






【推荐系统论文代码讲解】Neural Graph Collaborative Filtering_哔哩哔哩_bilibili
【详细过程】
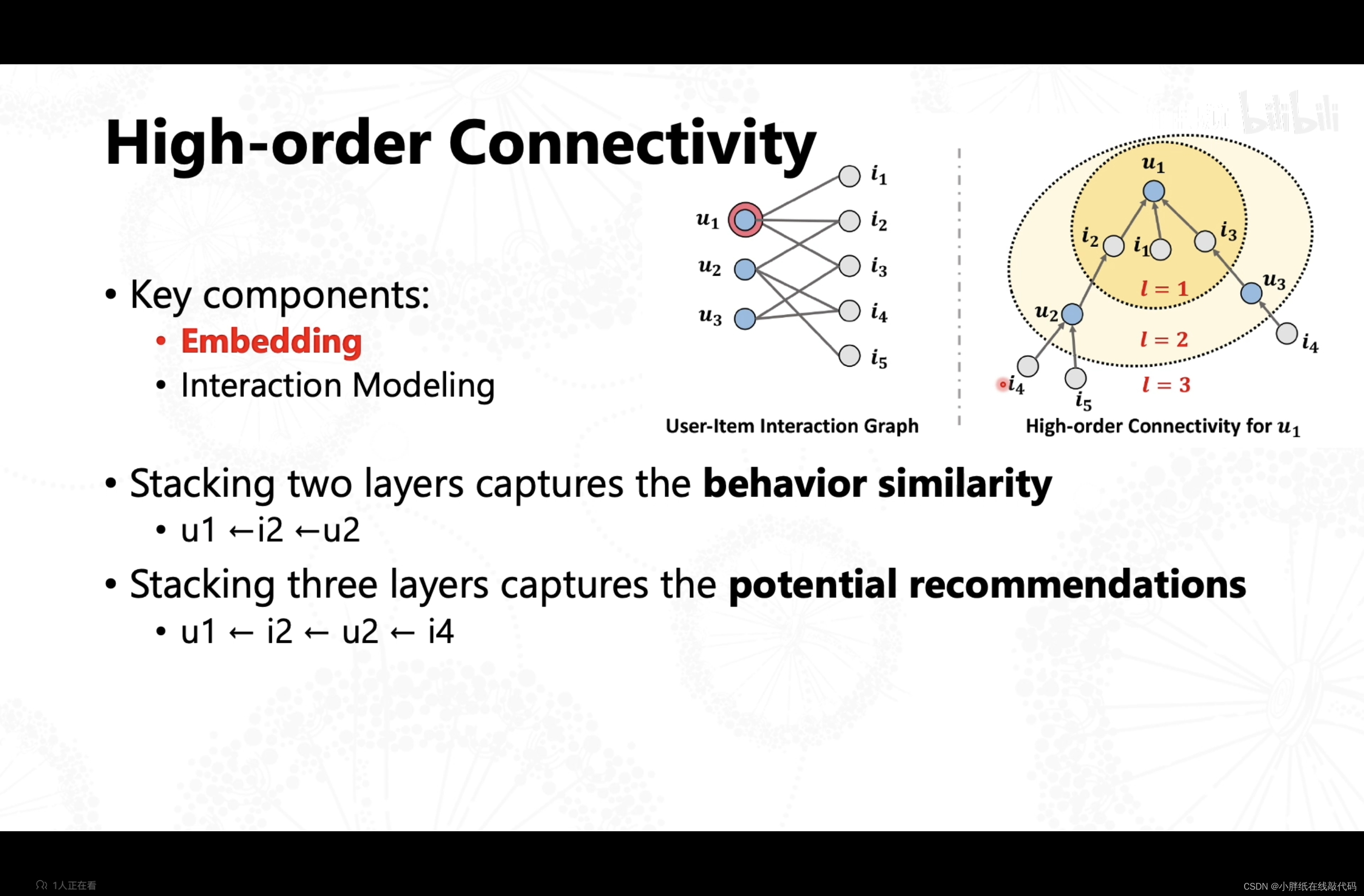
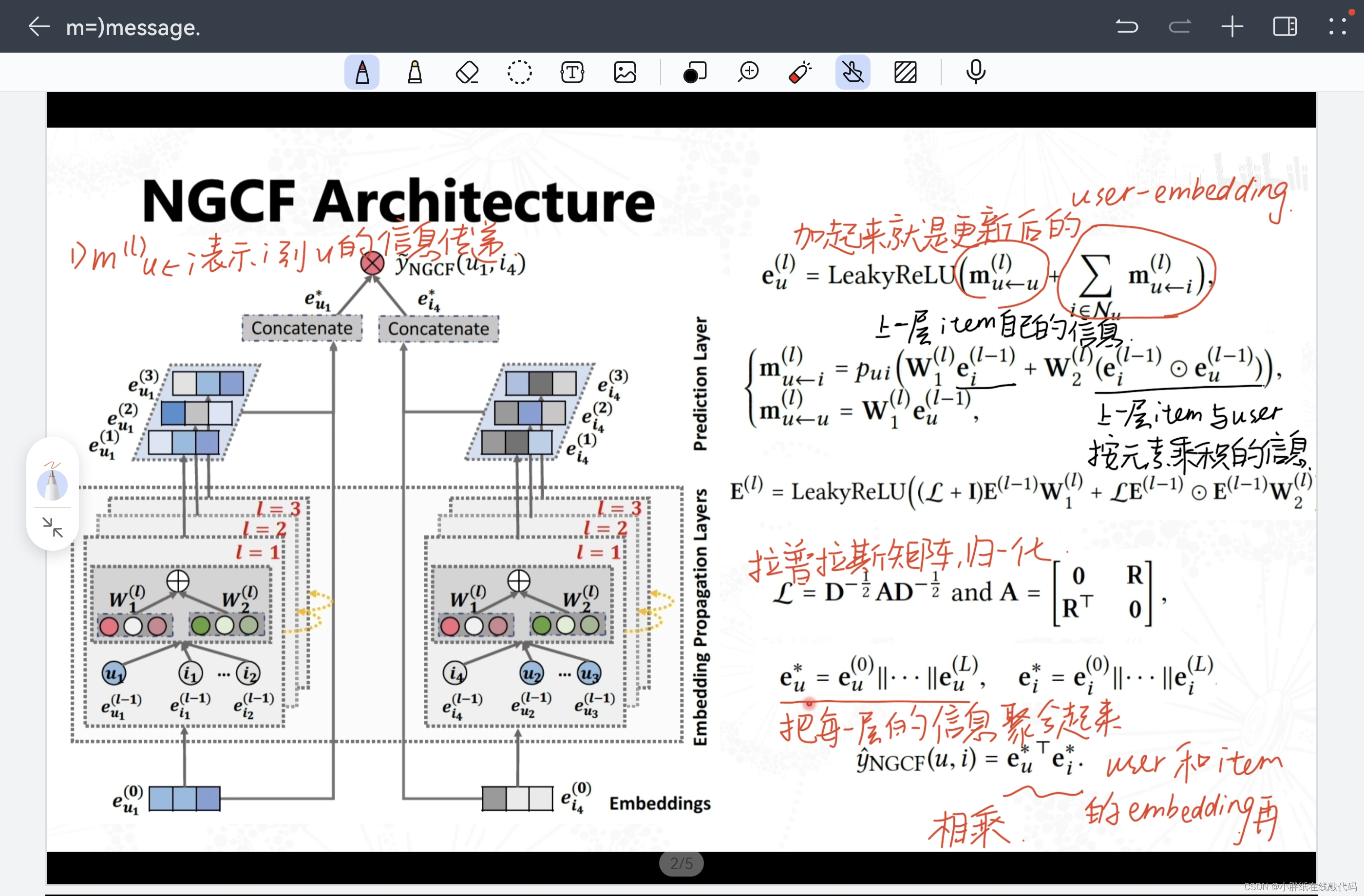
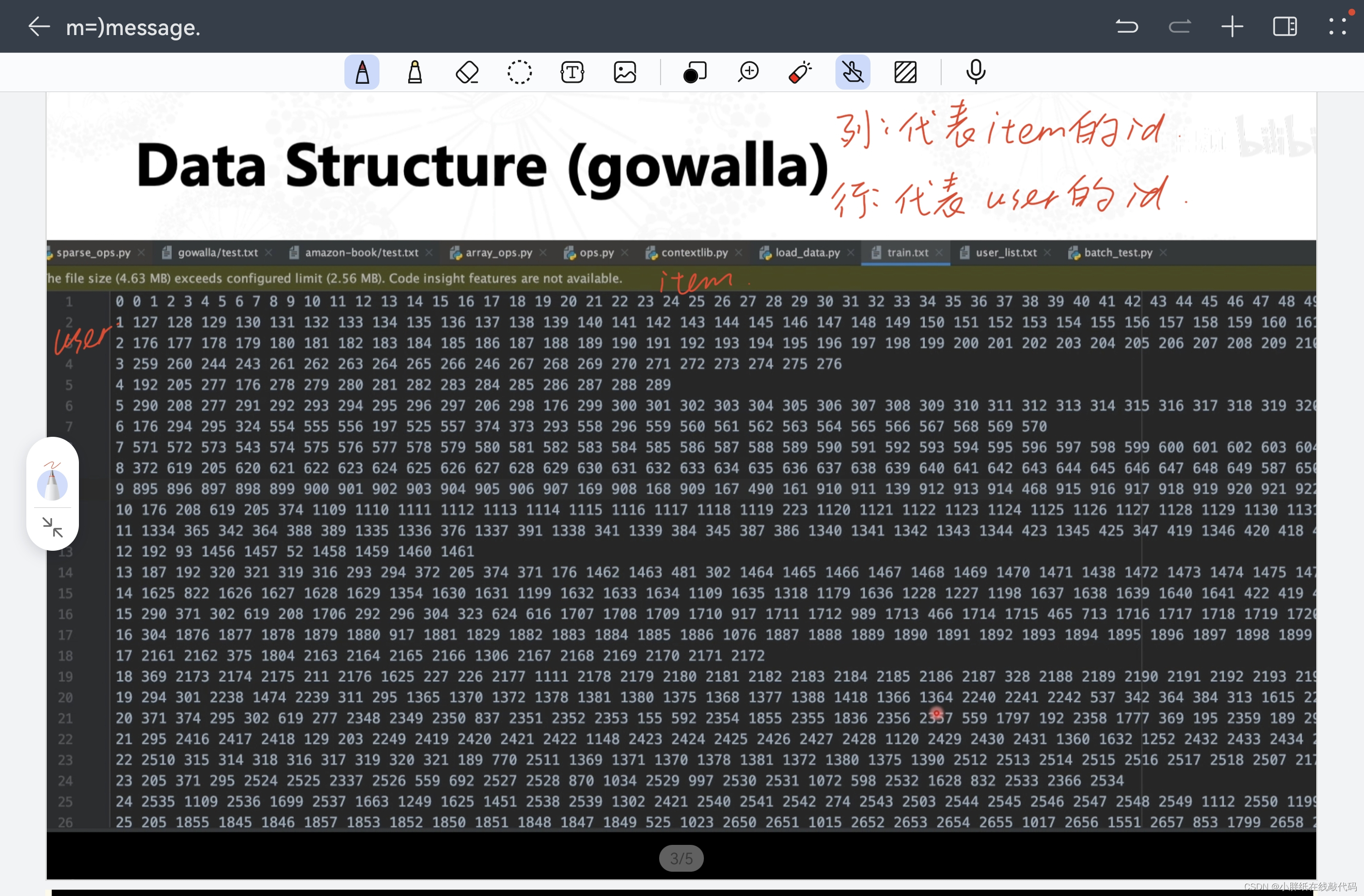
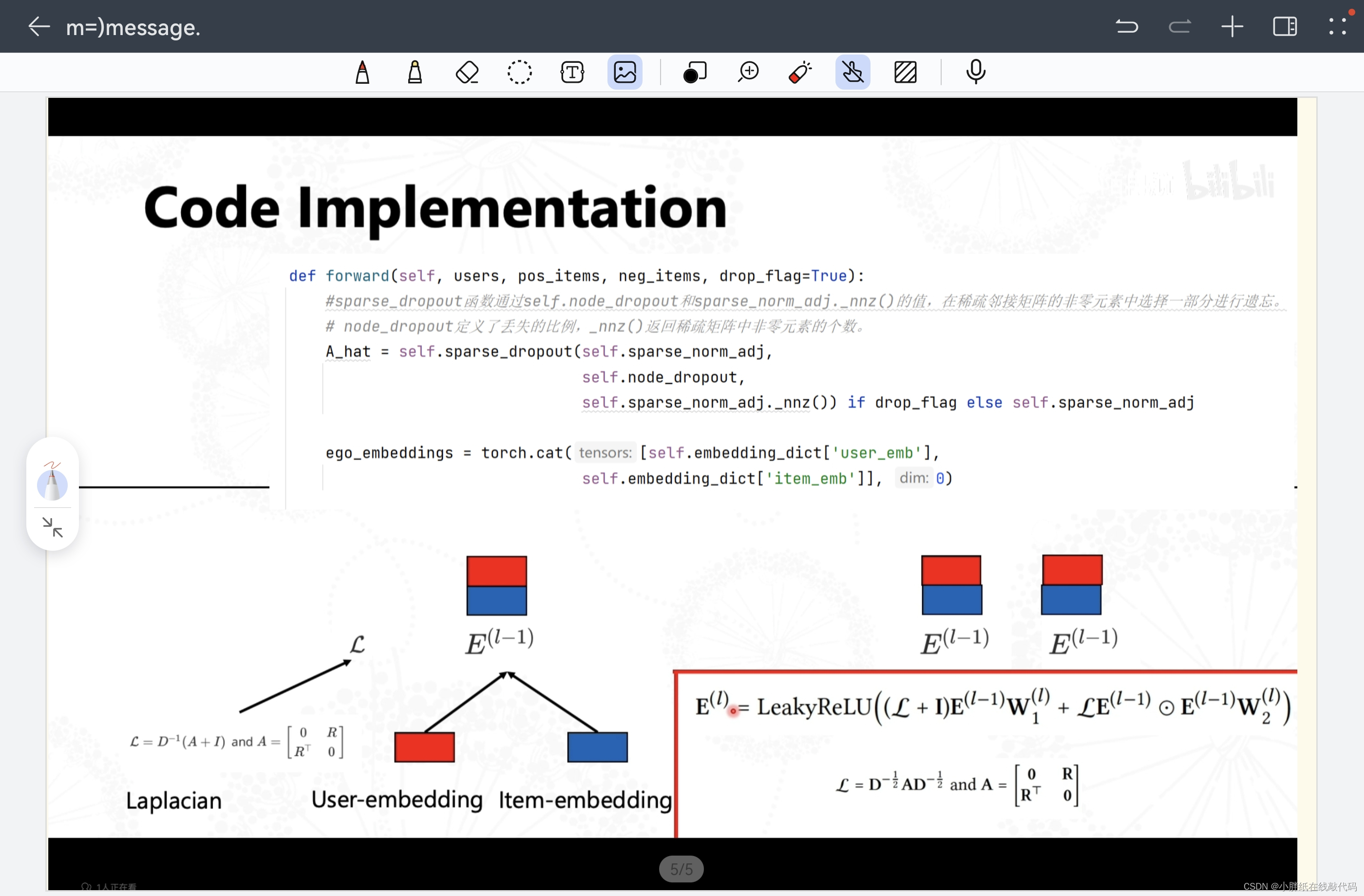

【NGCF.py】
'''
Created on March 24, 2020
@author: Tinglin Huang (huangtinglin@outlook.com)
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
class NGCF(nn.Module):
def __init__(self, n_user, n_item, norm_adj, args):
super(NGCF, self).__init__()
self.n_user = n_user #这两个参数是用户数量和商品数量,用于设定用户和物品的嵌入矩阵大小。
self.n_item = n_item
self.device = args.device
self.emb_size = args.embed_size #这是嵌入空间的大小,可以理解为在向量空间中表示每个用户和物品所需的维度。
self.batch_size = args.batch_size #批处理大小
self.node_dropout = args.node_dropout[0] #dropout是丢弃率
self.mess_dropout = args.mess_dropout
self.batch_size = args.batch_size
self.norm_adj = norm_adj #这是一个归一化的邻接矩阵,表示用户和物品之间的互动,也就是图(graph)的结构信息。
self.layers = eval(args.layer_size) #eval函数可以将字符串形式的值转换为实际的列表
self.decay = eval(args.regs)[0]
"""
*********************************************************
Init the weight of user-item.
"""
self.embedding_dict, self.weight_dict = self.init_weight()
"""
*********************************************************
Get sparse adj.
"""
self.sparse_norm_adj = self._convert_sp_mat_to_sp_tensor(self.norm_adj).to(self.device)
#将归一化的邻接矩阵从稀疏矩阵转化成稀疏张量格式的表示
def init_weight(self):
# xavier init,均匀初始化,把这个方法赋值给initializer
initializer = nn.init.xavier_uniform_
#self.n_user 代表用户的总数量,self.emb_size 表示嵌入向量的大小。
#nn.Parameter 用于表示模型参数,这些参数在反向传播过程中会自动更新。
embedding_dict = nn.ParameterDict({
'user_emb': nn.Parameter(initializer(torch.empty(self.n_user,
self.emb_size))),
'item_emb': nn.Parameter(initializer(torch.empty(self.n_item,
self.emb_size)))
})
weight_dict = nn.ParameterDict()
layers = [self.emb_size] + self.layers #创建一个列表 layers,该列表包含嵌入层大小和其他层大小。
#初始化权重(weight_dict)和偏置(b)参数。
for k in range(len(self.layers)):
weight_dict.update({'W_gc_%d'%k: nn.Parameter(initializer(torch.empty(layers[k],
layers[k+1])))})
weight_dict.update({'b_gc_%d'%k: nn.Parameter(initializer(torch.empty(1, layers[k+1])))})
weight_dict.update({'W_bi_%d'%k: nn.Parameter(initializer(torch.empty(layers[k],
layers[k+1])))})
weight_dict.update({'b_bi_%d'%k: nn.Parameter(initializer(torch.empty(1, layers[k+1])))})
return embedding_dict, weight_dict
#输入矩阵X转换为coo格式(即坐标格式)。在coo格式中,只需要存储非0元素的值以及它们的索引即可,从而节省存储空间。
# 这是通过调用X.tocoo()方法实现的。
def _convert_sp_mat_to_sp_tensor(self, X):
coo = X.tocoo()
i = torch.LongTensor([coo.row, coo.col])
v = torch.from_numpy(coo.data).float() #将coo矩阵中非0元素的值coo.data转换为一个PyTorch的浮点型张量v。
return torch.sparse.FloatTensor(i, v, coo.shape)
#该稀疏张量的索引为i,对应元素的值为v,并且拥有与原始矩阵X相同的形状coo.shape。
#dropout以一定的概率随机关闭一部分神经元,防止过拟合。
def sparse_dropout(self, x, rate, noise_shape):
random_tensor = 1 - rate
random_tensor += torch.rand(noise_shape).to(x.device)
dropout_mask = torch.floor(random_tensor).type(torch.bool)#掩码张量
i = x._indices()#一个二维张量,其中每一列都表示一个非零元素的索引。
v = x._values()#返回一个一维张量,其中每个元素都是一个非零元素的值。
i = i[:, dropout_mask]
v = v[dropout_mask]
#对i和v使用相同的dropout_mask是因为我们希望在dropout操作后,稀疏张量中的索引和值仍然对应。
# 换句话说,每一个保留下来的值,都需要一个与其对应的索引。
out = torch.sparse.FloatTensor(i, v, x.shape).to(x.device)
return out * (1. / (1 - rate))
def create_bpr_loss(self, users, pos_items, neg_items):
pos_scores = torch.sum(torch.mul(users, pos_items), axis=1)#axis=1对每一行进行操作
neg_scores = torch.sum(torch.mul(users, neg_items), axis=1)
maxi = nn.LogSigmoid()(pos_scores - neg_scores)
mf_loss = -1 * torch.mean(maxi)
# cul regularizer
regularizer = (torch.norm(users) ** 2
+ torch.norm(pos_items) ** 2
+ torch.norm(neg_items) ** 2) / 2
emb_loss = self.decay * regularizer / self.batch_size
return mf_loss + emb_loss, mf_loss, emb_loss
def rating(self, u_g_embeddings, pos_i_g_embeddings):
return torch.matmul(u_g_embeddings, pos_i_g_embeddings.t())
def forward(self, users, pos_items, neg_items, drop_flag=True):
#sparse_dropout函数通过self.node_dropout和sparse_norm_adj._nnz()的值,在稀疏邻接矩阵的非零元素中选择一部分进行遗忘。
# node_dropout定义了丢失的比例,_nnz()返回稀疏矩阵中非零元素的个数。
A_hat = self.sparse_dropout(self.sparse_norm_adj,
self.node_dropout,
self.sparse_norm_adj._nnz()) if drop_flag else self.sparse_norm_adj
ego_embeddings = torch.cat([self.embedding_dict['user_emb'],
self.embedding_dict['item_emb']], 0)
all_embeddings = [ego_embeddings]
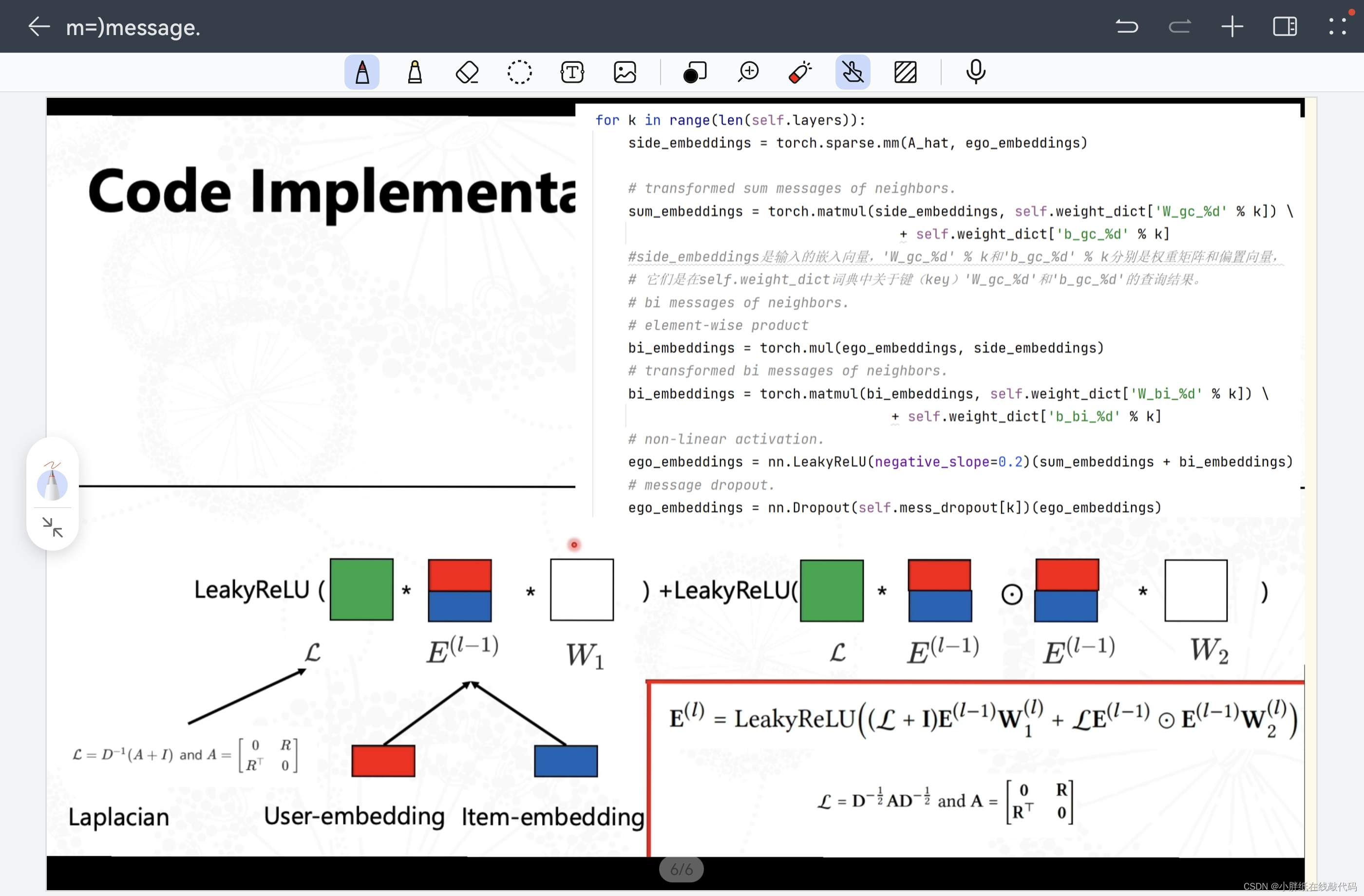
for k in range(len(self.layers)):
side_embeddings = torch.sparse.mm(A_hat, ego_embeddings)
# transformed sum messages of neighbors.
sum_embeddings = torch.matmul(side_embeddings, self.weight_dict['W_gc_%d' % k]) \
+ self.weight_dict['b_gc_%d' % k]
#side_embeddings是输入的嵌入向量,'W_gc_%d' % k和'b_gc_%d' % k分别是权重矩阵和偏置向量,
# 它们是在self.weight_dict词典中关于键(key)'W_gc_%d'和'b_gc_%d'的查询结果。
# bi messages of neighbors.
# element-wise product
bi_embeddings = torch.mul(ego_embeddings, side_embeddings)
# transformed bi messages of neighbors.
bi_embeddings = torch.matmul(bi_embeddings, self.weight_dict['W_bi_%d' % k]) \
+ self.weight_dict['b_bi_%d' % k]
# non-linear activation.
ego_embeddings = nn.LeakyReLU(negative_slope=0.2)(sum_embeddings + bi_embeddings)
# message dropout.
ego_embeddings = nn.Dropout(self.mess_dropout[k])(ego_embeddings)
# normalize the distribution of embeddings.
norm_embeddings = F.normalize(ego_embeddings, p=2, dim=1)
all_embeddings += [norm_embeddings]
all_embeddings = torch.cat(all_embeddings, 1)
u_g_embeddings = all_embeddings[:self.n_user, :]
i_g_embeddings = all_embeddings[self.n_user:, :]
"""
*********************************************************
look up.
"""
u_g_embeddings = u_g_embeddings[users, :]
pos_i_g_embeddings = i_g_embeddings[pos_items, :]
neg_i_g_embeddings = i_g_embeddings[neg_items, :]
return u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings
【main.py】
'''
Created on March 24, 2020
@author: Tinglin Huang (huangtinglin@outlook.com)
'''
import numpy as np
import torch
import torch.optim as optim
from NGCF import NGCF
from utility.helper import *
from utility.batch_test import *
import warnings
warnings.filterwarnings('ignore')
from time import time
if __name__ == '__main__':
args.device = torch.device('cuda:' + str(args.gpu_id))
plain_adj, norm_adj, mean_adj = data_generator.get_adj_mat()
#获取了平均邻接矩阵,标准化邻接矩阵和邻接矩阵的平均值。
args.node_dropout = eval(args.node_dropout)
args.mess_dropout = eval(args.mess_dropout)
model = NGCF(data_generator.n_users,
data_generator.n_items,
norm_adj,
args).to(args.device)
t0 = time()
"""
*********************************************************
Train.
"""
cur_best_pre_0, stopping_step = 0, 0
optimizer = optim.Adam(model.parameters(), lr=args.lr)
loss_loger, pre_loger, rec_loger, ndcg_loger, hit_loger = [], [], [], [], []
for epoch in range(args.epoch):
t1 = time()
loss, mf_loss, emb_loss = 0., 0., 0.
n_batch = data_generator.n_train // args.batch_size + 1
for idx in range(n_batch):
users, pos_items, neg_items = data_generator.sample()
u_g_embeddings, pos_i_g_embeddings, neg_i_g_embeddings = model(users,
pos_items,
neg_items,
drop_flag=args.node_dropout_flag)
batch_loss, batch_mf_loss, batch_emb_loss = model.create_bpr_loss(u_g_embeddings,
pos_i_g_embeddings,
neg_i_g_embeddings)
optimizer.zero_grad()
batch_loss.backward()
optimizer.step()
loss += batch_loss
mf_loss += batch_mf_loss
emb_loss += batch_emb_loss
if (epoch + 1) % 10 != 0:
if args.verbose > 0 and epoch % args.verbose == 0:
perf_str = 'Epoch %d [%.1fs]: train==[%.5f=%.5f + %.5f]' % (
epoch, time() - t1, loss, mf_loss, emb_loss)
print(perf_str)
continue
t2 = time()
users_to_test = list(data_generator.test_set.keys())
ret = test(model, users_to_test, drop_flag=False)
t3 = time()
loss_loger.append(loss)
rec_loger.append(ret['recall'])
pre_loger.append(ret['precision'])
ndcg_loger.append(ret['ndcg'])
hit_loger.append(ret['hit_ratio'])
if args.verbose > 0:
perf_str = 'Epoch %d [%.1fs + %.1fs]: train==[%.5f=%.5f + %.5f], recall=[%.5f, %.5f], ' \
'precision=[%.5f, %.5f], hit=[%.5f, %.5f], ndcg=[%.5f, %.5f]' % \
(epoch, t2 - t1, t3 - t2, loss, mf_loss, emb_loss, ret['recall'][0], ret['recall'][-1],
ret['precision'][0], ret['precision'][-1], ret['hit_ratio'][0], ret['hit_ratio'][-1],
ret['ndcg'][0], ret['ndcg'][-1])
print(perf_str)
cur_best_pre_0, stopping_step, should_stop = early_stopping(ret['recall'][0], cur_best_pre_0,
stopping_step, expected_order='acc', flag_step=5)
# *********************************************************
# early stopping when cur_best_pre_0 is decreasing for ten successive steps.
if should_stop == True:
break
# *********************************************************
# save the user & item embeddings for pretraining.
if ret['recall'][0] == cur_best_pre_0 and args.save_flag == 1:
torch.save(model.state_dict(), args.weights_path + str(epoch) + '.pkl')
print('save the weights in path: ', args.weights_path + str(epoch) + '.pkl')
recs = np.array(rec_loger)
pres = np.array(pre_loger)
ndcgs = np.array(ndcg_loger)
hit = np.array(hit_loger)
best_rec_0 = max(recs[:, 0])
idx = list(recs[:, 0]).index(best_rec_0)
final_perf = "Best Iter=[%d]@[%.1f]\trecall=[%s], precision=[%s], hit=[%s], ndcg=[%s]" % \
(idx, time() - t0, '\t'.join(['%.5f' % r for r in recs[idx]]),
'\t'.join(['%.5f' % r for r in pres[idx]]),
'\t'.join(['%.5f' % r for r in hit[idx]]),
'\t'.join(['%.5f' % r for r in ndcgs[idx]]))
print(final_perf)GREC代码(在NGCF的基础上做了小的修改)
【main.py】
import torch
import torch.nn as nn
import torch.sparse as sparse
import torch.nn.functional as F
import torch.optim as optim
import csv
import os
import sys
import datetime
import math
from Models import *
from utility.helper import *
from utility.batch_test import *
class Model_Wrapper(object):
def __init__(self, data_config, pretrain_data):
# argument settings
self.model_type = args.model_type
self.adj_type = args.adj_type
self.alg_type = args.alg_type
self.mess_dropout = eval(args.mess_dropout)
self.pretrain_data = pretrain_data
self.n_users = data_config['n_users']
self.n_items = data_config['n_items']
self.norm_adj = data_config['norm_adj']
self.norm_adj = self.sparse_mx_to_torch_sparse_tensor(self.norm_adj).float()
self.record_alphas = False
self.lr = args.lr
self.emb_dim = args.embed_size
self.batch_size = args.batch_size
self.weight_size = eval(args.layer_size)
self.n_layers = len(self.weight_size)
self.model_type += '_%s_%s_l%d' % (self.adj_type, self.alg_type, self.n_layers)
self.regs = eval(args.regs)
self.decay = self.regs[0]
self.verbose = args.verbose
print('model_type is {}'.format(self.model_type))
self.weights_save_path = '%sweights/%s/%s/l%s/r%s' % (args.weights_path, args.dataset, self.model_type,
str(args.lr), '-'.join([str(r) for r in eval(args.regs)]))
"""
*********************************************************
Compute Graph-based Representations of all users & items via Message-Passing Mechanism of Graph Neural Networks.
"""
print('----self.alg_type is {}----'.format(self.alg_type))
if self.alg_type in ['ngcf']:
self.model = NGCF(self.n_users, self.n_items, self.emb_dim, self.weight_size, self.mess_dropout)
elif self.alg_type in ['mf']:
self.model = MF(self.n_users, self.n_items, self.emb_dim)
else:
raise Exception('Dont know which model to train')
self.model = self.model.cuda()
self.norm_adj = self.norm_adj.cuda()
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
self.lr_scheduler = self.set_lr_scheduler()
print(self.model)
for name, param in self.model.named_parameters():
print(name, ' ', param.size())
def set_lr_scheduler(self):
fac = lambda epoch: 0.96 ** (epoch / 50)
scheduler = optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda=fac)
return scheduler
def save_model(self):
ensureDir(self.weights_save_path)
torch.save(self.model.state_dict(), self.weights_save_path)
def load_model(self):
self.model.load_state_dict(torch.load(self.weights_save_path))
def test(self, users_to_test, drop_flag=False, batch_test_flag=False):
self.model.eval()
with torch.no_grad():
ua_embeddings, ia_embeddings = self.model(self.norm_adj)
result = test_torch(ua_embeddings, ia_embeddings, users_to_test)
return result
def train(self):
training_time_list = []
loss_loger, pre_loger, rec_loger, ndcg_loger, hit_loger, map_loger, mrr_loger, fone_loger = [], [], [], [], [], [], [], []
stopping_step = 0
should_stop = False
cur_best_pre_0 = 0.
n_batch = data_generator.n_train // args.batch_size + 1
for epoch in range(args.epoch):
t1 = time()
loss, mf_loss, emb_loss, reg_loss = 0., 0., 0., 0.
n_batch = data_generator.n_train // args.batch_size + 1
f_time, b_time, loss_time, opt_time, clip_time, emb_time = 0., 0., 0., 0., 0., 0.
sample_time = 0.
cuda_time = 0.
for idx in range(n_batch):
self.model.train()
self.optimizer.zero_grad()
sample_t1 = time()
users, pos_items, neg_items = data_generator.sample()
sample_time += time() - sample_t1
ua_embeddings, ia_embeddings = self.model(self.norm_adj)
u_g_embeddings = ua_embeddings[users]
pos_i_g_embeddings = ia_embeddings[pos_items]
neg_i_g_embeddings = ia_embeddings[neg_items]
batch_mf_loss, batch_emb_loss, batch_reg_loss = self.bpr_loss(u_g_embeddings, pos_i_g_embeddings,
neg_i_g_embeddings)
batch_loss = batch_mf_loss + batch_emb_loss + batch_reg_loss
batch_loss.backward()
self.optimizer.step()
loss += float(batch_loss)
# print('loss: ', loss)
mf_loss += float(batch_mf_loss)
emb_loss += float(batch_emb_loss)
reg_loss += float(batch_reg_loss)
self.lr_scheduler.step()
del ua_embeddings, ia_embeddings, u_g_embeddings, neg_i_g_embeddings, pos_i_g_embeddings
if math.isnan(loss) == True:
print('ERROR: loss is nan.')
sys.exit()
# print the test evaluation metrics each 10 epochs; pos:neg = 1:10.
if (epoch + 1) % 10 != 0:
if args.verbose > 0 and epoch % args.verbose == 0:
perf_str = 'Epoch %d [%.1fs]: train==[%.5f=%.5f + %.5f]' % (
epoch, time() - t1, loss, mf_loss, emb_loss)
#training_time_list.append(time() - t1)
print(perf_str)
continue
t2 = time()
users_to_test = list(data_generator.test_set.keys())
ret = self.test(users_to_test, drop_flag=True)
training_time_list.append(t2 - t1)
t3 = time()
loss_loger.append(loss)
rec_loger.append(ret['recall'])
pre_loger.append(ret['precision'])
ndcg_loger.append(ret['ndcg'])
hit_loger.append(ret['hit_ratio'])
map_loger.append(ret['map'])
mrr_loger.append(ret['mrr'])
fone_loger.append(ret['fone'])
if args.verbose > 0:
perf_str = 'Epoch %d [%.1fs + %.1fs]: train==[%.5f=%.5f + %.5f + %.5f], recall=[%.5f, %.5f], ' \
'precision=[%.5f, %.5f], hit=[%.5f, %.5f], ndcg=[%.5f, %.5f], map=[%.5f, %.5f], mrr=[%.5f, %.5f], f1=[%.5f, %.5f]' % \
(epoch, t2 - t1, t3 - t2, loss, mf_loss, emb_loss, reg_loss, ret['recall'][0],
ret['recall'][-1],
ret['precision'][0], ret['precision'][-1], ret['hit_ratio'][0], ret['hit_ratio'][-1],
ret['ndcg'][0], ret['ndcg'][-1],ret['map'][0], ret['map'][-1],ret['mrr'][0], ret['mrr'][-1],ret['fone'][0], ret['fone'][-1])
print(perf_str)
cur_best_pre_0, stopping_step, should_stop = early_stopping(ret['recall'][0], cur_best_pre_0,
stopping_step, expected_order='acc',
flag_step=5)
# *********************************************************
# early stopping when cur_best_pre_0 is decreasing for ten successive steps.
if should_stop:
break
# *********************************************************
# save the user & item embeddings for pretraining.
if ret['recall'][0] == cur_best_pre_0 and args.save_flag == 1:
# save_saver.save(sess, weights_save_path + '/weights', global_step=epoch)
self.save_model()
if self.record_alphas:
self.best_alphas = [i for i in self.model.get_alphas()]
print('save the weights in path: ', self.weights_save_path)
#print the final recommendation results to csv files.
if args.save_recom:
results_save_path = '%soutput/%s/reRecommendation.csv' % (args.proj_path, args.dataset)
self.save_recResult(results_save_path)
if rec_loger != []:
self.print_final_results(rec_loger, pre_loger, ndcg_loger, hit_loger, map_loger,mrr_loger,fone_loger,training_time_list)
def save_recResult(self,outputPath):
#used for reverve the recommendation lists
recommendResult = {}
u_batch_size = BATCH_SIZE * 2
i_batch_size = BATCH_SIZE
#get all apps (users)
users_to_test = list(data_generator.test_set.keys())
n_test_users = len(users_to_test)
n_user_batchs = n_test_users // u_batch_size + 1
count = 0
#calculate the result by our own
#get the latent factors
self.model.eval()
with torch.no_grad():
ua_embeddings, ia_embeddings = self.model(self.norm_adj)
#get result in batch
for u_batch_id in range(n_user_batchs):
start = u_batch_id * u_batch_size
end = (u_batch_id + 1) * u_batch_size
user_batch = users_to_test[start: end]
item_batch = range(ITEM_NUM)
u_g_embeddings = ua_embeddings[user_batch]
i_g_embeddings = ia_embeddings[item_batch]
#get the ratings
rate_batch = torch.matmul(u_g_embeddings, torch.transpose(i_g_embeddings, 0, 1))
#move from GPU to CPU
rate_batch = rate_batch.detach().cpu().numpy()
#contact each user's ratings with his id
user_rating_uid = zip(rate_batch, user_batch)
#now for each user, calculate his ratings and recommendation
for x in user_rating_uid:
#user u's ratings for user u
rating = x[0]
#uid
u = x[1]
training_items = data_generator.train_items[u]
user_pos_test = data_generator.test_set[u]
all_items = set(range(ITEM_NUM))
test_items = list(all_items - set(training_items))
item_score = {}
for i in test_items:
item_score[i] = rating[i]
K_max = max(Ks)
K_max_item_score = heapq.nlargest(K_max, item_score, key=item_score.get)
recommendResult[u] = K_max_item_score
#output the result to csv file.
ensureDir(outputPath)
with open(outputPath, 'w') as f:
print("----the recommend result has %s items." % (len(recommendResult)))
for key in recommendResult.keys(): #due to that all users have been used for test and the subscripts start from 0.
outString = ""
for v in recommendResult[key]:
outString = outString + "," + str(v)
f.write("%s%s\n"%(key,outString))
#f.write("%s,%s\n"%(key,recommendResult[key]))
def print_final_results(self, rec_loger, pre_loger, ndcg_loger, hit_loger,map_loger,mrr_loger,fone_loger,training_time_list):
recs = np.array(rec_loger)
pres = np.array(pre_loger)
map = np.array(map_loger)
mrr = np.array(mrr_loger)
fone = np.array(fone_loger)
best_rec_0 = max(recs[:, 0])
idx = list(recs[:, 0]).index(best_rec_0)
final_perf = "Best Iter=[%d]@[%.1f]\trecall=[%s], precision=[%s], hit=[%s], ndcg=[%s], map=[%s],mrr=[%s], f1=[%s]" % \
(idx, time() - t0, '\t'.join(['%.5f' % r for r in recs[idx]]),
'\t'.join(['%.5f' % r for r in pres[idx]]),
'\t'.join(['%.5f' % r for r in map[idx]]),
'\t'.join(['%.5f' % r for r in mrr[idx]]),
'\t'.join(['%.5f' % r for r in fone[idx]]))
#output the result that can be uesed by Matlab.
final_perf_output = "%s\n%s\n%s\n%s\n%s\n%s\n%s" % \
(','.join(['%.5f' % r for r in recs[idx]]),
','.join(['%.5f' % r for r in pres[idx]]),
','.join(['%.5f' % r for r in map[idx]]),
','.join(['%.5f' % r for r in mrr[idx]]),
','.join(['%.5f' % r for r in fone[idx]]))
print(final_perf)
# Benchmarking: time consuming
avg_time = sum(training_time_list) / len(training_time_list)
time_consume = "Benchmarking time consuming: average {}s per epoch".format(avg_time)
print(time_consume)
results_path = '%soutput/%s/result.csv' % (args.proj_path, args.dataset)
ensureDir(results_path)
f = open(results_path, 'a')
f.write(final_perf_output)
f.close()
def bpr_loss(self, users, pos_items, neg_items):
pos_scores = torch.sum(torch.mul(users, pos_items), dim=1)
neg_scores = torch.sum(torch.mul(users, neg_items), dim=1)
regularizer = 1./2*(users**2).sum() + 1./2*(pos_items**2).sum() + 1./2*(neg_items**2).sum()
regularizer = regularizer / self.batch_size
maxi = F.logsigmoid(pos_scores - neg_scores)
mf_loss = -torch.mean(maxi)
emb_loss = self.decay * regularizer
reg_loss = 0.0
return mf_loss, emb_loss, reg_loss
def sparse_mx_to_torch_sparse_tensor(self, sparse_mx):
"""Convert a scipy sparse matrix to a torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)
def get_sparse_tensor_value(self, X):
coo = X.tocoo().astype(np.float32)
indices = np.mat([coo.row, coo.col]).transpose()
return indices, coo.data, coo.shape
def load_pretrained_data():
pretrain_path = '%spretrain/%s/%s.npz' % (args.proj_path, args.dataset, 'embedding')
try:
pretrain_data = np.load(pretrain_path)
print('load the pretrained embeddings.')
except Exception:
pretrain_data = None
return pretrain_data
if __name__ == '__main__':
os.environ["CUDA_VISIBLE_DEVICES"] = str(args.gpu_id)
config = dict()
config['n_users'] = data_generator.n_users
config['n_items'] = data_generator.n_items
"""
*********************************************************
Generate the Laplacian matrix, where each entry defines the decay factor (e.g., p_ui) between two connected nodes.
"""
plain_adj, norm_adj, mean_adj = data_generator.get_adj_mat()
if args.adj_type == 'norm':
config['norm_adj'] = norm_adj
print('use the normalized adjacency matrix')
else:
config['norm_adj'] = mean_adj + sp.eye(mean_adj.shape[0])
print('use the mean adjacency matrix')
t0 = time()
if args.pretrain == -1:
pretrain_data = load_pretrained_data()
else:
pretrain_data = None
Engine = Model_Wrapper(data_config=config, pretrain_data=pretrain_data)
if args.pretrain:
print('pretrain path: ', Engine.weights_save_path)
if os.path.exists(Engine.weights_save_path):
Engine.load_model()
users_to_test = list(data_generator.test_set.keys())
ret = Engine.test(users_to_test, drop_flag=True)
cur_best_pre_0 = ret['recall'][0]
pretrain_ret = 'pretrained model recall=[%.5f, %.5f], precision=[%.5f, %.5f], hit=[%.5f, %.5f],' \
'ndcg=[%.5f, %.5f], map=[%.5f, %.5f], mrr=[%.5f, %.5f], f1=[%.5f, %.5f]' % \
(ret['recall'][0], ret['recall'][-1],
ret['precision'][0], ret['precision'][-1],
ret['hit_ratio'][0], ret['hit_ratio'][-1],
ret['ndcg'][0], ret['ndcg'][-1],
ret['map'][0], ret['map'][-1],
ret['mrr'][0], ret['mrr'][-1],
ret['fone'][0], ret['fone'][-1])
print(pretrain_ret)
else:
print('Cannot load pretrained model. Start training from stratch')
else:
print('without pretraining')
Engine.train()【Models.py】
import torch
import torch.nn as nn
import torch.sparse as sparse
import torch.nn.functional as F
import numpy as np
#This source file is based on the NGCF framwork published by Xiang Wang et al.
#We would like to thank and offer our appreciation to them.
#Original algorithm can be found in paper: Neural Graph Collaborative Filtering, SIGIR 2019.
class NGCF(nn.Module):
def __init__(self, n_users, n_items, embedding_dim, weight_size, dropout_list):
super().__init__()
self.n_users = n_users
self.n_items = n_items
self.embedding_dim = embedding_dim
self.weight_size = weight_size
self.n_layers = len(self.weight_size)
self.dropout_list = nn.ModuleList()
self.GC_Linear_list = nn.ModuleList()
self.Bi_Linear_list = nn.ModuleList()
self.weight_size = [self.embedding_dim] + self.weight_size
for i in range(self.n_layers):
self.GC_Linear_list.append(nn.Linear(self.weight_size[i], self.weight_size[i+1]))
self.Bi_Linear_list.append(nn.Linear(self.weight_size[i], self.weight_size[i+1]))
self.dropout_list.append(nn.Dropout(dropout_list[i]))
self.user_embedding = nn.Embedding(n_users, embedding_dim)
self.item_embedding = nn.Embedding(n_items, embedding_dim)
self._init_weight_()
def _init_weight_(self):
nn.init.xavier_uniform_(self.user_embedding.weight)
nn.init.xavier_uniform_(self.item_embedding.weight)
def forward(self, adj):
ego_embeddings = torch.cat((self.user_embedding.weight, self.item_embedding.weight), dim=0)
all_embeddings = [ego_embeddings]
for i in range(self.n_layers):
side_embeddings = torch.sparse.mm(adj, ego_embeddings)
sum_embeddings = F.leaky_relu(self.GC_Linear_list[i](side_embeddings))
bi_embeddings = torch.mul(ego_embeddings, side_embeddings)
bi_embeddings = F.leaky_relu(self.Bi_Linear_list[i](bi_embeddings))
# here remove the bi_embeddings can remove the inner product of e_i and e_u;
ego_embeddings = sum_embeddings + bi_embeddings
#ego_embeddings = sum_embeddings
ego_embeddings = self.dropout_list[i](ego_embeddings)
norm_embeddings = F.normalize(ego_embeddings, p=2, dim=1)
all_embeddings += [norm_embeddings]
all_embeddings = torch.cat(all_embeddings, dim=1)
u_g_embeddings, i_g_embeddings = torch.split(all_embeddings, [self.n_users, self.n_items], dim=0)
return u_g_embeddings, i_g_embeddings















 4023
4023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









