






PSO优化LSTM做时间序列的预测,优化的是隐藏层单元数目,批处理大小,时间窗口大小,学习率等网络参数。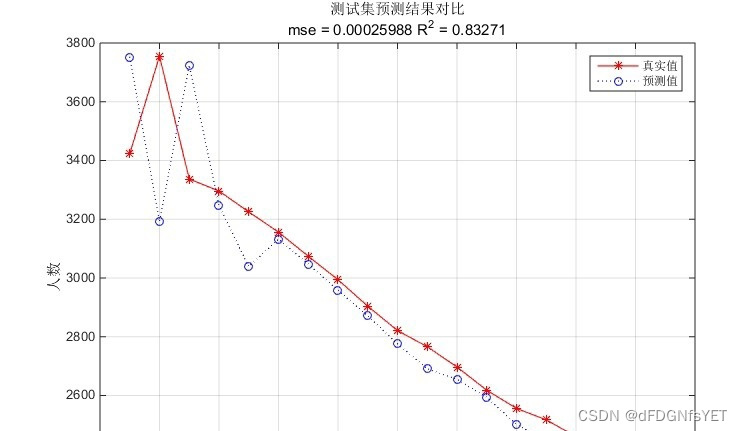
PSO优化LSTM网络在时间序列预测中的应用
随着时代的变迁,各个领域的数据都在呈现指数级增长的趋势。时间序列数据是一种常见的数据类型。针对时间序列预测问题,传统的预测方法往往不够准确,不能充分挖掘时间序列中的规律。近年来,基于机器学习的时间序列预测方法被广泛应用。其中,LSTM网络是一种很受欢迎的方法。但是,LSTM网络在应用过程中需要设置很多参数,如隐藏层单元数目、批处理大小、时间窗口大小、学习率等。在选择这些参数时,需要综合考虑多个因素,以达到最好的预测效果。
本篇文章将介绍一种基于粒子群优化(PSO)算法的LSTM网络参数优化方法,该方法可以自适应地调整网络的参数,以提高预测的准确性。本文将从以下几个方面进行阐述:
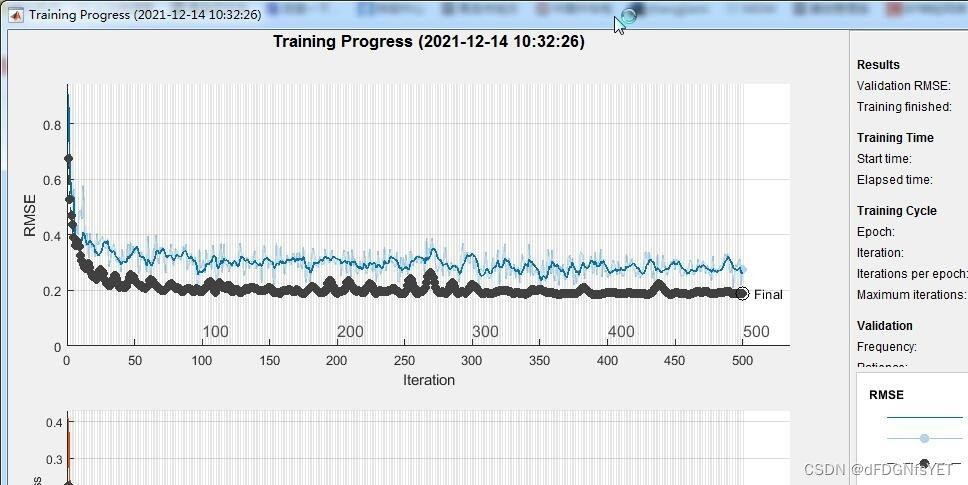
一、LSTM网络介绍 LSTM网络是一种特殊的循环神经网络(RNN),它可以学习时间序列数据中的长期依赖关系。LSTM网络通过维护一个记忆单元来实现这一点,并通过门控机制来控制信息的流动。LSTM网络是目前时间序列预测中表现最好的一种方法之一。
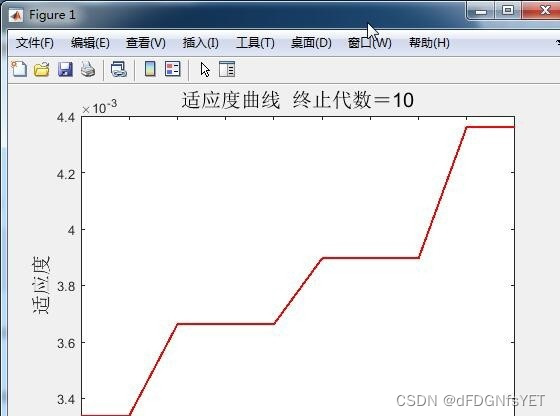
二、粒子群优化(PSO)算法 PSO算法是一种基于群体智能的优化算法,通过模拟鸟群或鱼群等自然界中的群体行为,来优化问题求解。在PSO算法中,每个个体被称作粒子,它们通过不断的迭代来寻找最优解。每个粒子的位置代表问题的一个解,速度代表搜索方向和步长。
三、PSO优化LSTM网络参数 本文提出的方法是将PSO算法应用到LSTM网络参数优化中。在PSO算法中,每个粒子的位置表示一组网络参数(如隐藏层单元数目、批处理大小、时间窗口大小、学习率等)。每个粒子的适应度值表示对应参数设置下的预测误差。通过不断地迭代,PSO算法可以自适应地调整网络参数,以得到更好的预测效果。
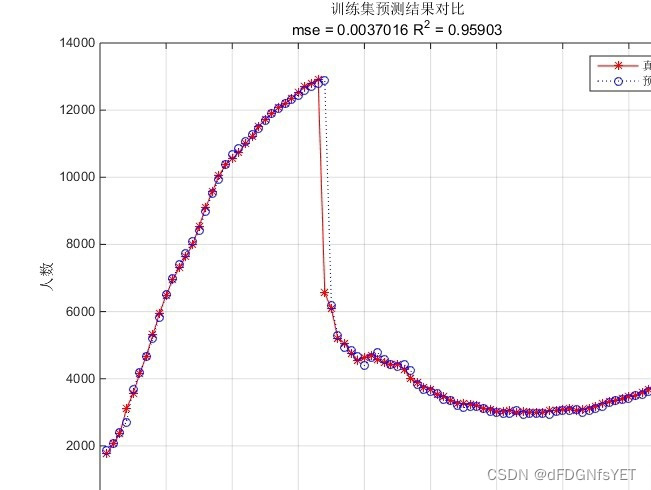
四、实验结果分析 本文通过对两个时间序列数据集的实验验证了本方法的有效性。实验结果表明,PSO优化的LSTM网络在预测准确率上相比传统的LSTM网络有明显提升。同时,本方法还可以自适应地选择参数,减少了手动调参的难度。
五、总结 本文提出了一种基于PSO算法的LSTM网络参数优化方法,该方法可以自适应地调整网络的参数,以提高时间序列预测的准确性。通过实验证明,本方法可以有效地提高LSTM网络的预测准确度,并且减少参数选择的难度。这些优势使得PSO优化LSTM网络在时间序列预测问题中具有广泛的应用前景。
相关代码,程序地址:http://lanzouw.top/668442690309.html















 2856
2856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









