







整理 | 屠敏
出品 | CSDN(ID:CSDNnews)
抄袭的风刮到了大模型圈,这一次抄袭方直指斯坦福 AI 团队,而被抄袭方则是国内大模型公司面壁智能。
事情要从 5 天前说起,网罗前沿技术最新动态的 HN 上出现一条有关大模型成果的最新消息,一个名为 Llama 3-V 的模型横空出世,它是比 GPT4-V 小 100 倍的 SOTA(State-of-the-Art,即技术水平最先进的模型),而且只需要 500 美元就能训练出来。

观其背后团队,更是有名校斯坦福大学的加持,项目作者之一的 Aksh Garg 是斯坦福大学、Point72 和 Jump 的机器学习研究员,曾就职于特斯拉、SpaceX、DE Shaw。
在介绍 Llama 3-V 的文章中,Aksh Garg 分享了该项目的由来。他表示,“Llama3 风靡全球,几乎在所有基准测试中都优于 GPT3.5,在多项测试中优于 GPT4。随后,GPT4o 横空出世,以其多模式的精妙性能夺回了王座。今天,我们将发布一款产品来改变这一局面:Llama3-V ,这是有史以来第一个基于 Llama3 构建的多模态模型。更为值得注意的是,我们的训练费用不到 500 美元。”
至于 Llama 3-V 性能如何,Aksh Garg 放上了与 Llava、GPT-4o、Gemini 1.5 Pro 等当前 SOTA 和最受欢迎的多模态理解模型对比图,其中相比 Llava,Llama 3-V 的性能提升了 10-20%。此外,除 MMMU 外,Llama 3-V 在所有指标上的表现都非常接近其 100 倍规模的封闭源模型。
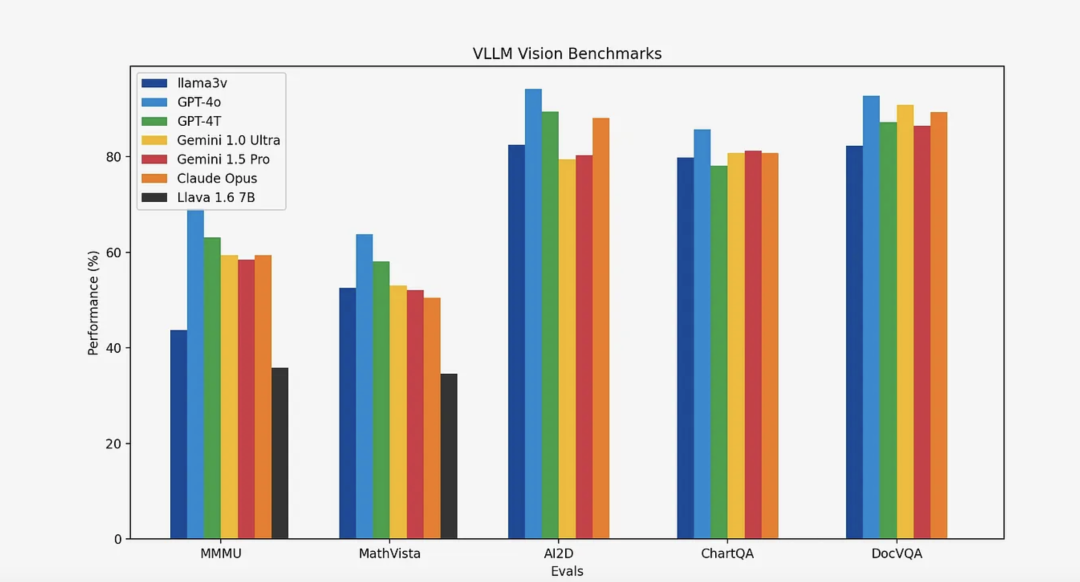
用更低的成本训练出更好的模型,这也是业界诸多大模型公司一直在致力于做的事情。随着 Aksh Garg 的官宣,众多大模型爱好者蜂拥而至,探索这个最新开源的大模型的风采。
万万没想到,在体验与深挖技术实现的过程中,意外出现了。一位名为 pzx163 用户跑到了中国面壁智能 GitHub 项目 issue 地址下(https://github.com/OpenBMB/MiniCPM-V/issues/196),对着 MiniCPM-Llama3-V 2.5 项目作者举报:你们被“偷家”了。
pzx163 为了节约面壁智能的调查时间,还顺便直接甩出自己发现的三大事实。

事实 1:Llama3-V 项目使用与 MiniCPM-Llama 3-V 2.5 项目几乎完全相同的模型结构和代码
先从时间线来看,面壁智能在 5 月 21 日刚开源了端侧多模态模型 MiniCPM-Llama3-V 2.5(https://github.com/OpenBMB/MiniCPM-V),参数量为 8B。根据基准测试显示,多模态综合性能超越 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等商用闭源模型,OCR 能力及指令跟随能力进一步提升,能够精准识别难图长图长文本,并支持超过 30 种语言的多模态交互。
而 Llama 3-V 是在 5 天前,即 5 月 29 日才发布的。
二者都在 GitHub 上开源了。
pzx163 在分析代码时发现,Llama3-V 具有与 MiniCPM-Llama3-V 2.5 完全相同的模型结构和配置文件,只有变量名称不同。
从下图来看(左:MiniCPM-Llama3-V 2.5,右:Llama3-V)

Llama3-V 的代码看起来像是 MiniCPM-Llama3-V 2.5 的代码,但进行了一些重新格式化和变量重命名,包括但不限于图像切片、分词器、重采样器和数据加载。只举几个例子:
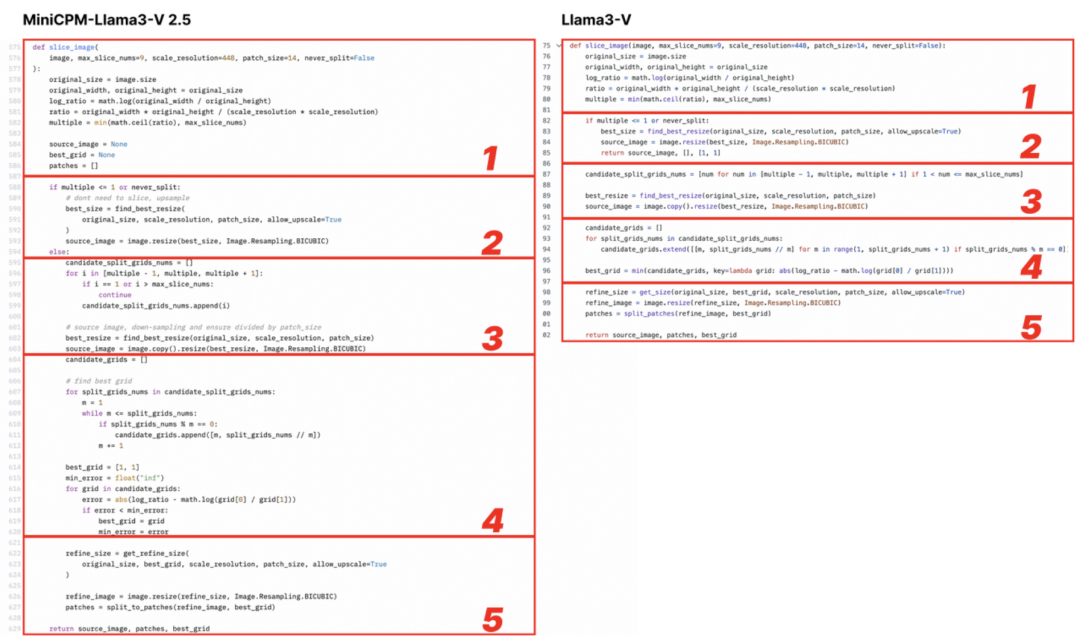
Llama3-V 的作者引用了 LLaVA-UHD 的架构,并在 ViT 和 LLM 的选择上列出了一些差异。但作者没有提到的是,它们的具体实现其实与与 MiniCPM-Llama3-V 2.5 完全相同,而后者在很多方面都与 LLaVA-UHD 不同,比如空间模式。
Llama3-V 还具有与 MiniCPM-Llama3-V 2.5 相同的分词器,包括 MiniCPM-Llama3-V 2.5 新定义的特殊标记。

实锤之下,网友 pzx163 再放“猛料”,称:「最初,Llama3-V 作者上传的代码直接导入 MiniCPM-V 的代码,后来将名字改为 Llama3-V。https://huggingface.co/mustafaaliadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6」。
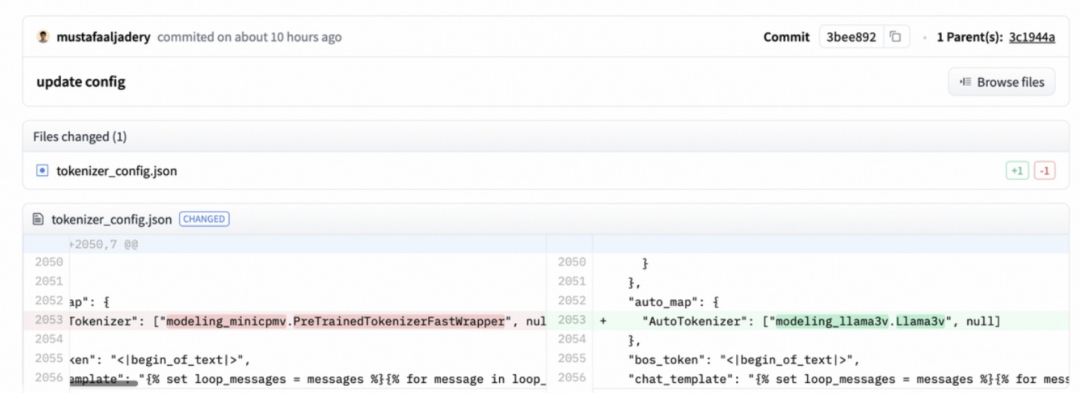

实证 2:Llama3-V 的作者撒谎
在发现这些细节问题之后,网友 pzx163 起初并没有直接找到面壁智能团队反馈,而是先去 Llama3-V GitHub 项目 Issue 中联系了 Llama3-V 的作者们,想要让他们先出面解释一下。
没想到在看到 pzx163 的质疑时,Llama3-V 的作者们先是做了回复:
这是非常错误的。我们在此 repo 中使用了 MiniCPi-llama3 上的配置,因为要使用 huggingface Transformer 运行模型,必须有特定的配置!现在,要在 huggingface Transformer 上运行模型,还存在一些实现问题。
我测试过 MiniCPM,他们的配置很有效,所以我们使用了相同的配置。此外,我强调了架构的相似性,但 MiniCPM 的架构来自 Idefics。SigLiP 来自 ldefics,关于投影的想法也是如此。我们从 ldefics 的论文中找到了这些内容。LLava UHD 来自他们的实验室,我已经强调了这一点。此外,我还强调了更多关于它的架构是如何相同的,但架构是来自联合研究,你怎么能说它是 MiniCPM。请阅读 MiniCPM 的代码,从字面上看,它的视觉代码来自 Idefics。
我们还将在本周末发布训练和数据代码以及固定推理:)
随即 pzx163 又发现 Llama3-V 团队直接上删除了 Huggingface 上 Llama3-V 的 repo。
如果不是“心虚”,或许不会直接走到删库这一步。没想到的是,Llama3-V 团队作者对于自己删库的行为,解释称:
我把它设为私有,以修复推理问题。推理仍不起作用的原因是,你必须有特定的配置才能让它与 Huggingface Transformer 一起工作。我尝试使用的 MiniCPM-LLama3 配置与模型不兼容!人们在下载模型后发现它无法工作。这就是为什么我把它设为私有,这样人们在我解决问题时就不会下载了。
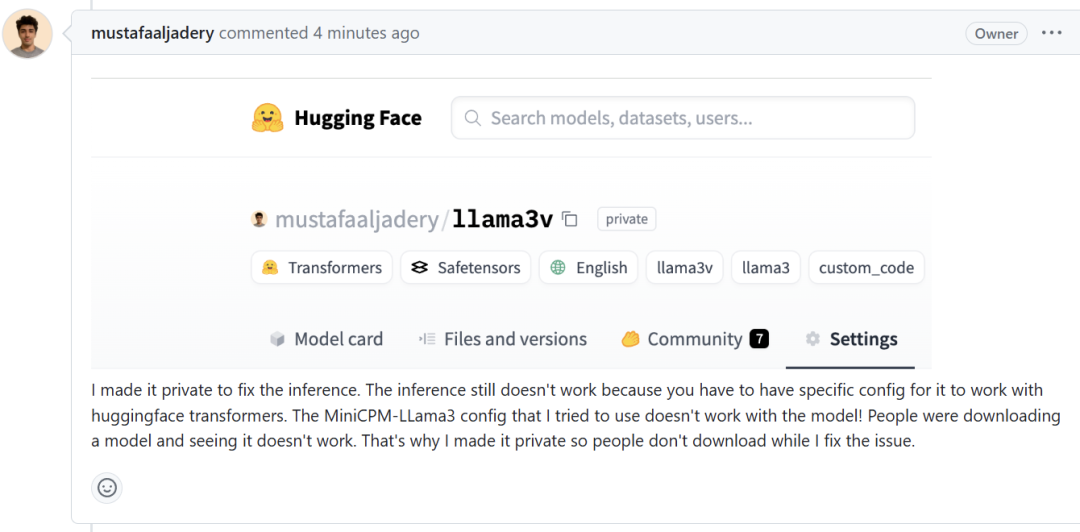
这些话也让 pzx163 找到了漏洞,这位网友再次质问 Llama3-V 作者:
你说你只是使用 Mini CPM-Lama3-V2.5 的tokenizer。但也声称在Mini CPM-Lama3-V2.5 发布之前就已经开始了这项工作。我很好奇你是如何在 MinicPM-Llama3-V2.5 项目发布之前就使用上 MinicPM-Llama3-V2.5 tokenizer 的?
Llama3-V 作者自己貌似也有些“糊涂”了,连忙矢口否认,称自己用的是面壁上一代 MiniCPM-V-2 项目的 tokenizer(https://huggingface.co/openbmb/MinicPM-V-2/blob/main/tokenizer.json),还附上了链接。
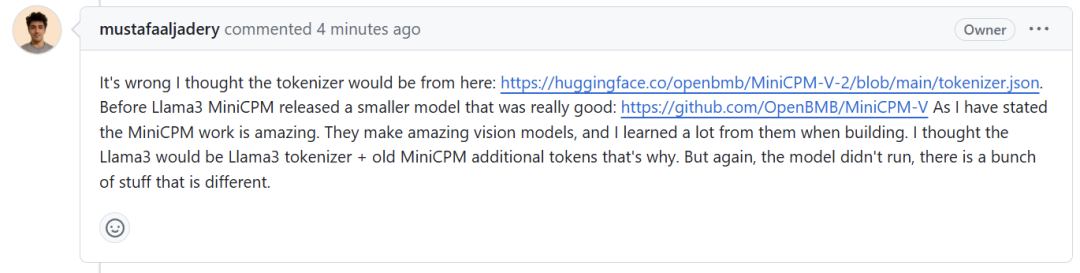
这的确是在 MinicPM-Llama3-V2.5 之前发布的,但是需要注意的是,MinicPM-V-2 的 tokenizer 与 MinicPM-Llama3-V2.5 完全不同,它们不是同一个标记符文件,文件大小也完全不同。
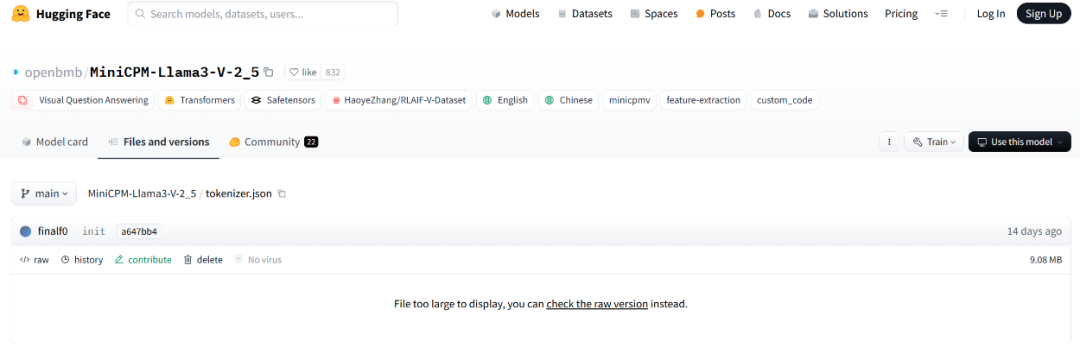
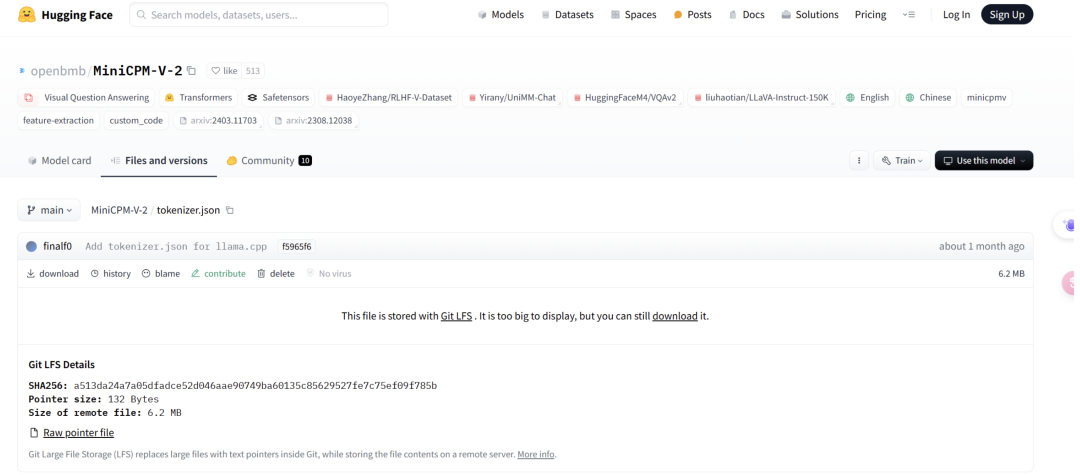
而 MinicPM-Llama3-v2.5 的 tokenizer 是由 Llama3 tokenizer 加上 miniCPM-v 系列模型中的几个特殊 token 组成的,而且 MinicPM-v2 发布都是在 llama3 开源之前,怎么会有 Llama3 分词器。
毫无疑问,Llama3-V 作者撒谎了。

事实 3:Llama3-V 项目的作者害怕面对质疑,删除了网友在 llama3-V 上提出的质疑他们偷窃的问题
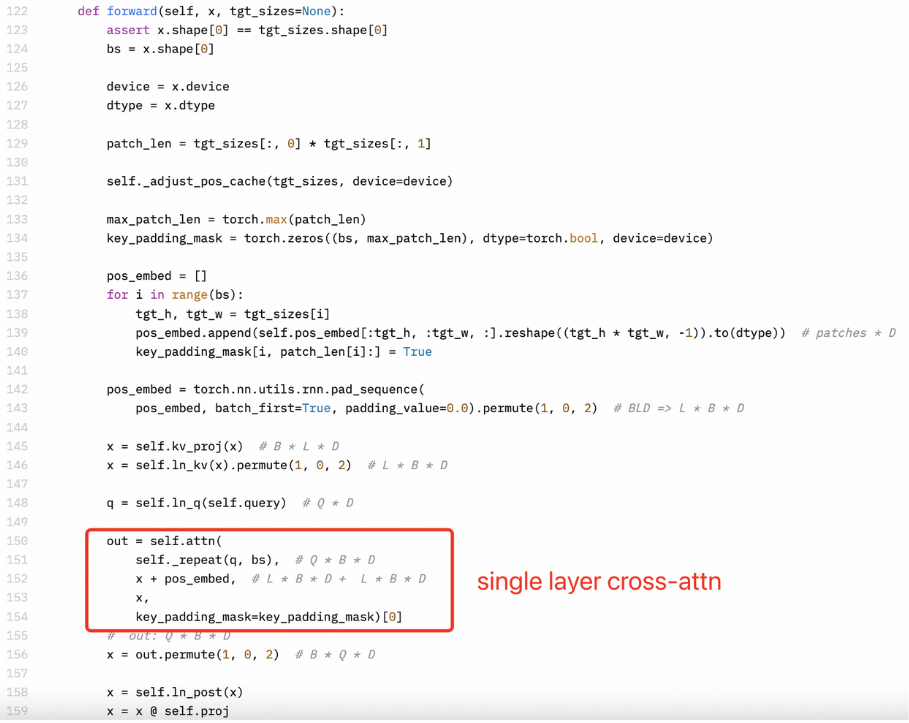
此外,Llama3-V 作者似乎并不完全了解 MiniCPM-Llama3-V 2.5 的架构或他们自己的代码。感知器重采样器(Perceiver Resampler)是单层交叉注意力,而不是双层自注意力。
Llama3-V 的技术博客中描述明显是错误的:

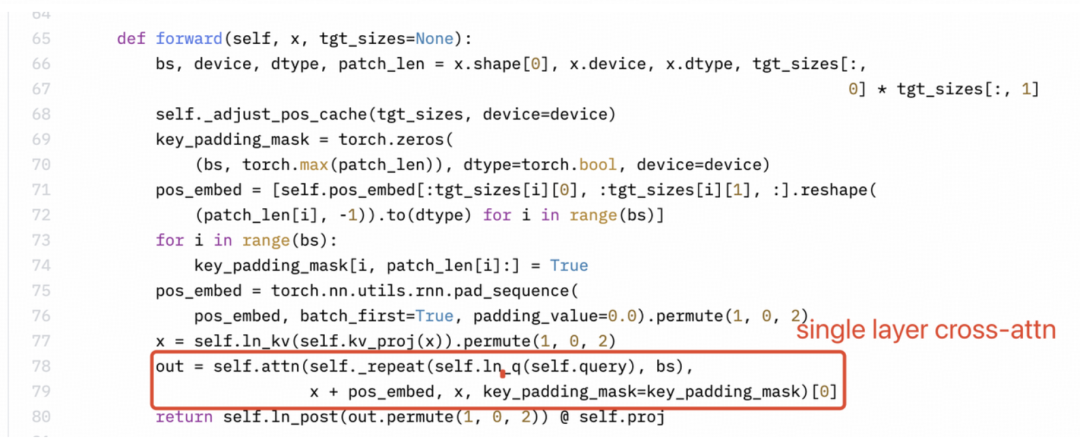
MiniCPM-Llama3-V 2.5:
SigLIP 的 Sigmoid 激活不用于训练多模态大语言模型。这些激活仅用于预训练 SigLIP。

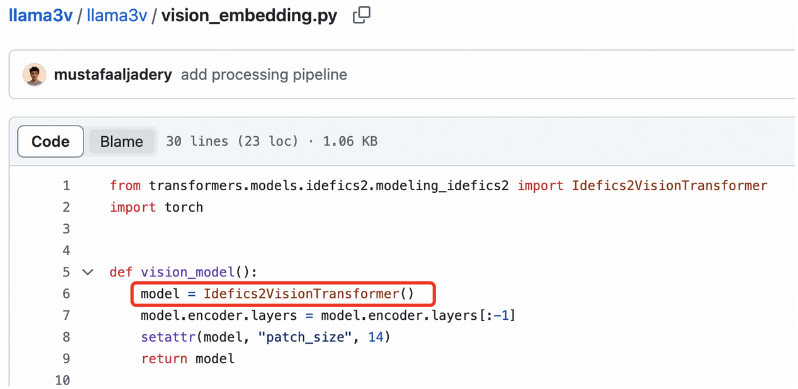
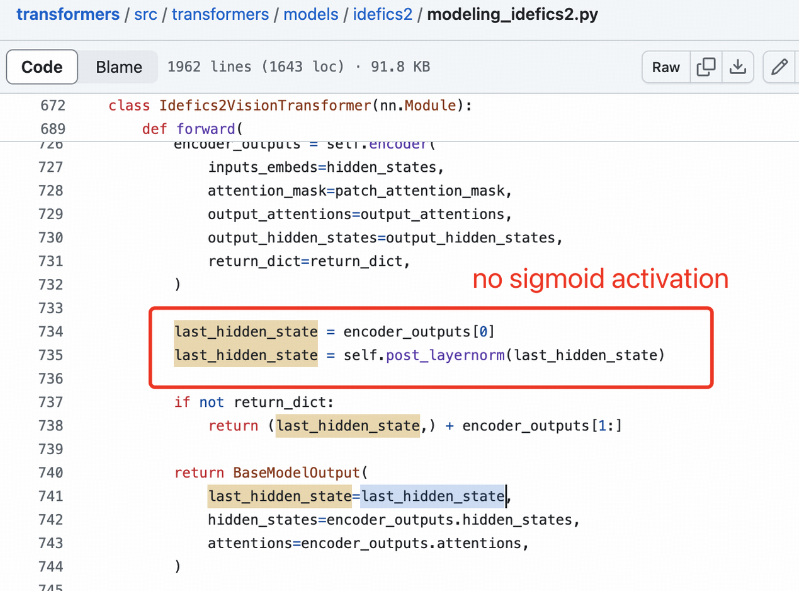
事情到此还没有结束。pzx163 继续补充自己发现的证据:
1. 前几天,当网友尝试运行 Llama3-V 时,发现他们提供的代码无法与 HuggingFace 的 checkpoint 兼容。GitHub 和 HuggingFace 上已经发布了许多关于此问题的问题,但作者尚未回复。网友将从 HuggingFace 下载的 Llama3-V 模型权重中的变量名称更改为 MiniCPM-Llama3-V 2.5 的名称,并意外地发现该模型可以成功与 MiniCPM-V 代码一起运行。
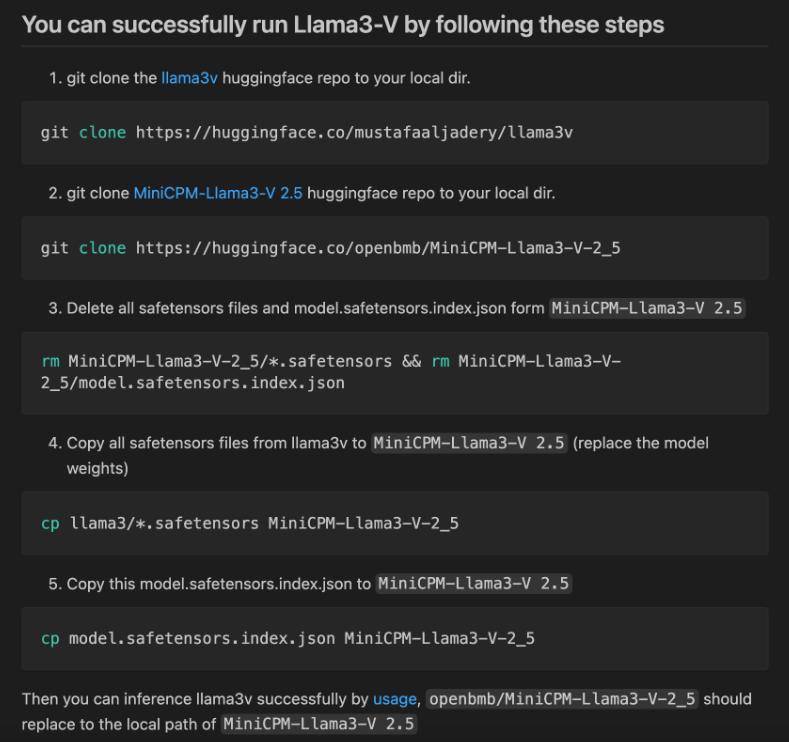
2. 如果将高斯噪声(由单个标量参数化)添加到 MiniCPM-Llama3-V 2.5 的检查点,会得到什么?
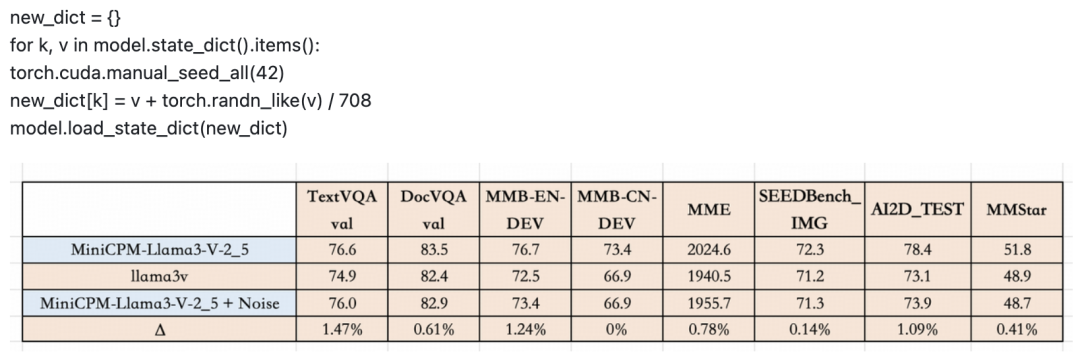
根据 pzx163 的尝试发现,你实际上可以得到一个新的检查点,“如果给这个新检查点起一个新名字,称之为 llama3-V,听起来不是很棒吗?至少哈希值将与 miniCPM-llama3-V2.5 完全不同,对吧?”
对此,pzx163 得出自己的结论:“我认为有充分的证据证明 llama3-v 项目窃取了minicpm-llama 3-v 2.5 项目的学术成果,并且强烈建议 minicpm-llama 3-v 2.5 项目团队去投诉,揭露 llama3-v 项目作者的窃取、说谎学术不端等等一系列问题!”

官方调查:在未公开数据上,Llama3-V 表现出与 MiniCPM-Llama3-V 2.5 相似特征
关注到这一问题后,MiniCPM-Llama3-V 2.5 团队也迅速展开了调查,并得出了结论:
-
更改参数名称后,可以使用 MiniCPM-Llama3-V 2.5 的代码和 config.json 运行 Llama3-V
-
它的表现与 MiniCPM-Llama3-V 2.5 类似,在内部数据上训练了未公开的实验特征,例如识别清华竹简和 GUIAgent
-
它有点类似于 MiniCPM-Llama3-V 2.5 的噪音版本?
要知道 MiniCPM-Llama3-V 2.5 团队在内部私有数据上训练的清华竹简,这是一种非常特殊且罕见的中国古代文字,写在竹子上,这些都是未公开的实验性特征,斯坦福 AI 团队的 Llama3-V 竟然表现出与 MiniCPM-Llama3-V 2.5 高度相似的行为,话都不用多说,明眼就知道发生了什么。
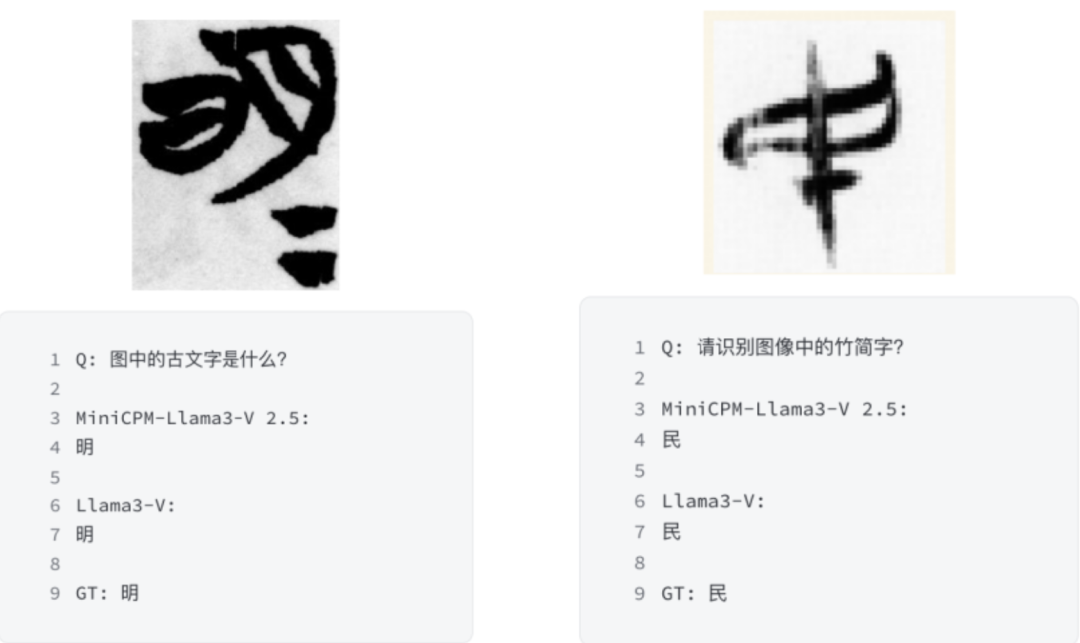

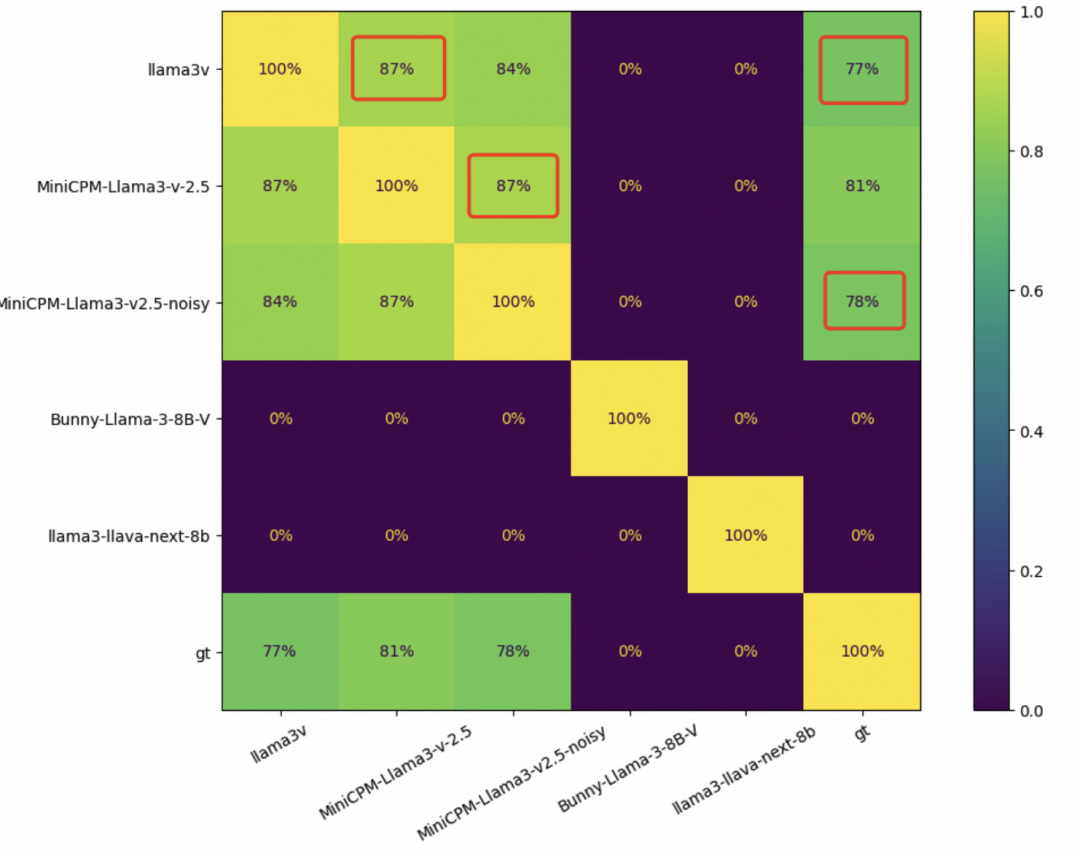
当然,为了严谨起见,MiniCPM-Llama3-V 2.5 团队还在 1K 竹子字符图像上测试了几个基于 Llama3 的 VLM,并比较了每对模型的预测精确匹配。
Llama3-V 和 MiniCPM-Llama3-V 2.5 之间的重叠度竟然达到了惊人的 87%,而且 MiniCPM-Llama3-V 2.5 和 Llama3-V 甚至有着相似的误差分布,Llama3-V 和 MiniCPM-Llama3-V 2.5 分别有 236 和 194 个错误预测,重叠部分有 182 个。
MiniCPM-Llama3-V 2.5 团队表示,“按照GitHub上@yangzhizheng1的说明得到的MiniCPM-Llama3-V2.5-noisy,其定量结果与Llama3-V几乎一模一样,真是让人摸不着头脑……”
同样的事情也发生在 WebAgent 上,这是另一个未公开的功能,使用内部数据进行训练。Llama3-v 的作者甚至在 MiniCPM-Llama3-V 2.5 团队新定义的 WebAgent 架构中犯了相同的错误……

紧急删库
面对层层实锤的证据,Llama3-V 的 HuggingFace 页面现已被移除,GitHub repo 也做了删除:
Llama3-V 作者之一的 Aksh Garg 在 Medium 平台的官宣文中上更新道:
非常感谢在评论中指出与之前研究相似之处的人。我们意识到我们的架构与 OpenBMB 的“MiniCPM-Llama3-V 2.5:手机上的 GPT-4V 级多模态 LLM”非常相似,他们在实现方面领先于我们。为了尊重作者,我们删除了原始模型。
原始作者存储库的链接可以在这里找到:https://github.com/OpenBMB/MiniCPM-V/tree/main?tab=readme-ov-file
— Aksh Garg、Sid Sharma
不过关于 Llama3-V 的概述、模型架构、如何训练的细节仍然做了保留(https://aksh-garg.medium.com/llama-3v-building-an-open-source-gpt-4v-competitor-in-under-500-7dd8f1f6c9ee)。
更让人有些无奈的是,今天中午,有不少网友发现作者之一的 Aksh Garg 发布了一则道歉声明,然而没过多久,却删了,只留下上述在 Medium 平台上一句简短的回应。
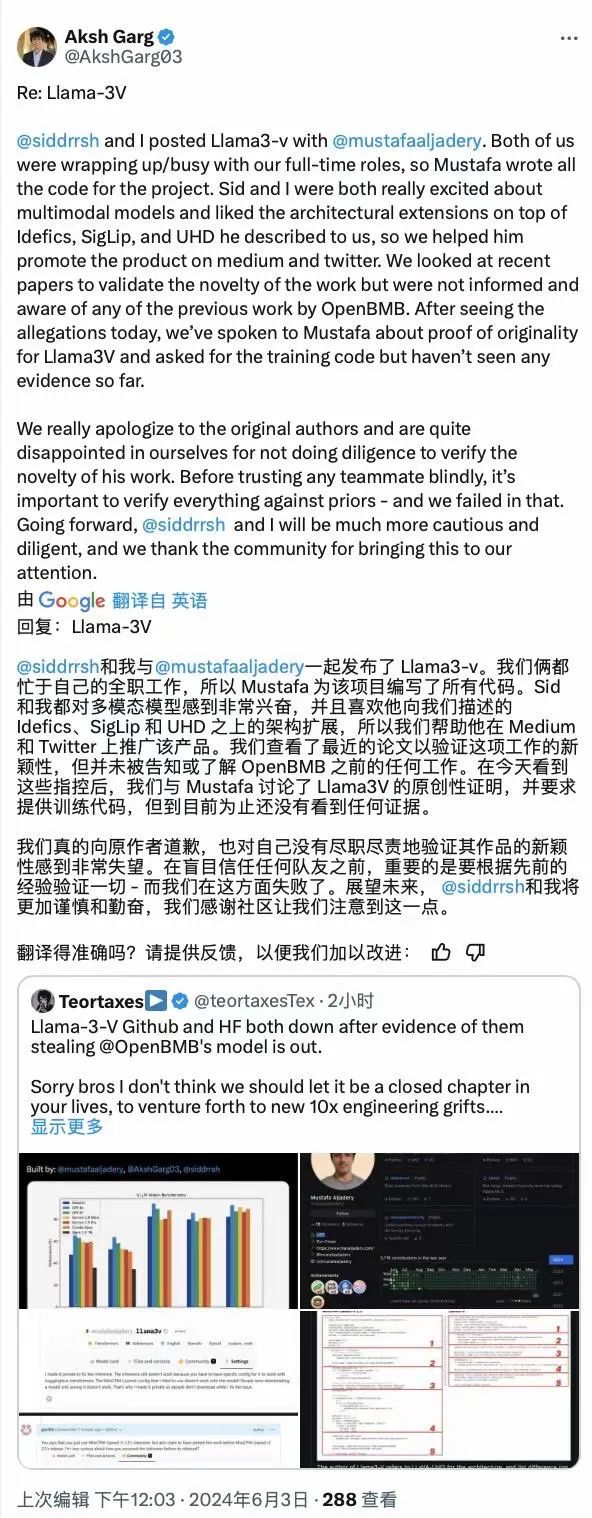
对于这一事件,MinicPM-Llama3-V2.5 团队在 GitHub 上表示,「鉴于这些结果,我们很难用巧合来解释这种不寻常的相似性。我们希望作者能够对这个问题给出官方解释。我们相信这对开源社区的共同利益很重要。」
面壁智能 CEO 李大海在朋友圈评论道:
“这两天收到社区和媒体及朋友的反馈,来自斯坦福团队的 Llama3V 项目与面壁小钢炮最新发布的多模态模型 MiniCPM-Llama3-V 2.5 展现出惊人的相似度。
经过团队核实,除了社区网友列出的证据外,我们还发现 Llama3V 展现出和小钢炮一样的清华简识别能力,连做错的样例都一模一样,而这一训练数据尚未对外公开。这项工作是团队同学耗时数个月,从卷帙浩繁的清华简中一个字一个字扫描下来,并逐一进行数据标注,融合进模型中的。更加 tricky 的是,两个模型在高斯扰动验证后,在正确和错误表现方面都高度相似。
技术创新不易,每一项工作都是团队夜以继日的奋斗结果,也是以有限算力对全世界技术进步与创新发展作出的真诚奉献。我们希望团队的好工作被更多人关注与认可,但不是以这种方式。
我们对这件事深表遗憾!一方面感慨这也是一种受到国际团队认可的方式,另一方面也呼吁大家共建开放、合作、有信任的社区环境。一起加油合作,让世界因AGI的到来变得更好!”
参考来源:
https://github.com/OpenBMB/MiniCPM-V/issues/196
https://aksh-garg.medium.com/llama-3v-building-an-open-source-gpt-4v-competitor-in-under-500-7dd8f1f6c9ee
推荐阅读:
▶被视为 QQ 的“大哥”,运行 28 年的老牌软件即将关停!
▶《庆余年2》唯一婚礼的凤冠,自曝由 Blender 建模、3D 打印!这款诞生于 30 年前的软件,有什么魔力?
▶在1500万行源码上“动刀”,复刻「美版」核心算法?TikTok下场辟谣
















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









