组成部分-邻域聚合-用于协同过滤。
NGCF利用用户-项目交互图来传播embedding:

上面的公式可以看到,NGCF在很大程度上遵循了标准的GCN,包括使用非线性激活函数σ(·)和特征变换矩阵W1和W2。然而,作者认为这两种操作对于协同过滤来说并不那么有用。
在半监督节点分类中,每个节点都有丰富的语义特征作为输入,例如一篇论文的标题和摘要词。因此,进行多层非线性变换有利于特征学习。
然而,在协同过滤中,用户-项目交互图的每个节点只有一个ID作为输入,没有具体的语义。在这种情况下,执行多个非线性变换将无助于学习更好的特征;更糟糕的是,它可能会增加训练的困难。
二、NGCF与LightGCN模型框架对比
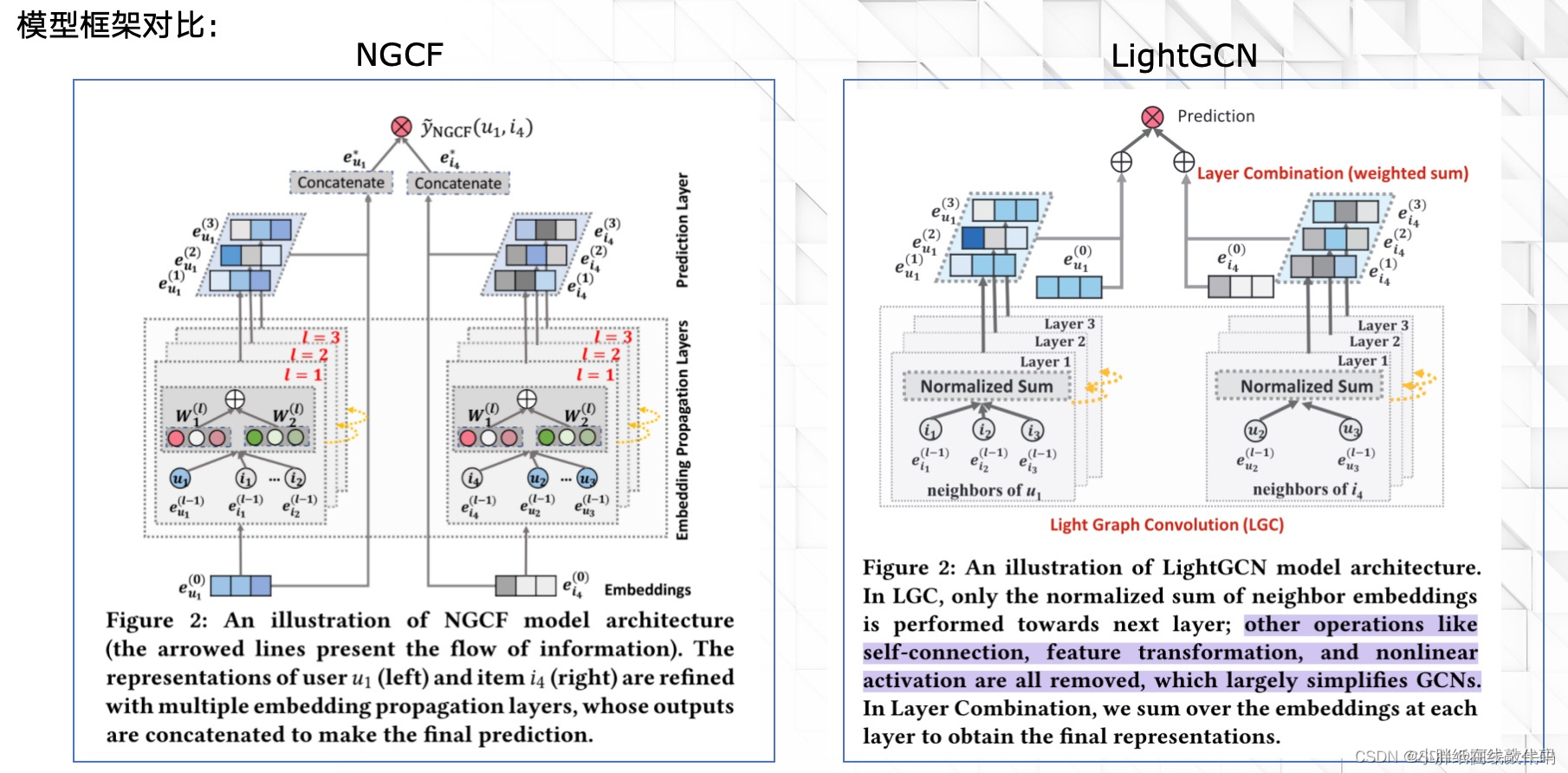
上图中左侧是NGCF模型框架,在中间的Embedding Propagation Layers中可以看到特征变换W1、W2,可以看到非线性变换⨁ \bigoplus⨁。而在右侧LightGCN模型框架中,只有简单的Normalized Sum。
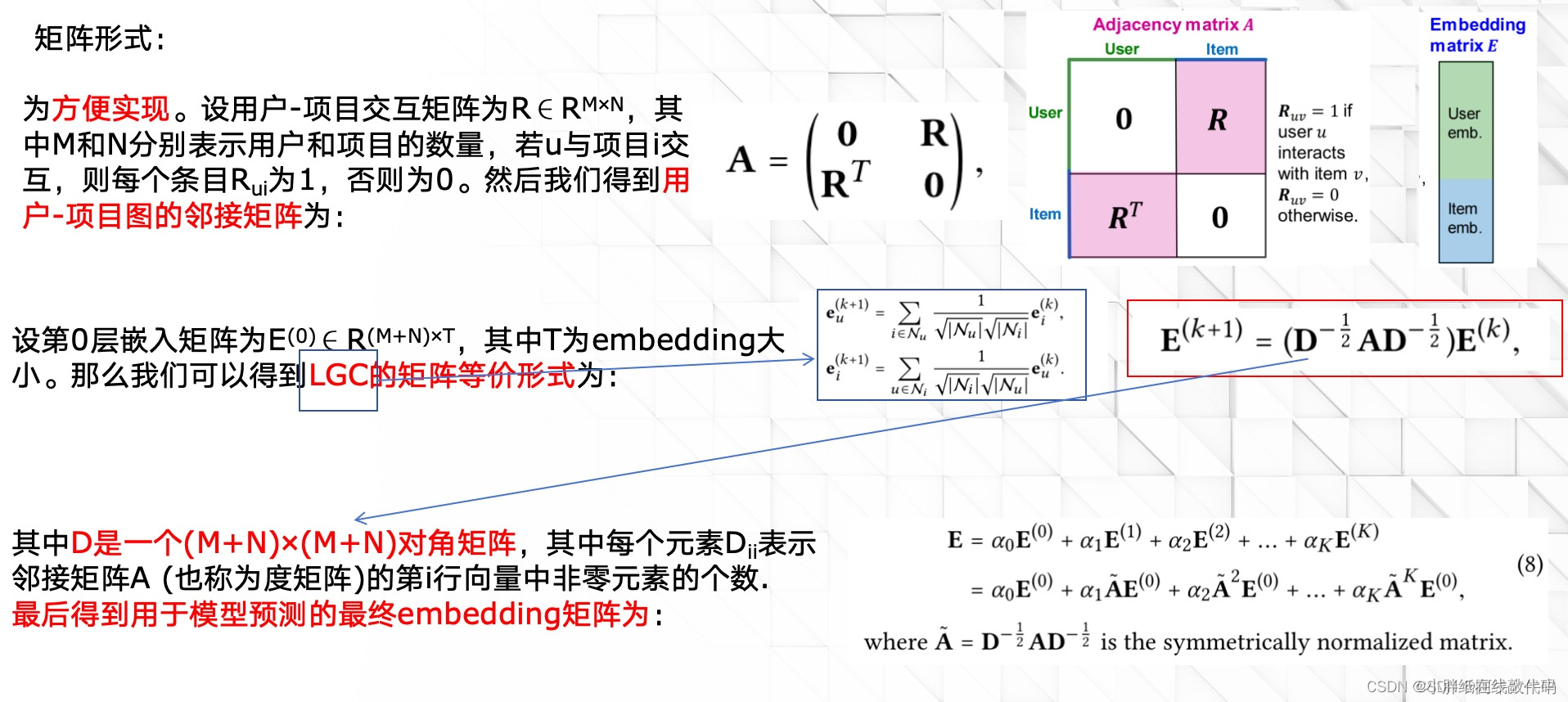
Light Graph Convolution(LGC)
论文中最重要的两点其实就是2.3小节的LGC与2.4小节的Layer Combination。
先来说一下LGC:

可以看到LightGCN传播embedding时做了很大的简化,从上面两个公式的区别就可以看出来。
2.4 Layer Combination and Model Prediction
在传统的GCN中,其实没有使用层组合,它直接通过卷积几层后得到的embedding作为输出,这样会有过平滑的问题:在卷积一定层数以后,所有节点都趋于统一,没有明显的区别,这显然是不好的。这里使用层组合方法来避免过平滑的问题:
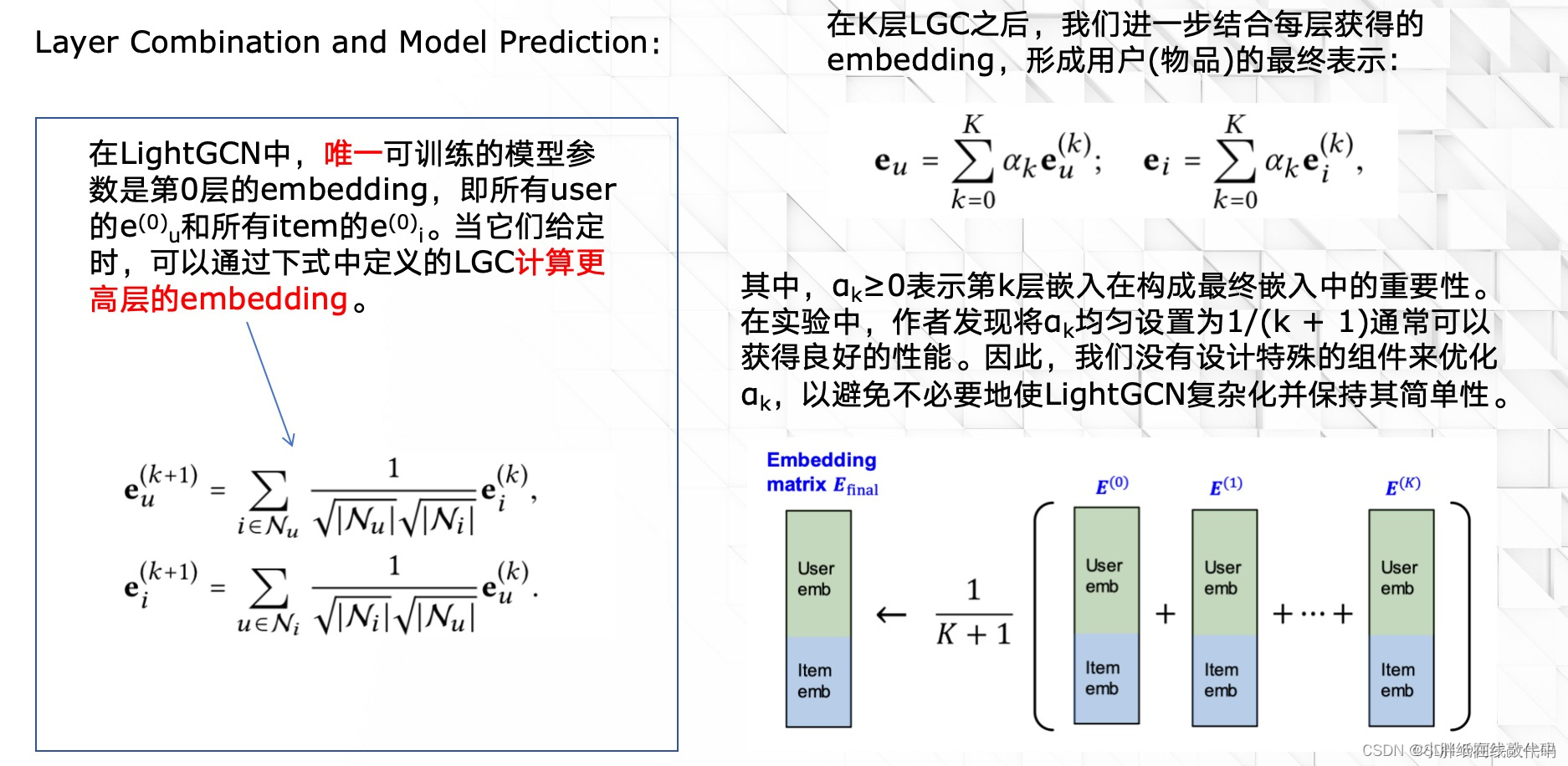
假设我们设置3层的传播层。刚开始输入的embedding称为e(0),经过第一层传播之后得到e(1),经过第二层传播之后得到e(2),经过第三层传播之后得到e(3)。传统的方法就会直接输出e(3)作为结果,而层组合则会给e(0)、e(1)、e(2)、e(3)以一定的权重,比如LightGCN中,直接取权重为1/k+1,即平均。
我们执行层组合(Layer Combination)以获得最终表示的原因有三个:
(1)随着层数的增加,节点embedding会出现过平滑现象(over-smoothed)。因此,仅仅使用最后一层是有问题的。
(2)不同层的嵌入捕获不同的语义。例如,第一层对有交互的用户和项进行平滑处理,第二层对交互项(用户)上有重叠的用户(项)进行平滑处理,更高层捕获更高阶的接近度。因此,将它们结合起来会使表现更加全面。
(3)将不同层的嵌入与加权和结合起来,捕获了具有自连接的图卷积的效果,这是GCNs中的一个重要技巧。
模型预测的话就比较简单,直接使用内积就可以:

与SGCN的关系

与APPNP的关系

二阶embedding分析

三、代码框架
'''
Created on Oct 10, 2018
Tensorflow Implementation of Neural Graph Collaborative Filtering (NGCF) model in:
Wang Xiang et al. Neural Graph Collaborative Filtering. In SIGIR 2019.
@author: Xiang Wang (xiangwang@u.nus.edu)
version:
Parallelized sampling on CPU
C++ evaluation for top-k recommendation
'''
import os
import sys
import threading
import tensorflow as tf
from tensorflow.python.client import device_lib
from utility.helper import *
from utility.batch_test import *
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
cpus = [x.name for x in device_lib.list_local_devices() if x.device_type == 'CPU']
class LightGCN(object):
def __init__(self, data_config, pretrain_data):
# argument settings
self.model_type = 'LightGCN'
self.adj_type = args.adj_type
self.alg_type = args.alg_type
self.pretrain_data = pretrain_data
self.n_users = data_config['n_users']
self.n_items = data_config['n_items']
self.n_fold = 100
self.norm_adj = data_config['norm_adj']
self.n_nonzero_elems = self.norm_adj.count_nonzero()
self.lr = args.lr
self.emb_dim = args.embed_size
self.batch_size = args.batch_size
self.weight_size = eval(args.layer_size)
self.n_layers = len(self.weight_size)
self.regs = eval(args.regs)
self.decay = self.regs[0]
self.log_dir=self.create_model_str()
self.verbose = args.verbose
self.Ks = eval(args.Ks)
'''
*********************************************************
Create Placeholder for Input Data & Dropout.
'''
# placeholder definition
self.users = tf.placeholder(tf.int32, shape=(None,))
self.pos_items = tf.placeholder(tf.int32, shape=(None,))
self.neg_items = tf.placeholder(tf.int32, shape=(None,))
self.node_dropout_flag = args.node_dropout_flag
self.node_dropout = tf.placeholder(tf.float32, shape=[None])
self.mess_dropout = tf.placeholder(tf.float32, shape=[None])
with tf.name_scope('TRAIN_LOSS'):
self.train_loss = tf.placeholder(tf.float32)
tf.summary.scalar('train_loss', self.train_loss)
self.train_mf_loss = tf.placeholder(tf.float32)
tf.summary.scalar('train_mf_loss', self.train_mf_loss)
self.train_emb_loss = tf.placeholder(tf.float32)
tf.summary.scalar('train_emb_loss', self.train_emb_loss)
self.train_reg_loss = tf.placeholder(tf.float32)
tf.summary.scalar('train_reg_loss', self.train_reg_loss)
self.merged_train_loss = tf.summary.merge(tf.get_collection(tf.GraphKeys.SUMMARIES, 'TRAIN_LOSS'))
with tf.name_scope('TRAIN_ACC'):
self.train_rec_first = tf.placeholder(tf.float32)
#record for top(Ks[0])
tf.summary.scalar('train_rec_first', self.train_rec_first)
self.train_rec_last = tf.placeholder(tf.float32)
#record for top(Ks[-1])
tf.summary.scalar('train_rec_last', self.train_rec_last)
self.train_ndcg_first = tf.placeholder(tf.float32)
tf.summary.scalar('train_ndcg_first', self.train_ndcg_first)
self.train_ndcg_last = tf.placeholder(tf.float32)
tf.summary.scalar('train_ndcg_last', self.train_ndcg_last)
self.merged_train_acc = tf.summary.merge(tf.get_collection(tf.GraphKeys.SUMMARIES, 'TRAIN_ACC'))
with tf.name_scope('TEST_LOSS'):
self.test_loss = tf.placeholder(tf.float32)
tf.summary.scalar('test_loss', self.test_loss)
self.test_mf_loss = tf.placeholder(tf.float32)
tf.summary.scalar('test_mf_loss', self.test_mf_loss)
self.test_emb_loss = tf.placeholder(tf.float32)
tf.summary.scalar('test_emb_loss', self.test_emb_loss)
self.test_reg_loss = tf.placeholder(tf.float32)
tf.summary.scalar('test_reg_loss', self.test_reg_loss)
self.merged_test_loss = tf.summary.merge(tf.get_collection(tf.GraphKeys.SUMMARIES, 'TEST_LOSS'))
with tf.name_scope('TEST_ACC'):
self.test_rec_first = tf.placeholder(tf.float32)
tf.summary.scalar('test_rec_first', self.test_rec_first)
self.test_rec_last = tf.placeholder(tf.float32)
tf.summary.scalar('test_rec_last', self.test_rec_last)
self.test_ndcg_first = tf.placeholder(tf.float32)
tf.summary.scalar('test_ndcg_first', self.test_ndcg_first)
self.test_ndcg_last = tf.placeholder(tf.float32)
tf.summary.scalar('test_ndcg_last', self.test_ndcg_last)
self.merged_test_acc = tf.summary.merge(tf.get_collection(tf.GraphKeys.SUMMARIES, 'TEST_ACC'))
"""
*********************************************************
Create Model Parameters (i.e., Initialize Weights).
"""
# initialization of model parameters
self.weights = self._init_weights()
"""
*********************************************************
Compute Graph-based Representations of all users & items via Message-Passing Mechanism of Graph Neural Networks.
Different Convolutional Layers:
1. ngcf: defined in 'Neural Graph Collaborative Filtering', SIGIR2019;
2. gcn: defined in 'Semi-Supervised Classification with Graph Convolutional Networks', ICLR2018;
3. gcmc: defined in 'Graph Convolutional Matrix Completion', KDD2018;
"""
if self.alg_type in ['lightgcn']:
self.ua_embeddings, self.ia_embeddings = self._create_lightgcn_embed()
elif self.alg_type in ['ngcf']:
self.ua_embeddings, self.ia_embeddings = self._create_ngcf_embed()
elif self.alg_type in ['gcn']:
self.ua_embeddings, self.ia_embeddings = self._create_gcn_embed()
elif self.alg_type in ['gcmc']:
self.ua_embeddings, self.ia_embeddings = self._create_gcmc_embed()
"""
*********************************************************
Establish the final representations for user-item pairs in batch.
"""
self.u_g_embeddings = tf.nn.embedding_lookup(self.ua_embeddings, self.users)
self.pos_i_g_embeddings = tf.nn.embedding_lookup(self.ia_embeddings, self.pos_items)
self.neg_i_g_embeddings = tf.nn.embedding_lookup(self.ia_embeddings, self.neg_items)
self.u_g_embeddings_pre = tf.nn.embedding_lookup(self.weights['user_embedding'], self.users)
self.pos_i_g_embeddings_pre = tf.nn.embedding_lookup(self.weights['item_embedding'], self.pos_items)
self.neg_i_g_embeddings_pre = tf.nn.embedding_lookup(self.weights['item_embedding'], self.neg_items)
"""
*********************************************************
Inference for the testing phase.
"""
self.batch_ratings = tf.matmul(self.u_g_embeddings, self.pos_i_g_embeddings, transpose_a=False, transpose_b=True)
"""
*********************************************************
Generate Predictions & Optimize via BPR loss.
"""
self.mf_loss, self.emb_loss, self.reg_loss = self.create_bpr_loss(self.u_g_embeddings,
self.pos_i_g_embeddings,
self.neg_i_g_embeddings)
self.loss = self.mf_loss + self.emb_loss
self.opt = tf.train.AdamOptimizer(learning_rate=self.lr).minimize(self.loss)
def create_model_str(self):
log_dir = '/' + self.alg_type+'/layers_'+str(self.n_layers)+'/dim_'+str(self.emb_dim)
log_dir+='/'+args.dataset+'/lr_' + str(self.lr) + '/reg_' + str(self.decay)
return log_dir
def _init_weights(self):
all_weights = dict()
initializer = tf.random_normal_initializer(stddev=0.01) #tf.contrib.layers.xavier_initializer()
if self.pretrain_data is None:
all_weights['user_embedding'] = tf.Variable(initializer([self.n_users, self.emb_dim]), name='user_embedding')
all_weights['item_embedding'] = tf.Variable(initializer([self.n_items, self.emb_dim]), name='item_embedding')
print('using random initialization')#print('using xavier initialization')
else:
all_weights['user_embedding'] = tf.Variable(initial_value=self.pretrain_data['user_embed'], trainable=True,
name='user_embedding', dtype=tf.float32)
all_weights['item_embedding'] = tf.Variable(initial_value=self.pretrain_data['item_embed'], trainable=True,
name='item_embedding', dtype=tf.float32)
print('using pretrained initialization')
self.weight_size_list = [self.emb_dim] + self.weight_size
for k in range(self.n_layers):
all_weights['W_gc_%d' %k] = tf.Variable(
initializer([self.weight_size_list[k], self.weight_size_list[k+1]]), name='W_gc_%d' % k)
all_weights['b_gc_%d' %k] = tf.Variable(
initializer([1, self.weight_size_list[k+1]]), name='b_gc_%d' % k)
all_weights['W_bi_%d' % k] = tf.Variable(
initializer([self.weight_size_list[k], self.weight_size_list[k + 1]]), name='W_bi_%d' % k)
all_weights['b_bi_%d' % k] = tf.Variable(
initializer([1, self.weight_size_list[k + 1]]), name='b_bi_%d' % k)
all_weights['W_mlp_%d' % k] = tf.Variable(
initializer([self.weight_size_list[k], self.weight_size_list[k+1]]), name='W_mlp_%d' % k)
all_weights['b_mlp_%d' % k] = tf.Variable(
initializer([1, self.weight_size_list[k+1]]), name='b_mlp_%d' % k)
return all_weights
def _split_A_hat(self, X):
A_fold_hat = []
fold_len = (self.n_users + self.n_items) // self.n_fold
for i_fold in range(self.n_fold):
start = i_fold * fold_len
if i_fold == self.n_fold -1:
end = self.n_users + self.n_items
else:
end = (i_fold + 1) * fold_len
A_fold_hat.append(self._convert_sp_mat_to_sp_tensor(X[start:end]))
return A_fold_hat
def _split_A_hat_node_dropout(self, X):
A_fold_hat = []
fold_len = (self.n_users + self.n_items) // self.n_fold
for i_fold in range(self.n_fold):
start = i_fold * fold_len
if i_fold == self.n_fold -1:
end = self.n_users + self.n_items
else:
end = (i_fold + 1) * fold_len
temp = self._convert_sp_mat_to_sp_tensor(X[start:end])
n_nonzero_temp = X[start:end].count_nonzero()
A_fold_hat.append(self._dropout_sparse(temp, 1 - self.node_dropout[0], n_nonzero_temp))
return A_fold_hat
def _create_lightgcn_embed(self):
if self.node_dropout_flag:
A_fold_hat = self._split_A_hat_node_dropout(self.norm_adj)
else:
A_fold_hat = self._split_A_hat(self.norm_adj)
ego_embeddings = tf.concat([self.weights['user_embedding'], self.weights['item_embedding']], axis=0)
all_embeddings = [ego_embeddings]
for k in range(0, self.n_layers):
temp_embed = []
for f in range(self.n_fold):
temp_embed.append(tf.sparse_tensor_dense_matmul(A_fold_hat[f], ego_embeddings))
side_embeddings = tf.concat(temp_embed, 0)
ego_embeddings = side_embeddings
all_embeddings += [ego_embeddings]
all_embeddings=tf.stack(all_embeddings,1)
all_embeddings=tf.reduce_mean(all_embeddings,axis=1,keepdims=False)
u_g_embeddings, i_g_embeddings = tf.split(all_embeddings, [self.n_users, self.n_items], 0)
return u_g_embeddings, i_g_embeddings
def _create_ngcf_embed(self):
if self.node_dropout_flag:
A_fold_hat = self._split_A_hat_node_dropout(self.norm_adj)
else:
A_fold_hat = self._split_A_hat(self.norm_adj)
ego_embeddings = tf.concat([self.weights['user_embedding'], self.weights['item_embedding']], axis=0)
all_embeddings = [ego_embeddings]
for k in range(0, self.n_layers):
temp_embed = []
for f in range(self.n_fold):
temp_embed.append(tf.sparse_tensor_dense_matmul(A_fold_hat[f], ego_embeddings))
side_embeddings = tf.concat(temp_embed, 0)
sum_embeddings = tf.nn.leaky_relu(tf.matmul(side_embeddings, self.weights['W_gc_%d' % k]) + self.weights['b_gc_%d' % k])
# bi messages of neighbors.
bi_embeddings = tf.multiply(ego_embeddings, side_embeddings)
# transformed bi messages of neighbors.
bi_embeddings = tf.nn.leaky_relu(tf.matmul(bi_embeddings, self.weights['W_bi_%d' % k]) + self.weights['b_bi_%d' % k])
# non-linear activation.
ego_embeddings = sum_embeddings + bi_embeddings
# message dropout.
# ego_embeddings = tf.nn.dropout(ego_embeddings, 1 - self.mess_dropout[k])
# normalize the distribution of embeddings.
norm_embeddings = tf.nn.l2_normalize(ego_embeddings, axis=1)
all_embeddings += [norm_embeddings]
all_embeddings = tf.concat(all_embeddings, 1)
u_g_embeddings, i_g_embeddings = tf.split(all_embeddings, [self.n_users, self.n_items], 0)
return u_g_embeddings, i_g_embeddings
def _create_gcn_embed(self):
A_fold_hat = self._split_A_hat(self.norm_adj)
embeddings = tf.concat([self.weights['user_embedding'], self.weights['item_embedding']], axis=0)
all_embeddings = [embeddings]
for k in range(0, self.n_layers):
temp_embed = []
for f in range(self.n_fold):
temp_embed.append(tf.sparse_tensor_dense_matmul(A_fold_hat[f], embeddings))
embeddings = tf.concat(temp_embed, 0)
embeddings = tf.nn.leaky_relu(tf.matmul(embeddings, self.weights['W_gc_%d' %k]) + self.weights['b_gc_%d' %k])
# embeddings = tf.nn.dropout(embeddings, 1 - self.mess_dropout[k])
all_embeddings += [embeddings]
all_embeddings = tf.concat(all_embeddings, 1)
u_g_embeddings, i_g_embeddings = tf.split(all_embeddings, [self.n_users, self.n_items], 0)
return u_g_embeddings, i_g_embeddings
def _create_gcmc_embed(self):
A_fold_hat = self._split_A_hat(self.norm_adj)
embeddings = tf.concat([self.weights['user_embedding'], self.weights['item_embedding']], axis=0)
all_embeddings = []
for k in range(0, self.n_layers):
temp_embed = []
for f in range(self.n_fold):
temp_embed.append(tf.sparse_tensor_dense_matmul(A_fold_hat[f], embeddings))
embeddings = tf.concat(temp_embed, 0)
# convolutional layer.
embeddings = tf.nn.leaky_relu(tf.matmul(embeddings, self.weights['W_gc_%d' % k]) + self.weights['b_gc_%d' % k])
# dense layer.
mlp_embeddings = tf.matmul(embeddings, self.weights['W_mlp_%d' %k]) + self.weights['b_mlp_%d' %k]
# mlp_embeddings = tf.nn.dropout(mlp_embeddings, 1 - self.mess_dropout[k])
all_embeddings += [mlp_embeddings]
all_embeddings = tf.concat(all_embeddings, 1)
u_g_embeddings, i_g_embeddings = tf.split(all_embeddings, [self.n_users, self.n_items], 0)
return u_g_embeddings, i_g_embeddings
def create_bpr_loss(self, users, pos_items, neg_items):
pos_scores = tf.reduce_sum(tf.multiply(users, pos_items), axis=1)
neg_scores = tf.reduce_sum(tf.multiply(users, neg_items), axis=1)
regularizer = tf.nn.l2_loss(self.u_g_embeddings_pre) + tf.nn.l2_loss(
self.pos_i_g_embeddings_pre) + tf.nn.l2_loss(self.neg_i_g_embeddings_pre)
regularizer = regularizer / self.batch_size
mf_loss = tf.reduce_mean(tf.nn.softplus(-(pos_scores - neg_scores)))
emb_loss = self.decay * regularizer
reg_loss = tf.constant(0.0, tf.float32, [1])
return mf_loss, emb_loss, reg_loss
def _convert_sp_mat_to_sp_tensor(self, X):
coo = X.tocoo().astype(np.float32)
indices = np.mat([coo.row, coo.col]).transpose()
return tf.SparseTensor(indices, coo.data, coo.shape)
def _dropout_sparse(self, X, keep_prob, n_nonzero_elems):
"""
Dropout for sparse tensors.
"""
noise_shape = [n_nonzero_elems]
random_tensor = keep_prob
random_tensor += tf.random_uniform(noise_shape)
dropout_mask = tf.cast(tf.floor(random_tensor), dtype=tf.bool)
pre_out = tf.sparse_retain(X, dropout_mask)
return pre_out * tf.div(1., keep_prob)
def load_pretrained_data():
pretrain_path = '%spretrain/%s/%s.npz' % (args.proj_path, args.dataset, 'embedding')
try:
pretrain_data = np.load(pretrain_path)
print('load the pretrained embeddings.')
except Exception:
pretrain_data = None
return pretrain_data
# parallelized sampling on CPU
class sample_thread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
with tf.device(cpus[0]):
self.data = data_generator.sample()
class sample_thread_test(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
with tf.device(cpus[0]):
self.data = data_generator.sample_test()
# training on GPU
class train_thread(threading.Thread):
def __init__(self,model, sess, sample):
threading.Thread.__init__(self)
self.model = model
self.sess = sess
self.sample = sample
def run(self):
users, pos_items, neg_items = self.sample.data
self.data = sess.run([self.model.opt, self.model.loss, self.model.mf_loss, self.model.emb_loss, self.model.reg_loss],
feed_dict={model.users: users, model.pos_items: pos_items,
model.node_dropout: eval(args.node_dropout),
model.mess_dropout: eval(args.mess_dropout),
model.neg_items: neg_items})
class train_thread_test(threading.Thread):
def __init__(self,model, sess, sample):
threading.Thread.__init__(self)
self.model = model
self.sess = sess
self.sample = sample
def run(self):
users, pos_items, neg_items = self.sample.data
self.data = sess.run([self.model.loss, self.model.mf_loss, self.model.emb_loss],
feed_dict={model.users: users, model.pos_items: pos_items,
model.neg_items: neg_items,
model.node_dropout: eval(args.node_dropout),
model.mess_dropout: eval(args.mess_dropout)})
if __name__ == '__main__':
os.environ["CUDA_VISIBLE_DEVICES"] = str(args.gpu_id)
f0 = time()
config = dict()
config['n_users'] = data_generator.n_users
config['n_items'] = data_generator.n_items
"""
*********************************************************
Generate the Laplacian matrix, where each entry defines the decay factor (e.g., p_ui) between two connected nodes.
"""
plain_adj, norm_adj, mean_adj,pre_adj = data_generator.get_adj_mat()
if args.adj_type == 'plain':
config['norm_adj'] = plain_adj
print('use the plain adjacency matrix')
elif args.adj_type == 'norm':
config['norm_adj'] = norm_adj
print('use the normalized adjacency matrix')
elif args.adj_type == 'gcmc':
config['norm_adj'] = mean_adj
print('use the gcmc adjacency matrix')
elif args.adj_type=='pre':
config['norm_adj']=pre_adj
print('use the pre adjcency matrix')
else:
config['norm_adj'] = mean_adj + sp.eye(mean_adj.shape[0])
print('use the mean adjacency matrix')
t0 = time()
if args.pretrain == -1:
pretrain_data = load_pretrained_data()
else:
pretrain_data = None
model = LightGCN(data_config=config, pretrain_data=pretrain_data)
"""
*********************************************************
Save the model parameters.
"""
saver = tf.train.Saver()
if args.save_flag == 1:
layer = '-'.join([str(l) for l in eval(args.layer_size)])
weights_save_path = '%sweights/%s/%s/%s/l%s_r%s' % (args.weights_path, args.dataset, model.model_type, layer,
str(args.lr), '-'.join([str(r) for r in eval(args.regs)]))
ensureDir(weights_save_path)
save_saver = tf.train.Saver(max_to_keep=1)
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
"""
*********************************************************
Reload the pretrained model parameters.
"""
if args.pretrain == 1:
layer = '-'.join([str(l) for l in eval(args.layer_size)])
pretrain_path = '%sweights/%s/%s/%s/l%s_r%s' % (args.weights_path, args.dataset, model.model_type, layer,
str(args.lr), '-'.join([str(r) for r in eval(args.regs)]))
ckpt = tf.train.get_checkpoint_state(os.path.dirname(pretrain_path + '/checkpoint'))
if ckpt and ckpt.model_checkpoint_path:
sess.run(tf.global_variables_initializer())
saver.restore(sess, ckpt.model_checkpoint_path)
print('load the pretrained model parameters from: ', pretrain_path)
# *********************************************************
# get the performance from pretrained model.
if args.report != 1:
users_to_test = list(data_generator.test_set.keys())
ret = test(sess, model, users_to_test, drop_flag=True)
cur_best_pre_0 = ret['recall'][0]
pretrain_ret = 'pretrained model recall=[%s], precision=[%s], '\
'ndcg=[%s]' % \
(', '.join(['%.5f' % r for r in ret['recall']]),
', '.join(['%.5f' % r for r in ret['precision']]),
', '.join(['%.5f' % r for r in ret['ndcg']]))
print(pretrain_ret)
else:
sess.run(tf.global_variables_initializer())
cur_best_pre_0 = 0.
print('without pretraining.')
else:
sess.run(tf.global_variables_initializer())
cur_best_pre_0 = 0.
print('without pretraining.')
"""
*********************************************************
Get the performance w.r.t. different sparsity levels.
"""
if args.report == 1:
assert args.test_flag == 'full'
users_to_test_list, split_state = data_generator.get_sparsity_split()
users_to_test_list.append(list(data_generator.test_set.keys()))
split_state.append('all')
report_path = '%sreport/%s/%s.result' % (args.proj_path, args.dataset, model.model_type)
ensureDir(report_path)
f = open(report_path, 'w')
f.write(
'embed_size=%d, lr=%.4f, layer_size=%s, keep_prob=%s, regs=%s, loss_type=%s, adj_type=%s\n'
% (args.embed_size, args.lr, args.layer_size, args.keep_prob, args.regs, args.loss_type, args.adj_type))
for i, users_to_test in enumerate(users_to_test_list):
ret = test(sess, model, users_to_test, drop_flag=True)
final_perf = "recall=[%s], precision=[%s], ndcg=[%s]" % \
(', '.join(['%.5f' % r for r in ret['recall']]),
', '.join(['%.5f' % r for r in ret['precision']]),
', '.join(['%.5f' % r for r in ret['ndcg']]))
f.write('\t%s\n\t%s\n' % (split_state[i], final_perf))
f.close()
exit()
"""
*********************************************************
Train.
"""
tensorboard_model_path = 'tensorboard/'
if not os.path.exists(tensorboard_model_path):
os.makedirs(tensorboard_model_path)
run_time = 1
while (True):
if os.path.exists(tensorboard_model_path + model.log_dir +'/run_' + str(run_time)):
run_time += 1
else:
break
train_writer = tf.summary.FileWriter(tensorboard_model_path +model.log_dir+ '/run_' + str(run_time), sess.graph)
loss_loger, pre_loger, rec_loger, ndcg_loger, hit_loger = [], [], [], [], []
stopping_step = 0
should_stop = False
for epoch in range(1, args.epoch + 1):
t1 = time()
loss, mf_loss, emb_loss, reg_loss = 0., 0., 0., 0.
n_batch = data_generator.n_train // args.batch_size + 1
loss_test,mf_loss_test,emb_loss_test,reg_loss_test=0.,0.,0.,0.
'''
*********************************************************
parallelized sampling
'''
sample_last = sample_thread()
sample_last.start()
sample_last.join()
for idx in range(n_batch):
train_cur = train_thread(model, sess, sample_last)
sample_next = sample_thread()
train_cur.start()
sample_next.start()
sample_next.join()
train_cur.join()
users, pos_items, neg_items = sample_last.data
_, batch_loss, batch_mf_loss, batch_emb_loss, batch_reg_loss = train_cur.data
sample_last = sample_next
loss += batch_loss/n_batch
mf_loss += batch_mf_loss/n_batch
emb_loss += batch_emb_loss/n_batch
summary_train_loss= sess.run(model.merged_train_loss,
feed_dict={model.train_loss: loss, model.train_mf_loss: mf_loss,
model.train_emb_loss: emb_loss, model.train_reg_loss: reg_loss})
train_writer.add_summary(summary_train_loss, epoch)
if np.isnan(loss) == True:
print('ERROR: loss is nan.')
sys.exit()
if (epoch % 20) != 0:
if args.verbose > 0 and epoch % args.verbose == 0:
perf_str = 'Epoch %d [%.1fs]: train==[%.5f=%.5f + %.5f]' % (
epoch, time() - t1, loss, mf_loss, emb_loss)
print(perf_str)
continue
users_to_test = list(data_generator.train_items.keys())
ret = test(sess, model, users_to_test ,drop_flag=True,train_set_flag=1)
perf_str = 'Epoch %d: train==[%.5f=%.5f + %.5f + %.5f], recall=[%s], precision=[%s], ndcg=[%s]' % \
(epoch, loss, mf_loss, emb_loss, reg_loss,
', '.join(['%.5f' % r for r in ret['recall']]),
', '.join(['%.5f' % r for r in ret['precision']]),
', '.join(['%.5f' % r for r in ret['ndcg']]))
print(perf_str)
summary_train_acc = sess.run(model.merged_train_acc, feed_dict={model.train_rec_first: ret['recall'][0],
model.train_rec_last: ret['recall'][-1],
model.train_ndcg_first: ret['ndcg'][0],
model.train_ndcg_last: ret['ndcg'][-1]})
train_writer.add_summary(summary_train_acc, epoch // 20)
'''
*********************************************************
parallelized sampling
'''
sample_last= sample_thread_test()
sample_last.start()
sample_last.join()
for idx in range(n_batch):
train_cur = train_thread_test(model, sess, sample_last)
sample_next = sample_thread_test()
train_cur.start()
sample_next.start()
sample_next.join()
train_cur.join()
users, pos_items, neg_items = sample_last.data
batch_loss_test, batch_mf_loss_test, batch_emb_loss_test = train_cur.data
sample_last = sample_next
loss_test += batch_loss_test / n_batch
mf_loss_test += batch_mf_loss_test / n_batch
emb_loss_test += batch_emb_loss_test / n_batch
summary_test_loss = sess.run(model.merged_test_loss,
feed_dict={model.test_loss: loss_test, model.test_mf_loss: mf_loss_test,
model.test_emb_loss: emb_loss_test, model.test_reg_loss: reg_loss_test})
train_writer.add_summary(summary_test_loss, epoch // 20)
t2 = time()
users_to_test = list(data_generator.test_set.keys())
ret = test(sess, model, users_to_test, drop_flag=True)
summary_test_acc = sess.run(model.merged_test_acc,
feed_dict={model.test_rec_first: ret['recall'][0], model.test_rec_last: ret['recall'][-1],
model.test_ndcg_first: ret['ndcg'][0], model.test_ndcg_last: ret['ndcg'][-1]})
train_writer.add_summary(summary_test_acc, epoch // 20)
t3 = time()
loss_loger.append(loss)
rec_loger.append(ret['recall'])
pre_loger.append(ret['precision'])
ndcg_loger.append(ret['ndcg'])
if args.verbose > 0:
perf_str = 'Epoch %d [%.1fs + %.1fs]: test==[%.5f=%.5f + %.5f + %.5f], recall=[%s], ' \
'precision=[%s], ndcg=[%s]' % \
(epoch, t2 - t1, t3 - t2, loss_test, mf_loss_test, emb_loss_test, reg_loss_test,
', '.join(['%.5f' % r for r in ret['recall']]),
', '.join(['%.5f' % r for r in ret['precision']]),
', '.join(['%.5f' % r for r in ret['ndcg']]))
print(perf_str)
cur_best_pre_0, stopping_step, should_stop = early_stopping(ret['recall'][0], cur_best_pre_0,
stopping_step, expected_order='acc', flag_step=5)
# *********************************************************
# early stopping when cur_best_pre_0 is decreasing for ten successive steps.
if should_stop == True:
break
# *********************************************************
# save the user & item embeddings for pretraining.
if ret['recall'][0] == cur_best_pre_0 and args.save_flag == 1:
save_saver.save(sess, weights_save_path + '/weights', global_step=epoch)
print('save the weights in path: ', weights_save_path)
recs = np.array(rec_loger)
pres = np.array(pre_loger)
ndcgs = np.array(ndcg_loger)
best_rec_0 = max(recs[:, 0])
idx = list(recs[:, 0]).index(best_rec_0)
final_perf = "Best Iter=[%d]@[%.1f]\trecall=[%s], precision=[%s], ndcg=[%s]" % \
(idx, time() - t0, '\t'.join(['%.5f' % r for r in recs[idx]]),
'\t'.join(['%.5f' % r for r in pres[idx]]),
'\t'.join(['%.5f' % r for r in ndcgs[idx]]))
print(final_perf)
save_path = '%soutput/%s/%s.result' % (args.proj_path, args.dataset, model.model_type)
ensureDir(save_path)
f = open(save_path, 'a')
f.write(
'embed_size=%d, lr=%.4f, layer_size=%s, node_dropout=%s, mess_dropout=%s, regs=%s, adj_type=%s\n\t%s\n'
% (args.embed_size, args.lr, args.layer_size, args.node_dropout, args.mess_dropout, args.regs,
args.adj_type, final_perf))
f.close()
第三篇论文是关于NGCF的应用:(看得六成懂吧)
“Embedding App-Library Graph for Neural Third Party Library”这篇论文的主题是研究和演示如何使用图神经网络为软件开发者推荐第三方库。
文章的核心思想是利用图神经网络的能力来抽取和处理复杂的图关系。其中的App-Library图是这项工作的一项重要贡献,它建立了移动应用(App)和第三方库(Library)之间复杂的关系。在这个图中,节点代表应用和库,而边则表示应用和库之间的使用关系。通过这种方式,App-Library图能够反映出App与库之间以及库与库之间的依赖关系。
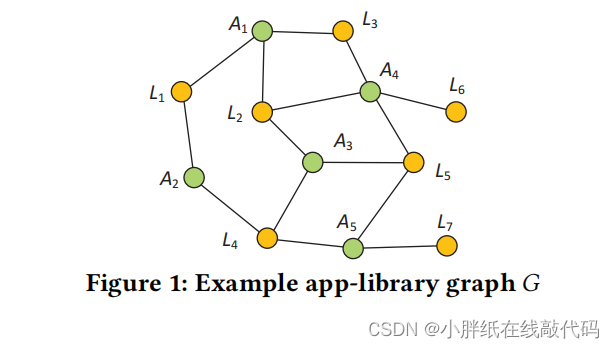
GRec是建立在App-Library图的基础之上,利用深度图神经网络在这个图上进行训练,得到了应用和库之间复杂关系的内在表示。这种方法允许模型更好地理解应用和库之间的潜在关系,并基于这些关系为开发者推荐最合适的库。
GRec的另一个突出之处是它在处理图时采用了多跳邻接特性,这使得它能在更大的上下文中看到每个节点,获取更多的相关信息。
而且,他们的实验结果也表明,GRec在推荐效果上优于其他基准方法,这进一步证明了该模型的有效性。















 4968
4968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









