









 本文深入探讨了激活函数如Sigmoid、ReLU、Tanh和Softmax的特点与应用,以及交叉熵损失函数的工作原理。详细分析了不同激活函数的优缺点,如ReLU如何避免梯度消失,以及Tanh为何优于Sigmoid。同时,解释了交叉熵如何衡量预测与真实标签间的差异。
本文深入探讨了激活函数如Sigmoid、ReLU、Tanh和Softmax的特点与应用,以及交叉熵损失函数的工作原理。详细分析了不同激活函数的优缺点,如ReLU如何避免梯度消失,以及Tanh为何优于Sigmoid。同时,解释了交叉熵如何衡量预测与真实标签间的差异。
目录
-
sigmoid:
,它的导数
,
为单调递增函数。函数图像如下:
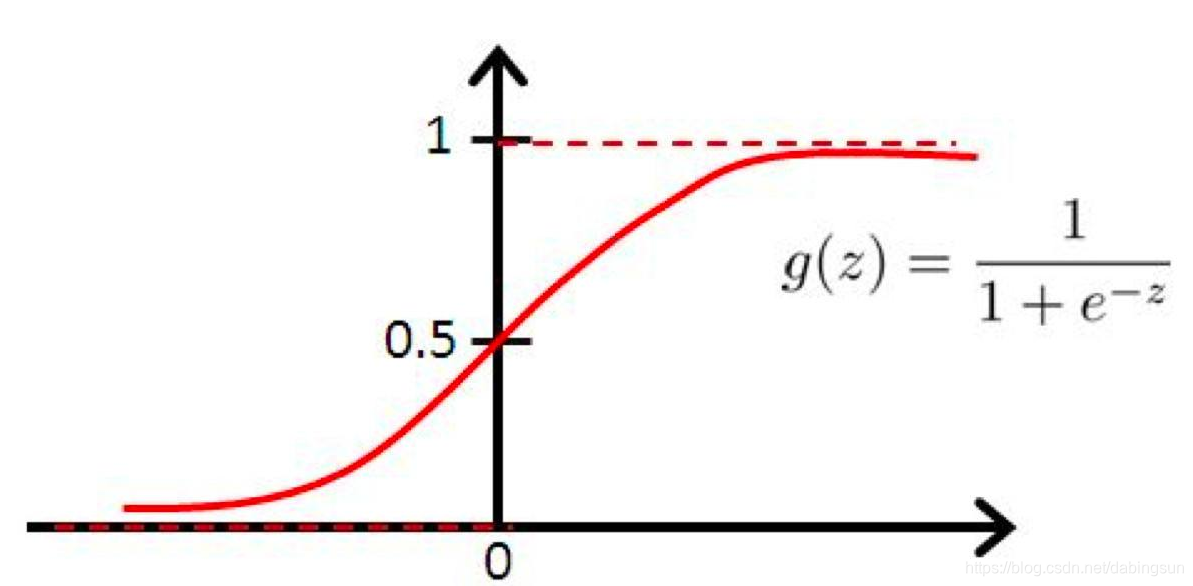
sigmoid函数的导数图如下所示:
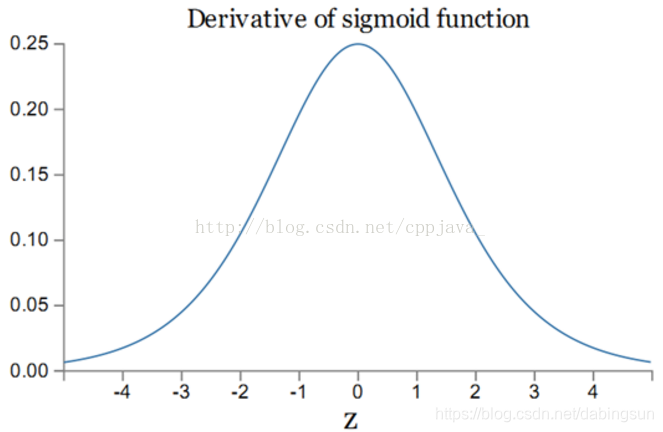
即,当层数过多时,会产生过多的
相乘,如果W足够大,则梯度会呈指数型上升,则为梯度爆炸。如果W很小,则梯度会呈指数型衰减,则为梯度衰减。一般情况|W|<1,比较容易发生梯度消失的情况。
详情:sigmoid引起的梯度消失和爆炸问题:链接
-
relu:
,即
。函数的图像如下:
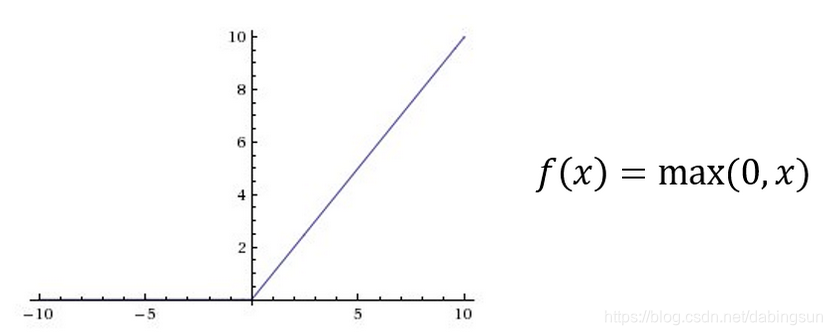
导数。当有多层时,中间每层输入都为max{0,
},反向多次求导,导数都为一个常数W。
评判:relu 可以增加网络的非线性能力,从而拟合更多的非线性过程。ReLU在一定程度上能够防止梯度消失,但防止梯度消失不是用它的主要原因,主要原因是求导数简单。一定程度是指,右端的不会趋近于饱和(变为一条横线),求导数时,导数不为零,从而梯度不消失,但左端问题依然存在,一样掉进去梯度也会消失。所以出现很多改进的ReLU。
-
tanh
公式:,导数
,
- tanh关于原点对称,相比Sigmoid函数,其输出以0为中心,因此实际应用中 tanh 会比 sigmoid 更好,因为 tanh 的输出均值比 sigmoid 更接近 0。
- 比Sigmoid函数收敛速度更快。
- 但也含有sigmoid的缺点。
-
softmax:
,对向量每个元素进行exp(),然后求和,归一化处理。目的是凸显其中最大的值并抑制远低于最大值的其他分量。Softmax函数的优势在于所有输出概率的总和为1。
-
交叉熵Cross entropy:
。此处
为概率值在(0,1)范围,
为真实标签,在tensorflow中以one-hot编码形式表示标签。在真实标签时,预测概率越接近1,ln值越接近0,最后的损失就越小,相反,则损失就越大。

















 5919
5919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









