






一、数据的划分和介绍









数据集介绍
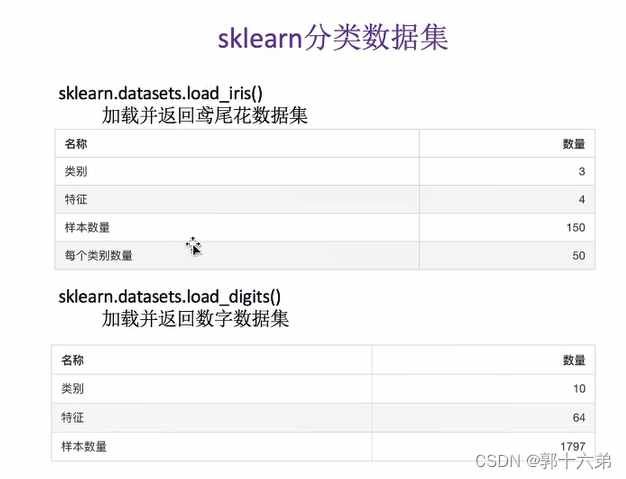
- 名称: Iris数据集
- 来源: UCI机器学习库
- 大小: 150个样本,4个特征
- 用途: 多分类
特征描述
- 萼片长度(sepal length): 数值型,单位:厘米
- 萼片宽度(sepal width): 数值型,单位:厘米
- 花瓣长度(petal length): 数值型,单位:厘米
- 花瓣宽度(petal width): 数值型,单位:厘米
目标变量描述
- 种类(species): 类别型,取值为三类(Setosa, Versicolor, Virginica)
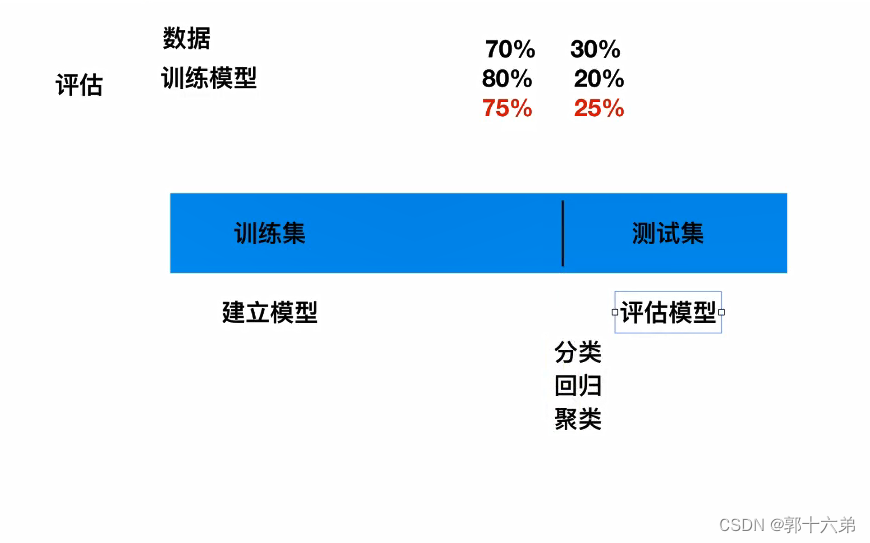
数据集划分
我们将数据集划分为训练集、验证集和测试集,比例分别为70%、15%和15%。
代码示例
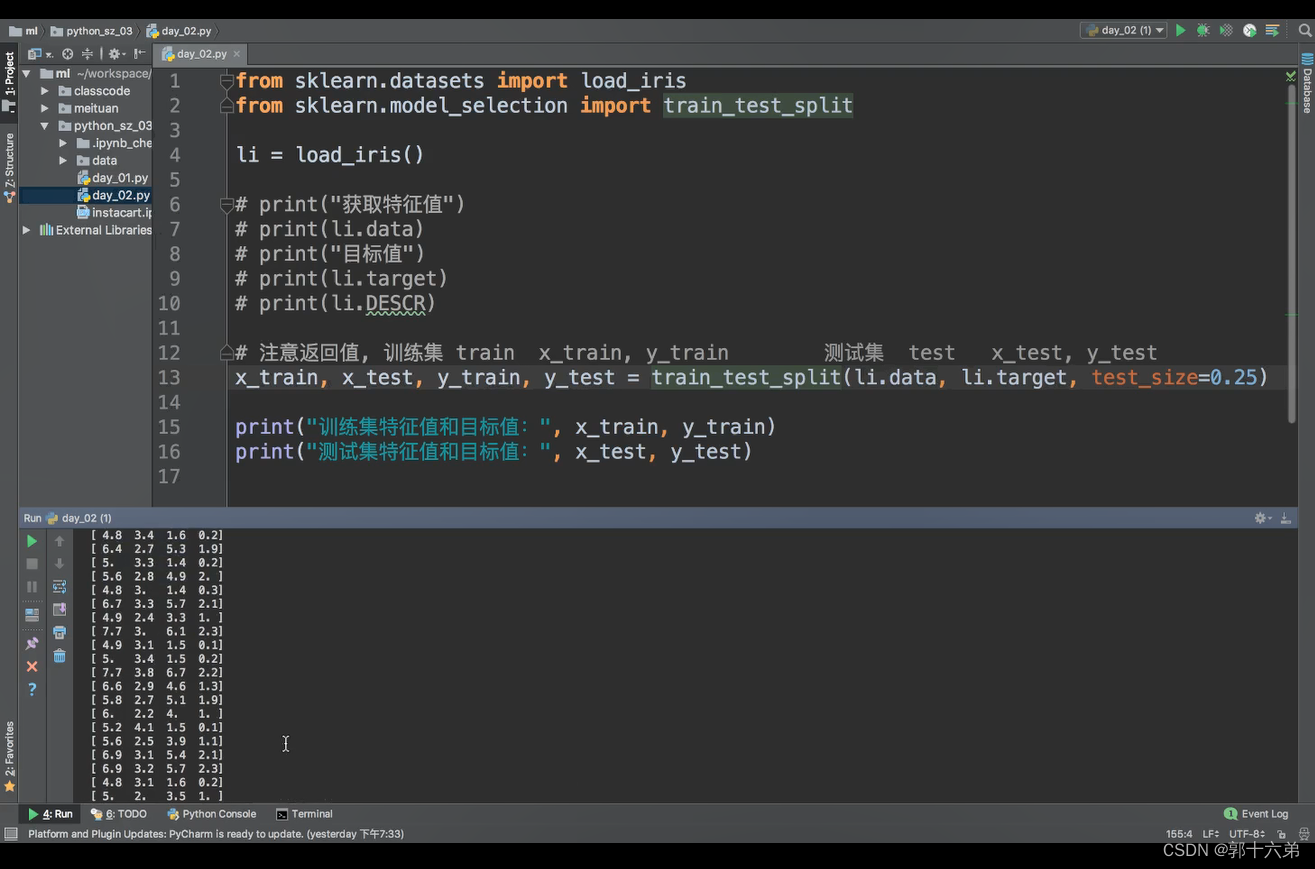
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
data = iris.data
target = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# 转换为DataFrame
df = pd.DataFrame(data, columns=feature_names)
df['species'] = target
# 数据集划分:训练集(70%)、验证集(15%)、测试集(15%)
train_data, temp_data, train_labels, temp_labels = train_test_split(data, target, test_size=0.3, random_state=42)
val_data, test_data, val_labels, test_labels = train_test_split(temp_data, temp_labels, test_size=0.5, random_state=42)
# 打印数据集信息
print("训练集大小:", train_data.shape)
print("验证集大小:", val_data.shape)
print("测试集大小:", test_data.shape)
# 数据集介绍
print("\n数据集介绍:")
print("名称: Iris数据集")
print("来源: UCI机器学习库")
print("大小: 150个样本,4个特征")
print("用途: 多分类")
# 特征描述
print("\n特征描述:")
for feature in feature_names:
print(f"{feature}: 数值型,单位:厘米")
# 目标变量描述
print("\n目标变量描述:")
print("种类(species): 类别型,取值为三类(Setosa, Versicolor, Virginica)")
输出示例
训练集大小: (105, 4)
验证集大小: (22, 4)
测试集大小: (23, 4)
数据集介绍:
名称: Iris数据集
来源: UCI机器学习库
大小: 150个样本,4个特征
用途: 多分类
特征描述:
sepal length (cm): 数值型,单位:厘米
sepal width (cm): 数值型,单位:厘米
petal length (cm): 数值型,单位:厘米
petal width (cm): 数值型,单位:厘米
目标变量描述:
种类(species): 类别型,取值为三类(Setosa, Versicolor, Virginica)
二、转换器与估计器
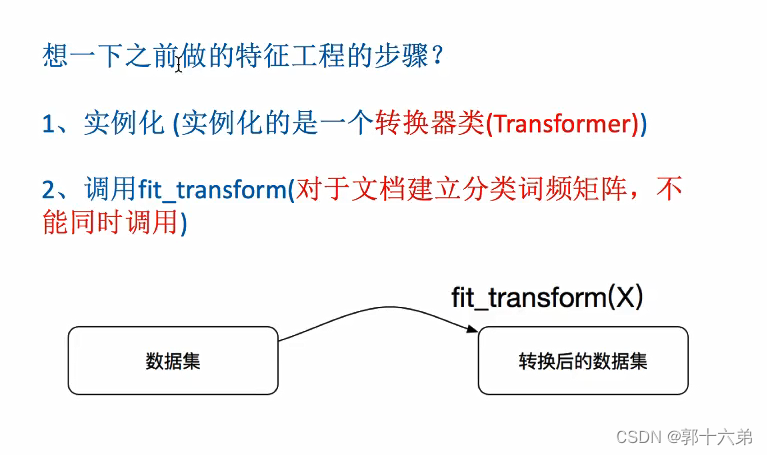
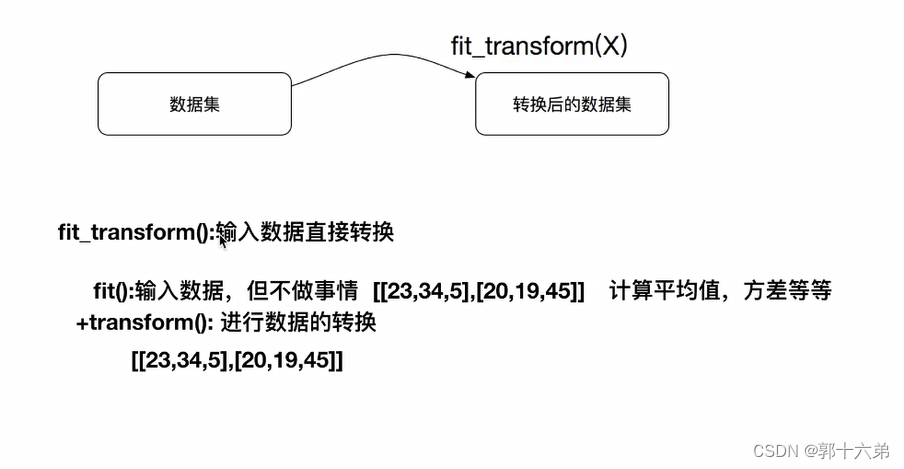

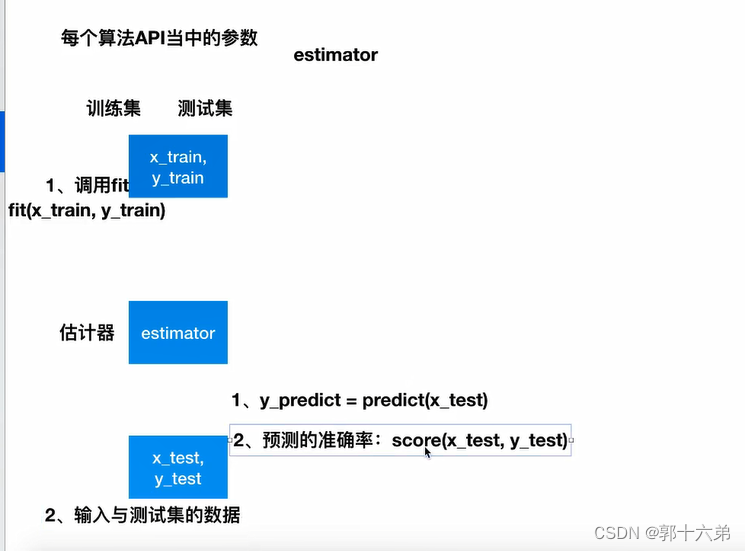
在机器学习中,转换器(Transformers)和估计器(Estimators)是两个常见的概念,特别是在使用scikit-learn库时。这些概念帮助我们理解如何处理数据和训练模型。下面是它们的通俗解释和总结。
转换器(Transformers)
通俗解释
转换器是用于预处理数据的一种工具。它们可以对数据进行转换,如标准化、归一化、特征提取等。你可以把它们想象成数据的“加工器”,帮助将原始数据转化为更适合模型训练的格式。
例子
-
标准化(Standardization):
- 把数据缩放到均值为0、标准差为1的范围。
- 类比:将不同单位的数据(比如身高和体重)转换到同一个标准,方便比较。
-
特征提取(Feature Extraction):
- 从文本中提取关键词或从图像中提取特征向量。
- 类比:从一篇文章中挑出关键词来概括内容。
from sklearn.preprocessing import StandardScaler
# 创建标准化转换器
scaler = StandardScaler()
# 使用fit方法计算训练集的均值和标准差
scaler.fit(train_data)
# 使用transform方法对训练数据进行标准化
train_data_scaled = scaler.transform(train_data)
# 对测试数据进行同样的标准化
test_data_scaled = scaler.transform(test_data)
估计器(Estimators)
通俗解释
估计器是用于训练机器学习模型的工具。它们可以基于训练数据建立模型,然后用这个模型对新数据进行预测。你可以把它们想象成数据的“学习者”,通过学习历史数据来预测未来的数据。
例子
-
线性回归(Linear Regression):
- 建立一个线性模型来预测数值。
- 类比:根据过去的销售数据预测未来的销售额。
-
分类算法(如k近邻算法):
- 根据特征预测数据所属的类别。
- 类比:根据病人的症状预测病人的病情。
from sklearn.linear_model import LinearRegression
# 创建线性回归估计器
model = LinearRegression()
# 使用fit方法训练模型
model.fit(train_data, train_labels)
# 使用predict方法进行预测
predictions = model.predict(test_data)
总结
转换器与估计器的主要区别
-
转换器(Transformers):
- 主要用于数据预处理。
- 常用方法:
fit(计算数据的统计信息),transform(转换数据),fit_transform(一次性完成计算和转换)。
-
估计器(Estimators):
- 主要用于训练和评估机器学习模型。
- 常用方法:
fit(训练模型),predict(预测数据),score(评估模型性能)。
共同点
- 都有
fit方法,用于学习数据的统计信息或模型参数。 - 都是scikit-learn库中的重要组成部分。
通过了解和使用转换器与估计器,我们可以更好地处理数据和训练模型,提升机器学习项目的效果和效率。
三、机器学习算法分类以及开发流程

 、
、















机器学习算法分类
根据学习方式分类
-
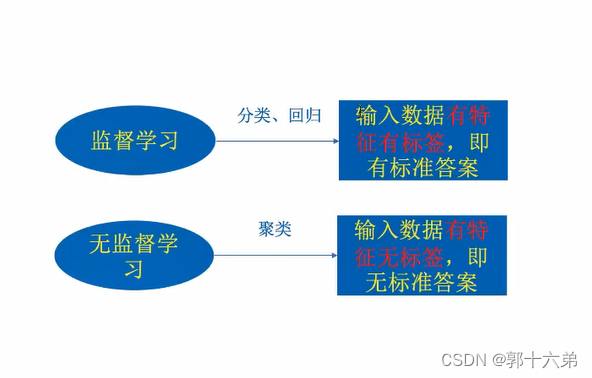
监督学习(Supervised Learning)
- 定义:通过已标记的训练数据学习映射函数,用于预测未知数据的标签。
- 常见算法:
- 线性回归(Linear Regression)
- 逻辑回归(Logistic Regression)
- 支持向量机(SVM)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- K近邻(K-Nearest Neighbors, KNN)
- 神经网络(Neural Networks)
-
无监督学习(Unsupervised Learning)
- 定义:通过未标记的训练数据发现数据的内在结构和模式。
- 常见算法:
- K均值聚类(K-Means Clustering)
- 层次聚类(Hierarchical Clustering)
- 主成分分析(Principal Component Analysis, PCA)
- 独立成分分析(Independent Component Analysis, ICA)
- 高斯混合模型(Gaussian Mixture Model, GMM)
- 自编码器(Autoencoders)
-
半监督学习(Semi-Supervised Learning)
- 定义:通过少量已标记数据和大量未标记数据进行学习。
- 常见算法:
- 半监督SVM(Semi-Supervised SVM)
- 图半监督学习(Graph-Based Semi-Supervised Learning)
-
强化学习(Reinforcement Learning)
- 定义:通过与环境的互动学习策略,以最大化累积奖励。
- 常见算法:
- Q学习(Q-Learning)
- 深度Q网络(Deep Q-Network, DQN)
- 策略梯度(Policy Gradient)
- 近端策略优化(Proximal Policy Optimization, PPO)
根据任务类型分类
-
分类(Classification)
- 定义:将输入数据分配到预定义的类别中。
- 常见算法:逻辑回归、SVM、决策树、随机森林、KNN、神经网络
-
回归(Regression)
- 定义:预测连续数值型变量。
- 常见算法:线性回归、支持向量回归(SVR)、决策树回归、随机森林回归、神经网络
-
聚类(Clustering)
- 定义:将数据分组为若干类,使得同类数据的相似度最大,不同类数据的相似度最小。
- 常见算法:K均值聚类、层次聚类、GMM
-
降维(Dimensionality Reduction)
- 定义:将高维数据转换为低维数据,同时保留尽可能多的重要信息。
- 常见算法:PCA、t-SNE、UMAP
-
生成模型(Generative Models)
- 定义:学习数据的分布,并从中生成新的数据样本。
- 常见算法:生成对抗网络(GAN)、变分自编码器(VAE)
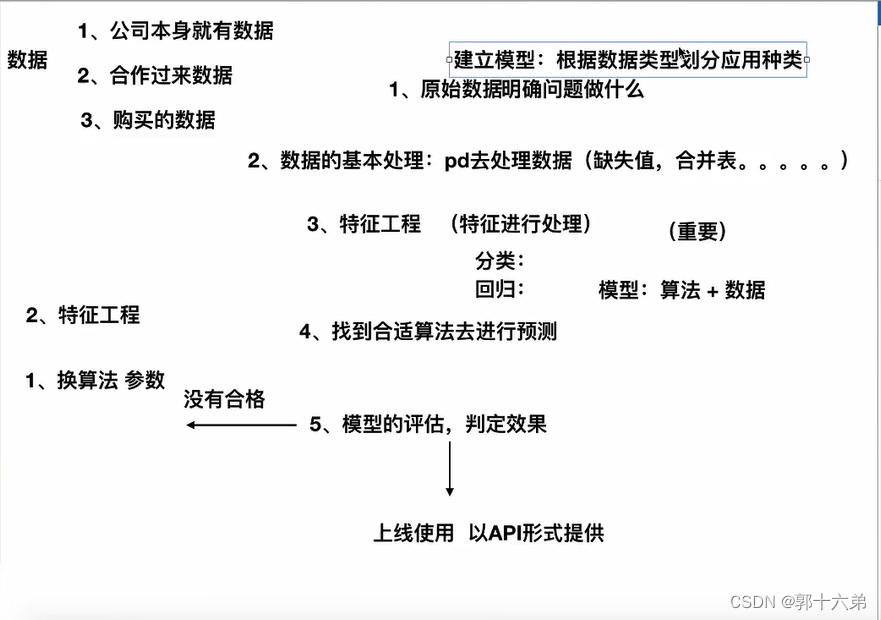
机器学习开发流程
-
定义问题和目标
- 明确业务需求和问题背景
- 定义模型的目标(分类、回归、聚类等)
-
收集和准备数据
- 收集数据:从数据库、API、传感器等获取原始数据
- 数据预处理:清洗数据、处理缺失值、异常值检测和处理
- 特征工程:特征选择、特征提取、特征缩放
-
选择模型
- 根据问题类型选择合适的算法(分类、回归、聚类等)
- 考虑模型的复杂度和解释性
-
分割数据
- 将数据集分为训练集、验证集和测试集
- 常见的分割比例为70/20/10或80/10/10
-
训练模型
- 使用训练集训练模型
- 调整超参数,优化模型性能
-
验证和调优
- 使用验证集评估模型性能
- 调整模型参数和超参数,防止过拟合和欠拟合
-
测试模型
- 使用测试集评估最终模型性能
- 确保模型在未见数据上的泛化能力
-
模型部署
- 将训练好的模型部署到生产环境中
- 考虑模型的实时性、响应时间和可扩展性
-
监控和维护
- 监控模型在生产环境中的性能
- 定期更新模型,处理数据漂移和概念漂移
- 收集新数据,重新训练和调优模型
-
文档和报告
- 编写详细的技术文档和用户指南
- 向相关人员汇报模型的性能和应用效果
总结
机器学习算法可以根据学习方式和任务类型进行分类,常见的有监督学习、无监督学习、半监督学习和强化学习等。开发流程包括定义问题、收集数据、选择模型、训练和评估模型、模型部署以及监控和维护等步骤。这些步骤确保了机器学习模型能够有效解决实际问题并在生产环境中稳定运行。















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









