







本文首发在《算法channel》公众号
在最近的推送中,先后总结了最小二乘法的原理,两个求解方法:直接法和梯度下降,最后利用这两种思路进行了python实战;之后阐述了OLS算法使用的前提是必须满足数据集无多重共线性,因为它是无偏估计,这也带来了它非常惧怕多重共线性问题,在面对这些数据时,它往往得到的权重参数方差大,是一个不稳定的回归算法。
工程应用中,你拿到的数据集可能有上百个特征维度,实际上是很难保证数据集中的所有维度都满足无共线性,所以OLS实际上没有太多的实际应用价值,它必须要想到一种办法解决多重共线性,进而过滤掉那些权重参数等于或接近于0的特征项,因为它们根本就对最终的标签值贡献不了任何东西,我们最终想要的结果是从这100个维度中,得到一些,可能最后只有10个特征,或个位数个特征是主要的影响标签值的特征,它们才是贡献最大的特征列。
要想达成这个目标,脊回归和套索回归出现了,它们无一例外的在OLS的基础上做了一定优化,发现都是加了一项,这一项就是大名鼎鼎的正则化项。
1 L1和L2正则化项
正则化项在机器学习中几乎无处不在,无一例外的都可以看到损失函数后面会添加一个额外项。
常用的额外项一般有两种,L1正则化和L2正则化 ,它们都可以看做是成本函数的惩罚项(指对成本函数中的参数做的一些限制)。
对于线性回归模型,在上篇推送中我们说到了套索回归,它是应用了L1正则化项,而脊回归应用了L2正则化项。L1正则化是指权重参数 w 中各个元素的绝对值之和,通常表示为 ||w||1;L2正则化是指 中各个元素的平方和然后再求平方根,通常表示为 ||w||2 。
一般都会在正则化项之前添加一个系数α,这在机器学习中称为超参数(权重参数以外的相关参数称为超参数)。
那么L1正则化项和L2正则化项到底是如何做到对成本函数的参数惩罚的呢? 它们到底起到什么作用呢?
2 L1和L2的作用
L1正则化可以产生稀疏权重参数矩阵,从而得到一个稀疏模型,这样表示为0的特征的贡献值为0,那么自然地我们会在这100个特征列中将这些过滤掉,只留下那些对因变量产生主要贡献的参数,简而言之,这样我们可以用L1正则化进行特征选择;同时一定程度上,L1可以防止过拟合。
L2正则化可以防止模型过拟合。
下面先初步看下L1和L2正则化项取值的图型,假定模型的主要两个权重参数分别为w1和w2,分别在Jupyter Notebook中写python代码模拟取值。
看下L1和L2的定义:
# 定义L1正则化项
def L1(w1, w2):
return np.abs(w1) + np.abs(w2) # 定义L2正则化项
def L2(w1,w2):
return (w1**2+w2**2) 正则化项取值图:
import matplotlib.pyplot as plt
import numpy as np
# 数据数目
n = 256
# 定义x, y
x = np.linspace(-2, 2, n)
y = np.linspace(-2, 2, n)
# 生成网格数据
X, Y = np.meshgrid(x, y)
# 填充等高线的颜色, 6是等高线分为几部分
plt.contourf(X, Y, L2(X, Y),6, alpha = 0.75, cmap = plt.cm.hot)
#C = plt.contour(X, Y, L2(X, Y), 6, colors = 'black', linewidth = 0.2)
plt.show()L1正则化项取值的等高线图,两个坐标轴:w1,w2
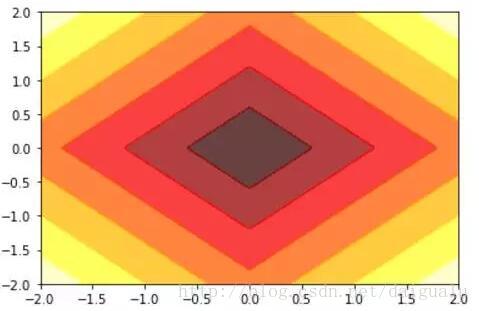
L1正则化项取值的等高线图带有高度的图
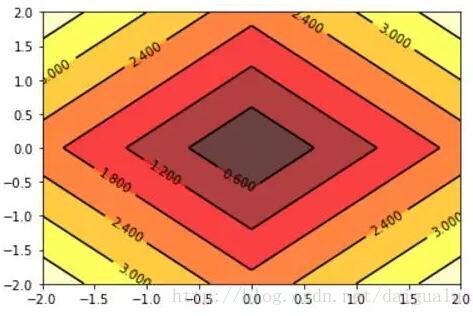
L2正则化项取值的等高线图,两个坐标轴:w1,w2
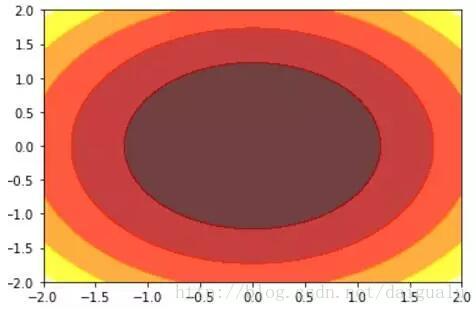
L2正则化项取值的等高线图带有高度的图

从以上结果图中看到L1的等高线图是一个四边形(对于二维特征来说),L2是一个圆形。
3 L1如何做到稀疏
OLS的成本函数添加L1正则化项后,套索回归的成本函数变为了以上两项,其中前一项记为 costOLS,后一项记为 costL1。还是假定数据集的特征为二维:w1, w2,costOLS的等高线和 costL1的图如下所示:
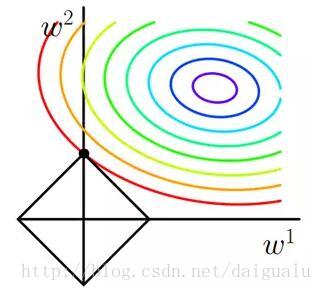
当 costOLS 等值线与costL1 图形首次在一个顶点处相交,此处就是最成本函数最小值,注意到此时的权重参数 w1等于0,这不就是把2个特征稀疏到1个了吗!
当上升到参数含有多个时,costL1会有更对的角点出来,比如100维空间中,这样导致的一个直接结果便是costOLS 会率先与这些角点相碰的机率大于与其他部位相碰的机率,这就是为什么L1可以产生稀疏模型从而用于特征选择。
那么再聊聊超参数alfa对costL1图形的影响吧! alfa越小,表明正则化惩罚的力度越小,那么 costL1的面积就会越大,这样权重参数被稀疏的程度(等于0的个数)就越小;alfa 越大,惩罚力度越大,稀疏的程度就越大。
4 L2如何做到防止过拟合
从第二节的介绍中我们可以看到L2正则化的等高线是个圆形。相比于L1正则化的方形相比,自然地,costOLS与 L2 相交时使得 w1 或w2 等于零的机率会缩小,这样与L1正则相比,为什么 L2 稀疏能力不强大的原因。具体可以参考上节推送的例子:机器学习线性回归:谈谈多重共线性问题及相关算法,其中举例了直接调用sklearn API:OLS,Ridge, Lasso 三种回归,得到的权重参数比较。
但是L2正则化可以防止过拟合,L2正则化项通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。
可以设想一下对于一个线性回归方程,若参数很大(这个在之前的推送中:机器学习之线性回归:OLS 无偏估计及相关性python分析,机器学习线性回归:谈谈多重共线性问题及相关算法,多次看到OLS得到的权重参数会很大),那么只要数据偏移一点点,就会对结果造成很大的影响,OLS对多重共线性问题的抗扰动能力很差!
那么带L2正则化项的脊回归为什么得到的权重参数往往很小呢? 在前面的推送中我们已经知道OLS的梯度下降,参数的迭代公式如下:
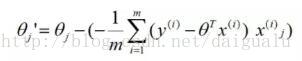
在脊回归中,加了L2后的参数迭代公式优化为如下:
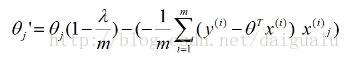
以上两个公式,并未引入学习率这个参数。
可以看到,每次迭代都会使参数比之前下降的快了,因为乘以了一个小于1的数,所以参数会更小些。
让我们看一下远边的大海,和海边优美的风景,先放松一下吧!

4 总结
以上详细总结了L1和L2正则化在机器学习中发挥的作用,文章以线性回归的正则化:脊回归和套索回归为例子,阐述了L1更擅长进行参数向量的稀疏化,而L2相比于L1更能防止过拟合的发生。
明天,我们开始总结机器学习中非常重要的,应用很广泛的逻辑回归了,欢迎您的关注!
谢谢您的阅读,期待您的到来。
欢迎关注《算法channel》
主要推送关于算法的分析过程及应用的消息。培养思维能力,注重过程,挖掘背后的原理,刨根问底。本着严谨和准确的态度,目标是撰写实用和启发性的文章,欢迎您的关注。
















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









