







前言
本篇部署的spark模式是local模式,所以就只在node1机器上部署。食用之前,请确保安装了Anaconda。
一、安装spark
前提条件
- python推荐3.8版本
- JDK1.8版本
- hadoop3.x以上
下载网址:https://dlcdn.apache.org/spark
我目前使用的版本是spark-3.2.0-bin-hadoop3.2.tgz,下载链接为:
链接:https://pan.baidu.com/s/1ZmarnyvBzHESBMXRBnri4g?pwd=d094
提取码:d094
1、上传安装包
将文件上传到安装路径中,我这里是/export/servers。
2、解压
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz
名字有点长,我们设置个别名,当然你也可以用mv命令进行改名
#设置别名(快捷方式)
ln -s /export/servers/spark-3.2.0-bin-hadoop3.2 /export/servers/spark-3.2.0
#重命名
mv spark-3.2.0-bin-hadoop3.2 spark-3.2.0
补充:
重命名:更直观地显示文件或目录的名称,不会影响原来的名称,但如果文件或目录已经存在,重命名会覆盖原来的文件或目录,需要注意避免同名文件的覆盖。
别名:将文件、目录 或 命令的名称进行自定义的命名。别名可以设置多个,也可以随时修改或删除,不会影响原来的名称。但如果别名设置错误,可能会导致命令无法正常使用。
3、配置环境变量
Spark环境变量的内容就5个:
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里
1)修改配置文件
vi /etc/profile
#添加以下内容,具体安装路径以及版本号以实际为准
export JAVA_HOME=/export/servers/jdk1.8.0_241
export HADOOP_HOME=/export/servers/hadoop-3.3.0
export SPARK_HOME=/export/servers/spark-3.2.0
export PYSPARK_PYTHON=/export/servers/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#使文件生效
source /etc/profile
2)修改Bash shell配置文件
vi /root/.bashrc
#这里主要设置 java路径 和 python执行器路径。
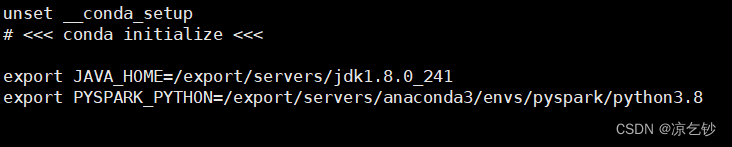
#使文件生效
source /root/.bashrc
二、测试spark环境
在测试之前,我们先了解一下spark目录下都有什么
- bin:可执行文件
- conf:配置文件
- data:数据
- examples:示例代码
- jars:spark依赖的jar包
- kubernetes:又称K8S,spark运行在K8S的依赖
- licenses:授权信息
- python:spark支持的python库
- R:spark支持的R语言库
- sbin:与超级用户相关,包含启停进程环境的相关命令
- yarn:yarn集成的相关依赖项
spark下的bin目录有:
- beeline:远程客户端
- pyspark:python类型解释器环境
- spark-shell:Scala类型解释器环境
- spark-sql:SQL类型解释器环境
- spark-submit:提交运行已经写好的示例代码
测试spark能否正常运行的方式有很多种,这里以启动pyspark程序为例。
1、使用pyspark解释器
正常情况下,如果我们要使用python解释器的话,直接输入python即可

spark提供了一个交互式的python解释器pyspark,在这里我们可以编写python类型的spark代码。
1)进入$SPARK_HOME
cd /export/servers/spark-3.2.0
2)启动pyspark
bin/pyspark #如果当前是在bin目录下,也可以写成./pyspark
补充:./pyspark --master local[*] 以全部资源去启动lcoal

3)执行代码

可以正常执行,说明spark环境能正常使用。
2、使用Web页面
刚才我们启动了pyspark进程,可以通过node1:4040去到web监控页面上,查看详细信息。
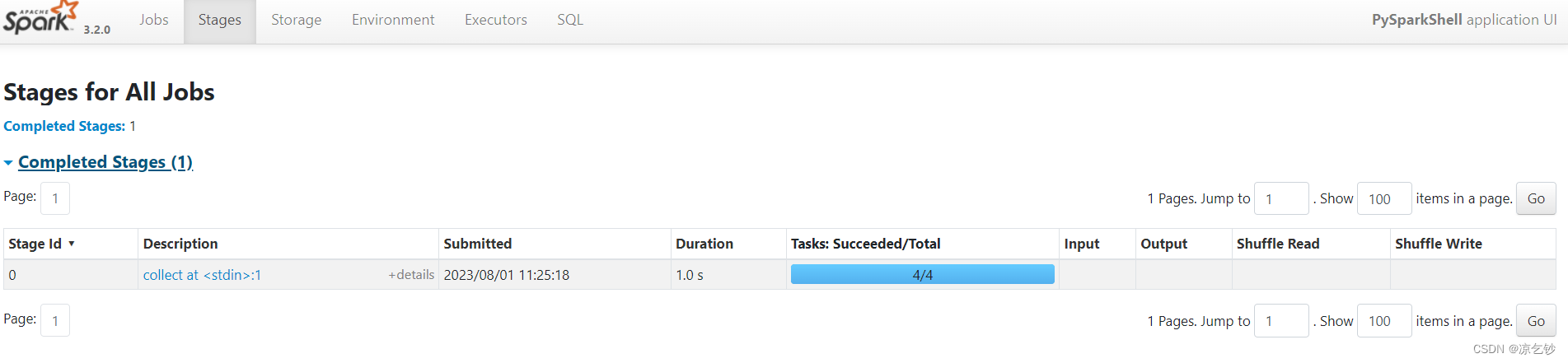
拓展:如果我的node1(Driver所在机器)同时启动两个进程,能否在4040端口页面上同时看到两个进程?答案是肯定不行,local模式下的spark进程是相互独立的,1个进程只能处理一类任务,如果发生端口冲突,会改变端口号来显示监控界面。如我同时启动pyspark和spark-shell,则很可能是node1:4040上显示pyspark的情况,node1:4041显示spark-shell的情况。
其它文章:
Spark环境搭建部署全流程,看这一篇就够了














 185
185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









