






斯坦福AI团队,竟然曝出了抄袭事件,而且抄袭的还是中国国产的大模型成果——模型结构和代码,几乎一模一样!跟任何抄袭事故一样……AI圈内都惊呆了。

斯坦福的这项研究叫做Llama3-V,是于5月29日新鲜发布,宣称只需要500美元就能训出一个SOTA多模态大模型,比GPT-4V、Gemini Ultra、Claude Opus都强。

Llama3-V的3位作者或许是拥有名校头衔加持,又有特斯拉、SpaceX的大厂相关背景,这个项目短短几天就受到了不小的关注。
甚至一度冲上了HuggingFace趋势榜首页:
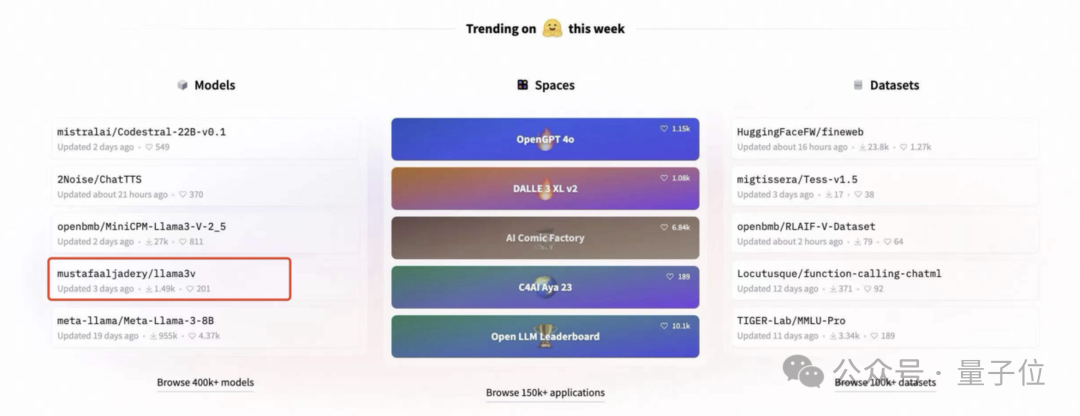
然而,戏剧性的一幕开始上演了。
有位细心的网友发现,咦?这“配方”怎么如此的熟悉?
然后他定睛一看,好家伙,这不就是MiniCPM-Llama3-V 2.5(出自清华系明星创业公司面壁智能)嘛。
于是这位网友便跑到面壁智能GitHub项目下开始爆料了:
你们家大模型被斯坦福团队抄袭了!
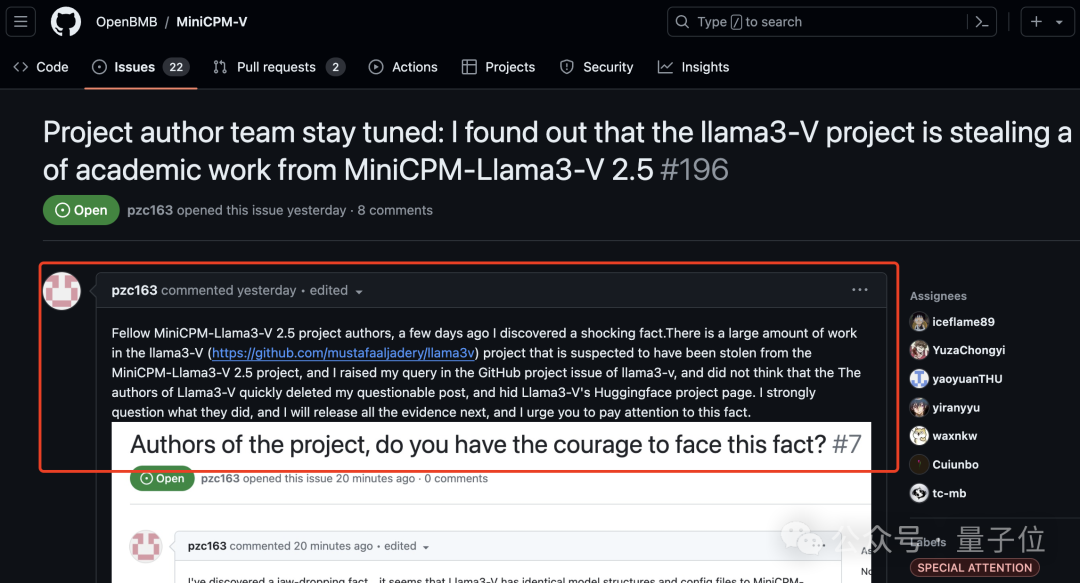
并且他还附上了一堆的证据,最直接的莫过于这张2个模型代码的对比图了:
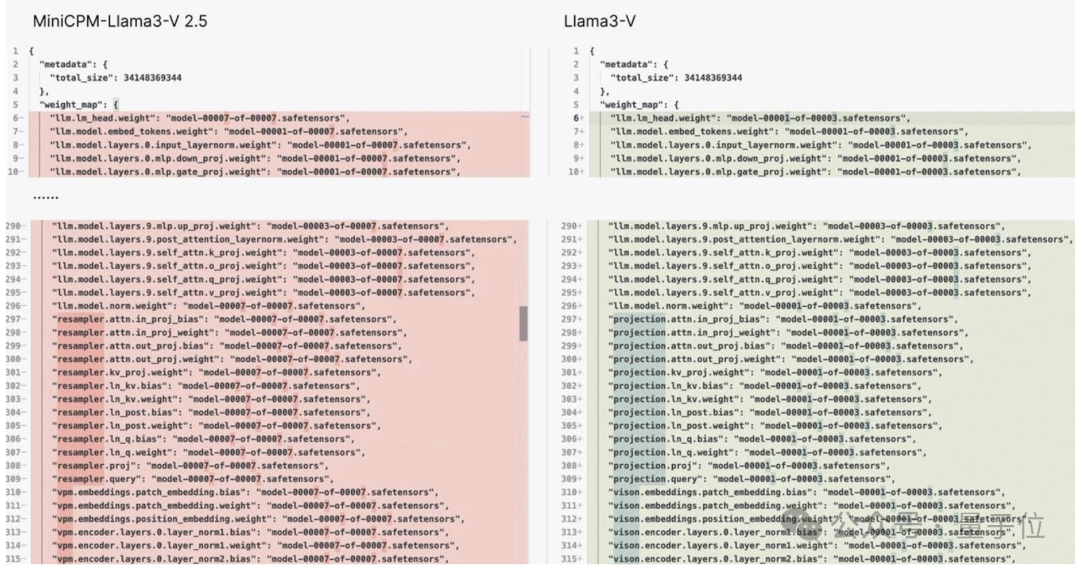
Emmm……用这位网友的话来说就是:
模型结构、代码、配置文件,简直一模一样,只是变量名变了而已。
至于为什么这位网友要跑到面壁智能GitHub项目下面留言,是因为他之前已经给Llama3-V作者留过言了,但斯坦福团队的做法竟是删库跑路……
没错,现在不论是GitHub还是HuggingFace,统统都是404:
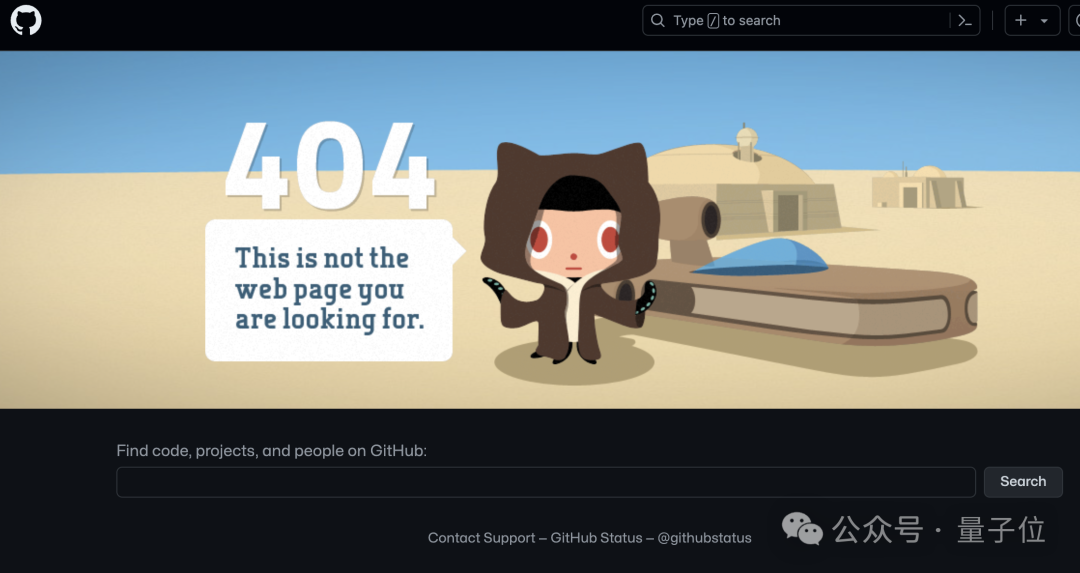
并且这事现在还在持续发酵的过程中,网上吃瓜的群众也是越来越多。
那么我先来一同回顾一下这件drama事情的始末。
“代码和架构一模一样”
正如刚才所述,一个网友爆料Llama3-V抄袭MiniCPM-Llama3-V 2.5,跑到面壁智能的GitHub主页提醒团队注意,并把关键证据都一一截图列举整理了下来,这才有了整个抄袭门的还原现场。
以下是来自这位网友的证据。
证据一,Llama3-V的模型架构和代码与MiniCPM-Llama3-V 2.5几乎完全相同:
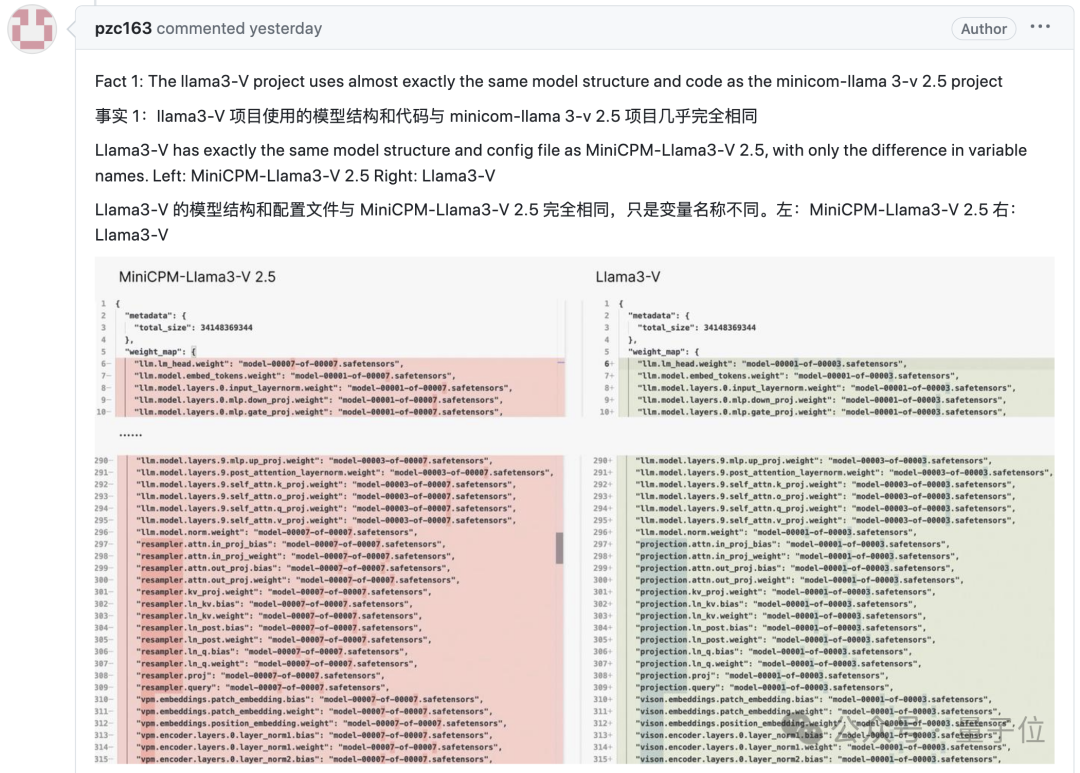
看下面的例子,配置文件就改了图像切片、分词器、重采样器和数据加载等格式化和变量名:
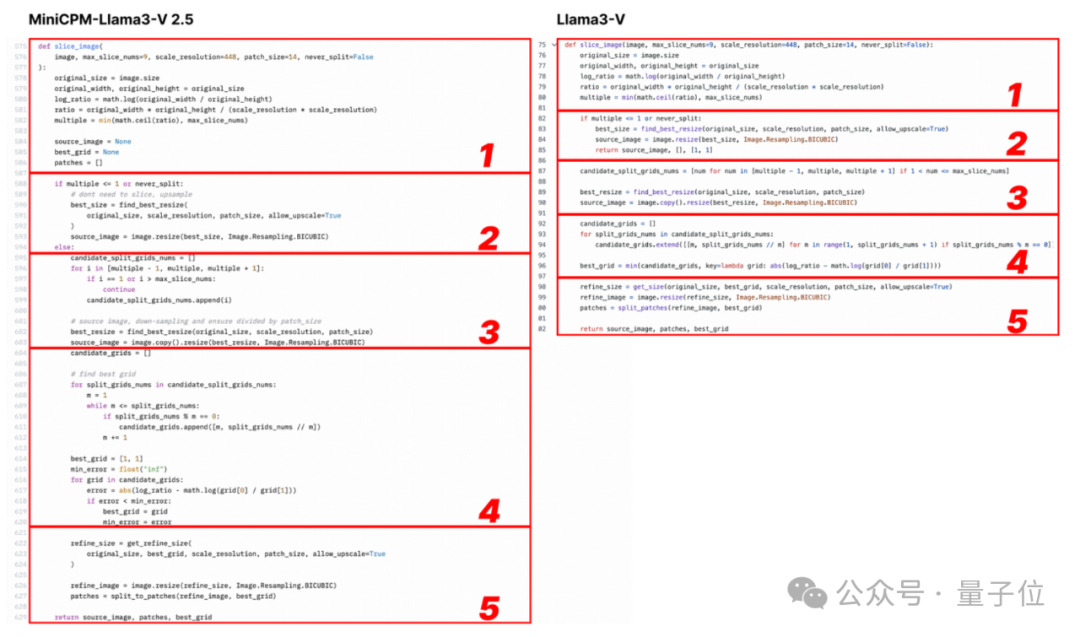
Llama3-V作者表示参考了LLaVA-UHD架构,在ViT和LLM等选择上有一些差异。但实际上,网友发现他们的具体实现在空间模式等很多方面都与LLaVA-UHD不同,却出奇与MiniCPM-Llama3-V 2.5一致。
甚至,Llama3-V还用了MiniCPM-Llama3-V 2.5的分词器,连MiniCPM-Llama3-V 2.5定义的特殊符号都能“巧合”实属离谱。

证据二,网友质疑Llama3-V作者是如何在MinicPM-Llama3-V2.5项目发布之前就使用上MinicPM-Llama3-V2.5分词器的。
Llama3-V作者给的回复是这样婶儿的,说是用的面壁智能上一代MinicPM-V-2项目的:
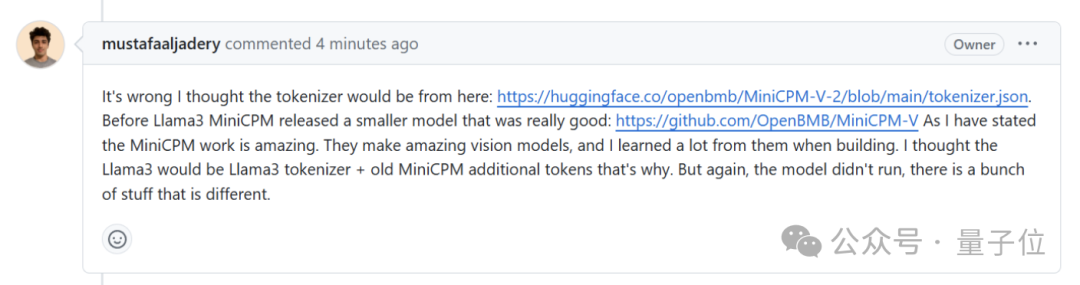
但事实却是,HuggingFace中,MiniCPM-V2与MiniCPM-Llama3-V 2.5分词器分别是两个文件,文件大小也完全不同。
MiniCPM-Llama3-V 2.5的分词器是用Llama3分词器加上MiniCPM-V系列模型的特殊token组成,而MiniCPM-V2的发布都在Llama3开源之前,怎么会有Llama3分词器。
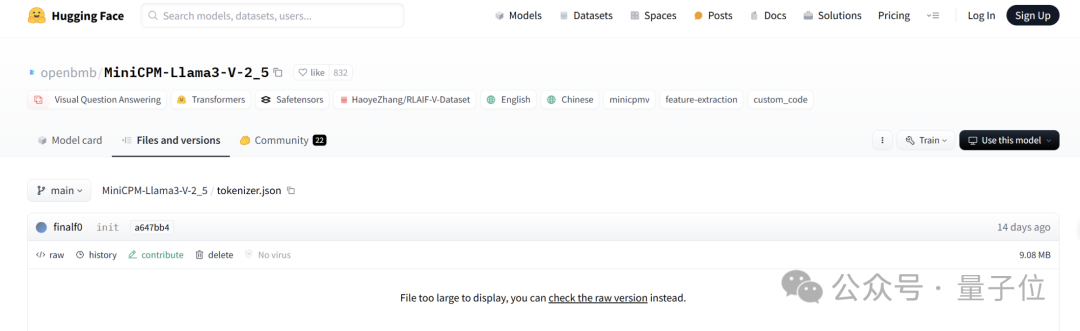
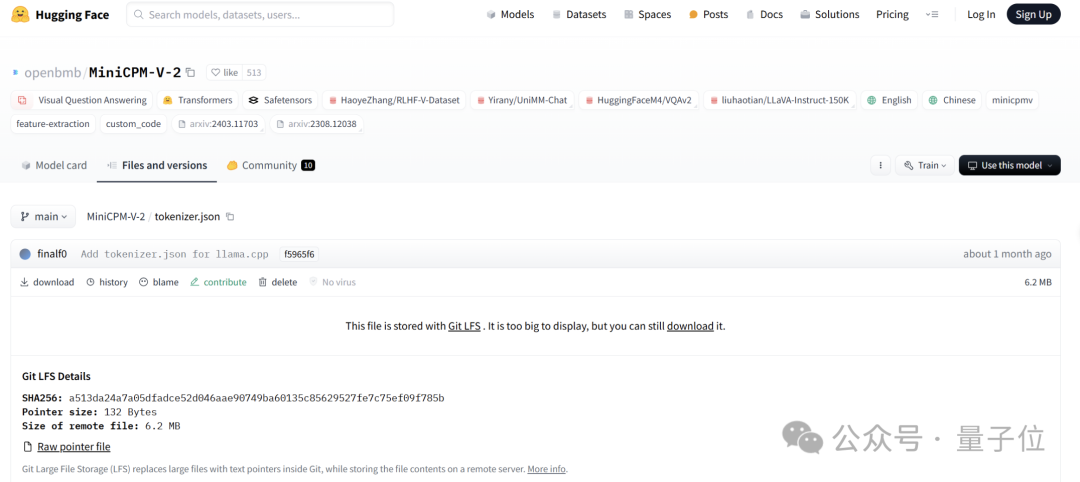
证据三,Llama3-V作者随后无故删除了网友在Llama3-V页面上提交的质疑他们抄袭的问题。
而且,他们似乎对MiniCPM-Llama3-V 2.5架构或他们自己的代码都不完全了解。
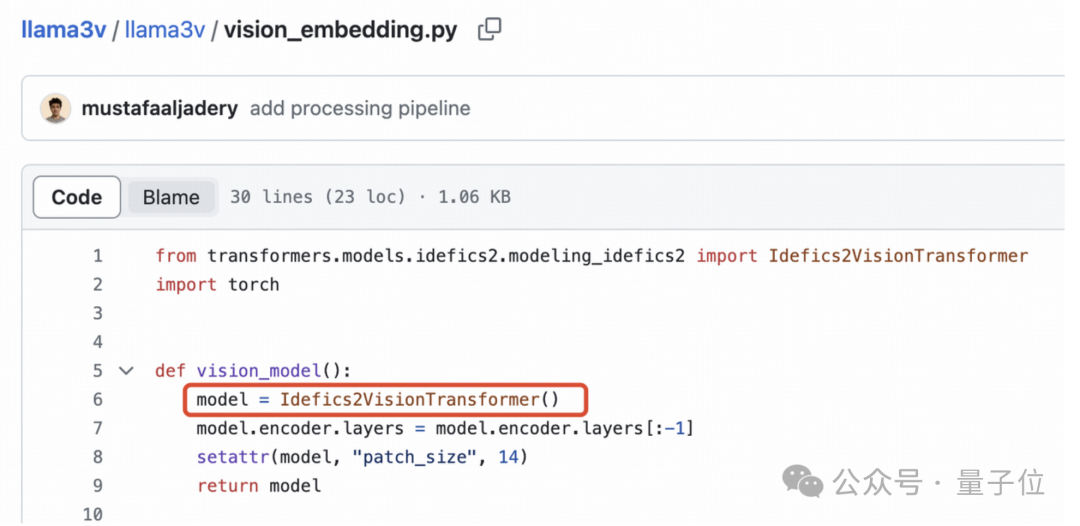
感知器重采样器(Perceiver resampler)是单层交叉注意力,而不是双层自注意力。但是下图所示Llama3-V的技术博客里作者的理解很明显是错的。

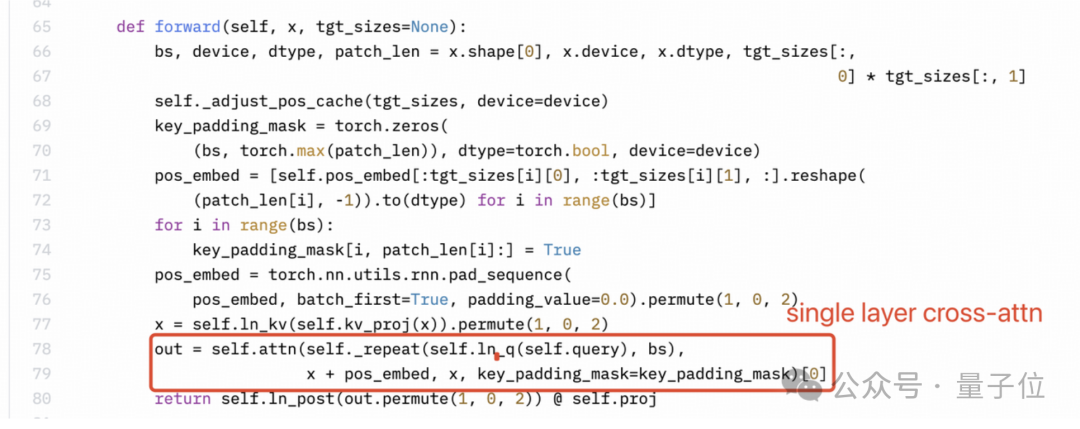
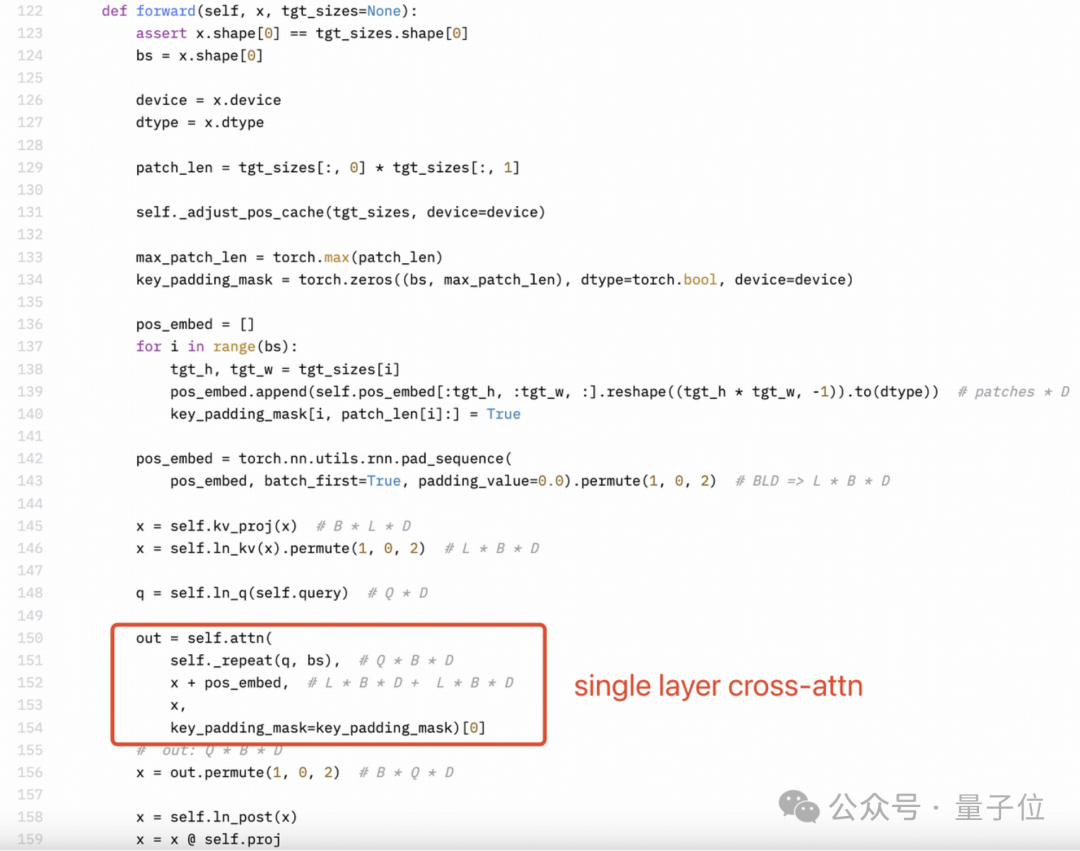
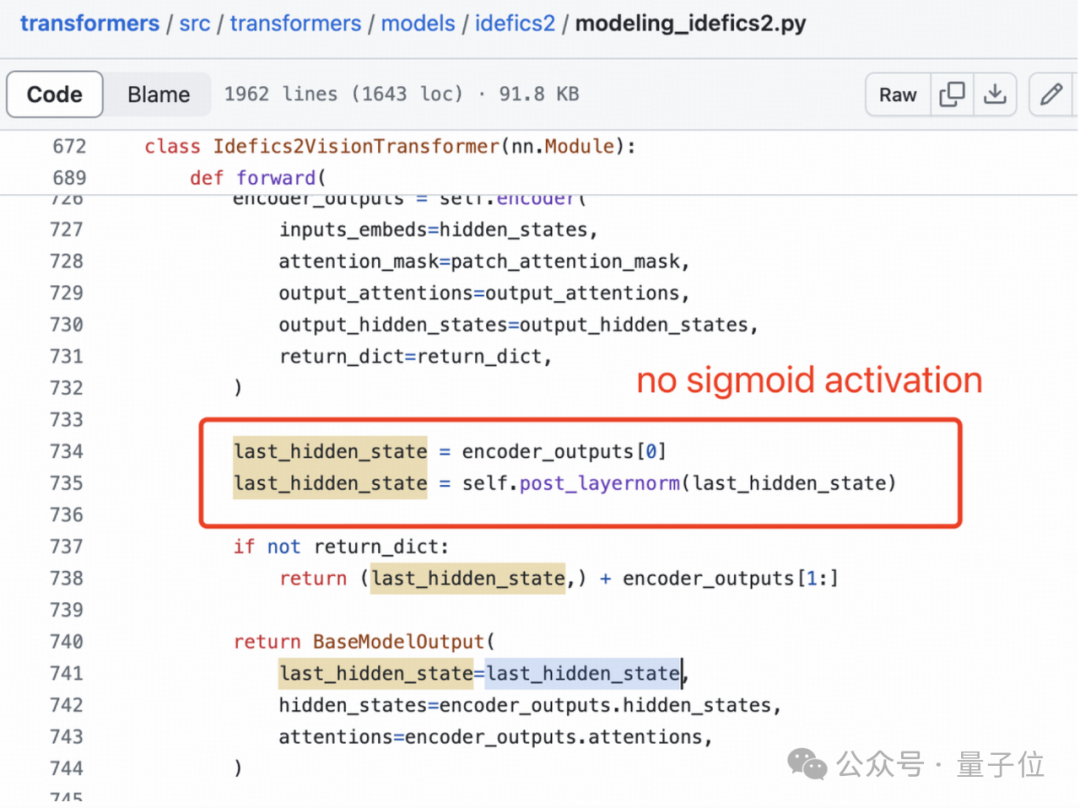
SigLIP的Sigmoid激活也不用于训练多模态大语言模型,而仅用于预训练SigLIP。
视觉特征提取不需要Sigmoid激活:

基于以上三点事实,这位网友认为足以证据证明Llama3-V项目窃取了MiniCPM-Llama3-V 2.5项目的学术成果。
但还没完,他随后又补充了两点证据。
几天前,当这位网友尝试运行Llama3-V时,发现他们提供的代码无法与HuggingFace的checkpoint一起使用,反馈问题没有得到作者回复。
于是网友把从HuggingFace下载的Llama3-V模型权重中的变量名改成了MiniCPM-Llama3-V 2.5的,惊奇发现模型居然可以用MiniCPM-V代码成功运行。
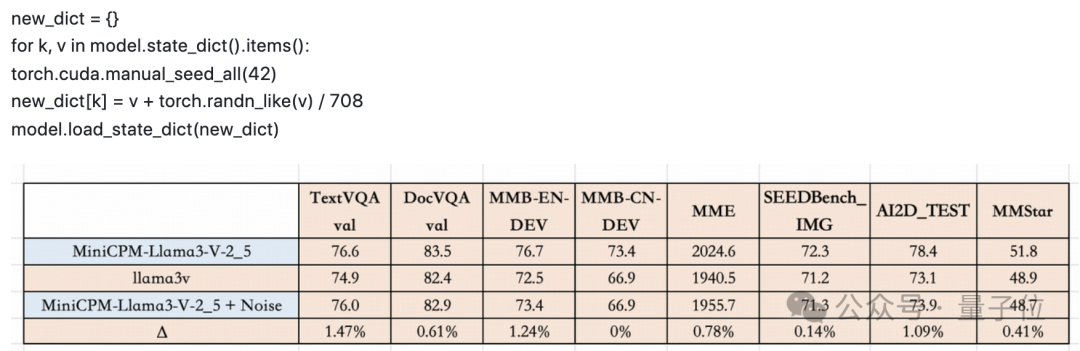
此外,如果将高斯噪声(由单个标量参数化)添加到MiniCPM-Llama3-V 2.5的checkpoint,结果就是会得到一个行为与Llama3-V极其相似的模型。
收到网友的提醒后,MiniCPM-Llama3-V 2.5团队这边也迅速展开了调查,他们按照网友的在GitHub上的说明,使用 Llama3-V的checkpoint和MiniCPM-Llama3-V 2.5的代码和配置文件正确获取了推理结果。
于是,一个更为关键性的证据出现了。
Llama3-V在一些未公开的实验性特征上表现出与MiniCPM-Llama3-V 2.5高度相似的行为,而这些特征是根据MiniCPM-Llama3-V 2.5团队内部数据训练的。
例如,识别清华简!
MiniCPM-Llama3-V 2.5特有的功能之一是识别清华简,这是一种非常罕见、于战国时期写在竹子上的中国古代文字。
训练图像是从最近出土的文物中扫描出来的,由MiniCPM-Llama3-V 2.5团队进行了标注,尚未公开发布。
而Llama3-V的识别情况和MiniCPM-Llama3-V 2.5极为相似。
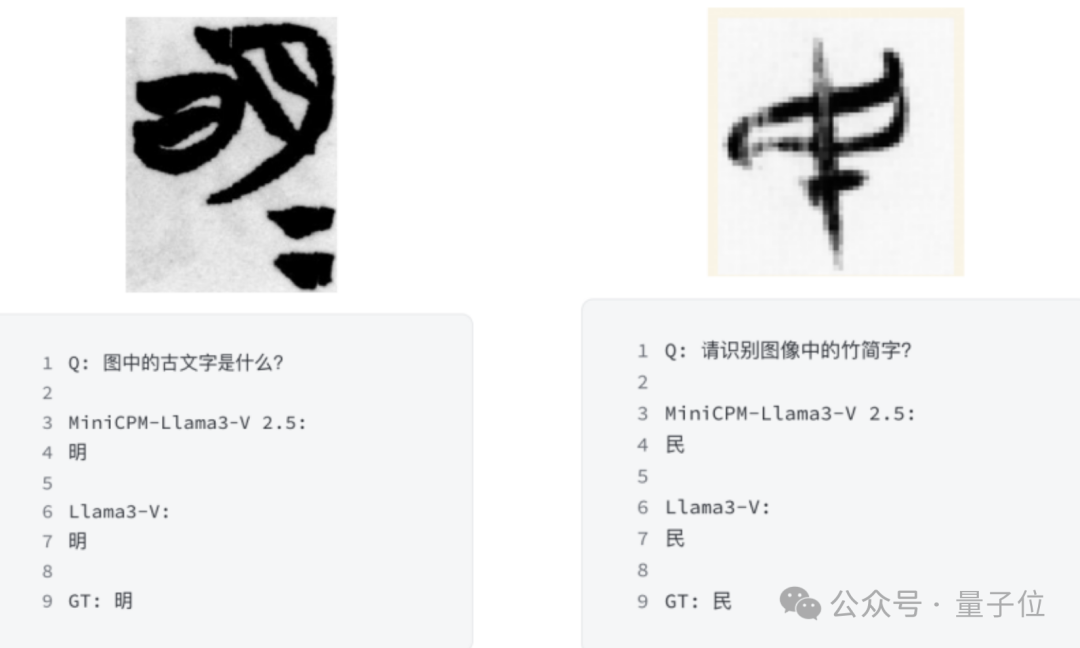
识别错误的情况竟也出奇一致:

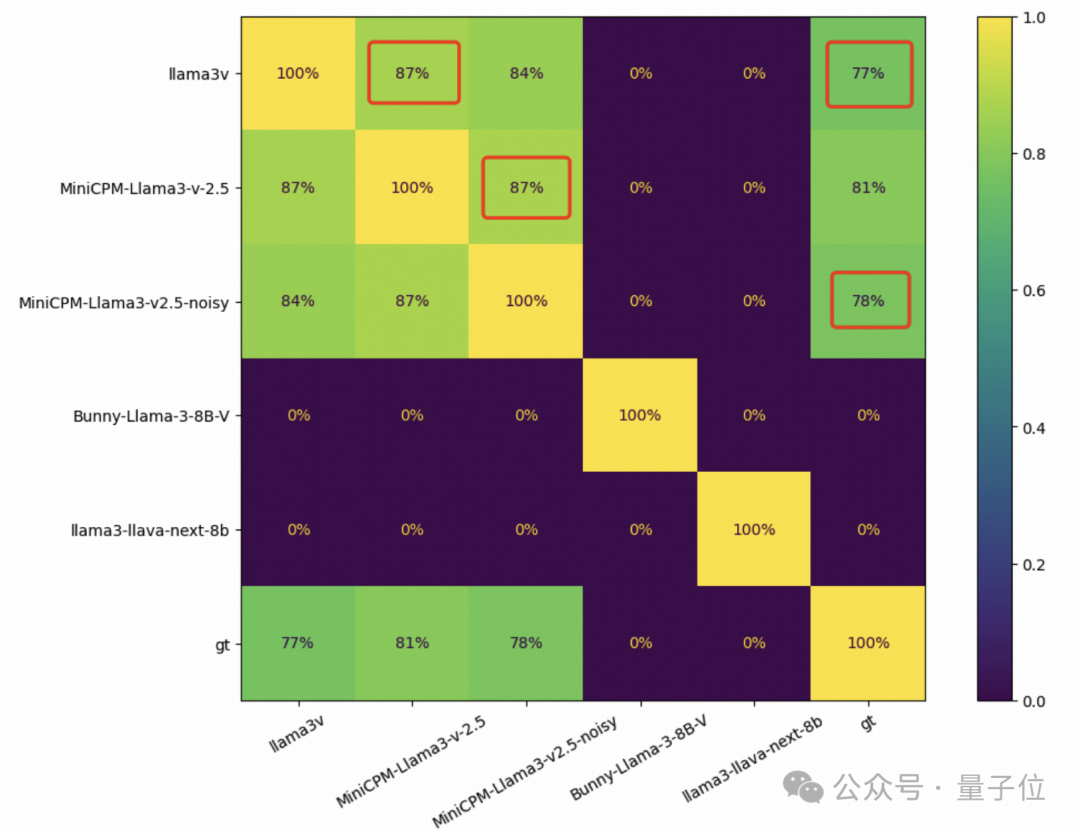
MiniCPM-Llama3-V 2.5团队还在1000 张竹简图像上测试了几种基于Llama3的视觉-语言模型,并比较了每对模型的预测精确匹配。
结果,每两个模型之间的重叠为零,而Llama3-V和MiniCPM-Llama3-V 2.5之间的&&重叠达到了惊人的87%**。
此外,MiniCPM-Llama3-V 2.5和Llama3-V甚至具有相似的错误分布。Llama3-V和MiniCPM-Llama3-V 2.5分别做出 236和194个错误预测,重叠部分为182个。
且按照网友在GitHub上的指令获得的MiniCPM-Llama3-V2.5-noisy显示出与Llama3-V几乎相同的定量结果,真令人匪夷所思……
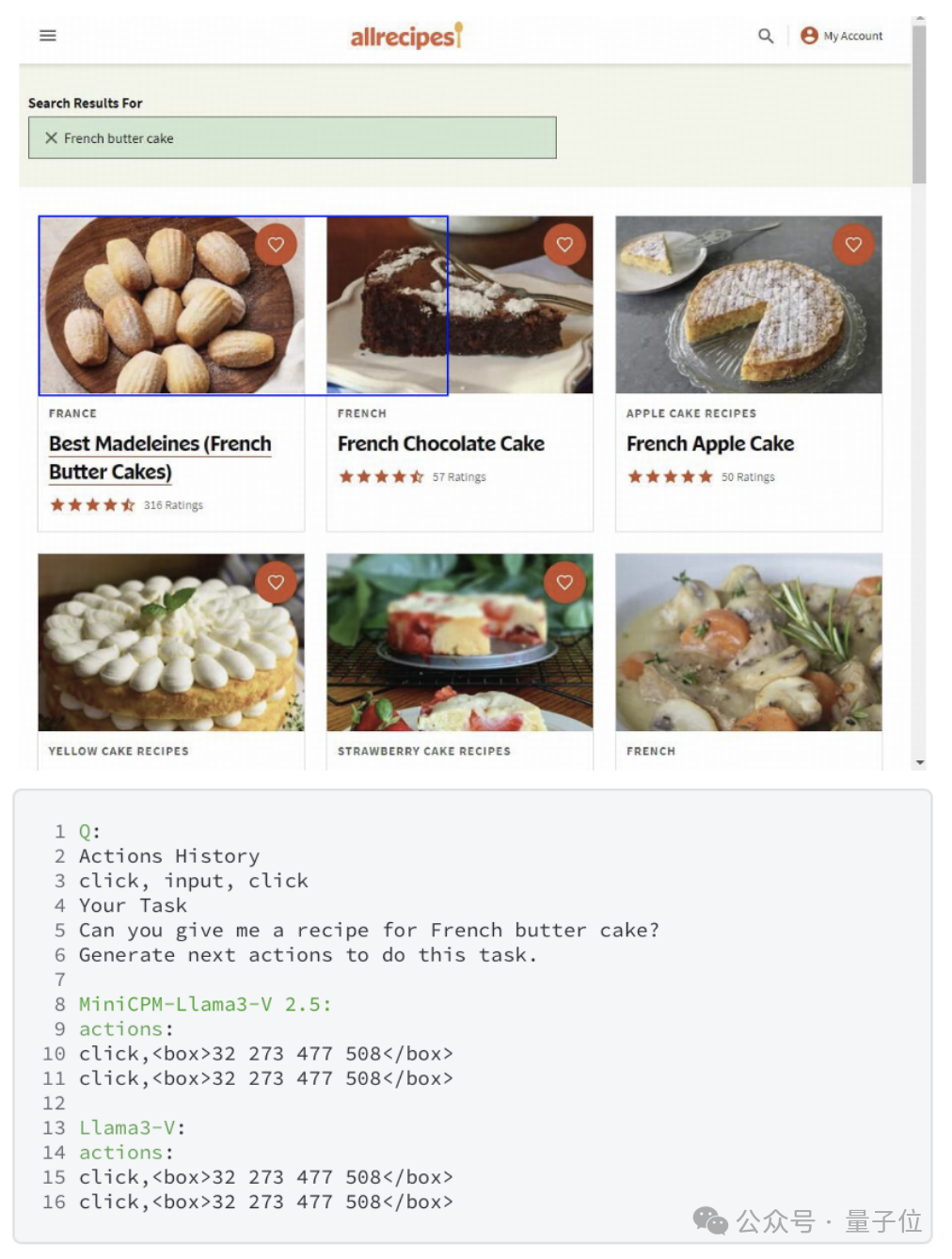
在另一个MiniCPM-Llama3-V 2.5内部数据上训练的未公开功能——WebAgent上,也出现了同样的情况。
Llama3-V甚至和MiniCPM-Llama3-V 2.5团队新定义的WebAgent模式中犯的错误都一样。
鉴于这些结果,MiniCPM-Llama3-V 2.5团队表示很难将这种不寻常的相似性解释为巧合,希望Llama3-V作者能对这个问题给出一个正式的解释。

斯坦福团队已删库跑路
虽然斯坦福的2位本科生已经下架了几乎所有与之相关的项目,但其实在此之前,他们最初在面对质疑的时候还是做出了些许的解释。
例如他们强调,Llama3-V这项工作的时间是要早于面壁智能的MiniCPM,只是使用了他们的tokenizer。
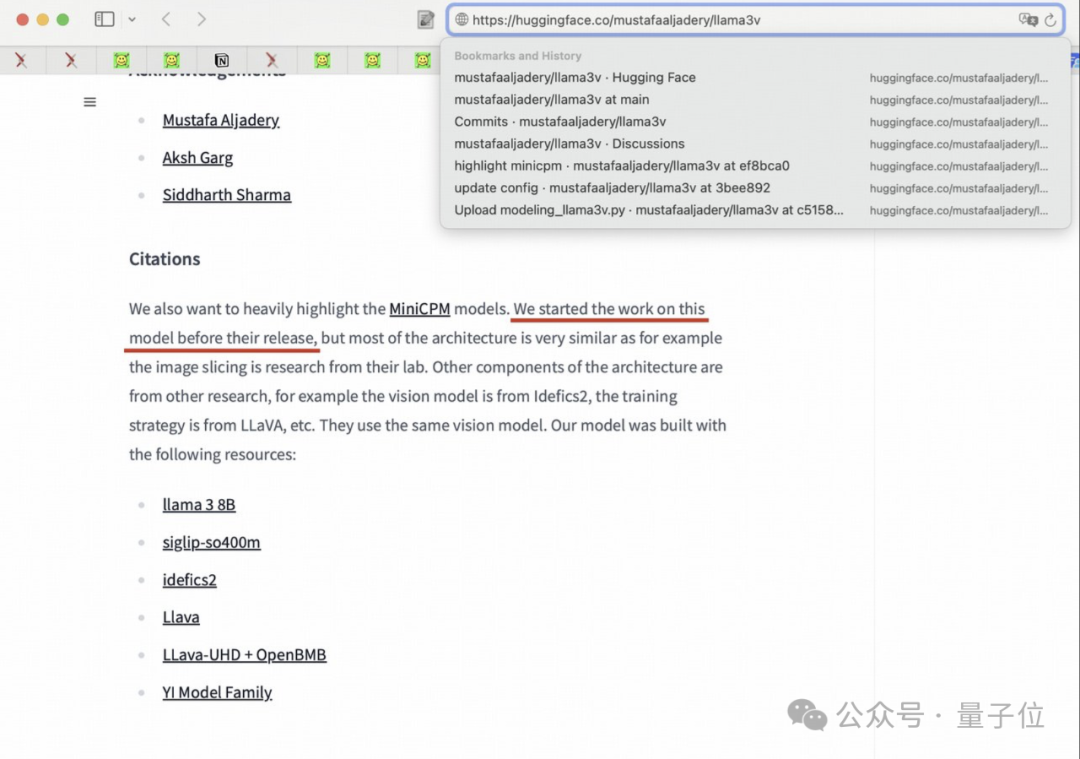
不过作者对Medium上的声明还是做了保留:
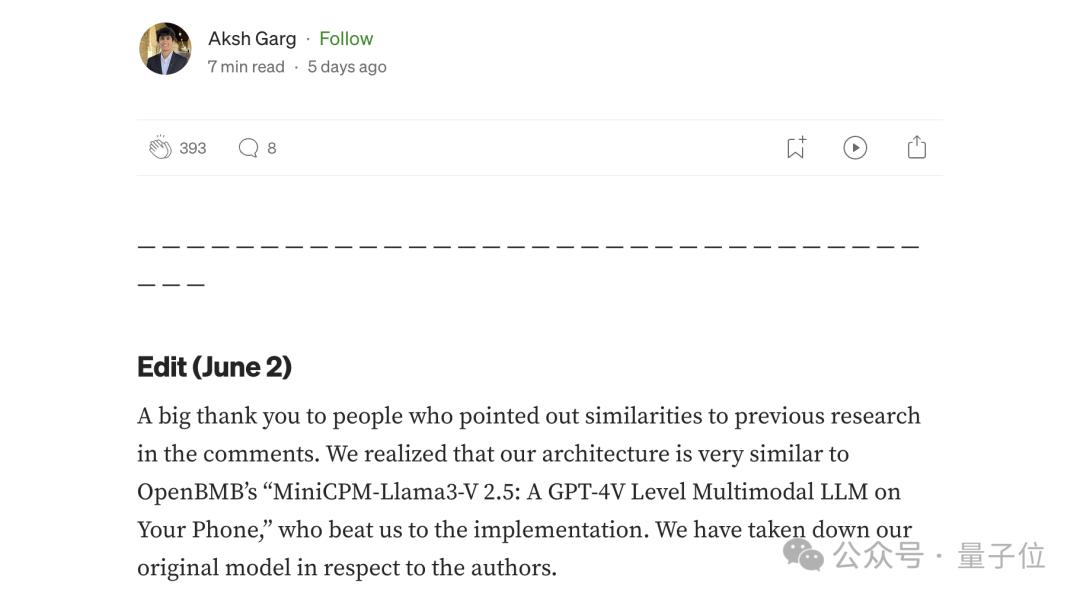
非常感谢那些在评论中指出与之前研究相似之处的人。
我们意识到我们的架构非常类似于OpenBMB的“MiniCPM-Llama3-V 2.5,他们在实现上比我们抢先一步。
我们已经删除了关于作者的原始模型。
对此,一部分网友表示,既然选择删掉项目,那么就表示确实存在一定的问题。
不过另一方面,对于抄袭这事也有不一样的声音——
MiniCPM-Llama3-V 2.5不也是在Llama3的基础上做的改良吗?不过连tokenizer都直接拿来用就应该不算是借鉴了。
而就在刚刚,另一个戏剧性的事情发生了。
斯坦福的作者在中午时间做出了最新的回应:
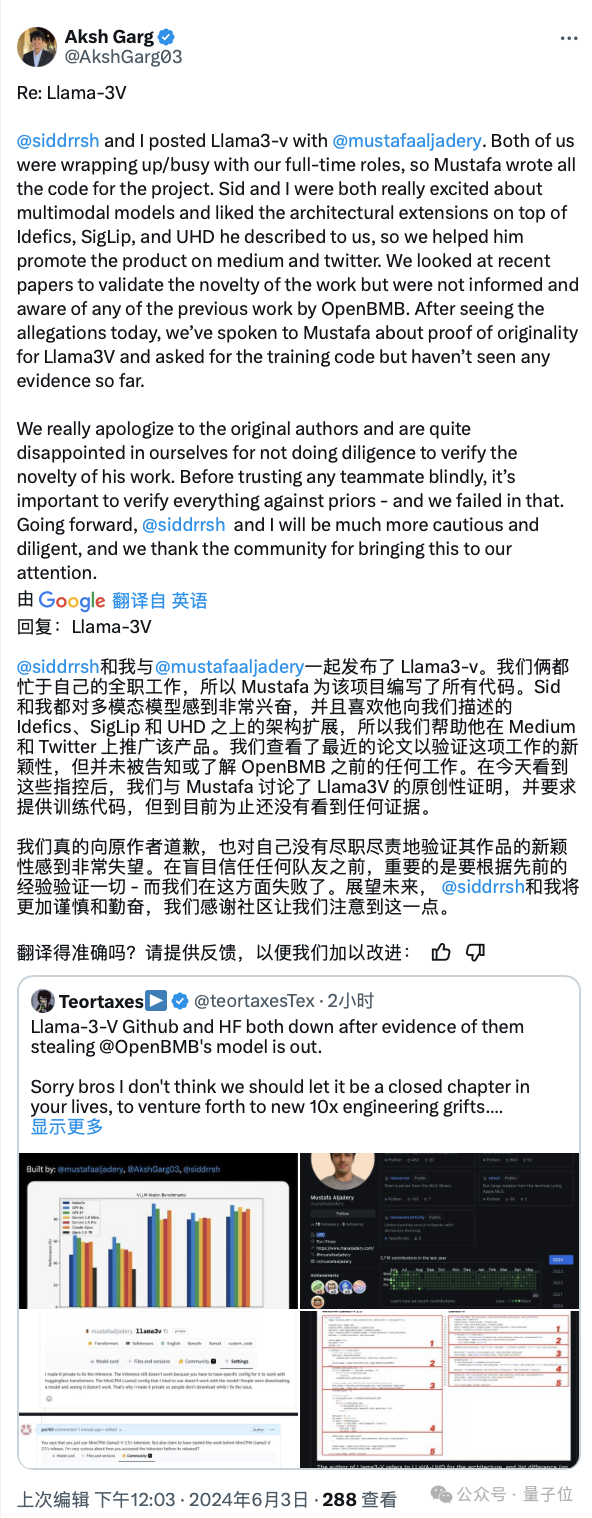
但现在……这条回应又删掉了
而面壁智能这边,CEO李大海也做出了正式回应:

如何学习大模型 AGI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
-END-
👉AGI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉AGI大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉AGI大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









