







问题:
-
在系统启动时,ARM Linux内核如何知道系统中有多大的内存空间?
答: 通过从DTS配置文件中的memory 字段获取reg的大小得到内存空间大小
-
在32bit Linux内核中,用户空间和内核空间的比例通常是3:1 ,可以修改成2:2吗?
答:可以修改,可以修改config文件
-
物理内存页面如何添加到伙伴系统中,是一页一页添加,还是以2的几次幂来加入呢?
答:是通过2^n 连续物理内存块添加到伙伴系统 0<=n<=10
内存大小解析:
在ARM Vexpress平台中,内存的定义在vexpress-v2p-ca9.dts文件中:
arch/arm/boot/dts/vexpress-v2p-ca9.dts
memory@60000000 {
device_type = "memory";
reg = <0x60000000 0x40000000>;
};内存的开始地址为0x60000000, 大小为0x40000000, 即1GB大小的内存空间。
内核在启动的过程中,需要解析这些DTS文件,实现代码在
start_kernel()->setup_arch()->setup_machine_fdt()->early_init_dt_scan_nodes()->early_init_dt_scan_memory()
/**
* early_init_dt_scan_memory - Look for an parse memory nodes
*/
int __init early_init_dt_scan_memory(unsigned long node, const char *uname,
int depth, void *data)
{
const char *type = of_get_flat_dt_prop(node, "device_type", NULL);
const __be32 *reg, *endp;
int l;
/* We are scanning "memory" nodes only */
if (type == NULL) {
/*
* The longtrail doesn't have a device_type on the
* /memory node, so look for the node called /memory@0.
*/
if (!IS_ENABLED(CONFIG_PPC32) || depth != 1 || strcmp(uname, "memory@0") != 0)
return 0;
} else if (strcmp(type, "memory") != 0)
return 0;
reg = of_get_flat_dt_prop(node, "linux,usable-memory", &l);
if (reg == NULL)
reg = of_get_flat_dt_prop(node, "reg", &l);
if (reg == NULL)
return 0;
endp = reg + (l / sizeof(__be32));
pr_debug("memory scan node %s, reg size %d, data: %x %x %x %x,\n",
uname, l, reg[0], reg[1], reg[2], reg[3]);
while ((endp - reg) >= (dt_root_addr_cells + dt_root_size_cells)) {
u64 base, size;
base = dt_mem_next_cell(dt_root_addr_cells, ®); //解析到的物理内存基地址0x6000000
size = dt_mem_next_cell(dt_root_size_cells, ®); //内存大小0x40000000
if (size == 0)
continue;
pr_debug(" - %llx , %llx\n", (unsigned long long)base,
(unsigned long long)size);
early_init_dt_add_memory_arch(base, size);
}
return 0;
}解析"memory"描述的信息从而得到内存的base_address和size信息,最后内存块信息通过early_init_dt_add_memory_arch()->memblock_add()函数添加到memblock子系统中
int __init_memblock memblock_add(phys_addr_t base, phys_addr_t size)
{
return memblock_add_range(&memblock.memory, base, size,
MAX_NUMNODES, 0);
}**
* memblock_add_range - add new memblock region
* @type: memblock type to add new region into
* @base: base address of the new region
* @size: size of the new region
* @nid: nid of the new region
* @flags: flags of the new region
*
* Add new memblock region [@base,@base+@size) into @type. The new region
* is allowed to overlap with existing ones - overlaps don't affect already
* existing regions. @type is guaranteed to be minimal (all neighbouring
* compatible regions are merged) after the addition.
*
* RETURNS:
* 0 on success, -errno on failure.
*/
int __init_memblock memblock_add_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int nid, unsigned long flags)
{
bool insert = false;
phys_addr_t obase = base; //0x60000000
phys_addr_t end = base + memblock_cap_size(base, &size);//end = 0xa0000000
int i, nr_new;
if (!size)
return 0;
/* special case for empty array */
if (type->regions[0].size == 0) {
WARN_ON(type->cnt != 1 || type->total_size);
type->regions[0].base = base;
type->regions[0].size = size;
type->regions[0].flags = flags;
memblock_set_region_node(&type->regions[0], nid);
type->total_size = size;
return 0;
}
repeat:
/*
* The following is executed twice. Once with %false @insert and
* then with %true. The first counts the number of regions needed
* to accomodate the new area. The second actually inserts them.
*/
base = obase;
nr_new = 0;
for (i = 0; i < type->cnt; i++) {
struct memblock_region *rgn = &type->regions[i];
phys_addr_t rbase = rgn->base;
phys_addr_t rend = rbase + rgn->size;
if (rbase >= end)
break;
if (rend <= base)
continue;
/*
* @rgn overlaps. If it separates the lower part of new
* area, insert that portion.
*/
if (rbase > base) {
nr_new++;
if (insert)
memblock_insert_region(type, i++, base,
rbase - base, nid,
flags);
}
/* area below @rend is dealt with, forget about it */
base = min(rend, end);
}
/* insert the remaining portion */
if (base < end) {
nr_new++;
if (insert)
memblock_insert_region(type, i, base, end - base,
nid, flags);
}
/*
* If this was the first round, resize array and repeat for actual
* insertions; otherwise, merge and return.
*/
if (!insert) {
while (type->cnt + nr_new > type->max)
if (memblock_double_array(type, obase, size) < 0)
return -ENOMEM;
insert = true;
goto repeat;
} else {
memblock_merge_regions(type);
return 0;
}
}物理内存映射:
在内核使用内存前,需要初始化内核的页表,初始化页表主要在map_lowmem()函数中。在映射页表之前,需要把页表的页表项清零,主要在prepare_page_table()函数中实现。
start_kernel()->setup_arch()->paging_init()
*
* paging_init() sets up the page tables, initialises the zone memory
* maps, and sets up the zero page, bad page and bad page tables.
*/
void __init paging_init(const struct machine_desc *mdesc)
{
void *zero_page;
build_mem_type_table();
prepare_page_table();//清理页表
map_lowmem();//创建页表
dma_contiguous_remap();
devicemaps_init(mdesc);
kmap_init();
tcm_init();
top_pmd = pmd_off_k(0xffff0000);
/* allocate the zero page. */
zero_page = early_alloc(PAGE_SIZE);
bootmem_init();
empty_zero_page = virt_to_page(zero_page);
__flush_dcache_page(NULL, empty_zero_page);
}prepare_page_table()函数实现:清理一级页面
[paging_init()->prepare_page_table()]
static inline void prepare_page_table(void)
{
unsigned long addr;
phys_addr_t end;
/*
* Clear out all the mappings below the kernel image.
PAGE_OFFSET - the virtual address of the start of the kernel image
*/
for (addr = 0; addr < MODULES_VADDR; addr += PMD_SIZE)
// PMD_SIZE = 1 << 21(2MB). 0xC0000000 MODULES_VADDR等于PAGE_OFFSET,此地址就是内核在虚拟地址开始的位置
pmd_clear(pmd_off_k(addr));
#ifdef CONFIG_XIP_KERNEL
/* The XIP kernel is mapped in the module area -- skip over it */
addr = ((unsigned long)_etext + PMD_SIZE - 1) & PMD_MASK;
#endif
for ( ; addr < PAGE_OFFSET; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
/*
* Find the end of the first block of lowmem.
*/
end = memblock.memory.regions[0].base + memblock.memory.regions[0].size;
if (end >= arm_lowmem_limit)
end = arm_lowmem_limit;
/*
* Clear out all the kernel space mappings, except for the first
* memory bank, up to the vmalloc region.
*/
for (addr = __phys_to_virt(end);
addr < VMALLOC_START; addr += PMD_SIZE)
pmd_clear(pmd_off_k(addr));
}这里对如下3段地址调用pmd_clear()函数来清理一级页表项的内容。
-
0--MODULES_VADDR(0xbf000000)
-
MODULES_VADDR-- PAGE_OFFSET(0xc0000000)
-
arm_low_mem_limit--VMALLOC_START
如何清理一级页表项
#define PMD_SHIFT 21
#define PMD_SIZE (1UL << PMD_SHIFT)
static inline pmd_t *pmd_off_k(unsigned long virt)
{
return pmd_offset(pud_offset(pgd_offset_k(virt), virt), virt);
}
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
#define PGDIR_SHIFT 21
static inline pud_t * pud_offset(pgd_t * pgd, unsigned long address)
{
return (pud_t *)pgd;
}
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long addr)
{
return (pmd_t *)pud;
}
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
INIT_MM_CONTEXT(init_mm)
};
struct mm_struct {
......
pgd_t * pgd;
......
};
typedef unsigned long pgd_t[2];
#define pmd_clear(pmdp) \
do { \
pmdp[0] = __pmd(0); \
pmdp[1] = __pmd(0); \
clean_pmd_entry(pmdp); \
} while (0)
clean_pmd_entry函数看不懂,是汇编代码
typedef pmdval_t pmd_t;
typedef u64 pmdval_t;
以上列举出所有要使用的数据结构
首先确认swapper_pg_dir的值为多少
swapper_pg_dir = KERNEL_RAM_VADDR - PG_DIR_SIZE
#define KERNEL_RAM_VADDR (PAGE_OFFSET + TEXT_OFFSET)
TEXT_OFFSET = 0x00008000
PG_DIR_SIZE = 0x4000 (刚好1M)
PAGE_OFFSET = 0xC0000000 定义在CONFIG文件中
计算: swapper_pg_dir = (PAGE_OFFSET+TEXT_OFFSET) - PG_DIR_SIZE = 0xc0000000 + 0x00008000 - 0x4000 = 0xc0004000
swappder_pg_dir 就是一级页表的基地址
for (addr = 0; addr < MODULES_VADDR; addr += PMD_SIZE) // PMD_SIZE = 1 << 21. 0xC0000000 MODULES_VADDR等于PAGE_OFFSET,此地址就是内核在虚拟地址开始的位置
pmd_clear(pmd_off_k(addr));
for (addr = 0; addr < 0xbf000000; addr += 0x200000(2MB)){
addr = 0
pmd_clear(pmd_off_k(0))
pmd_clear(pmd_offset(pud_offset(pgd_offset_k(0), 0), 0))
pmd_clear(pmd_offset(pud_offset(0xc0004000, 0), 0))
pmd_clear(pmd_offset(0xc0004000, 0))
pmd_clear(0xc0004000)
addr = 0x200000
pmd_off_k(0x200000) = 0xc0004008
pmd_clear(0xc0004008)
从这里可以看出PGD每一项是256KB的内存空间,
}
为什么这里清理的是虚拟地址? 因为这里是线性映射map_lowmem()函数实现:创建页表
[paging_init()->map_lowmem()]
#define for_each_memblock(memblock_type, region) \
for (region = memblock.memblock_type.regions; \
region < (memblock.memblock_type.regions + memblock.memblock_type.cnt); \
region++)
/*
kernel_x_start kernel_x_end
0x60000000 0x61100000
.---------------------------------------------------------------------------------.
| | | |
'---------------------------------------------------------------------------------'
0x60000000 0x8f800000 0xa0000000
start end
*/
static void __init map_lowmem(void)
{
struct memblock_region *reg;
phys_addr_t kernel_x_start = round_down(__pa(_stext), SECTION_SIZE); // 0x60000000
phys_addr_t kernel_x_end = round_up(__pa(__init_end), SECTION_SIZE); // 0x61100000
/*以上就是内核的大小 0x1100000 = 17MB */
/* Map all the lowmem memory banks. */
for_each_memblock(memory, reg) {
phys_addr_t start = reg->base; //0x60000000
phys_addr_t end = start + reg->size; // 0xa0000000
struct map_desc map;
if (end > arm_lowmem_limit)// arm_lowmem_limit的值在后面确认,先查看 值为0x8f800000
end = arm_lowmem_limit; // end = 0x8f800000
if (start >= end)
break;
if (end < kernel_x_start) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RWX;
create_mapping(&map);
} else if (start >= kernel_x_end) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = end - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
} else {
//进入这里
/* This better cover the entire kernel */
if (start < kernel_x_start) {
map.pfn = __phys_to_pfn(start);
map.virtual = __phys_to_virt(start);
map.length = kernel_x_start - start;
map.type = MT_MEMORY_RW;
create_mapping(&map);
}
//执行这里
map.pfn = __phys_to_pfn(kernel_x_start); //内核开始地址的页帧号0x60000
map.virtual = __phys_to_virt(kernel_x_start);//映射到虚拟地址0xc0000000
map.length = kernel_x_end - kernel_x_start;// 0x1100000 (17M)
map.type = MT_MEMORY_RWX; // 0x9
create_mapping(&map); //执行create_mapping 内核映射
if (kernel_x_end < end) {
map.pfn = __phys_to_pfn(kernel_x_end); //0x61100
map.virtual = __phys_to_virt(kernel_x_end); //0xc1100000
map.length = end - kernel_x_end; //0x2e700000 (743MB)
map.type = MT_MEMORY_RW; //0xa
create_mapping(&map);/*create mapping 就是页表的映射过程*/
}
}
}
}arm_lowmem_limit的值,在vexpress 平台中,arm_lowmem_limit等于vmalloc_limit
static void * __initdata vmalloc_min =
(void *)(VMALLOC_END - (240 << 20) - VMALLOC_OFFSET);
#define VMALLOC_OFFSET (8*1024*1024)
#define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))
#define VMALLOC_END 0xff000000UL
phys_addr_t arm_lowmem_limit __initdata = 0;
void __init sanity_check_meminfo(void)
{
......
}create_mapping是页表的映射过程,需要单独分析
UMA计算机和NUMA计算机的区别:
-
UMA计算机(一致内存访问,uniform memory access)将可用内存以连续方式组织起来(可能有小的缺口)。SMP系统中的每个处理器访问各个内存区都是同样快。
-
NUMA计算机(非一致内存访问,non-uniform memory access)总是多处理器计算机。系统的各个CPU都有本地内存。可支持特别快速的访问。各个处理器之间通过总线连接起来,以支持对其他CPU的本地内存的访问,当然比访问本地内存慢些。
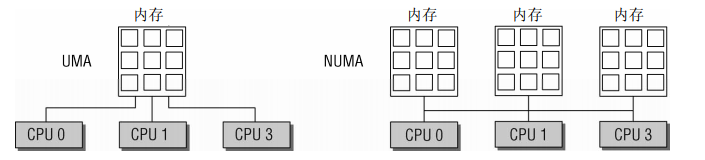
内核对一致和非一致内存访问系统使用相同的数据结构,因此针对各种不同形式的内存布局,各个算法几乎没有什么差别,在UMA系统上,只使用一个NUMA结点来管理整个系统内存。而内存管理的其他部分则相信她们是在处理一个伪NUMA系统。
NUMA系统内存划分如下图:
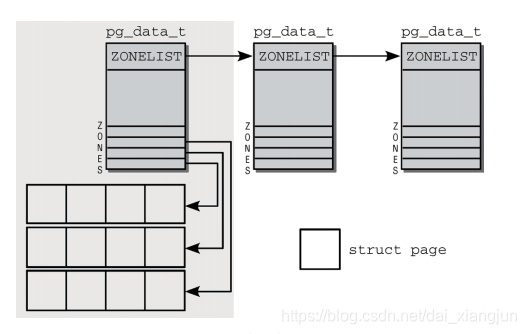
在Linux 4.0内核中pg_data_t已经不是一个链表,而是一个数组了 struct pglist_data *node_data[MAX_NUMNODES] __read_mostly;
内核引入了下列常量来枚举系统中的所有内存域:
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/* 标记适合DMA的内存域。该区域的长度依赖于处理器类型,在IA-32计算上,一般的限制16MiB,这是由古老的ISA设备强加的边界。
但更现代的计算机也可能受这一限制的影响
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/* 标记了使用32位地址字可寻址、适合DMA的内存域。显然,只有在64位系统上,两种DMA内存域才有差别。在32位计算上,本内存域是空的,即长度为0 MiB.在Alpha和
AMD64系统上,该内存域的长度可能从0到4 GiB。
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/* 标记了可直接映射到内核段的普通内存域。这是在所有体系结构上保证都会存在的唯一内存域,但无法保证该地址范围对应了实际的物理内存。例如,如果AMD64系统有2GiB
内存,那么所有内存都所都属于ZONE_DMA32范围,而ZONE_NORMAL则为空。
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/* 标记了超出内核段的物理内存
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,/*伪内存域,在防止物理内存碎片化的机制中需要使用该内存域*/
__MAX_NR_ZONES
};MAX_NR_ZONES充当结束标记,在内核想要迭代系统中的所有内存域时,会用到该常量。
各个内存域都关联了一个数组,用来组织属于该内存域的物理内存页(内核中称为页帧)。对每个页帧,都分配了一个struct page实例以及所需的管理数据。
结点管理:
pg_data_t 是用于表示结点的基本元素
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; /*包含了结点中各内存域的数据结构 DMA DMA32 NORMAL HIGHMEM等*/
struct zonelist node_zonelists[MAX_ZONELISTS];/*指定了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存*/
int nr_zones; /*结点中不同内存域的数目保存在nr_zones*/
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map;/*指向page实例数组的指针,用于描述结点的所有物理内存页。它包含了结点中所有内存域的页*/
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#ifndef CONFIG_NO_BOOTMEM
struct bootmem_data *bdata;/*在系统启动期间,内存管理子系统初始化之前,内核也需要使用内存(另外,还必须保留部分内存用于初始化内存管理子系统)*/
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn; /*是该NUMA结点第一个页帧的逻辑编号,系统中所有结点的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一)
node_start_pfn在UMA系统中总是0,因为其中只有一个结点,因此其第一个页帧编号总是0*/
unsigned long node_present_pages; /* total number of physical pages 指定了结点中页帧的数目*/
unsigned long node_spanned_pages; /* total size of physical page
range, including holes 给出了该节点以页帧为单位计算的长度,和node_paresent_pages的值不一定相同,因为结点中可能存在空洞*/
int node_id; /*全局结点ID,系统中的NUMA结点都从0开始编号*/
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_max_order;
enum zone_type classzone_idx;
#ifdef CONFIG_NUMA_BALANCING
/* Lock serializing the migrate rate limiting window */
spinlock_t numabalancing_migrate_lock;
/* Rate limiting time interval */
unsigned long numabalancing_migrate_next_window;
/* Number of pages migrated during the rate limiting time interval */
unsigned long numabalancing_migrate_nr_pages;
#endif
} pg_data_t;结点状态管理:
如果系统中结点多于一个,内核会维护一个位图,用以提供各个结点的状态信息,状态是用位掩码指定的,可使用下列值:
/*
* Bitmasks that are kept for all the nodes.
*/
enum node_states {
N_POSSIBLE, /* The node could become online at some point */
N_ONLINE, /* The node is online */
N_NORMAL_MEMORY, /* The node has regular memory */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory */
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
#ifdef CONFIG_MOVABLE_NODE
N_MEMORY, /* The node has memory(regular, high, movable) */
#else
N_MEMORY = N_HIGH_MEMORY,
#endif
N_CPU, /* The node has one or more cpus */
NR_NODE_STATES
};只有在NUMA中才用得到结点状态管理。
内存域:
对页表的初始化完成之后,内核就可以对内存进行管理了,但是内核并不是统一对待这些页面,而是采用区块的zone的方式来管理,struct zone数据结构的主要成员如下:
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];/*每个zone在系统启动时会计算出3个水位值,分别是WMARK_MIN/WMARK_LOW/WMARK_HIGH水位,
这在页面分配器和kswapd页面回收中会用到*/
/*
* We don't know if the memory that we're going to allocate will be freeable
* or/and it will be released eventually, so to avoid totally wasting several
* GB of ram we must reserve some of the lower zone memory (otherwise we risk
* to run OOM on the lower zones despite there's tons of freeable ram
* on the higher zones). This array is recalculated at runtime if the
* sysctl_lowmem_reserve_ratio sysctl changes.
*/
long lowmem_reserve[MAX_NR_ZONES];/*zone中预留的内存。*/
#ifdef CONFIG_NUMA
int node;
#endif
/*
* The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
* this zone's LRU. Maintained by the pageout code.
*/
unsigned int inactive_ratio;
struct pglist_data *zone_pgdat;/*指向内存结点*/
struct per_cpu_pageset __percpu *pageset;/*用于维护Per-CPU上的一些列页面,以减少自旋锁的争用*/
/*
* This is a per-zone reserve of pages that should not be
* considered dirtyable memory.
*/
unsigned long dirty_balance_reserve;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
#ifdef CONFIG_NUMA
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn; /*zone中开始页面的页帧号*/
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*
* Read access to managed_pages should be safe because it's unsigned
* long. Write access to zone->managed_pages and totalram_pages are
* protected by managed_page_count_lock at runtime. Idealy only
* adjust_managed_page_count() should be used instead of directly
* touching zone->managed_pages and totalram_pages.
*/
unsigned long managed_pages;/*zone中被伙伴系统管理的页面数量*/
unsigned long spanned_pages;/*zone包含的页面数量*/
unsigned long present_pages;/*zone里实际管理的页面数量。对一些体系结构来说,其值和spanned_pages相等*/
const char *name;
/*
* Number of MIGRATE_RESERVE page block. To maintain for just
* optimization. Protected by zone->lock.
*/
int nr_migrate_reserve_block;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
/*
* wait_table -- the array holding the hash table
* wait_table_hash_nr_entries -- the size of the hash table array
* wait_table_bits -- wait_table_size == (1 << wait_table_bits)
*
* The purpose of all these is to keep track of the people
* waiting for a page to become available and make them
* runnable again when possible. The trouble is that this
* consumes a lot of space, especially when so few things
* wait on pages at a given time. So instead of using
* per-page waitqueues, we use a waitqueue hash table.
*
* The bucket discipline is to sleep on the same queue when
* colliding and wake all in that wait queue when removing.
* When something wakes, it must check to be sure its page is
* truly available, a la thundering herd. The cost of a
* collision is great, but given the expected load of the
* table, they should be so rare as to be outweighed by the
* benefits from the saved space.
*
* __wait_on_page_locked() and unlock_page() in mm/filemap.c, are the
* primary users of these fields, and in mm/page_alloc.c
* free_area_init_core() performs the initialization of them.
*/
wait_queue_head_t *wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];/*管理空闲区域的数组,包含管理链表等,用于实现伙伴系统,每个数组元素都表示某种固定长度
的一些连续内存区,对于包含在每个区域中的空闲内存页的管理,free_area是一个起点*/
/* zone flags, see below */
unsigned long flags;
/* Write-intensive fields used from the page allocator 并行访问时用于对zone保护的自旋锁 */
spinlock_t lock;
ZONE_PADDING(_pad2_)
/* Write-intensive fields used by page reclaim */
/* Fields commonly accessed by the page reclaim scanner 用于对zone中LRU链表并行访问时进行保护的自旋锁*/
spinlock_t lru_lock;
struct lruvec lruvec; /*LRU链表集合*/
/* Evictions & activations on the inactive file list */
atomic_long_t inactive_age;
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
} ____cacheline_internodealigned_in_smp;在ARM Vexpress平台中,只定义CONFIG_ZONE_NORMAL和ZONE_HIGHMEM两种。
zon的初始化函数集中在bootmem_init()中完成,所以需要确定每个zone的范围。在find_limits()函数中会计算出min_low_pfn、max_low_pfn和max_pfn这3个值。其中,min_low_pfn是内存块的开始地址的页帧号0x60000,max_low_pfn = 0x8f800 表示normal区域的结束页帧号,它由arm_low_mem_limit这个变量得到,max_pfn = 0xa0000, 是内存块的结束地址的页帧号。
下面是ARM Vexpress 运行之后打印出来的zone的信息
[ 0.000000] free_area_init_node: node 0, pgdat c10ede40, node_mem_map eeffa000
[ 0.000000] Normal zone: 1520 pages used for memmap
[ 0.000000] Normal zone: 0 pages reserved
[ 0.000000] Normal zone: 194560 pages, LIFO batch:31
[ 0.000000] HighMem zone: 67584 pages, LIFO batch:15
[ 0.000000] Virtual kernel memory layout:
[ 0.000000] vector : 0xffff0000 - 0xffff1000 ( 4 kB)
[ 0.000000] fixmap : 0xffc00000 - 0xfff00000 (3072 kB)
[ 0.000000] vmalloc : 0xf0000000 - 0xff000000 ( 240 MB)
[ 0.000000] lowmem : 0xc0000000 - 0xef800000 ( 760 MB)
[ 0.000000] pkmap : 0xbfe00000 - 0xc0000000 ( 2 MB)
[ 0.000000] modules : 0xbf000000 - 0xbfe00000 ( 14 MB)
[ 0.000000] .text : 0xc0008000 - 0xc0d145ac (13362 kB)
[ 0.000000] .init : 0xc0d15000 - 0xc10b8000 (3724 kB)
[ 0.000000] .data : 0xc10b8000 - 0xc10f3608 ( 238 kB)
[ 0.000000] .bss : 0xc10f3608 - 0xc11223d8 ( 188 kB)可以看出ARM Vexpress平台分为两个zone,ZONE_NORMAL和ZONE_HIGHMEM。其中ZONE_NORMAL是从0xc000000到0xef800000 ,这个地址空间有多少个页面呢?
(0xef800000-0xc000000)/4096 = 194560
所以ZONE_NORMAL有194560个页面。另外ZONE_NORMAL的虚拟地址的结束地址是0xef800000,减去PAGE_OFFSET(0xc0000000),在加上PHY_OFFSET(0x60000000),正好等于0x8f800000,这个值等于我们之前计算出来的arm_lowmem_limit.
zone_sizes_init()函数实现:计算zone的大小,以及计算zone之间空洞大小
start_kernel()->setup_arch()->paging_init()->bootmem_init()->zone_sizes_init()
/*参数
@min: 起始pfn号,0x60000
@max_low: 最大low mem的pfn号:0x8f800
@max_high: high mem最大pfn号:0xa0000
*/
static void __init zone_sizes_init(unsigned long min, unsigned long max_low,
unsigned long max_high)
{
/*MAX_NR_ZONES = 3*/
unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES];
struct memblock_region *reg;
/*
* initialise the zones.
*/
memset(zone_size, 0, sizeof(zone_size));
/*
* The memory size has already been determined. If we need
* to do anything fancy with the allocation of this memory
* to the zones, now is the time to do it.
*/
zone_size[0] = max_low - min; // zone_size[0] = 0x8f800 - 0x60000 = 0x2f800
#ifdef CONFIG_HIGHMEM
zone_size[ZONE_HIGHMEM] = max_high - max_low; //zone_size[1] = 0xa0000 - 0x8f800 = 0x10800
#endif
/*
* Calculate the size of the holes.
* holes = node_size - sum(bank_sizes)
*/
memcpy(zhole_size, zone_size, sizeof(zhole_size));
for_each_memblock(memory, reg) {
unsigned long start = memblock_region_memory_base_pfn(reg); //0x60000
unsigned long end = memblock_region_memory_end_pfn(reg); //0xa0000
if (start < max_low) {
unsigned long low_end = min(end, max_low); // low_end = 0x8f800
zhole_size[0] -= low_end - start; // 0x2f800 - (0x8f800-0x6000) = 0
}
#ifdef CONFIG_HIGHMEM
if (end > max_low) {
unsigned long high_start = max(start, max_low); //high_start = 0x8f800
zhole_size[ZONE_HIGHMEM] -= end - high_start; // 0x10800 - (0xa0000-0x8f800) = 0
}
#endif
}
#ifdef CONFIG_ZONE_DMA
/*
* Adjust the sizes according to any special requirements for
* this machine type.
*/
if (arm_dma_zone_size)
arm_adjust_dma_zone(zone_size, zhole_size,
arm_dma_zone_size >> PAGE_SHIFT);
#endif
/*下面查看此函数实现*/
free_area_init_node(0, zone_size, min, zhole_size);
}free_area_init_node()函数实现:1.分配mem_map内存 2.初始化zone
[start_kernel()->setup_arch()->paging_init()->bootmem_init()->zone_sizes_init()->free_area_init_node()]
/*
参数说明:
@nid:numa节点,这里为0
@zones_size: 存放每个zone的大小,这里为zones_size[0] = 0x2f800(normal), zones_size[1] = 0x10800(high mem)
@node_start_pfn:numa节点的起始pfn,0x60000
@zholes_size: 空洞数组,这里都是0,zholes_size[0] = 0, zholes_size[1] = 0;
*/
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->classzone_idx);
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT, ((u64)end_pfn << PAGE_SHIFT) - 1);
#endif
/*计算这个node中所有的页数,这里即zones_size[0]+zones_size[1] = 0x40000 = 262144*/
calculate_node_totalpages(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
/*下面查看此函数实现:分配mem_map的内存空间*/
alloc_node_mem_map(pgdat);
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
/*下面查看此函数实现:初始化zone*/
free_area_init_core(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
}alloc_node_mem_map()函数实现:
[start_kernel()->setup_arch()->paging_init()->bootmem_init()->zone_sizes_init()->free_area_init_node()->alloc_node_mem_map()]
/*如果系统只有一个pglist_data对象,那么此对象下的node_mem_map即为全局对象mem_map。
此函数就是针对节点node的node_mem_map处理*/
static void __init_refok alloc_node_mem_map(struct pglist_data *pgdat)
{
/* Skip empty nodes */
/*我们这里的node_spanned_pages = 0x40000*/
if (!pgdat->node_spanned_pages)
return;
#ifdef CONFIG_FLAT_NODE_MEM_MAP //只处理平坦型内存
/* ia64 gets its own node_mem_map, before this, without bootmem */
/**/
if (!pgdat->node_mem_map) {
unsigned long size, start, end;
struct page *map;
/*
* The zone's endpoints aren't required to be MAX_ORDER
* aligned but the node_mem_map endpoints must be in order
* for the buddy allocator to function correctly.
*/
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1); //start = 0x60000
end = pgdat_end_pfn(pgdat); //end = 0xa0000
end = ALIGN(end, MAX_ORDER_NR_PAGES); // 0xa0000
/*计算需要的数组大小,主要注意end-start是页帧个数,每个页需要一个struct page对象,
所以这类是乘关系,这样得到整个node内所有以page为单位描述需要占据的内存。
这里计算出来的结果为0x800000字节,暂用8MB的空间*/
size = (end - start) * sizeof(struct page);
/*分配内存,alloc_remap()返回的是NULL。*/
map = alloc_remap(pgdat->node_id, size);
if (!map)
/*下面查看此函数实现,为mem_map分配内存,假设这里分配的起始地址为map = 0xeeffa000*/
map = memblock_virt_alloc_node_nopanic(size,
pgdat->node_id);
pgdat->node_mem_map = map + (pgdat->node_start_pfn - start);// map +(0x60000-0x60000) = 0xeeffa000
}
#ifndef CONFIG_NEED_MULTIPLE_NODES
/*
* With no DISCONTIG, the global mem_map is just set as node 0's
*/
if (pgdat == NODE_DATA(0)) {
mem_map = NODE_DATA(0)->node_mem_map; //赋值node_mem_map给全局变量mem_map
}
#endif
#endif /* CONFIG_FLAT_NODE_MEM_MAP */
}memblock_virt_alloc_node_nopanic()函数实现:为mem_map分配内存
[start_kernel()->setup_arch()->paging_init()->bootmem_init()->zone_sizes_init()->free_area_init_node()->alloc_node_mem_map()->memblock_virt_alloc_node_nopanic()]
[include/linux/bootmem.h]
static inline void * __init memblock_virt_alloc_node_nopanic(
phys_addr_t size, int nid)
{
return memblock_virt_alloc_try_nid_nopanic(size, 0, BOOTMEM_LOW_LIMIT,
BOOTMEM_ALLOC_ACCESSIBLE,
nid);
}
[mm/memblock.c]
void * __init memblock_virt_alloc_try_nid_nopanic(
phys_addr_t size, phys_addr_t align,
phys_addr_t min_addr, phys_addr_t max_addr,
int nid)
{
/*这里的align/min_addr/max_addr/nid参数均为0,只有size=0x800000*/
memblock_dbg("%s: %llu bytes align=0x%llx nid=%d from=0x%llx max_addr=0x%llx %pF\n",
__func__, (u64)size, (u64)align, nid, (u64)min_addr,
(u64)max_addr, (void *)_RET_IP_);
return memblock_virt_alloc_internal(size, align, min_addr,
max_addr, nid);
}
static void * __init memblock_virt_alloc_internal(
phys_addr_t size, phys_addr_t align,
phys_addr_t min_addr, phys_addr_t max_addr,
int nid)
{
phys_addr_t alloc;
void *ptr;
if (WARN_ONCE(nid == MAX_NUMNODES, "Usage of MAX_NUMNODES is deprecated. Use NUMA_NO_NODE instead\n"))
nid = NUMA_NO_NODE;
/*
* Detect any accidental use of these APIs after slab is ready, as at
* this moment memblock may be deinitialized already and its
* internal data may be destroyed (after execution of free_all_bootmem)
*/
if (WARN_ON_ONCE(slab_is_available()))
return kzalloc_node(size, GFP_NOWAIT, nid);
if (!align)
align = SMP_CACHE_BYTES; // 0x40 ,64字节对齐,cache line
if (max_addr > memblock.current_limit)
max_addr = memblock.current_limit;
again:
alloc = memblock_find_in_range_node(size, align, min_addr, max_addr,
nid);
if (alloc)
goto done;
if (nid != NUMA_NO_NODE) {
alloc = memblock_find_in_range_node(size, align, min_addr,
max_addr, NUMA_NO_NODE);
if (alloc)
goto done;
}
if (min_addr) {
min_addr = 0;
goto again;
} else {
goto error;
}
done:
memblock_reserve(alloc, size);
ptr = phys_to_virt(alloc);
memset(ptr, 0, size);
/*
* The min_count is set to 0 so that bootmem allocated blocks
* are never reported as leaks. This is because many of these blocks
* are only referred via the physical address which is not
* looked up by kmemleak.
*/
kmemleak_alloc(ptr, size, 0, 0);
return ptr;
error:
return NULL;
}zone的初始化函数在free_area_init_core()中。
[start_kernel()->setup_arch()->paging_init()->bootmem_init()->zone_sizes_init()->free_area_init_node()->free_area_init_core()]
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*
* NOTE: pgdat should get zeroed by caller.
*/
static void __paginginit free_area_init_core(struct pglist_data *pgdat,
unsigned long node_start_pfn, unsigned long node_end_pfn,
unsigned long *zones_size, unsigned long *zholes_size)
{
enum zone_type j;
int nid = pgdat->node_id;
unsigned long zone_start_pfn = pgdat->node_start_pfn; //0x60000
int ret;
pgdat_resize_init(pgdat); //空函数
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);
init_waitqueue_head(&pgdat->pfmemalloc_wait);
pgdat_page_ext_init(pgdat); //空函数
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;/*这里对每个zone进行了初始化DMA/DMA32/NORMAL/HIGH*/
unsigned long size, realsize, freesize, memmap_pages;
size = zone_spanned_pages_in_node(nid, j, node_start_pfn,
node_end_pfn, zones_size); //得到zones_size[j]的值
realsize = freesize = size - zone_absent_pages_in_node(nid, j,
node_start_pfn,
node_end_pfn,
zholes_size);//zone_absent_pages_in_node()函数得到zholes_size[j]的值
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize); //计算page的数量
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
printk(KERN_WARNING
" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
zone->spanned_pages = size;
zone->present_pages = realsize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;
#ifdef CONFIG_NUMA
zone->node = nid;
zone->min_unmapped_pages = (freesize*sysctl_min_unmapped_ratio)
/ 100;
zone->min_slab_pages = (freesize * sysctl_min_slab_ratio) / 100;
#endif
zone->name = zone_names[j];
spin_lock_init(&zone->lock);
spin_lock_init(&zone->lru_lock);
zone_seqlock_init(zone);
zone->zone_pgdat = pgdat;
zone_pcp_init(zone);
/* For bootup, initialized properly in watermark setup */
mod_zone_page_state(zone, NR_ALLOC_BATCH, zone->managed_pages);
lruvec_init(&zone->lruvec);
if (!size)
continue;
set_pageblock_order();
setup_usemap(pgdat, zone, zone_start_pfn, size);
ret = init_currently_empty_zone(zone, zone_start_pfn,
size, MEMMAP_EARLY);
BUG_ON(ret);
//初始化page
memmap_init(size, nid, j, zone_start_pfn);
zone_start_pfn += size;
}
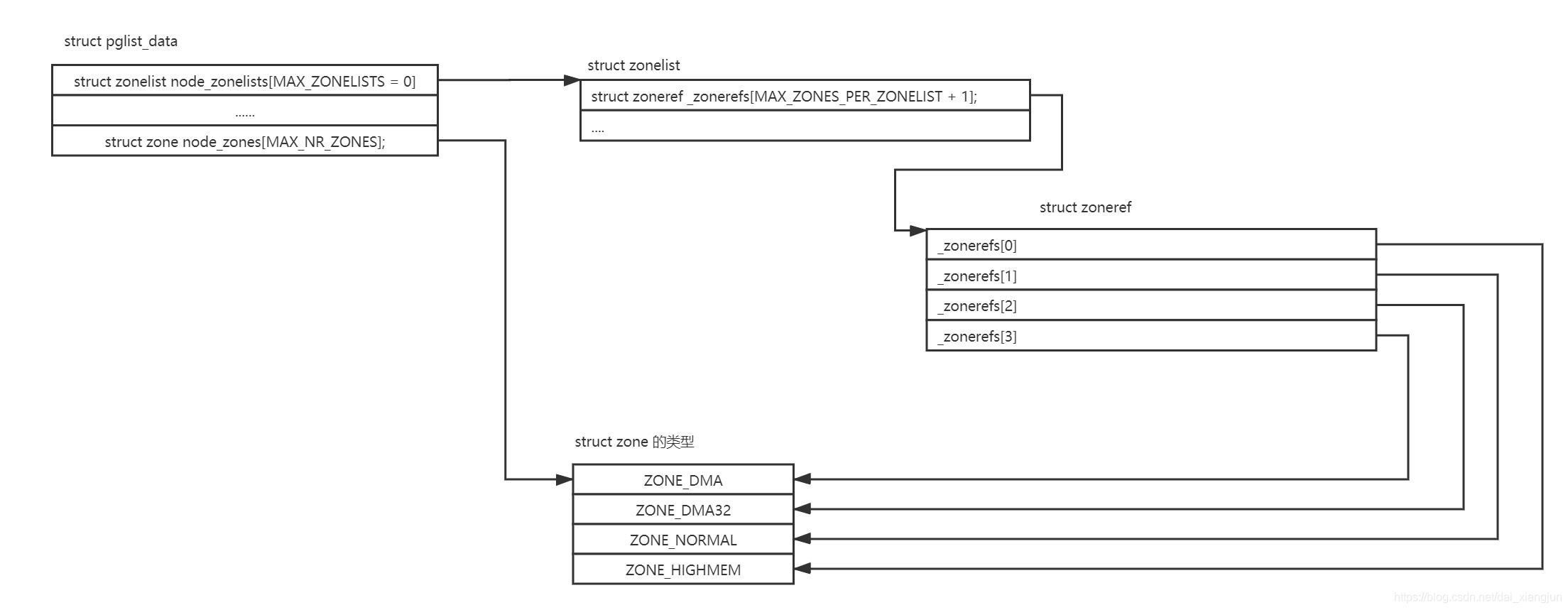
}另外系统中会有一个zonelist的数据结构,伙伴系统分配器会从zonelist开始分配内存,zonelist有一个zoneref数组,数组里有一个成员会指向zone数据结构。zoneref数组的第一个成员指向的zone是页面分配器的第一个候选者,其他成员则是第一个候选者分配失败之后考虑,优先级逐渐降低。
zonelist/zoneref数据结构如下:
/*
* This struct contains information about a zone in a zonelist. It is stored
* here to avoid dereferences into large structures and lookups of tables
*/
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
/*
* One allocation request operates on a zonelist. A zonelist
* is a list of zones, the first one is the 'goal' of the
* allocation, the other zones are fallback zones, in decreasing
* priority.
*
* If zlcache_ptr is not NULL, then it is just the address of zlcache,
* as explained above. If zlcache_ptr is NULL, there is no zlcache.
* *
* To speed the reading of the zonelist, the zonerefs contain the zone index
* of the entry being read. Helper functions to access information given
* a struct zoneref are
*
* zonelist_zone() - Return the struct zone * for an entry in _zonerefs
* zonelist_zone_idx() - Return the index of the zone for an entry
* zonelist_node_idx() - Return the index of the node for an entry
*/
struct zonelist {
struct zonelist_cache *zlcache_ptr; // NULL or &zlcache
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
#ifdef CONFIG_NUMA
struct zonelist_cache zlcache; // optional ...
#endif
};zonelist的初始化路径如下:
start_kernel()->build_all_zonelists()->build_all_zonelists_init()->__build_all_zonelists()->build_zonelists()->build_zonelists_node()
/*
* Builds allocation fallback zone lists.
*
* Add all populated zones of a node to the zonelist.
*/
static int build_zonelists_node(pg_data_t *pgdat, struct zonelist *zonelist,
int nr_zones)
{
struct zone *zone;
enum zone_type zone_type = MAX_NR_ZONES;
do {
zone_type--;
zone = pgdat->node_zones + zone_type;
if (populated_zone(zone)) {
zoneref_set_zone(zone,
&zonelist->_zonerefs[nr_zones++]);
check_highest_zone(zone_type);
}
} while (zone_type);
return nr_zones;
}static void zoneref_set_zone(struct zone *zone, struct zoneref *zoneref)
{
zoneref->zone = zone;
zoneref->zone_idx = zone_idx(zone);
}这里从最高MAX_NR_ZONES的zone开始,设置到_zonerefs[0]数组中。在ARM Vexpress平台中,该函数的运行结果如下:
HighMem _zonerefs[0]->zone_index=1
Normal _zonerefs[1]->zone_index=0
详细的初始化内存管理:
pg_data_t数据结构的初始化在UMA没有,在NUMA中才有初始化
建立数据结构:
对相关数据结构的初始化是从全局启动例程start_kernel中开始的,该例程在加载内核并激活各个子系统之后执行。对各种系统内存模式生成了一个pgdata_t实例,用于保存诸如结点中内存数量以及内存在各个内存域之间分配情况的信息。所有平台上都实现了特定于体系结构的NODE_DATA宏,用于通过结点编号,来查询与一个NUMA结点相关的pgdata_t实例。
由于大部分系统都只有一个内存结点。为确保内存管理代码是可移植的(因此它可以同样用于UMA和NUMA系统),内存在mm/bootmem.c中定义了一个pg_data_t实例(称作contig_page_data)管理所有的系统内存。根据该文件的路径名可以看出,这不是特定于CPU的实现。实际上,大多数系统结构都采用了该方案。NODE_DATA的实现现在更简单了。
<mmzone.h>
#define NODE_DATA(nid) (&contig_page_data)
尽管该宏有一个形式参数用于选择NUMA结点,但是在UMA系统中只有一个伪结点,因此总是返回同样的数据。内存页可以依赖于下述事实:系统结构相关的初始化代码将numnodes变量设置为系统中结点数目。在NUMA系统上因为只有一个结点,因此该数量是1.
结点和内存域初始化:
build_all_zonelists()建立管理结点以及内存域所需的数据结构。其中将所有工作都委托给__build_all_zonelists()
/* return values int ....just for stop_machine() */
static int __build_all_zonelists(void *data)
{
int nid;
int cpu;
pg_data_t *self = data;
#ifdef CONFIG_NUMA
memset(node_load, 0, sizeof(node_load));
#endif
if (self && !node_online(self->node_id)) {
build_zonelists(self);
build_zonelist_cache(self);
}
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
build_zonelists(pgdat);
build_zonelist_cache(pgdat);
}
/*
* Initialize the boot_pagesets that are going to be used
* for bootstrapping processors. The real pagesets for
* each zone will be allocated later when the per cpu
* allocator is available.
*
* boot_pagesets are used also for bootstrapping offline
* cpus if the system is already booted because the pagesets
* are needed to initialize allocators on a specific cpu too.
* F.e. the percpu allocator needs the page allocator which
* needs the percpu allocator in order to allocate its pagesets
* (a chicken-egg dilemma).
*/
for_each_possible_cpu(cpu) {
setup_pageset(&per_cpu(boot_pageset, cpu), 0);
#ifdef CONFIG_HAVE_MEMORYLESS_NODES
/*
* We now know the "local memory node" for each node--
* i.e., the node of the first zone in the generic zonelist.
* Set up numa_mem percpu variable for on-line cpus. During
* boot, only the boot cpu should be on-line; we'll init the
* secondary cpus' numa_mem as they come on-line. During
* node/memory hotplug, we'll fixup all on-line cpus.
*/
if (cpu_online(cpu))
set_cpu_numa_mem(cpu, local_memory_node(cpu_to_node(cpu)));
#endif
}
return 0;
}for_each_online_node 遍历了系统中所有的活动结点。由于UMA系统只有一个结点,build_zonelists()只调用了一次,就对所有的内存创建了内存域列表。NUMA系统调用该函数的次数等同于结点数目。每次调用对一个不同结点生成内存域数据。
build_zonelists()需要一个指向pgdata_t实例的指针作为参数,其中包含了结点内存配置的所有现存信息,而新建的数据结构也会放置在其中。
在UMA系统上,NODE_DATA返回config_page_data地址。
该函数的任务是,在当前处理的结点和系统中其他结点的内存域之间建立一种等级次序。接下来,依据这种次序分配内存。如果在期望的结点内存中,没有空闲内存,那么这种次序就很重要。
例子:内核想要分配高端内存。它首先企图在当前结点的高端内存域找到一个大小适当的空闲段。如果失败,则查看该结点的普通内存域。如果还是失败,则试图在该结点的DMA内存域执行分配。如果在3个本地内存域都无法找到空闲内存,则查看其他结点。在这种情况下,备选结点应该尽可能靠近主结点,以最小化由于访问非本地内存引起的性能损失。
内核定义了内存的一个层次结构,首先试图分配廉价的内存。如果失败,则根据访问速度和容量,逐渐尝试分配更昂贵的内存。
高端内存是最廉价的,因为内核没有任何部分依赖于从该内存域分配的内存。如果高端内存域用尽,对内核没有任何副作用,这也是优先分配高端内存的原因。
普通内存的情况有所不同。许多内核数据而机构必须保存在该内存域,而不能放置到高端内存域。因此如果普通内存完全用尽,那么内存会面临紧急情况。所以只要高端内存域的内存没有用尽,都不会从普通内存域分配内存。
最昂贵的是DMA内存域,因为它用于外设和系统之间的数据传输。因此从该内存域分配内存是最后一招。
内核使用pg_data_t中的zonelist数组,来表示 所描述的层次结构。
<mmzone.h>
typedef struct pglist_data {
......
struct zonelist node_zonelists[MAX_ZONELISTS];/*指定了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存*/
......
} pg_data_t;
/* Maximum number of zones on a zonelist */
#define MAX_ZONES_PER_ZONELIST (MAX_NUMNODES * MAX_NR_ZONES)
struct zonelist {
......
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
......
};node_zonelists数组对每种可能的内存域类型,都配置了一个独立的数组项、数组项包含了类型为zonelist的一个备用列表。
由于该备用列表包含所有结点的所有内存域,因此由 MAX_NUMNODES * MAX_NR_ZONES项组成,外加一个空指针标记。
建立备用层次结构的任务委托给build_zonelists,该函数为每个NUMA结点都创建了相应的数据结构。
static void build_zonelists(pg_data_t *pgdat)
{
int node, local_node;
enum zone_type j;
struct zonelist *zonelist;
local_node = pgdat->node_id;
zonelist = &pgdat->node_zonelists[0];
j = build_zonelists_node(pgdat, zonelist, 0);
/*
* Now we build the zonelist so that it contains the zones
* of all the other nodes.
* We don't want to pressure a particular node, so when
* building the zones for node N, we make sure that the
* zones coming right after the local ones are those from
* node N+1 (modulo N)
*/
for (node = local_node + 1; node < MAX_NUMNODES; node++) {
if (!node_online(node))
continue;
j = build_zonelists_node(NODE_DATA(node), zonelist, j);
}
for (node = 0; node < local_node; node++) {
if (!node_online(node))
continue;
j = build_zonelists_node(NODE_DATA(node), zonelist, j);
}
zonelist->_zonerefs[j].zone = NULL;
zonelist->_zonerefs[j].zone_idx = 0;
}
static int build_zonelists_node(pg_data_t *pgdat, struct zonelist *zonelist,
int nr_zones)
{
struct zone *zone;
enum zone_type zone_type = MAX_NR_ZONES;
do {
zone_type--;
zone = pgdat->node_zones + zone_type;
if (populated_zone(zone)) {
zoneref_set_zone(zone,
&zonelist->_zonerefs[nr_zones++]);
check_highest_zone(zone_type);
}
} while (zone_type);
return nr_zones;
}根据上述得出,_zonerefs 越靠前的内存越廉价,越靠后的内存越昂贵啊。
空间划分:
在32bit linux中,一共能使用的虚拟地址空间是4GB,用户空间和内核空间的划分通常按照3:1来划分,也可以按照2:2 来划分。
choice
prompt "Memory split"
depends on MMU
default VMSPLIT_3G
help
Select the desired split between kernel and user memory.
If you are not absolutely sure what you are doing, leave this
option alone!
config VMSPLIT_3G
bool "3G/1G user/kernel split"
config VMSPLIT_2G
bool "2G/2G user/kernel split"
config VMSPLIT_1G
bool "1G/3G user/kernel split"
endchoice
config PAGE_OFFSET
hex
default PHYS_OFFSET if !MMU
default 0x40000000 if VMSPLIT_1G
default 0x80000000 if VMSPLIT_2G
default 0xC0000000在ARM linux中有一个配置选项"memory split",可以用于调整内核空间和用户空间的大小划分。通常使用"VMSPLIT_3G"选项,用户空间大小是3GB,内核空间大小是1GB,那么PAGE_OFFSET描述内核空间的偏移就等于0xC0000000(3GB)。也可以选择"VMSPLIT_2G"选项。这时内核空间和用户空间的大小都是2GB,PAGE_OFFSET就等于0x80000000.
内核通常会使用PAGE_OFFSET这个宏来计算内核线性映射虚拟地址和物理地址的转换。
/* PAGE_OFFSET - the virtual address of the start of the kernel image */
#define PAGE_OFFSET UL(CONFIG_PAGE_OFFSET)例如,内核中用于计算线性映射的物理地址和虚拟地址的转换关系。线性映射的物理地址等于虚拟地址vaddr减去PAGE_OFFSET(0xc0000000)再减去PHYS_OFFSET(在部分ARM系统中该值为0)。
arch/arm/include/asm/memory.h
static inline phys_addr_t __virt_to_phys(unsigned long x)
{
return (phys_addr_t)x - PAGE_OFFSET + PHYS_OFFSET;
}
static inline unsigned long __phys_to_virt(phys_addr_t x)
{
return x - PHYS_OFFSET + PAGE_OFFSET;
}物理内存初始化:
在内核启动时,内核知道物理内存DDR的大小并且计算出高端内存的起始地址和内核空间的内存布局后,物理内存页面page就要加入到伙伴系统中,物理内存页面如何添加到伙伴系统中呢?
系统内存中的每个物理内存页(页帧),都对应于一个struct page实例。每个内存域都关联了一个struct zone的实例,其中保存了用于管理伙伴数据的主要数组。
struct zone {
......
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
......
};
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};nr_free指定了当前内存区中空闲页块的数目(对0阶内存区逐页计算,对1阶内存区计算页对的数目,对2阶内存区计算4页集合的数目,依次类推)。free_list是用于连接空闲页的链表。页链表包含大小相同的连续内存区。
伙伴系统是操作中最常用的一种动态存储管理方法,在用户提出申请时,分配一块大小合适的内存块给用户,反之在用户释放内存块时回收。在伙伴系统中,内存块是2的order次幂。linux内核中oder的最大值用MAX_ORDER来表示,通常是11,也就是把所有的空闲页面分组成11个内存块链表,每个内存块链表分别包括1、2、4、8、16、... 、1024个连续的页面。
第0个链表包含的内存区为单页(2^0 = 1), 第1个链表管理的内存区为两页(2^1 = 2), 第3个管理的内存区为4页,依次类推
伙伴系统中相互连接的内存区示意图:
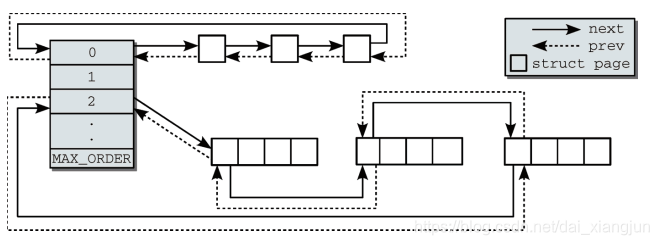
zone数据结构中的free_area数组,数组的大小是MAX_ORDER.free_area数据结构中包含了MIGRATE_TYPES个链表,这里相当于zone中根据order的大小有0到MAX_ORFER-1个free_area,每个free_area根据MIGRATE_TYPES类型有几个相应地链表。
enum {
MIGRATE_UNMOVABLE,/*不可移动页:在内存中有固定位置,不能移动到其他地方。核心内核分配的大多数内存属于该类别*/
MIGRATE_RECLAIMABLE,/*可回收页:不能直接移动,但可以删除,其内容可以从某些源重新生成。例如,映射自文件的数据属于该类别。
kswapd守护进程会根据可回收页访问的频繁度,周期性释放此类内存。这是一个复杂的过程。
*/
MIGRATE_MOVABLE,/*可移动页可以随意地移动。属于用户空间应用程序的页属于该类型。它们是通过页表映射的,如果它们复制到新位置,
页表项可以相应地更新,应用程序不会注意到任何事。
*/
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_RESERVE = MIGRATE_PCPTYPES,/*如果向具有特定可移动性的列表请求分配内存失败,这种情况下可从MIGRATE_RESERVE分配内存
对应的列表在内存子系统初始化期间用setup_zone_migrate_reserve填充。
*/
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here 是一个特殊的虚拟区域,用于跨越NUMA结点移动物理内存页。在大型系统上,
它有益于将物理内存页移动到接近于使用该页最频繁的CPU.
*/
#endif
MIGRATE_TYPES
};结构如下:
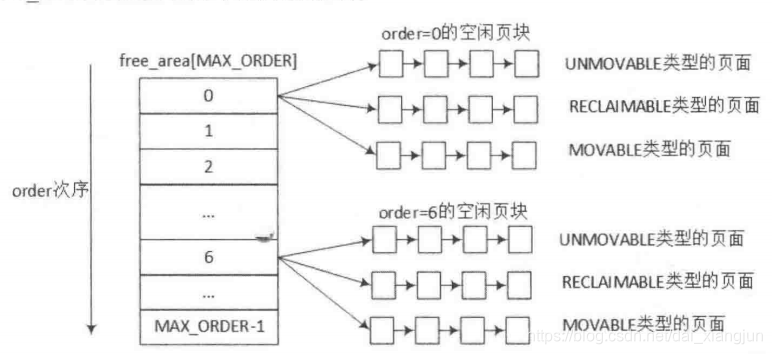 MIGRATE_TYPES类型包含MIGRATE_UNMOVABLE、MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE以及MIGRATE_RESERVE等几种类型。当前页面分配的状态可以从/proc/pagetypeinfo中获取得到。以下是ARM Vexpress平台pagetypeinfo信息
MIGRATE_TYPES类型包含MIGRATE_UNMOVABLE、MIGRATE_RECLAIMABLE、MIGRATE_MOVABLE以及MIGRATE_RESERVE等几种类型。当前页面分配的状态可以从/proc/pagetypeinfo中获取得到。以下是ARM Vexpress平台pagetypeinfo信息
/ # cat /proc/pagetypeinfo
Page block order: 10
Pages per block: 1024
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone Normal, type Unmovable 1 0 0 1 0 1 0 0 0 0 0
Node 0, zone Normal, type Reclaimable 0 0 0 0 0 1 0 1 1 1 0
Node 0, zone Normal, type Movable 0 0 0 0 0 2 4 4 1 4 172
Node 0, zone Normal, type Reserve 0 0 0 0 0 0 0 0 0 0 1
Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type Unmovable 0 0 0 1 0 0 0 1 1 1 0
Node 0, zone HighMem, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type Movable 0 0 1 1 0 1 0 1 1 0 62
Node 0, zone HighMem, type Reserve 0 0 0 0 0 0 0 0 0 0 1
Node 0, zone HighMem, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone HighMem, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Reclaimable Movable Reserve CMA Isolate
Node 0, zone Normal 6 2 181 1 0 0
Node 0, zone HighMem 1 0 64 1 0 0
-
大部分物理内存页面都存放在MIGRATE_MOVEABLE链表中。
-
大部分物理页面初始时存放在2的10次幂的链表中。
思考题:Linux内核初始化时究竟有多少页面是MIGRATE_MOVABLE?
内存管理中有一个pageblock的概念(pageblock就是用来描述迁移类型),一个pageblock的大小通常是2的(MAX_ORDER-1)次幂个页面,如果体系结构中提供了HUGETLB_PAGE特性,那么pageblock_order定义为HUGETLB_PAGE_ORDER。
/* Huge pages are a constant size */
#define pageblock_order HUGETLB_PAGE_ORDER
#endif /* CONFIG_HUGETLB_PAGE_SIZE_VARIABLE */
#else /* CONFIG_HUGETLB_PAGE */
/* If huge pages are not used, group by MAX_ORDER_NR_PAGES */
#define pageblock_order (MAX_ORDER-1)
#endif /* CONFIG_HUGETLB_PAGE */每个pageblock有一个相应地MIGRATE_TYPES类型。zone数据结构中有一个成员指针pageblock_flags,它指向用于存放每个pageblock的MIGRATE_TYPES类型的内存空间。pageblock_flags指向的内存空间大小通过usemap_size()函数来计算,每个pageblock用4个比特位来存放MIGRATE_TYPES类型。
zone的初始化函数free_area_init_core()会调用setup_usemap()函数来计算和分配pageblock_flags所需要的大小,并且分配相应地内存。
free_area_init_core()->setup_usemap()->usemap_size()
static void __init setup_usemap(struct pglist_data *pgdat,
struct zone *zone,
unsigned long zone_start_pfn,
unsigned long zonesize)
{
unsigned long usemapsize = usemap_size(zone_start_pfn, zonesize);
zone->pageblock_flags = NULL;
if (usemapsize)
zone->pageblock_flags =
memblock_virt_alloc_node_nopanic(usemapsize,
pgdat->node_id);
}/*
* Calculate the size of the zone->blockflags rounded to an unsigned long
* Start by making sure zonesize is a multiple of pageblock_order by rounding
* up. Then use 1 NR_PAGEBLOCK_BITS worth of bits per pageblock, finally
* round what is now in bits to nearest long in bits, then return it in
* bytes.
*/
static unsigned long __init usemap_size(unsigned long zone_start_pfn, unsigned long zonesize)
{
unsigned long usemapsize;
zonesize += zone_start_pfn & (pageblock_nr_pages-1);
usemapsize = roundup(zonesize, pageblock_nr_pages);
usemapsize = usemapsize >> pageblock_order;
usemapsize *= NR_PAGEBLOCK_BITS; //NR_PAGEBLOCK_BITS => 4
usemapsize = roundup(usemapsize, 8 * sizeof(unsigned long));
return usemapsize / 8;
}usemap()函数首先计算zone有多少个pageblock,每个pageblock需要4bit来存放MIGRATE_TYPE类型,最后可以计算出需要多少Byte,然后通过
memblock_virt_alloc_node_nopanic()来分配内存,并且zone->pageblock_flags成员指向这段内存。
例如在ARM Vexpress平台,ZONE_NORMAL的大小是760MB,每个pageblock大小是4MB,那么就有190个pageblock,每个pageblock的MIGRATE_TYPES的类型需要4bit,所以管理这些pageblock,需要96Byte。
内核有两个函数来管理这些迁移类型: get_pageblock_migratetype()和set_pageblock_migratetype()。内核初始化时所有的页面最初都标记为MIGRATE_MOVABLE类型,见free_area_init_core()->memmap_init()。
#define memmap_init(size, nid, zone, start_pfn) \
memmap_init_zone((size), (nid), (zone), (start_pfn), MEMMAP_EARLY)
#endif
/*
* Initially all pages are reserved - free ones are freed
* up by free_all_bootmem() once the early boot process is
* done. Non-atomic initialization, single-pass.
*/
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context)
{
struct page *page;
unsigned long end_pfn = start_pfn + size;
unsigned long pfn;
struct zone *z;
if (highest_memmap_pfn < end_pfn - 1)
highest_memmap_pfn = end_pfn - 1;
z = &NODE_DATA(nid)->node_zones[zone];
for (pfn = start_pfn; pfn < end_pfn; pfn++) {
/*
* There can be holes in boot-time mem_map[]s
* handed to this function. They do not
* exist on hotplugged memory.
*/
if (context == MEMMAP_EARLY) {
if (!early_pfn_valid(pfn))
continue;
if (!early_pfn_in_nid(pfn, nid))
continue;
}
page = pfn_to_page(pfn);
//初始化每个一个page
set_page_links(page, zone, nid, pfn); //设置此page属于哪个zone。在page->flags中
mminit_verify_page_links(page, zone, nid, pfn);
init_page_count(page);//设置page->_count 为 1
page_mapcount_reset(page); //设置page->_mapcount 为-1
page_cpupid_reset_last(page);
SetPageReserved(page);//设置该页不能被换出
/*
* Mark the block movable so that blocks are reserved for
* movable at startup. This will force kernel allocations
* to reserve their blocks rather than leaking throughout
* the address space during boot when many long-lived
* kernel allocations are made. Later some blocks near
* the start are marked MIGRATE_RESERVE by
* setup_zone_migrate_reserve()
*
* bitmap is created for zone's valid pfn range. but memmap
* can be created for invalid pages (for alignment)
* check here not to call set_pageblock_migratetype() against
* pfn out of zone.
*/
if ((z->zone_start_pfn <= pfn)
&& (pfn < zone_end_pfn(z))
&& !(pfn & (pageblock_nr_pages - 1)))
set_pageblock_migratetype(page, MIGRATE_MOVABLE); //MIGRATE_MOVABLE=2
INIT_LIST_HEAD(&page->lru);
#ifdef WANT_PAGE_VIRTUAL
/* The shift won't overflow because ZONE_NORMAL is below 4G. */
if (!is_highmem_idx(zone))
set_page_address(page, __va(pfn << PAGE_SHIFT));
#endif
}
}set_pageblock_migratetype()用于设置指定pageblock的MIGRATE_TYPES类型,最后调用来设置pageblock的迁移类型。
[set_pageblock_migratetype()->set_pageblock_flags_group()->set_pfnblock_flags_mask()]
void set_pageblock_migratetype(struct page *page, int migratetype)
{
if (unlikely(page_group_by_mobility_disabled &&
migratetype < MIGRATE_PCPTYPES))
migratetype = MIGRATE_UNMOVABLE;
//set_pageblock_flags_group(page, 2, 0, 2)
set_pageblock_flags_group(page, (unsigned long)migratetype,
PB_migrate, PB_migrate_end);
}
#define set_pageblock_flags_group(page, flags, start_bitidx, end_bitidx) \
set_pfnblock_flags_mask(page, flags, page_to_pfn(page), \
end_bitidx, \
(1 << (end_bitidx - start_bitidx + 1)) - 1)
/* Bit indices that affect a whole block of pages */
enum pageblock_bits {
PB_migrate,
PB_migrate_end = PB_migrate + 3 - 1,
/* 3 bits required for migrate types */
PB_migrate_skip,/* If set the block is skipped by compaction */
/*
* Assume the bits will always align on a word. If this assumption
* changes then get/set pageblock needs updating.
*/
NR_PAGEBLOCK_BITS
};
/**
* set_pfnblock_flags_mask - Set the requested group of flags for a pageblock_nr_pages block of pages
* @page: The page within the block of interest
* @flags: The flags to set
* @pfn: The target page frame number
* @end_bitidx: The last bit of interest
* @mask: mask of bits that the caller is interested in
*/
//set_pfnblock_flags_mask(page, flags = 2, pfn = 0x600000, end_bitidx = 2, mask = 7)
void set_pfnblock_flags_mask(struct page *page, unsigned long flags,
unsigned long pfn,
unsigned long end_bitidx,
unsigned long mask)
{
struct zone *zone;
unsigned long *bitmap;
unsigned long bitidx, word_bitidx;
unsigned long old_word, word;
BUILD_BUG_ON(NR_PAGEBLOCK_BITS != 4);
zone = page_zone(page);
bitmap = get_pageblock_bitmap(zone, pfn); //返回zone->pageblock_flags
bitidx = pfn_to_bitidx(zone, pfn);
word_bitidx = bitidx / BITS_PER_LONG;
bitidx &= (BITS_PER_LONG-1);
VM_BUG_ON_PAGE(!zone_spans_pfn(zone, pfn), page);
bitidx += end_bitidx;
mask <<= (BITS_PER_LONG - bitidx - 1);
flags <<= (BITS_PER_LONG - bitidx - 1);
word = ACCESS_ONCE(bitmap[word_bitidx]);
for (;;) {
old_word = cmpxchg(&bitmap[word_bitidx], word, (word & ~mask) | flags);
if (word == old_word)
break;
word = old_word;
}
}下面我们来思考,物理页面是如何加入到伙伴系统中的?是一页一页地添加,还是以2的几次幂来加入吗?
在free_low_memory_core_early()函数中,通过for_each_free_mem_range()函数来遍历所有的memblock内存块,找到内存块的起始地址和结束地址。
start_kernel()->mm_init()->mem_init()->free_all_bootmem()->free_low_memory_core_early()
tatic unsigned long __init free_low_memory_core_early(void)
{
unsigned long count = 0;
phys_addr_t start, end;
u64 i;
memblock_clear_hotplug(0, -1);
for_each_free_mem_range(i, NUMA_NO_NODE, &start, &end, NULL)
count += __free_memory_core(start, end);
#ifdef CONFIG_ARCH_DISCARD_MEMBLOCK
{
phys_addr_t size;
/* Free memblock.reserved array if it was allocated */
size = get_allocated_memblock_reserved_regions_info(&start);
if (size)
count += __free_memory_core(start, start + size);
/* Free memblock.memory array if it was allocated */
size = get_allocated_memblock_memory_regions_info(&start);
if (size)
count += __free_memory_core(start, start + size);
}
#endif
return count;
}
static unsigned long __init __free_memory_core(phys_addr_t start,
phys_addr_t end)
{
unsigned long start_pfn = PFN_UP(start);
unsigned long end_pfn = min_t(unsigned long,
PFN_DOWN(end), max_low_pfn);
if (start_pfn > end_pfn)
return 0;
__free_pages_memory(start_pfn, end_pfn);
return end_pfn - start_pfn;
}把内存块传递给__free_pages_memory()函数中,该函数定义如下:
static void __init __free_pages_memory(unsigned long start, unsigned long end)
{
int order;
while (start < end) {
order = min(MAX_ORDER - 1UL, __ffs(start));
while (start + (1UL << order) > end)
order--;
__free_pages_bootmem(pfn_to_page(start), order);
start += (1UL << order);
}
}
/*
* __ffs() returns the bit position of the first bit set, where the
* LSB is 0 and MSB is 31. Zero input is undefined.
*/
static inline unsigned long __ffs(unsigned long x)
{
return ffs(x) - 1;
}注意这里参数start和end指页帧号,while循环一直从起始页帧号start遍历到end,循环的步长和order有关。首先计算order的大小,取MAX_ORDER-1和__ffs(start)的最小值。ffs(start)函数计算start中第一个bit为1的位置,注意__ffs()=ffs()-1。因为伙伴系统的链表都是2^n,最大的链表是2的10次方,也就是1024,即0x400。所以,通过ffs函数可以很方便地计算出地址的对齐边界。
得到order值后,我们就可以把这块内存通过__free_pages_bootmem()函数添加到伙伴系统了。
void __init __free_pages_bootmem(struct page *page, unsigned int order)
{
unsigned int nr_pages = 1 << order;
struct page *p = page;
unsigned int loop;
prefetchw(p);
for (loop = 0; loop < (nr_pages - 1); loop++, p++) {
prefetchw(p + 1);
__ClearPageReserved(p);
set_page_count(p, 0);
}
__ClearPageReserved(p);
set_page_count(p, 0);
page_zone(page)->managed_pages += nr_pages;
set_page_refcounted(page);
__free_pages(page, order);
}__free_pages函数是伙伴系统的核心函数,这里按照order的方式添加到伙伴系统,后续将详解
[ 0.000000] start = 0x60000, end = 0x60004
[ 0.000000] start = 0x60000, order = 2
[ 0.000000] start = 0x60008, end = 0x60008
[ 0.000000] start = 0x61123, end = 0x63200
[ 0.000000] start = 0x61123, order = 0
[ 0.000000] start = 0x61124, order = 2
[ 0.000000] start = 0x61128, order = 3
[ 0.000000] start = 0x61130, order = 4
[ 0.000000] start = 0x61140, order = 6
[ 0.000000] start = 0x61180, order = 7
[ 0.000000] start = 0x61200, order = 9
[ 0.000000] start = 0x61400, order = 10
[ 0.000000] start = 0x61800, order = 10
[ 0.000000] start = 0x61c00, order = 10
[ 0.000000] start = 0x62000, order = 10
[ 0.000000] start = 0x62400, order = 10
[ 0.000000] start = 0x62800, order = 10
[ 0.000000] start = 0x62c00, order = 10
[ 0.000000] start = 0x63000, order = 9
[ 0.000000] start = 0x6320c, end = 0x662d9
[ 0.000000] start = 0x6320c, order = 2
[ 0.000000] start = 0x63210, order = 4
[ 0.000000] start = 0x63220, order = 5
[ 0.000000] start = 0x63240, order = 6
[ 0.000000] start = 0x63280, order = 7
[ 0.000000] start = 0x63300, order = 8
[ 0.000000] start = 0x63400, order = 10
[ 0.000000] start = 0x63800, order = 10
[ 0.000000] start = 0x63c00, order = 10
[ 0.000000] start = 0x64000, order = 10
[ 0.000000] start = 0x64400, order = 10
[ 0.000000] start = 0x64800, order = 10
[ 0.000000] start = 0x64c00, order = 10
[ 0.000000] start = 0x65000, order = 10
[ 0.000000] start = 0x65400, order = 10
[ 0.000000] start = 0x65800, order = 10
[ 0.000000] start = 0x65c00, order = 10
[ 0.000000] start = 0x66000, order = 9
[ 0.000000] start = 0x66200, order = 7
[ 0.000000] start = 0x66280, order = 6
[ 0.000000] start = 0x662c0, order = 4
[ 0.000000] start = 0x662d0, order = 3
[ 0.000000] start = 0x662d8, order = 0
[ 0.000000] start = 0x66325, end = 0x66325
[ 0.000000] start = 0x66326, end = 0x66326
[ 0.000000] start = 0x66332, end = 0x66332

















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











