







【导读】大模型时代的到来,将对开发者最为熟悉的研发领域带来怎样的变化?本文作者从大模型与研发活动的现状出发,结合CodeFuse的开发经验和实际应用效果,详细阐述了蚂蚁在智能研发方面的思考与探索,探讨了大模型在落地过程中的挑战与解决方案,更进一步揭示了智能研发的未来发展方向。
本文出自 2024 全球软件研发技术大会中的演讲,同时收录于《新程序员 008》。《新程序员 008》聚焦于大模型对软件开发的全面支撑,囊括 Daniel Jackson 和 Daniel Povey 等研发专家的真知灼见与“AGI 技术 50 人”栏目的深度访谈内容,欢迎大家点击订阅年卡。
作者 | 姜伟
责编 | 郑丽媛
出品丨新程序员编辑部

在ChatGPT横空出世之前,我们曾以为,创作型工作不容易被AI取代,如绘画、编曲、写作和编码等。
但早在1980年,莫拉维克悖论就否定了这个传统看法:人类独有的高阶智慧能力,比如推理,只需要很少的计算能力;但人类无意识的技能和直觉,比如感知,却需要非常巨大的算力——从理论上来说,利用大模型助力智力型创造(写代码),更为容易。
那么,实际情况如何?如图1所示,当今全球最顶尖的AI公司OpenAI,它的技术发展路线从2018年到2024年、从GPT-1一直到GPT-4,可以看到GPT系列中代码相关产品占3项,足见其在代码领域落地更广泛。
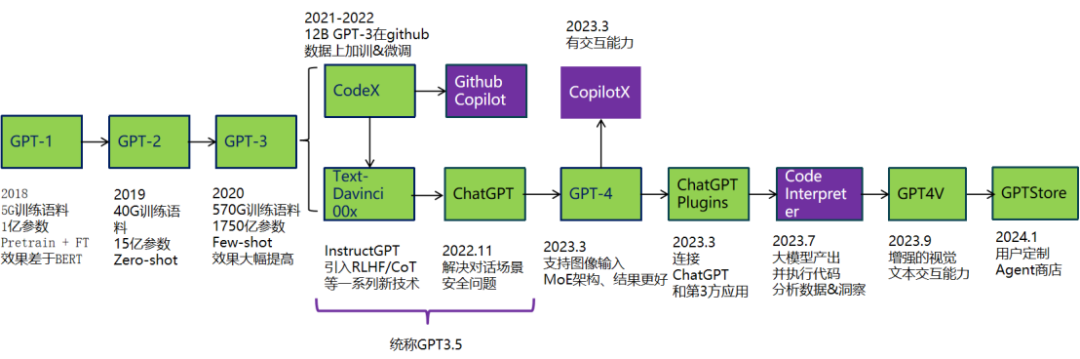
图1 OpenAI从2018年到2024年的技术发展路线
OpenAI曾对超过2000名开发者进行了调研,调查结果显示:使用大模型后,74%的人可以更专注于更具挑战性或更让人满意的工作,88%的人认为提高了生产效率,96%的人觉得在一些重复性任务上更快——从统计学上来说,这个调查结果是有意义的,它证明在实践中大模型确实可以帮助我们写代码、助力研发。

大模型与研发活动
在研发提效的路径选择上,实际上有“提升个人”和“提升大模型”两种选择,为何我们要选择大模型这条路?我认为是这样的:
信息技术发展需要人才与软硬件设备的同时进步。随着摩尔定律发展,硬件设备已取得巨大进步,而软件开发是一种智力劳动密集型的群体协同活动,关键在于优秀程序员。
传统的研发工程实践依赖于个人的能力和意愿,而提升个人能力是一个漫长的过程且难以标准化。
大模型能力提升遵循AI摩尔定律:每年LLM大小增长10倍,人工智能每18个月翻一番。
与其提升个人能力,不如提升大模型,因为大模型更具扩展性。况且一个大模型开发好了,所有人都可以用,相较之下培养几千几万名优秀程序员则相对困难。
在这样的认知下,现在业内基本上达成了一致共识:研发模式的基点正在发生变化。基础模型与生成式AI(Generative AI, GAI)工具正在重塑技术人员的工作方式,AI将改变软硬件研发工具,诞生开发工具2.0,把软件从1.0时代带向2.0时代。例如在编码方面,各种工具将从现有方式转向GAI 具,也就是“Dev Tools 2.0”。这对于我们来说是一个弯道超车的机会,打破各个环节的软件基本都被国外公司主导的现状。
提到研发模式的转变,流程中包含多个阶段,需要确定是在所有阶段都投入同等的努力,还是应该有所侧重。通过与业内诸多专家的讨论,我们确认关注点应优先放在高耗时、高频的场景上,而不是所有阶段都兼顾。
代码大模型的发展并非一蹴而就,而是学术界和工业界多方合作的结果。从2021年到现在,模型的规模越来越大,效果越来越好。实际上,大模型的发展有三要素:算法、算力和数据,这也被认为是AI核心的三要素。有些人认为大模型的成功仅仅是“大力出奇迹”,即单纯依靠算力就能解决问题,但我并不完全赞同这一观点——在我看来,这是一个量变引发质变的过程。
在这样的思考下,蚂蚁自研并发布了代码生成模型CodeFuse。

CodeFuse整体介绍
2022年,我们发布了一个GPT模型,参数规模为0.25B,仅支持Java代码行补全。尽管这只是一个小型模型,但它为我们在2023年的进展打下了基础:在2023年初,CodeFuse 1.3B、7B和13B等多个规模的模型陆续推出;到了9月份,CodeFuse开源,登顶开源代码大模型HumanEval榜单(74.4%),在BigCode状态下也表现优异。
结合CodeFuse的开发经验,想实现 IDE 代码补全功能,需要经过许多步骤。
第一步是找到合适的数据源。虽然现在有很多开源代码,例如GitHub仓库数据等等,但它们会存在很多问题,包括各语言分布不均、代码未格式化、含有缺陷或逻辑错误以及大量自动生成或重复的代码。这些问题非常之多,需花费相当大的精力去清洗数据。我们对代码质量进行了分层过滤,如图2所示,最终得到:2TB高质量代码数据,40+主流编程语言,1000万+精选代码库,3.8亿个代码文件和620亿行代码。
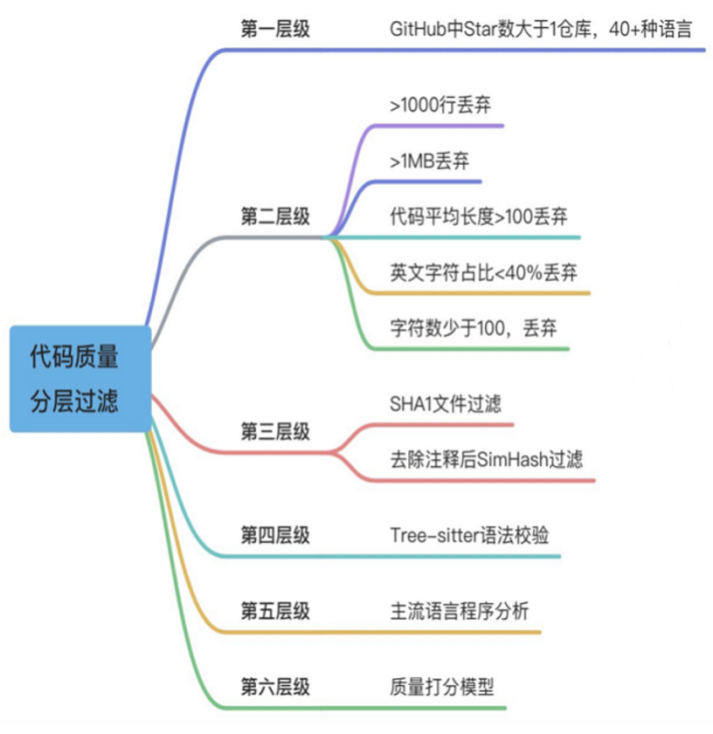
图2 对代码质量进行分层过滤
第二步是模型结构。代码大模型跟通用语言大模型有很大差异,需要在多个方面进行专门的优化和改进。以CodeFuse的模型结构来说,我们对代码领域进行了专业定制、GPT-3多项优化、安全保障和创新的指令微调,包括多任务微调M FT、低资源PEFT微调技术和测试反馈强化学习RLTF,如图3所示。
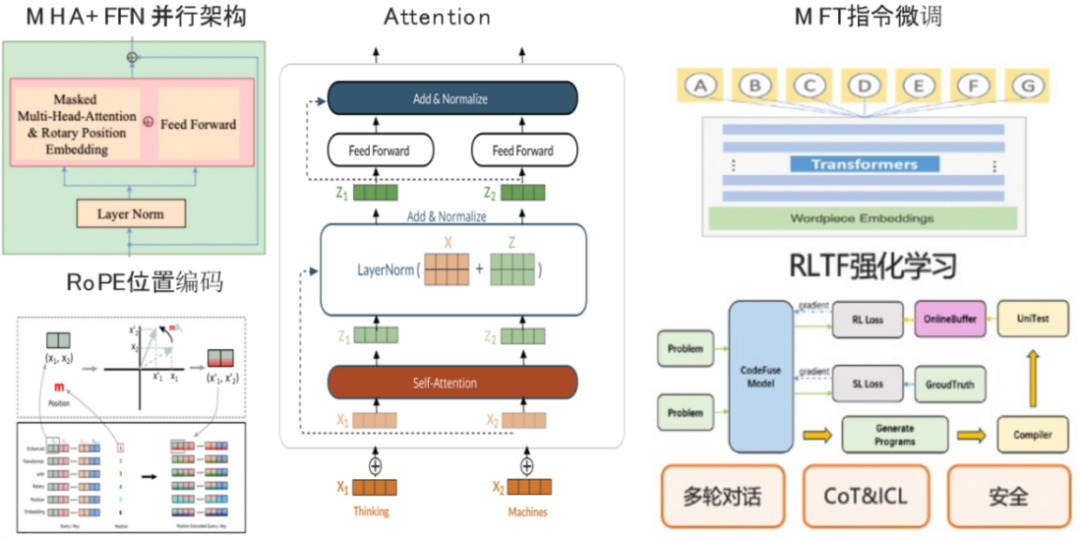
图3 CodeFuse模型结构
有了数据,有了模型结构,第三步就是预训练微调。当时我们大约使用了几百张显卡,成功训练出了我们的模型。在从0到1构建大模型时,除了要求GPU性能优秀之外,还可能出现数据尚未加载完成,训练就已经开始等各种情况。出现这些问题背后的根本原因在于,在早期GPT时代,很少有公司具备利用大规模GPU集群同时训练一个任务的最佳实践和基础设施。随着最近几年的发展,这一领域才逐渐成熟起来。
模型方面的准备工作完成后,最终我们要考虑的是产品落地——我的观点是:不要以为有了代码大模型作为基础,产品就能够顺利落地,这二者之间绝不是等同的关系。
从代码大模型到最终产品的落地过程中,有许多关键步骤和挑战需逐个攻破。
挑战1:代码底座大模型需要证明其代码能力(打榜),并要求生成代码符合逻辑。通常的解决方案是对模型进行预训练+MFT微调。
挑战2:自回归训练从左往右,模型只能普通续写,无法利用上下文代码进行填空。解决方案是利用FIM(Fill In the Middle)这种方式训练,即可充分利用上下文的代码信息。
挑战3:在自适应粒度方面,由于常规训练无代码语法,停止位置不可控。解决方案是通过BlockFIM完全丢弃规则前后处理,自适应决策代码生成粒度,以此让模型自主停止。
挑战4:单文件感知范围有限,业务逻辑不准。解决方案是用RepoFuse仓库级补全,实现仓库级感知,为模型提供更多信息,以此找到正确的业务定义。
挑战5:在推理部署这个环节,响应速度敏感,要求代码补全在几百ms以内,解决办法是通过ModelOps技术加速。

CodeFuse在蚂蚁的落地
在蚂蚁内部,我们在CodeFuse项目的落地方面采取了系统化思路,如图4所示。首先,需要依赖底层的大模型和相关基础设施,然后在此基础上构建核心能力,最终实现产品化和应用落地。
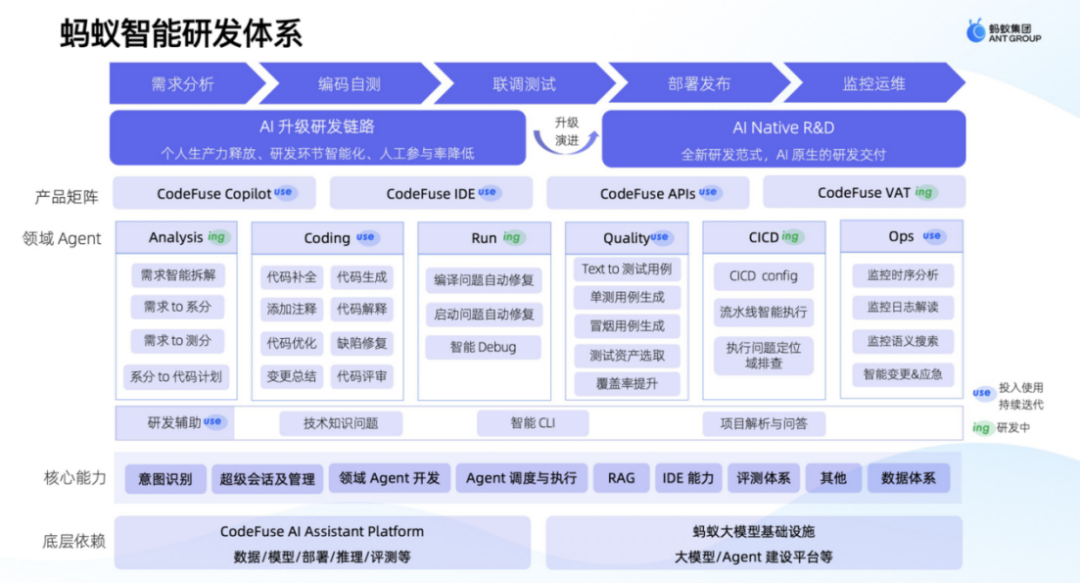
图4 基于CodeFuse蚂蚁研发体系
首先是底层依赖。在大模型及其训练数据上,我们依赖于高质量的大模型和训练数据,包括模型、训练、部署以及推理框架。在基础设施上,我们运用了蚂蚁大模型基础设施和智能平台,确保大模型的稳定运行和高效部署。
在底层依赖之上,我们构建了意图识别、超级会话管理、领域Agent开发、Agent调度与执行、RAG等一系列核心能力,支持自然语言与代码的交互,涵盖多个领域的智能化评审和IT能力。基于这些核心能力,我们可以构建各个领域的Agent,这些Agent对应着研发生命周期的不同阶段,如需求阶段、编码阶段、测试阶段、发布阶段以及监控运维阶段。
基于上述核心能力和架构,我们开发了四个主要产品,形成了完整的产品矩阵:
CodeFuse Copilot:一种为研发同学打造的IDE插件,支持13种IDE和40余种编程语言,具备实时代码补全、自然语言生成代码、代码注释生成解释、代码生成单测等功能,帮助开发者高效编码。
CodeFuse IDE:云端IDE,利用AI大模型重塑整个IDE功能,使开发者与AI交互更加便捷。
CodeFuse API:开放API,为各个研发平台提供AI升级服务,已接入147个平台。
CodeFuse VAT:一个端到端的智能交付平台,由AI主导研发的每个步骤,直到最后交付。
关于CodeFuse IDE,这款产品有两个重要特性:云原生和AI原生。所谓云原生,意味着它可以在云端直接使用,无需本地安装,用户可以随时随地通过网络访问;所谓AI原生,即许多关键行为不再依赖个人,而是由AI驱动。
为了更好地理解AI原生的概念,我们可以对比当前IDE中的情况。在当前的IDE中,许多关键行为都是依赖于个人的技能和经验,例如编码、调试命令、更改代码、查找错误等。而在未来的CodeFuse IDE中,我们将实现一种转变,使得这些行为不再依赖于个人,而是通过大模型来理解开发者的意图,由AI来主导并主动向开发者提供帮助。
此外,CodeFuse VAT也能从需求分析开始一直到最终交付,全程由AI主导研发过程中的每个步骤,凸显了大模型将彻底改变未来的研发模式。通过以上这些产品和服务,我们旨在推动一种全新研发范式,使得AI能自动完成从需求到交付的整个过程,进一步提升研发效率。

未来展望
从计算机萌芽时期至今,计算机的发展已经经历了很长时间,我认为可以把它分为两个不同的时代:2023年之前和2023年之后——2023年之前的计算机时代是“人理解计算机”的时代,而2023年之后,随着人工智能的迅猛发展,我们进入了“计算机理解人”的新时代。
2023年之前:“人理解计算机”的时代
在这个时代,人们需要学习计算机的基础知识,如二进制编码、操作系统、编程语言等。掌握这些知识越深,就越能让计算机按照人的意图完成各种任务。计算机在这个时代主要是工具,而人是操作者,计算机的能力受限于人的编程水平和理解能力。
2023年之后:“计算机理解人”的时代
2023年被认为是人工智能的元年,标志着计算机开始具备理解人的能力。计算机不再仅仅是按照预定程序运行的工具,而是能够理解自然语言、图片、音频和视频等复杂信息。这种转变意味着计算机能够更好地适应和响应人类的需求,未来的变化将会非常巨大。
在这两个时代之间,关键在于从确定性向概率性的转变。在人理解计算机的时代,编程是确定性的,即逻辑非常清晰且结果可预测。而在计算机理解人的时代,自然语言描述和模型输入具有模糊性,每次输入的结果可能不同,这代表了一个概率性的转变。其次,从PC时代到移动互联网时代,再到如今的智能互联网时代,每个时代都有不同的应用场景和需求,而人类的大多数角色和任务实际上也并不总是确定性的,会出现越来越多广泛和复杂的全新应用场景。
如果我们笃信这个新时代的到来,并且它才刚刚开始,那未来计算机的发展将基于以下几个关键共识:
(1)大模型能够识别一切的秘密,在于一个包含了“一切”可能模式的训练数据集。
(2)基于大数据集识别模式,大模型可通过next token进行推理、规划、行动。
(3)为了预测下一个符号,大模型必须理解这个问题,必须进行一些推理。
(4)大模型性能符合Scaling Law,与数据大小、计算量和模型参数量相关。
根据Gartner预测,到2028年,75%的企业软件工程师将使用AI助手,而2023年这个比例还不到10%。这标志着由AI增强的开发工具将快速增长,各大公司都在这一领域积极布局。
从技术上来说,我们正从传统生成式AI走向上下文感知的生成式AI。最开始的代码补全基于统计学,而大模型时代的代码补全则感知上下文,逐步从行级别扩展到文件级别、仓库级别,甚至非代码的内容。在这一发展过程中,Context变得尤为重要,它相当于GPU时代的内存,有了足够的Context,模型就可以处理更大、更复杂的问题。大体来说,Context可通过两种方式扩展:物理层面(增加模型的上下文窗口)和虚拟层面(通过摘要或嵌入来捕捉文件和仓库的信息),这两种方法都能提高模型的效果和准确性。
基于以上想法,展望未来代码大模型的发展趋势,我认为有以下两种可能:
其一,编写软件的门槛急剧降低,给机器下达指令不再是程序员的专利,人人都能用自然语言去创建应用;
其二,AI 工程师将替代人类软件工程师完成各类研发工作,届时软件开发不再是“脑力”劳动密集型行业,编写软件效率将急剧提升。
最后,对于未来我也有一些属于自己的畅想:人类的行走能力已经通过汽车、飞机进行了质的提升,极大拓展人类范围,甚至探索太空;人类的视觉能力也已经通过电子显微镜、太空望远镜进行了质的提升,可以观察原子和遥望星空;而如今,人类的理解和创造能力正通过 LLM 进行大幅提升中,且其继承和共享或许会更加高效。

大模型刷新一切,让我们有着诸多的迷茫,AI 这股热潮究竟会推着我们走向何方?面对时不时一夜变天,焦虑感油然而生,开发者怎么能够更快、更系统地拥抱大模型?《新程序员 007》以「大模型时代,开发者的成长指南」为核心,希望拨开层层迷雾,让开发者定下心地看到及拥抱未来。
读过本书的开发者这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
能学习到新知识、产生共鸣,解答久困于心的困惑,这是《新程序员》的核心价值。欢迎扫描下方二维码订阅纸书和电子书。
















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









