%matplotlib inline
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
练习1:航班乘客变化分析
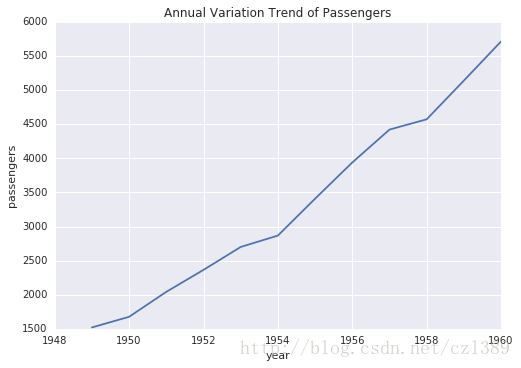
分析年度乘客总量变化情况(折线图)
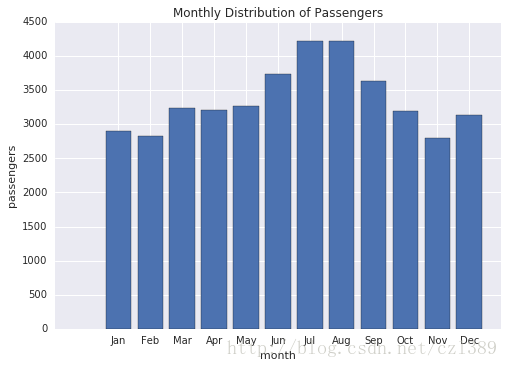
分析乘客在一年中各月份的分布(柱状图)
data = sns.load_dataset("flights")
data.head()
# 年份,月份,乘客数
year
month
passengers
0
1949
January
112
1
1949
February
118
2
1949
March
132
3
1949
April
129
4
1949
May
121
年度变化
# your code
year_group=data.groupby('year').sum()
fig,ax=plt.subplots()
ax.plot(year_group.index,year_group['passengers'])
ax.set_xlabel('year')
ax.set_ylabel('passengers')
ax.set_title('Annual Variation Trend of Passengers')
<matplotlib.text.Text at 0x7f89cacfaf50>
各月份之间的差异
data_1949=data[data['year']==1949]
month_group=data.groupby('month').sum()
month_group['month_num']=range(12)
fig1,ax1=plt.subplots()
ax1.bar(month_group['month_num'],month_group['passengers'],align='center')
ax1.set_xlabel('month')
ax1.set_ylabel('passengers')
ax1.set_xticks(range(12))
month_names=[str[:3] for str in list(month_group.index)]
ax1.set_xticklabels(month_names)
ax1.set_title('Monthly Distribution of Passengers')
<matplotlib.text.Text at 0x7f89cabdad10>
练习2:鸢尾花花型尺寸分析
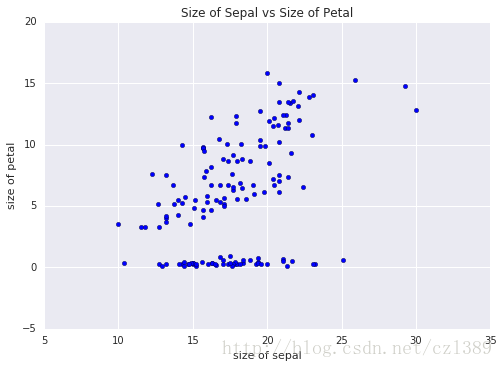
萼片(sepal)和花瓣(petal)的大小关系(散点图)
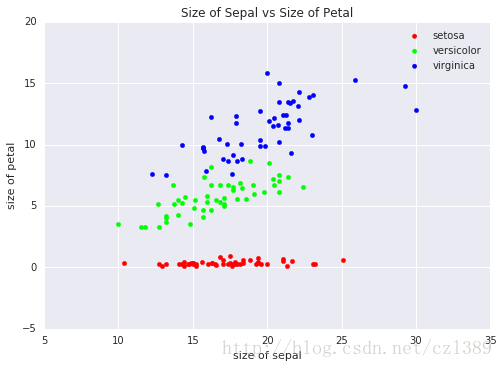
不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)
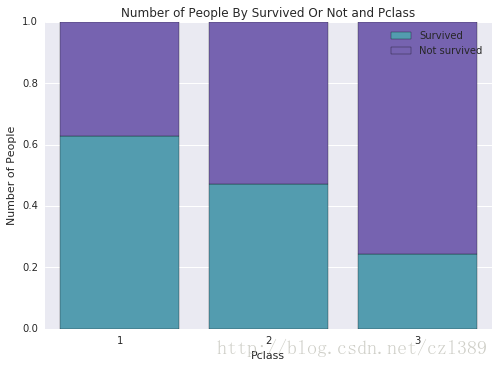
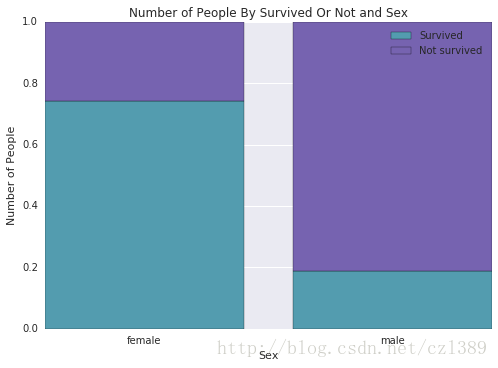
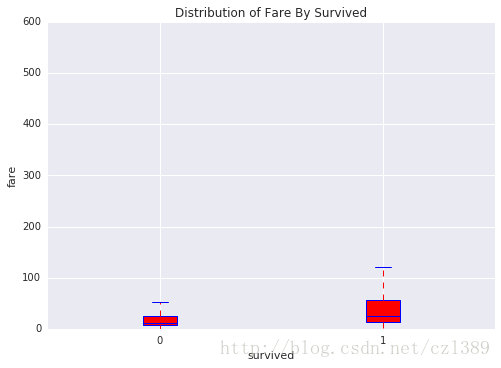
不同种类鸢尾花萼片和花瓣大小的分布情况(柱状图或者箱式图)
data = sns.load_dataset("iris")
data.head()
# 萼片长度,萼片宽度,花瓣长度,花瓣宽度,种类
sepal_length
sepal_width
petal_length
petal_width
species
0
5.1
3.5
1.4
0.2
setosa
1
4.9
3.0
1.4
0.2
setosa
2
4.7
3.2
1.3
0.2
setosa
3
4.6
3.1
1.5
0.2
setosa
4
5.0
3.6
1.4
0.2
setosa
# your code#尺寸为长乘以宽
data['sepal_size']=data['sepal_length']*data['sepal_width']
data['petal_size']=data['petal_length']*data['petal_width']
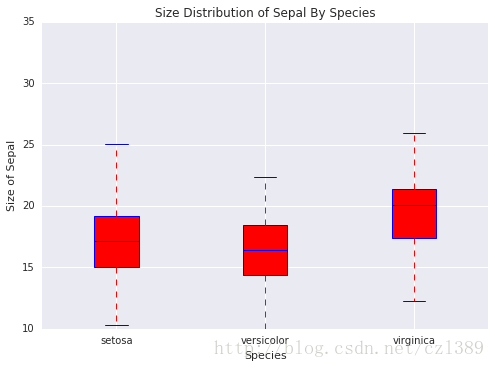
花瓣与萼片的关系
fig, ax2_1 = plt.subplots()
ax2_1.scatter(data['sepal_size'],data['petal_size'])
# 添加标题和坐标说明
ax2_1.set_title('Size of Sepal vs Size of Petal')
ax2_1.set_xlabel('size of sepal')
ax2_1.set_ylabel('size of petal')
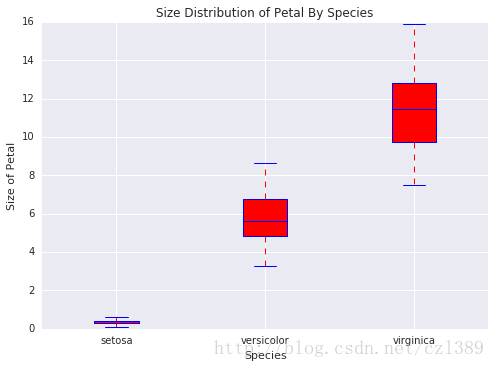
bp_data=[data1['petal_size'],data2['petal_size'],data3['petal_size']]
# 调用绘图函数
boxplot(x_data = species
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Species'
, y_label = 'Size of Petal'
, title = 'Size Distribution of Petal By Species')
练习3:餐厅小费情况分析
小费和总消费之间的关系(散点图)
男性顾客和女性顾客,谁更慷慨(分类箱式图)
抽烟与否是否会对小费金额产生影响(分类箱式图)
工作日和周末,什么时候顾客给的小费更慷慨(分类箱式图)
午饭和晚饭,哪一顿顾客更愿意给小费(分类箱式图)
就餐人数是否会对慷慨度产生影响(分类箱式图)
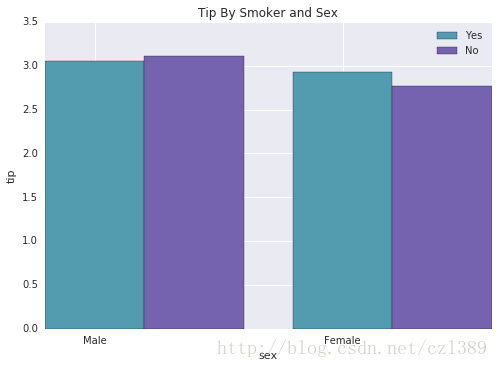
性别+抽烟的组合因素对慷慨度的影响(分组柱状图)
data = sns.load_dataset("tips")
data.head()
# 总消费,小费,性别,吸烟与否,就餐星期,就餐时间,就餐人数
total_bill
tip
sex
smoker
day
time
size
0
16.99
1.01
Female
No
Sun
Dinner
2
1
10.34
1.66
Male
No
Sun
Dinner
3
2
21.01
3.50
Male
No
Sun
Dinner
3
3
23.68
3.31
Male
No
Sun
Dinner
2
4
24.59
3.61
Female
No
Sun
Dinner
4
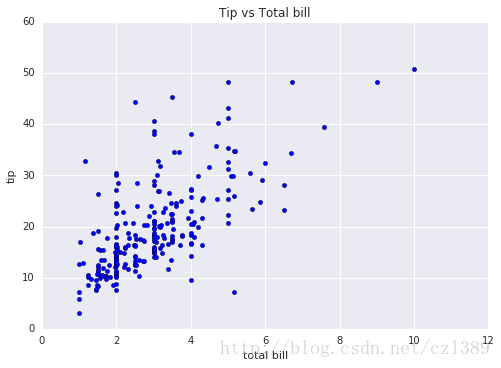
小费与总消费的关系
# your code
_, ax3_1 = plt.subplots()
ax3_1.scatter(data['tip'],data['total_bill'])
ax3_1.set_title('Tip vs Total bill')
ax3_1.set_xlabel('total bill')
ax3_1.set_ylabel('tip')
<matplotlib.text.Text at 0x7f89ca689150>
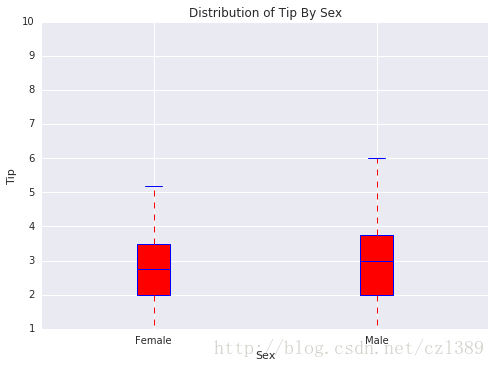
男性与女性
sex=data['sex'].unique()
bp_data=[data[data['sex']==sex[0]]['tip'],data[data['sex']==sex[1]]['tip']]
# 调用绘图函数
boxplot(x_data = sex
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Sex'
, y_label = 'Tip'
, title = 'Distribution of Tip By Sex')
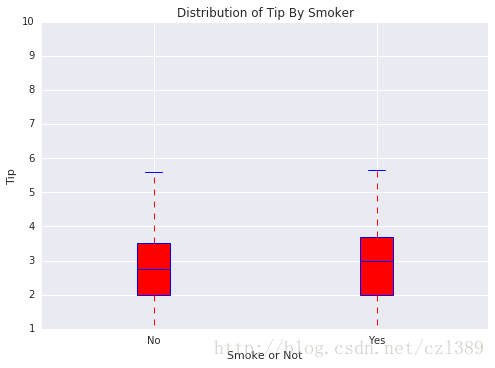
抽烟与否
smoker=data['smoker'].unique()
bp_data=[data[data['smoker']==smoker[0]]['tip'],data[data['smoker']==smoker[1]]['tip']]
# 调用绘图函数
boxplot(x_data = smoker
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Smoke or Not'
, y_label = 'Tip'
, title = 'Distribution of Tip By Smoker')
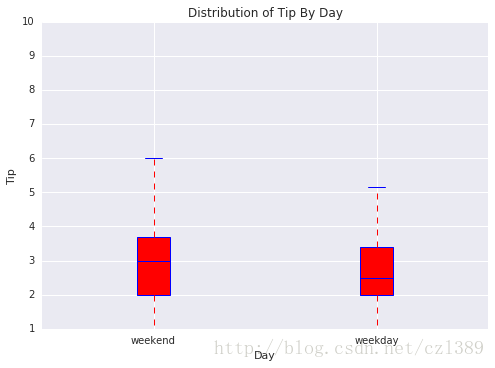
工作日与周末
day=data['day'].unique()
bp_data=[data[data['day'].isin(day[:2])]['tip'],data[data['day'].isin(day[2:4])]['tip']]
# 调用绘图函数
boxplot(x_data = ['weekend','weekday']
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Day'
, y_label = 'Tip'
, title = 'Distribution of Tip By Day')
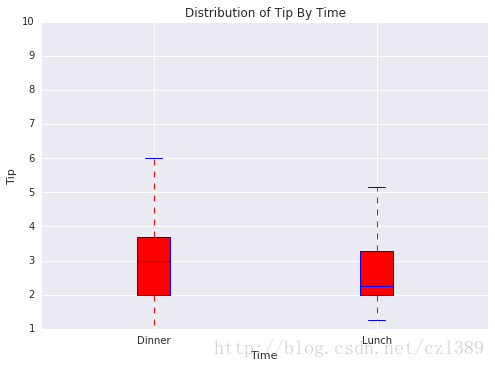
午餐与晚餐
time=data['time'].unique()
bp_data=[data[data['time']==time[0]]['tip'],data[data['time']==time[1]]['tip']]
# 调用绘图函数
boxplot(x_data = time
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Time'
, y_label = 'Tip'
, title = 'Distribution of Tip By Time')
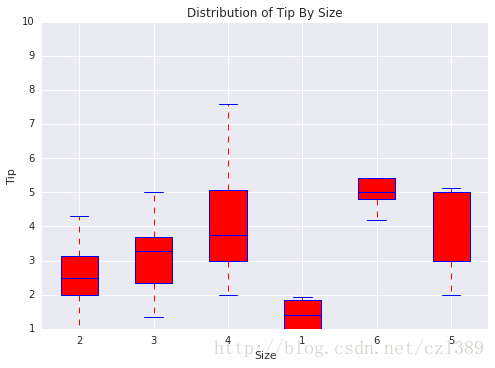
就餐人数
size=data['size'].unique()
bp_data=[]
for i in range(len(size)):
bp_data.append(data[data['size']==size[i]]['tip'])
# 调用绘图函数
boxplot(x_data = size
, y_data = bp_data
, base_color = 'b'
, median_color = 'r'
, x_label = 'Size'
, y_label = 'Tip'
, title = 'Distribution of Tip By Size')








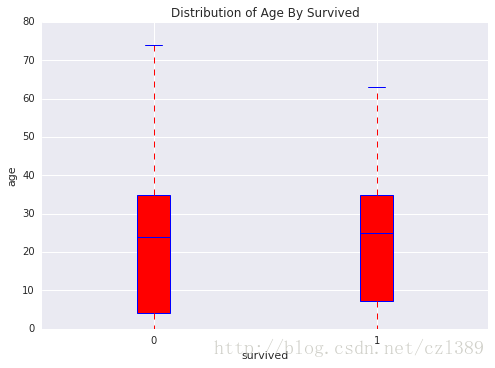
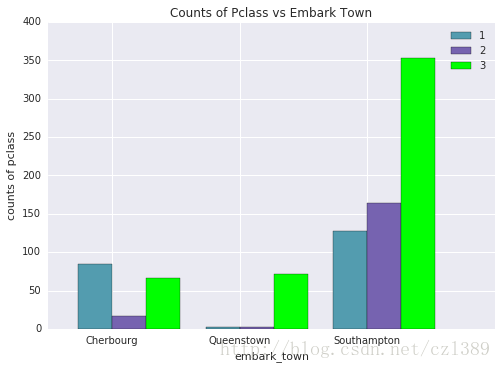
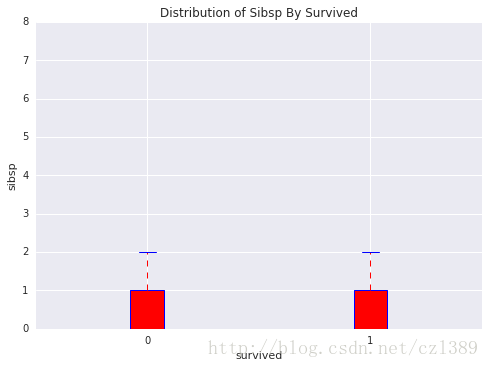
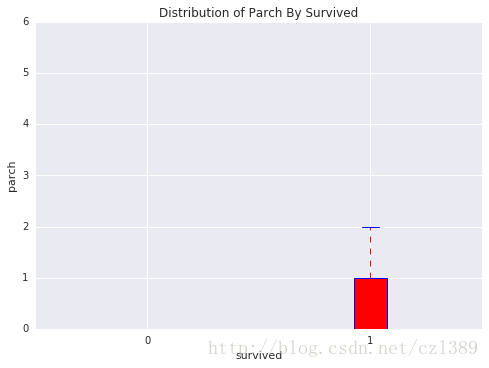

















 959
959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









