







源代码下载地址: http://pan.baidu.com/s/14H8D4
FPGA流水灯实验
花了几天通过流水灯实验把学习的verilogHDL的建模技巧总结了一下。写一份总结,给自己制定一套规范,方便以后查看和解决问题。
实现目标:
通过流水灯的实验实现了串行工作,流水线工作(时间并行),并行流水线工作(空间并行)。串行工作是CPU的工作方式,也就是一个时间只能做一件事。通过verilogHDL完全可以模仿这种工作方式,也就是说通过CPU实现的算法和驱动程序完全可以转换成对应的verilogHDL。并且结构化程序设计的思想(顺序,选择,循环)也可以通过verilogHDL实现。除了串行工作外,verilogHDL还有CPU很难实现的流水线(时间并行)和并行处理(空间并行)的优势。当然现在的多核CPU通过多线程编程也可以实现并行处理,但实现相对比较复杂。FPGA只要逻辑资源足够多,理论上可以实现无限并行处理。
这也就是我最喜欢FPGA的原因。只需要学习一种硬件描述语言,编写的可综合模块可以在不同厂家的FPAG,ASIC或CPLD上实现。可移植性强。可以不需要学习各种不同的单片机。和顺序处理最大的问题,驱动不同模块一次只能处理一个模块,停下另外模块,导致实时性不好。
流水灯实验通过以流水灯为原型简单的实现了串行和并行工作方式。通过4个LED灯表示完成一件事情的4个不同的步骤,LED闪烁一次表示完成一个步骤。
顺序工作:
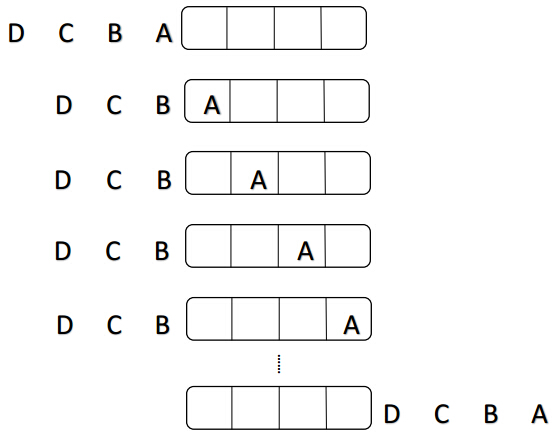
说明:顺序工作在T0时刻准备数据,在T1到T4时刻处理A数据,直到A处理完后才能开始处理B数据,一直到T16时刻处理完成4个数据,处理数据共用16个时刻(步骤数m*数据数n),时间复杂度为O(m*n)。
顺序时序图如下:
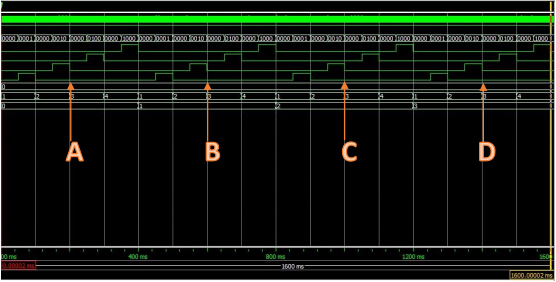
流水线工作:
说明:流水线工作在T0时刻准备数据,在T1到T4时刻为首次执行时间,接下来每个时钟完成一个数据。处理数据共用7个时刻。(步骤数m+(数据数n-1)),时间复杂度为O(n)。
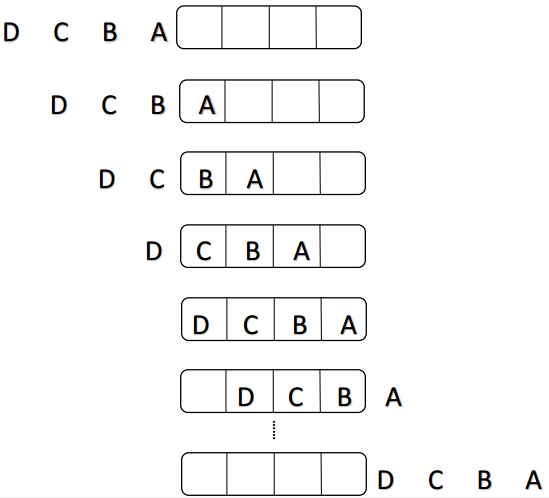
并行流水线工作:
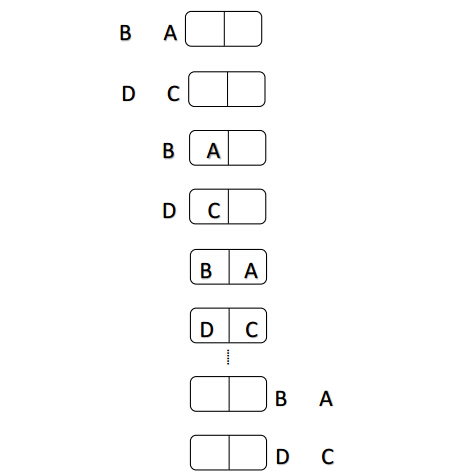
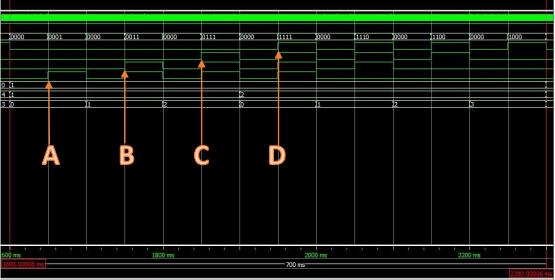
说明:并行流水线工作是多条流水线同时工作,在T0时刻准备数据,在T1到T2时刻为首次执行时间,接下来每个时钟处理一个数据。处理数据共用3个时刻。(步骤数m+(数据数n/流水线条数t-t) ),时间复杂度为O(n/t )。
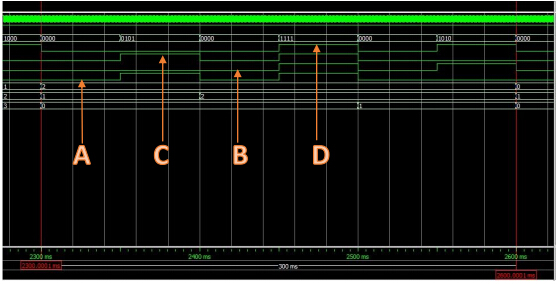
从上面三种工作方式的时间复杂度可以得到流水线处理数据的时间是串行方式的1/m,而并行流水线处理数据的时间则是单流水线的1/t。这是以空间换时间的方式,可以得到更高的效率,代价是消耗更多的空间。对于如今超大规模集成电路的产生,成本降低低,以空间换时间可以获得更高的性价比。而verilogHDL使得这种设计方式便的非常简单,并行流水处理数据也是通用处理器所无法代替的。
代码约定:
VerilogHDL是一个在不断完善的面向过程的语言,看了相关的语法书,发现没有找到一套合适的完整的语法结构。大多数VerilogHDL语法书只是讲了相关的用法,状态机的写法也时分繁琐,各种综合语言和验证语言混在一起,学起来就像盲人摸象,找不到方向。在编写代码的过程中,按照代码编写的原则找到了一套约定,来规范建模。发挥出verilogHDL更大的可能行的。
编写代码的历史是从开始的代码构成程序,到模块构成程序,再到如今的对象构成程序的过程。面向对象编程语言好坏,如今的任然是存在争议的。而我在开始制定约定之前就有想法把面向对象的编程方法引入对每个模块实现封装,然后通过模块内部的功能任务对外提供接口,以实现高度的抽象。达到像操作现实中的事物一样建模。但在尝试的过程中失败了。VerilogHDL并没有提供这类的语法支持,VerilogHDL中的任务和函数也不像高级语言一样。不过面向对象做为一种思考方式确实优秀和简单的。比如一个LED对象,它有打开LED和关闭LED两种操作。分析出有关特性后进行建模会把问题变得简单。而且VerilogHDL中模块也有类似于面向对象中类的特性。
编写代码的首要任务是管理复杂度,研究表明人能同时关注的智力模型为7+2,而嵌套关注通常不超过5层。编写一段代码的同时关注点很容易会超过9个。通过智力训练提供关注智力模型数的效果微乎其微。所以为了能编写任意大规模的代码,把同一时间关注的智力模型数降低的方法是很有效的。而且软件工程也是在制定相关的编程规范,对编程限制的基础上发展起来的。VerilogHDL虽然是硬件描述语言,但它已经摆脱了原始的电路图输入的方式,具有更高的抽象性,所以它应该可以应该软件开发中的类似的结论来提高开发效率。就像高级语言相对于01机器码编程一样。我觉得在verilogHDL在模仿顺序操作上更像汇编语言,因为它没有实现顺序,选择,循环结构的相关语句。结构化设计是编程上的一个里程碑,是已经被证明有效的技巧,所以把结构化设计引入verilogHDL进行建模可以提高建模效率。
结构化设计是建立在任何程序都可以用顺序,选择和迭代(常常也称作循环)三种结构实现的理论基础上的。结构化设计原则简单的来说就是,程序的流程按照自上而下方式设计,不用在流程中随意跳转。对于小规模的编程,在程序中任意跳转是非常灵活和快速的。但不符合人的逻辑思考方式。逻辑思考是自上而下的,在思考后面的时候很容易忘记前面。所以按照结构化程序设计,对硬件进行建模符合人的逻辑模式,可以直线式的从上到下进行设计。
应为高级语言编程和VerilogHDL建模虽然有很多类似的概念,但在实质上是不同的,VerilogHDL是对硬件进行设计的。为了区分概念在下面,把VerilogHDL的编写代码叫做建模。
变量名约定
在建模中我采用了类似于java的变量约定,应为java的变量名约定是与java语言一起完成的具有一定的完整性和普遍性。
reg和wire等普通变量的命名采用首字母小写,后面的每个字母开头大写,其它字母小写的形式。宏定义和常量定义名采用全部大写。任务、函数和模块名采用每个字母开头大写,其它字母小写的形式。
这里还涉及带4个特殊变量的命名,时钟(clk),复位(rst_n),模块调用开始(StartSig),模块反馈结束信号(DoneSig)。这四个变量是模块常用的输入输出变量。所以在建模中这四个变量名不再作其它变量命名。
前缀reg表示驱动某个输出变量的寄存器变量,is表示驱动某个输出变量的使能寄存器变量,_n表示输入输出变量的低电平有效。
在建模中发现模块可以大致分为四类,所以大致的约定四个后缀:_Interfac 接口模块,该模块中不含任何控制,只用来建立于外部元件的接口;_Dirve 驱动模块,该模块是包含控制功能的与外部模块进行连接的模块具有独立的驱动功能;_Control 控制模块,是用来协调各个模块之间控制功能的模块;其它没有后缀的模块为功能模块,每个模块能够完成独立的功能。
变量命名规则只是一个参考,并能当作约束。实际情况中变量名命名是很复杂的。要利用约定发挥管理复杂度的优势。当要更好的理由不使用约定时一定要小心使用,避免出错。
建模说明:
在建模的过程中运用了软件编程的几种技巧贯彻整个建模过程中,控制系统的复杂度。遵循抽象性,封装性,高内聚,松散耦合的建模技巧,并且采用了建立原型,和代码阅读的审查方法,及时查找错误,把修改错误成本降到最低。
首先从顶层以LED灯为对象建立抽象数据类型,LED灯能的操作只有简单的开和关。然后从底层以代码的角度出发建立LED灯的最小原型。我在最开始建立的最小原型是一个模块中包含一个定时器和一个LED翻转两部分时序逻辑的原型,实现了能够定时开关LED灯的功能。并且通过仿真验证了时序的正确性。最后通过代码阅读对代码的逻辑合理性进行检查。
相关实验数据表明这种编程方法是高效的。因为检查出错误的时间距产生错误的时间越晚,需要修改错误的成本也就越高,甚至可能导致无法修复错误,只能重建。所以即使检查和修改错误是提高效率和质量的有效方法,通常采用这种方法开发周期和一次完成率是很高的。
完成原型后的第二部步就是实现对模块的封装,按照一个模块一个功能的原则,把定时器时序逻辑,和LED翻转时序逻辑分开封装。期间复杂度并没有降低,只是转移到两个模块中,这样在一个时间所关注的代码就被有效的控制了。通过这种方法可以控制任意大的系统复杂度。使得实现超大系统成为可能。
下面以流水灯的代码为例来详细说明建模中的各种技巧,按照自顶到下的顺序:

这里是Led_Control模块和Led_Driver模块。Led_Driver实现了对控制LED开关的高度抽象和封装。使得控制每一个LED都只需要给它一个闪烁周期和开始信号,LED就会按照一个闪烁周期不停的闪烁,并且每闪烁一次完成给出了个完成信号。
这个模块是以模块数组的形式建立的。这里需要注意的是它建立了LED_SIZE个Led_Driver,其中的每个输入输出端口是(端口位数*LED_SIZE)个,外部信号输入输出时按照对于位数自动匹配。信号位不足的会自动重复,例如LED_SIZE个Led_Driver有LED_SIZE个时钟,但输入的时钟位只有1位,所以这1位时钟会自动扩展到LED_SIZE位。还有其中的Led_Driver有一个设定闪烁周期的信号有13位,LED_SIZE个Led_Driver就有LED_SIZE*13,这样输入信号的[13:0]匹配第一个Led_Driver的对应的13位闪烁周期,输入信号的[26:14]匹配第二个Led_Driver的对应的13位闪烁周期,依次类推。
使用模块数组是一个很有效的方法,避免了把Led_Driver重复的写多遍,割裂了它们的联系。使得修改其中一个时,要多个一起修改,导致修改漏掉,很难查找错误。通过模块数组也可以解决这个问题,还可以帮助封装和抽象模块。我在最开始的代码中为了实现4个流水灯的闪烁效果把重复模块写在一个模块中,并且4个LED翻转模块由同1个定时器控制翻转。在封装过程中发现,这个有4个LED驱动的模块没有实现高内聚性,也就是4个LED模块共享1个定时器。而模块数组表明了每个Led_Driver都是独立的,控制4个LED灯应该像控制1个LED灯一样。然后我就把1个LED模块和1个定时器封装成一个Led_Driver。通过模块数组实例化4次。因为每个Led_Driver模块都是独立的,所以降低了每个LED之间的耦合度,实现了松散耦合。使得可以很容易的把对4个LED的控制扩展到任意数量的控制。这是通过封装模块数组达到的高内聚和松散耦合的效果,同时也完成了对Led_Driver更高层次的操作,使得操作每个LED站在了抽象层,而不是是底层。
在底层你需要考虑定时器翻转多少次才能到这个时间,然后还要用这个时间打开或关闭LED,这样需要考虑的问题很复杂也容易出错。在抽象层你只需要给什么时候打开或关闭LED就够了,它就会自动的完成翻转工作。抽象性也是人脑处理信息的方式,例如自己的家你甚至说不清门是什么颜色的,门的把手是什么样式的。人脑对门的处理是抽象的,它是一个可以开和关的门。你只需要知道这个就可以进入家中,根本不需要记得门的颜色是什么。

在这个模块的头部有几个宏定义,用来集中管理需要设置的常量。可以实现代码的移植,在这里定义的是4个LED,可以很方便的变成8个,只需要修改一次,而不用在代码中到处修复神秘数字,减小出错的可能性。同时,使用宏定义破坏了模块之间的松散耦合,同一个宏定义可能在多个模块中引用,有时不注意会出现意想不到的问题,使得查找问题不能集中在一个模块中。相对而言,使用参数量(parameter)代替宏定义,定义一个模块中相同常量的神秘数字,达到集中修改的目的可以管理复杂度,使得模块松散耦合。这里使用宏定义的好处是把相关常量集中到开头,移植时只需要在同一个地方修改,避免了在代码中到处寻找参数量。所以这里的原则是优先使用参数量定义神秘数字,集中控制常量。然后再根据需要在抽象的过程中换用宏定义。不需要修改的常量就让它以参数量的形式定义。
Led_Control模块:
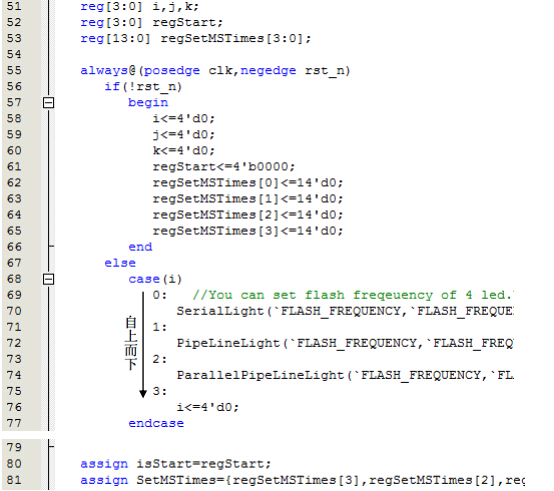
这是一个模块是的时序逻辑电路的核心部分,一般的模板也就是这个样子。从always开始看,一般时序逻辑都有时钟和复位信号,所以标准的always头就是这么写,时钟上升沿工作,复位下降沿异步复位。通过if复位条件把always块中用到所以寄存器全部复位。这些寄存器定义在对于always块的上面。原则在哪里使用,在哪里定义。尽量让定义和使用在一屏内显示,减小变量的生存周期和使用跨度,可以管理同一时间关注变量的个数。
这里用到了变量i,j,k来模仿结构化设计,一般的用i表示执行顺序,用j来计算循环次数,进行循环跳转。这样就可以模仿结构化设计的顺序、选择和循环结构。如果需要嵌套调用可以把i作为外层的执行顺序,j作为内层的执行顺序,用k来做循环计数。在建模中这3个变量不在作其它用途。一般来说嵌套超过3层就很难管理,这时应该把内层嵌套提前出来变成模块的调用。所以一般的这3个变量就已经足以应对很多情况。
这里的case语句中的功能类似于状态机通过输入的变化进行状态间的跳转。但这里的思想并不是传统的状态机。这样借用了《Verilog那些事》中的仿顺序建模思想。状态机所实现的算法与软件实现的算法本质是相同的,可以相互转换。但是传统的状态机需要先分析各种情况,然后画出状态转换图,才能映射成对应的代码。其中状态机中有很多冗余的空转部分,转换到另一个状态需要两个时钟。通过这种顺序建模思想可以把算法直接映射到代码,略去传统状态机中的冗余部分。使得步骤之间的转换只需要一时钟。这时设计和理解就更符合逻辑思维方式了。例如,case代码中的第一步调用串行流水灯任务,结束后返回。第二步,调用流水线流水灯任务,结束后返回。第三步,调用并行流水线流水灯任务,结束后返回。第四步,重复第一步。把程序设计中的结构化设计引入对硬件的建模,使得通过硬件实现逻辑算法变得和程序设计一样简单,并且硬件还可以很容易的是流水线和并行处理。充分发挥了硬件逻辑的优势,和消除了硬件实现算法的复杂过程。
最后的assign块一般是用来对组合逻辑建模,其中没有时序控制,输入立刻输出,但输出时间无法控制。在这样通常用来对模块的输出信号进行赋值。这里没有把输出信号直接声明成reg类型,而是通过中间变量的寄存器把always块中时序逻辑部分的量转出到assign块的输出wire类型。通过这种技巧把组合逻辑和时序逻辑分开考虑,管理复杂度。在生成的模块逻辑数量上是相同的。
assign块后面的代码是上面三个调用任务的具体实现过程。在封装成任务之前都是在always块中建立了原型,反复测试实现功能后通过任务封装起来的。在任务的接口处是需要通过修改传入的参数。任务里的j、k变量并没有通过传参数的方法进行封装,而是与所在模块共享,统一管理。因为通过传参数需要更多的输入输出变量,反而会增加复杂度。所以这里没有进行封装处理。
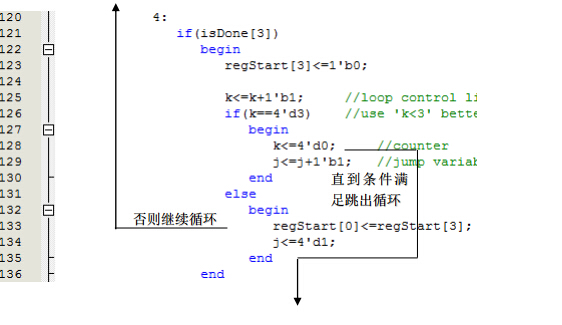
这是任务中对循环控制结构的模拟,类似于汇编语言中JMP的用法。汇编语言中没有像高级语言中循环结构,通过条件和跳转可以模拟实现结构化控制。这里用了类似的思想。这里用的是直到型循环(类似于do…while( )),也可以通过条件和转跳轻松实现当型循环(while( ))和计数循环(for( ))。类似的条件结构(if…else…)也可以模拟。这样就构成了结构化编程的三种基本结构。可以模拟任何程序。但这里的模拟还会出现类似于c语言中goto语句的问题。这么跳转方式在语法上是没有限制的,可以一会儿执行前面的代码,一会儿执行后面的代码,所以在使用的时候要按自上到下的结构化设计思想,避免逻辑混乱。原则跳转语句只向后跳转。这段代码中的循环结构并没有违反这样原则,因为循环结构是同一段代码重复多次,在同一个地方打圈后,继续向下执行,并没有跳到前面的部分。总体来说这段代码是符合结构化设计。已经证明任何程序都可以通过结构化设计实现,所以类似goto这样随意跳转的语句只会增加复杂度,导致逻辑混乱。
在这里提到了循环,在verilogHDL中也有类似于C语言的while和for语句,但这些语句和高级语言中的循环语句是不同的。高级语言是顺序执行的,所以循环语句重复的代码可以被执行多遍。而verliogHDL中的while和for重复的语句会生成重复的实例原件,并不能达到多次执行的效果。这里需要区分理解,只是看起来一样,实质是不同的。

这两个任务中实现的是并行处理的流水线和多条流水线结构,verilogHDL能够很容易的实现流水线处理,提高数据处理速度。但要建立流水线有一定的限制,流水线各个步骤必须是同步的才能发挥出最到的。如果流水线不同步,就会造成第二步的数据还没处理完,第一步的数据就来到,冲掉第二步的数据。这里可以用到互锁机制和同步FIFO来解决不同步的问题。但这样就不能发挥流水线最大的处理效率,不过在并行性上相对串行处理也要快不少。这是以空间换取时间的方式。对于超大规模集成电路发展,相对来说并不会对价格有太大的影响,反而提高了性能。
在这里可以得到一个结论,凡是类似于LED这种顺序处理时,每步都相同的操作可以转换成对应的流水线,提高处理数据的能力。类似的例子有乘法器和除法器要用到连续移位操作的,都可以转换成流水线设计。使得不同步骤可以同时工作。
这个LED_Control模块已经很长了,虽然中间应用的任务封装,大大降低以复杂度,但也是足够复杂的了。这三个任务全部写在一个always块中,复杂度将是难以想象的,稍有不慎就会出错,并且同时在几百行代码中查找错误的时间代价也是很高了。如果这个功能模块还要增加功能,就要把这些功能封装到不同的功能调用模块,然后再用一个控制模块对它们进行调用。分而治之的原则是一个功能一个模块,类似的功能用一个功能集中管理调用,不同的功能模块划分成部分的部分。通过这种封装,高内聚,松散耦合的思想来实现高度抽象,使得建立超大规模系统成为可能。
Led_Control模块:

LED_Control模块是整个LED流水灯的核心,但却相对来说简单得多。因为它已经实现了高度抽象,仅仅只需要一个设定时间和开始信号就可以工作。Led_Driver_Control用来协调外部的时间到内部闪烁周期的转换,和内部闪烁一次结束信号的输出。就像在内部和外部之间建立了一道栅栏,完成内外之间的映射。对外把内部的信息隐藏起来,使得外部只看得到接口,看不到内部是怎么工作。这样做的好处就是当外部需要挂接到其他控制器上是只需要修改这道栅栏就可以了,内部不用做很大的调整。如果没有这层栅栏,内部和外部混在一起,外部的变化会可能会导致要重建整个内部来适应变化。这种思想类似于数据库的三级模式与两级映射和防火墙的原理。建立这层栅栏来实现封装是很有价值的。
接下来的是定时器模块和LED接口模块,都是很简单的always实现的没有用到步骤的概念。
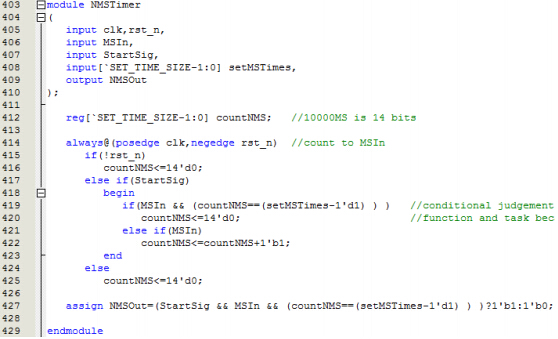
定时器是时序逻辑电路的基础,产生精确的定时是上层能够正常工作的保证。这是对另一个定时器计数的定时器。这里需要注意的是开始信号的位置以及对于的else条件中表达式。if中的else条件和case语句中的default条件是容易出错的,所以要认真考虑。以及对什么信号计数(MSIn)?什么时候清零计数?这里清零的条件是当(setMSTimes-1)个MSIn到来时,清零计数器。这里容易出错的是数的个数,从0到setMSTimes,数MSIn共setMSTimes+1次。这里容易出现偏差1(off by one)的错误。可以通过数一个小的数字来解决,例如数5次,要从0数到4,所以这里数setMSTimes次应该从0数到setMSTimes-1。
这里还有一个问题就是长长的布尔表达式(MSIn&& (countNMS==(setMSTimes-1'd1) )),
这里涉及到了一个表达式中需要完成两次决策和一次减法。这个长度还是可以接受的。如果这里的布尔表达式有七八个与或非的逻辑判断和加减运算。那么这个布尔表达式放在这里,并且在下面的assign块中有部分相同,很显然这种情况复杂度已经超过可以接受的能力。这里就需要用到用一个线网型变量带替代表达式,转移复杂度的方法,来控制复杂度。
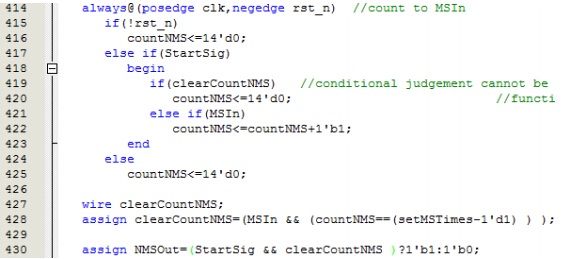
就像上图中把相同的部分提取出来,用一个变量名代替,虽然增加了几行代码,但实现的逻辑电路是相同的。同时提高了代码的可读性。这样逻辑就更清晰了。这时要考虑清零计数器的条件就只需要在对应的assign块中调整,不用考虑其它两个部分了。这里我开始使用的是编程中通过具名函数封装布尔表达式的,结果生成了完全不同的电路,无法实现想要的效果。这里的原因是verilogHDL的函数不能返回wire型变量,不能实现想要的组合逻辑。编程语言中的函数和verilogHDL中的函数调用是有区别的。在verilogDHL中使用函数时要特别注意。最好是不使用函数,避免出错。通过任务和assign块来代替编程语言中对应的函数功能。
最后需要说明的一点是在建模过程中,每一个模块一个文件,这样可以把代码的行数限制在一定数量以内。限制同时一时间关注的复杂度。在调试完成后再把所有的模块集中在一个文件中,便于打包和发布。
总结:
通过基本的流水灯实验实现了顺序操作,流水线操作(时间并行),多条流水线操作(空间并行)。并且验证了通过verilogHDL实现结构化建模的可行性,能够直接的把算法转换成对应的模块,省去了传统状态机的繁琐设计过程。软件工程中的编程的首要任务管理复杂度的思想同样适合硬件建模。并且可以把软件控制复杂度的方法引入硬件建模中。使得硬件建模的效率得到提高。
这篇文章中有很多都是自己的想法,有错误的地方还希望能够指出。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









