







 本文深入探讨了HashMap和HashSet的实现原理,解释了HashMap如何使用哈希算法存储和检索键值对,以及HashSet如何利用相同的机制存储唯一元素。文章还详细介绍了HashMap的初始容量、负载因子以及哈希冲突的解决策略。
本文深入探讨了HashMap和HashSet的实现原理,解释了HashMap如何使用哈希算法存储和检索键值对,以及HashSet如何利用相同的机制存储唯一元素。文章还详细介绍了HashMap的初始容量、负载因子以及哈希冲突的解决策略。
Map 是 Key-Value 对映射的抽象接口,该映射不包括重复的键,即一个键对应一个值。HashMap 是 Java Collection Framework 的重要成员,也是Map族(如下图所示)中我们最为常用的一种。简单地说,HashMap 是基于哈希表的 Map 接口的实现,以 Key-Value 的形式存在,即存储的对象是 Entry (同时包含了 Key 和 Value) 。在HashMap中,其会根据hash算法来计算key-value的存储位置并进行快速存取。特别地,HashMap最多只允许一条Entry的键为Null(多条会覆盖),但允许多条Entry的值为Null。此外,HashMap 是 Map 的一个非同步的实现(非线程安全)。
同样地,HashSet 也是 Java Collection Framework 的重要成员,是 Set 接口的常用实现类,但其与 HashMap 有很多相似之处。对于 HashSet 而言,其采用 Hash 算法决定元素在Set中的存储位置,这样可以保证元素的快速存取;对于 HashMap 而言,其将 key-value 当成一个整体(Entry 对象)来处理,其也采用同样的 Hash 算法去决定 key-value 的存储位置从而保证键值对的快速存取。虽然 HashMap 和 HashSet 实现的接口规范不同,但是它们底层的 Hash 存储机制完全相同。实际上,HashSet 本身就是在 HashMap 的基础上实现的。因此,通过对 HashMap 的数据结构、实现原理、源码实现三个方面了解,我们不但可以进一步掌握其底层的 Hash 存储机制,也有助于对 HashSet 的了解。
必须指出的是,虽然容器号称存储的是 Java 对象,但实际上并不会真正将 Java 对象放入容器中,只是在容器中保留这些对象的引用。也就是说,Java 容器实际上包含的是引用变量,而这些引用变量指向了我们要实际保存的 Java 对象。
-
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
初始容量 (16)和 负载因子(0.75)(负载因子就是指填充到多少开始扩大容量),这两个参数是影响HashMap性能的重要参数。其中,容量表示哈希表中桶的数量 (table 数组的大小),初始容量是创建哈希表时桶的数量;负载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小,。
为什么初始为16为了从Key映射到HashMap数组的对应位置,Hash函数index = Hash(“apple”)实现一个尽量均匀分布的Hash函数过利用Key的HashCode值来做按位运算。(相关位运算都是二进制运算直接在CPU的直接支持操作硬件设置寄存器内的二进制位(速度比较快但是不多用))
index = HashCode(Key) & (Length - 1)
以值为“book”的Key来演示整个过程:
1.计算book的hashcode,结果为十进制的3029737,二进制的101110001110101110 1001。
2.假定HashMap长度是默认的16,计算Length-1的结果为十进制的15,二进制的1111。
3.把以上两个结果做与运算,101110001110101110 1001 & 1111 = 1001,十进制是9,所以 index=9。
可以说,Hash算法最终得到的index结果,完全取决于Key的Hashcode值的最后几位。
长度16或者其他2的幂,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
HashMap数组每一个元素的初始值都是Null。

对于HashMap,我们最常使用的是两个方法:Get 和 Put。
1.Put方法的原理
调用Put方法的时候发生了什么呢?
比如调用 hashMap.put("apple", 0) ,插入一个Key为“apple"的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index):
index = Hash(“apple”)
假定最后计算出的index是2,那么结果如下:

但是,因为HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash函数也难免会出现index冲突的情况。比如下面这样:
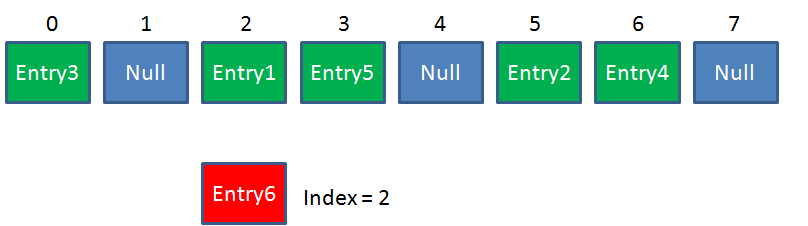
这时候该怎么办呢?我们可以利用链表来解决。
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:
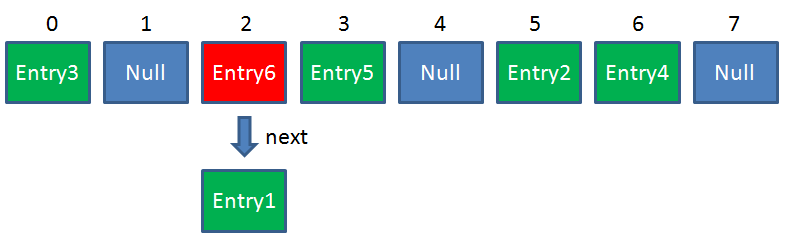
需要注意的是,新来的Entry节点插入链表时,使用的是“头插法”。(用头插法是因为当初的设计者觉得查找后插入的数据可能性大所以这样可以提高查找效率)
Get方法的原理
使用Get方法根据Key来查找Value的时候,发生了什么呢?
首先会把输入的Key做一次Hash映射,得到对应的index:
index = Hash(“apple”)
由于刚才所说的Hash冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key是“apple”:
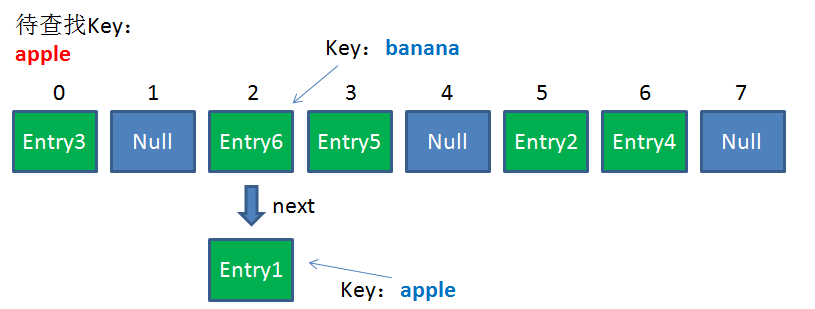
第一步,我们查看的是头节点Entry6,Entry6的Key是banana,显然不是我们要找的结果。
第二步,我们查看的是Next节点Entry1,Entry1的Key是apple,正是我们要找的结果。
之所以把Entry6放在头节点,是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。

















 1595
1595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









