






我这边采用快照的模式进行备份数据
备份源的es 版本要等于低于恢复elasticsearch集群的版本;
先看下:
Hadoop HDFS Repository Plugin:Hadoop HDFS Repository Plugin | Elasticsearch Plugins and Integrations [7.16] | Elastic
要注意自己版本哈 我的是7.16
ES集群快照存在版本兼容性问题:Snapshot and restore | Elasticsearch Guide [8.13] | Elastic
下载es-hdfs插件包:
https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-hdfs/repository-hdfs-7.16.0.zip
我就直接wget了
这里有一点要注意 插件版本必须与es版本一摸一样 差一点都不行 不然会出现报错. ——例如:你用 7.16.0插件就得 7.16.0。哪怕 7.16.3都不行 !!!
安装插件
/opt/dtstack/es/es/bin/elasticsearch-plugin install file:///opt/repository-hdfs-7.16.0.zip
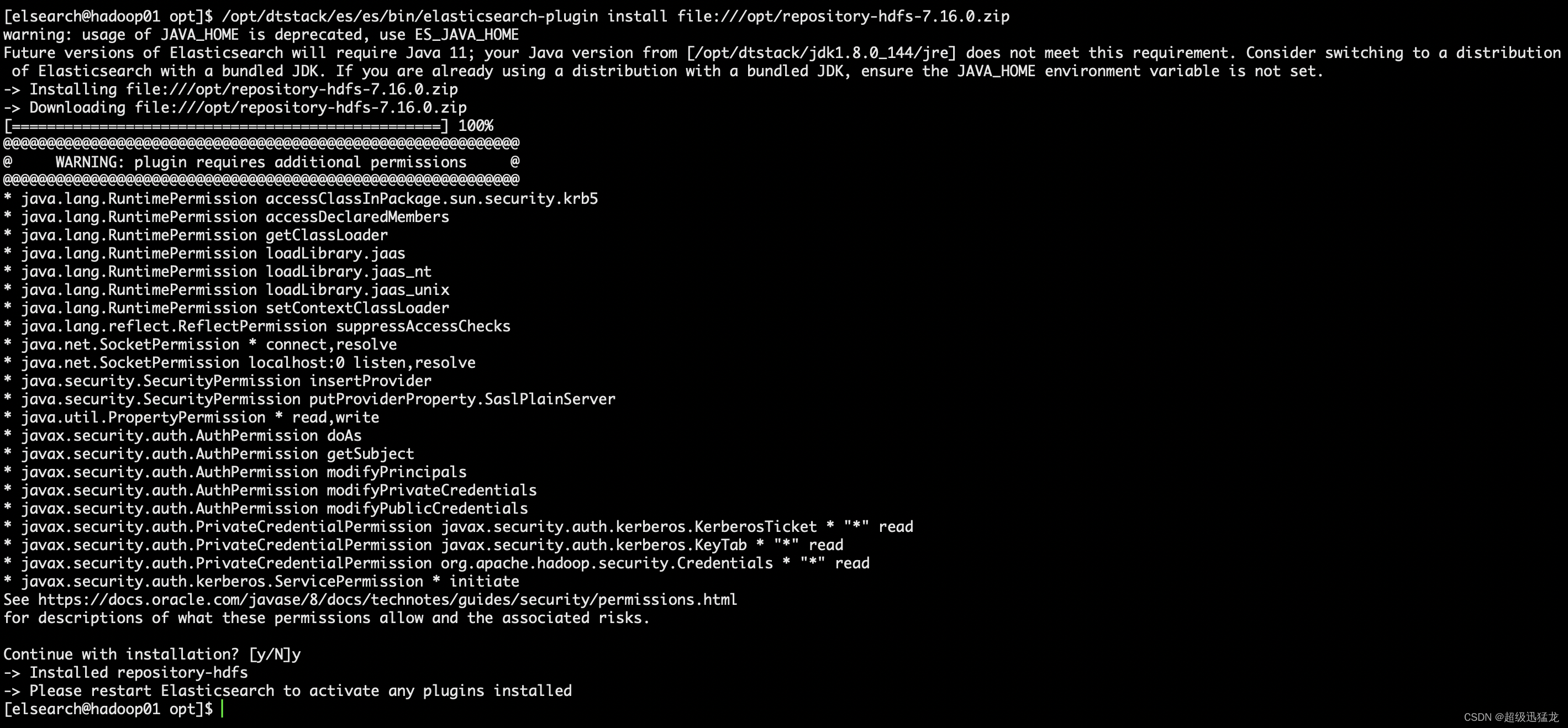
安装完成后 在es的plugins目录就会有这个插件
ll /opt/dtstack/es/es/plugins/

记得给其他es节点安装哈 不能只安装一台!---其他节点安装步骤省略 都一样。
都安装后就重启ES服务吧。
让我们查看已ES安装的插件信息
curl -XGET 'http://hadoop01:9200/_cat/plugins?v'

这样就对啦
然后我们就开始创建备份仓库了
首先在HDFS创建一个es的目录 并且要有elsearch权限哈
hdfs dfs -mkdir /es_backup
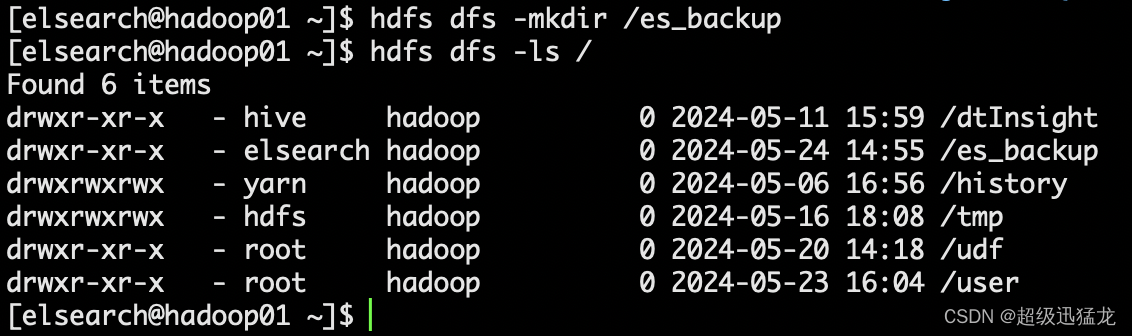
要注意hdfs权限哈
然后es创建快照仓库
curl -XPUT 'http://hadoop01:9200/_snapshot/my_backup' -H 'content-Type:application/json' -d '
{
"type": "hdfs",
"settings": {
"uri": "hdfs://hadoop02:9000/",
"path": "/es_backup",
"max_snapshot_bytes_per_sec": "50mb",
"max_restore_bytes_per_sec": "50mb"
}}'
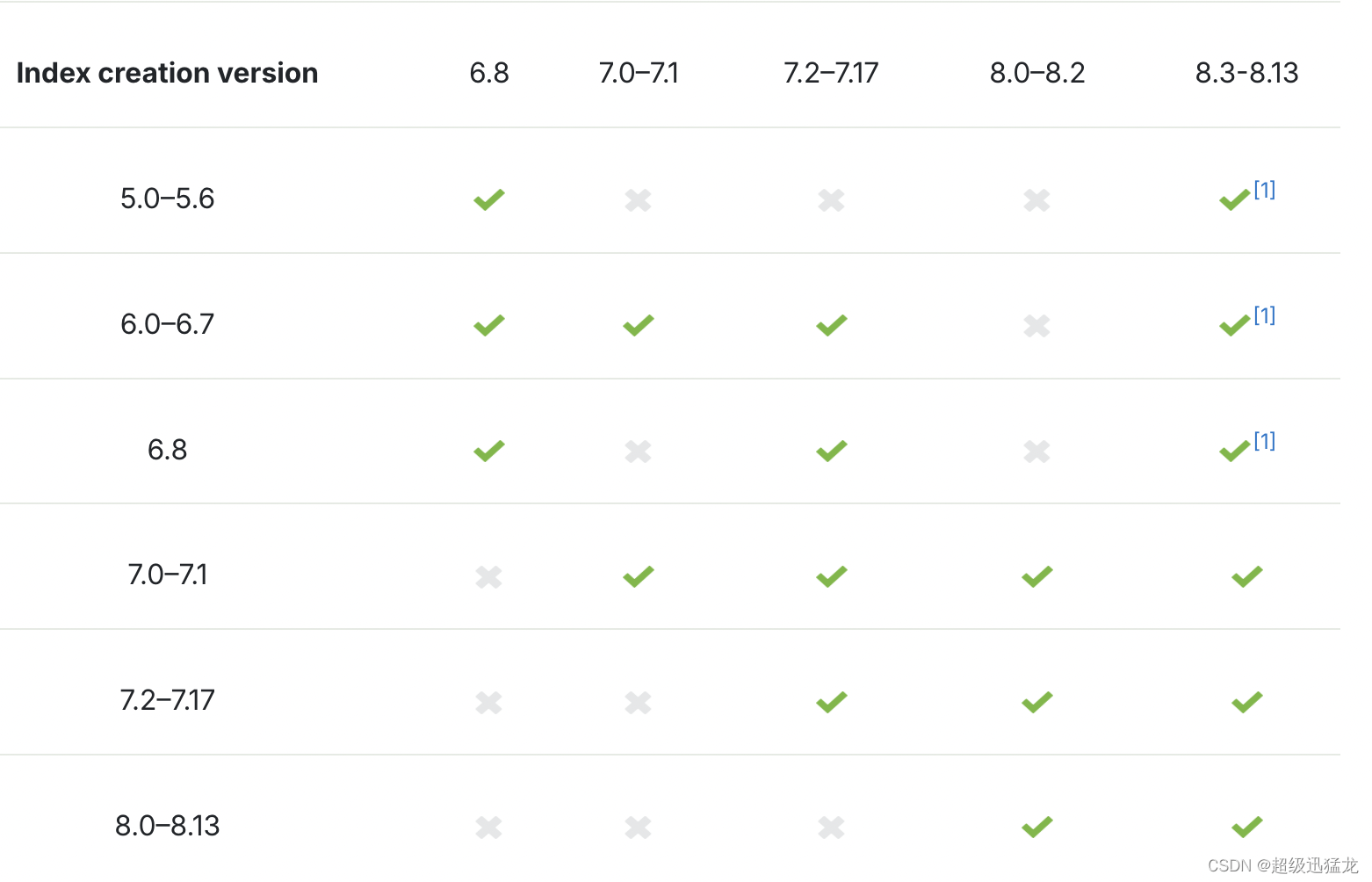
max_snapshot_bytes_per_sec:当快照数据进入仓库时,这个参数控制这个过程的限流情况。默认是每秒 50mb 。
max_restore_bytes_per_sec:当从仓库恢复数据时,这个参数控制什么时候恢复过程会被限流以保障你的网络不会被占满。默认是每秒 50mb
uri:写hdfs主的那个

查看 Elasticsearch 中所有可用的快照仓库列表
curl -XGET 'http://hadoop01:9200/_cat/repositories?v'

备份数据 我这边内网环境所以用curl啦
curl -XPUT "hadoop01:9200/_snapshot/my_backup/snapshot_2024-05-23?wait_for_completion=true"

查看备份情况
curl -XGET http://hadoop01:9200/_snapshot/my_backup/snapshot_2024-05-24

让我们查看下HDFS的数据
hdfs dfs -ls /es_backup
我们把这个数据get下来 用来去另一套环境恢复用
hdfs dfs -get /es_backup

传输到另一套环境
scp -r es_backup/ 172.16.121.150:/opt
然后让我们去新搭建的es环境上 把数据还原
首先在新环境查看下集群健康情况及索引信息
新环境集群健康情况
curl -X GET "http://localhost:9200/_cluster/health?pretty"

查看所有索引的列表
curl -XGET 'http://emr1:9200/_cat/indices?v'

然后安装插件 和上面步骤一样也是3台
我这边选择用小版本高的ES 同时测试下高版本es是否可以导入恢复数据
wget https://artifacts.elastic.co/downloads/elasticsearch-plugins/repository-hdfs/repository-hdfs-7.17.10.zip
安装
/opt/dtstack/es/es/bin/elasticsearch-plugin install file:///opt/repository-hdfs-7.17.10.zip
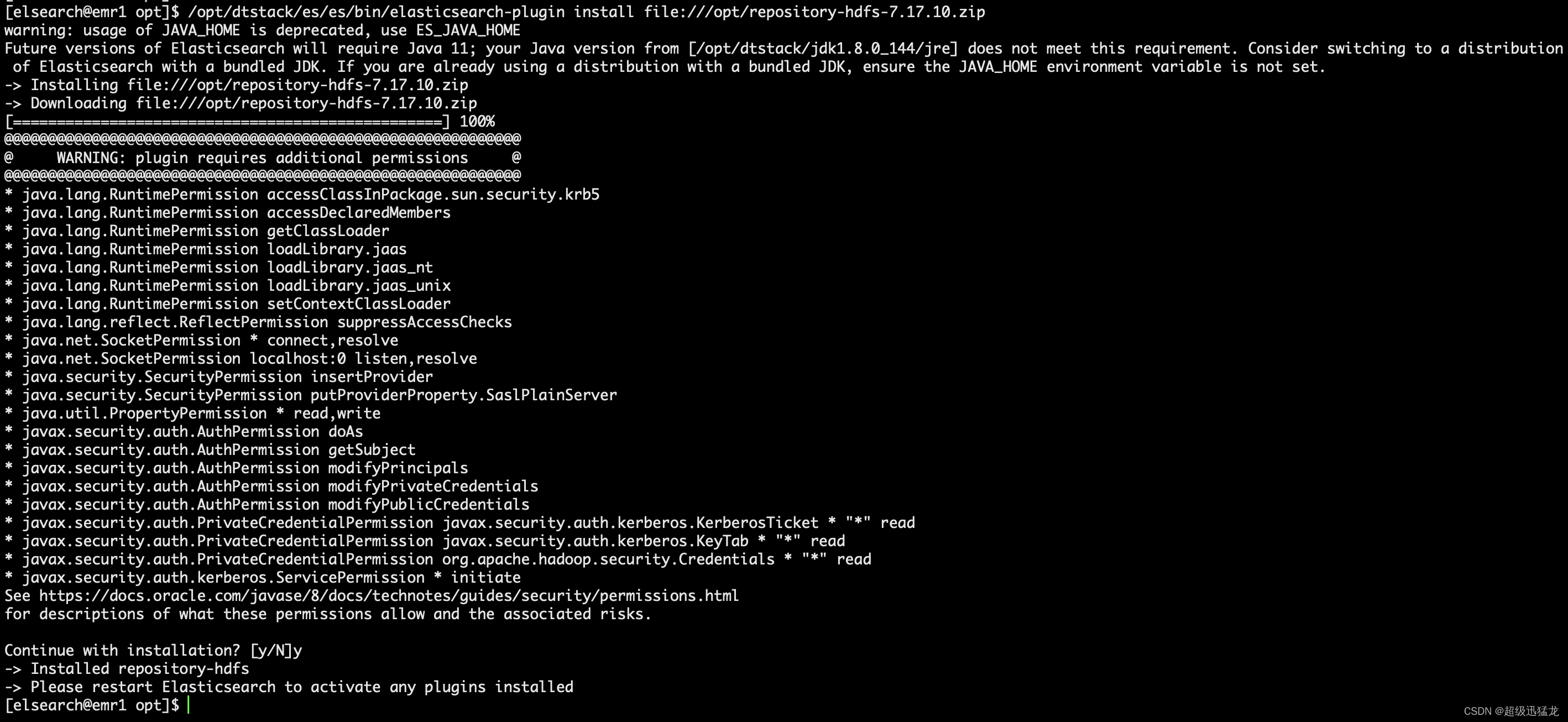
全部es节点搞完后重启es。
让我们查看已ES安装的插件信息
curl -XGET 'http://emr1:9200/_cat/plugins?v'
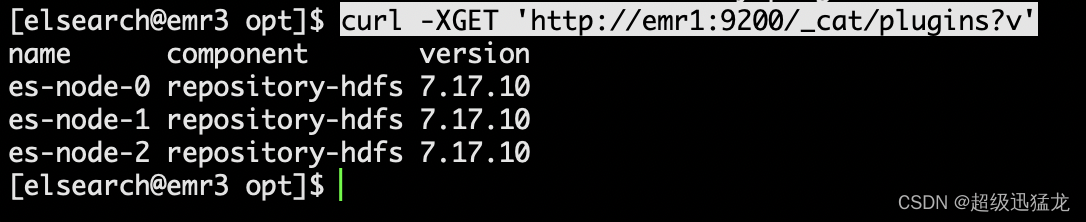
这样就可以了
然后我们把上一个快照传到HDFS上
hdfs dfs -put es_backup/ /
再创建一个创建 HDFS 的存储库快照(在跨集群还原索引快照的时候,我们需要在目标集群中创建与原始集群具体相同名称的存储库)
curl -XPUT 'http://emr1:9200/_snapshot/my_backup' -H 'content-Type:application/json' -d '
{
"type": "hdfs",
"settings": {
"uri": "hdfs://172.16.121.123:9000/",
"path": "/es_backup",
"max_snapshot_bytes_per_sec": "50mb",
"max_restore_bytes_per_sec": "50mb"
}}'

列出已注册的快照存储库并查看可用的快照
curl -XGET "http://emr1:9200/_snapshot/my_backup/_all?pretty"
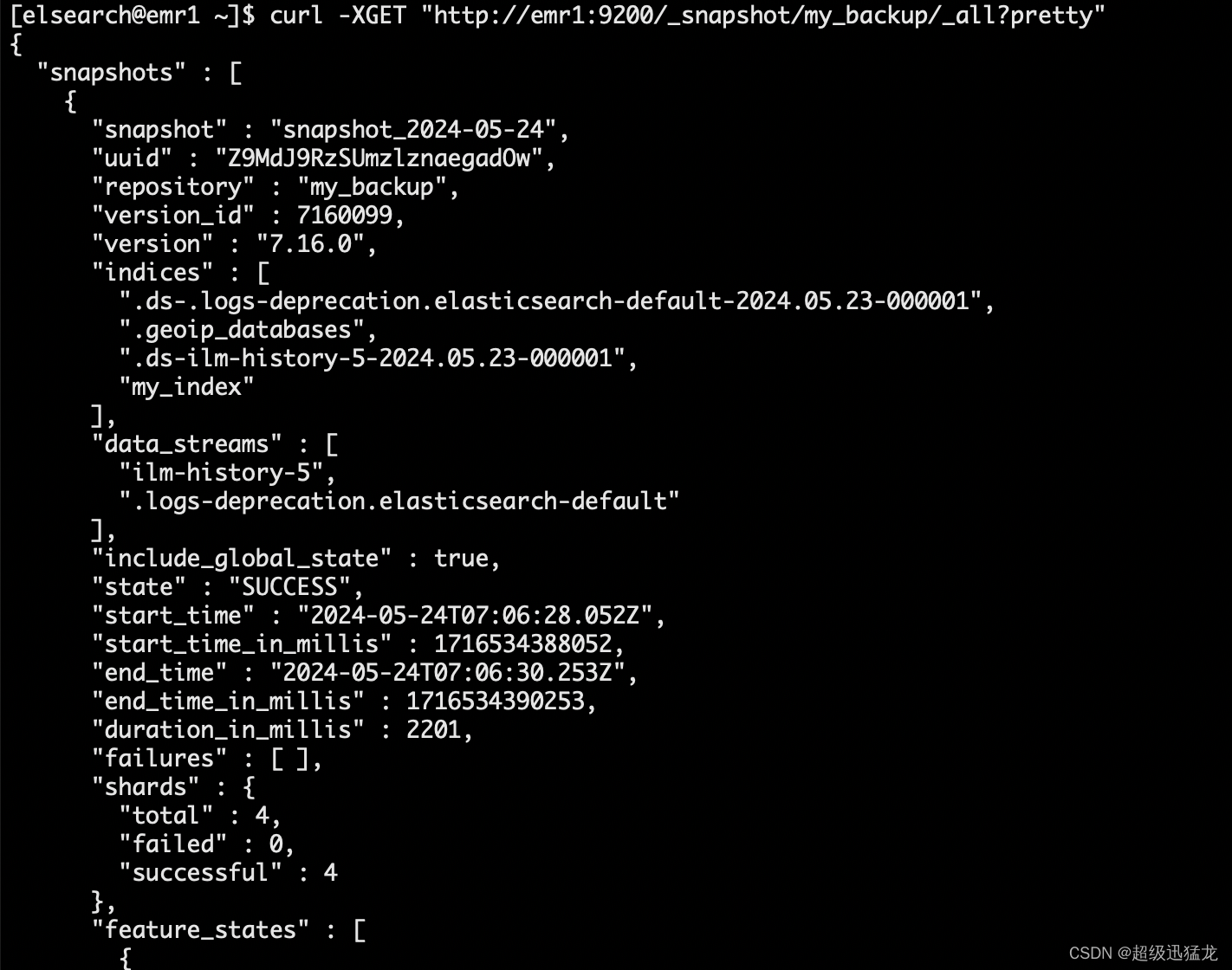
恢复所有索引
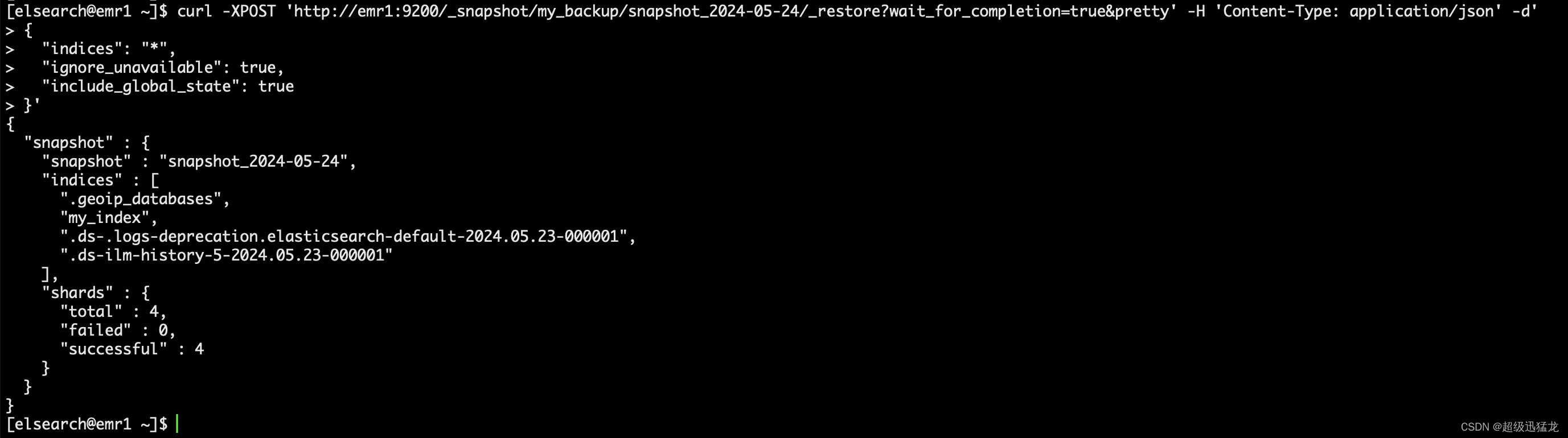
curl -XPOST 'http://emr1:9200/_snapshot/my_backup/snapshot_2024-05-24/_restore?wait_for_completion=true&pretty' -H 'Content-Type: application/json' -d'
{
"indices": "*",
"ignore_unavailable": true,
"include_global_state": true
}'
(1)ignore_unavailable,如果设置为true,则不存在的index会被忽略,不会进行备份。默认情况不设置
(2)include_global_state 设置为false,可以阻止集群把全局的state也作为snapshot一部分备份数据。
查询集群状态:
curl -X GET "http://localhost:9200/_cluster/health?pretty"
查看 Elasticsearch 中所有索引的列表
curl -XGET 'http://emr1:9200/_cat/indices?v'

查询数据
curl -X GET 'http://emr1:9200/my_index/_search?q=name:John'

搞定 数据没问题。















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









