







声明:此文是阅读李刚老师的Java疯狂系列图书中Set集合部分后做的笔记和针对性补充,整理成文便于日后回顾。
Java的集合体系大致分为四种
- Set: 无序、不可重复;
- List: 有序、可重复;
- Queue: 队列;
- Map: 映射关系;由多个key-value对组成,类似于关联数组,所有key的集合符合Set集合特性
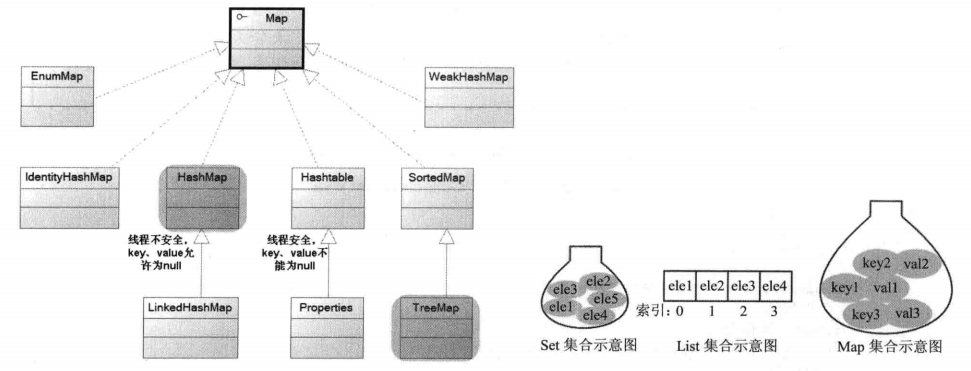
Java的集合类主要由两个接口派生:Collection和Map,继承树和示意图分别如下:
-----------------------------------------------

1.HashSet:
HashSet 是Set接口的典型实现,按Hash算法存储,有很好的存取和查找性能。
特点:
1、不能保证元素的排列顺序
2、不是同步的,多线程机制下需要靠代码保证其同步
3、集合元素值可以是null
判断两个元素是否相等的标准:两个对象通过equals()方法比较相等,且两个对象的hashCode()方法返回值也相等。
依据这个标准,在使用HashSet添加对象时,如果要重写这个类的equals()和hashCode()方法,尽量保证前者返回为true时,后者也返回为true。而且,当程序把可变对象添加进HashSet后,尽量不要去修改该集合元素中参与计算的hashCode()、equals()的示例变量,否则可能会导致该对象与其他对象相等而无法正确操作这些集合元素。
2.LinkedHashSet:
HashSet的子类,内部用链表维护元素的次序,所以性能也略低于HashSet,但在迭代访问Set里的全部元素时有很好的性能,因为其靠链表来维护内部排序。输出LinkedHashSet中元素时,顺序与添加顺序一致。
3.TreeSet:
TreeSet是SortedSet接口的实现类,其中的元素是有序的,采用红黑树的数据结构来存储,支持两种排序方式:自然排序(默认)和定制排序3.1 自然排序
TreeSet会调用集合元素的compareTo(Objece obj)方法来比较元素之间的大小关系,然后按照升序排序
如果希望TreeSet能正常运作,TreeSet只能添加同一类型的对象,否则很容易发生ClassCastException异常。
对于TreeSet而言,判断两个对象相等的唯一标准是:两个对象通过compareTo(Object obj)方法比较是否返回0,为0则相等。
依据这个标准,当需要把一个对象放入TreeSet中,重写该对象对应类的equals()方法时,应保证该方法与compareTo(Object obj)方法有一致的结果,即前者返回为true的话,后者应返回0.
3.2 定制排序
通过Comparator接口的帮助,实现int compare(T o1, T o2)方法,按需比较。4.性能分析和使用原则:
HashSet的性能总是比TreeSet要好(特别是常用的添加、查询元素等操作),因为TreeSet需要额外的红黑树算法来维护集合的元素次序。只有当需要一个保持排序的Set时,才应该使用TreeSet,否则都应该使用HashSet。
对于普通的插入、删除操作,LinkedHashSet要比HashSet要略微慢一点,这是由于维护链表所带来的额外开销所带来的,但是由于是链表,遍历会更快。
Set的三个实现类HashSet、TreeSet和EnumSet都是线程不安全的,多线程机制下,要手动保证Set集合的同步性。可用Collections工具类的synchronizedSortedSet方法来包装Set集合,此操作最好在创建时进行,以防止对Set集合的意外非同步访问。如:SortedSet s = Collections.synchronizedSortedSet(new TreeSet(...));
5.示例:
class Name { private String first; private String last; public Name(String first, String last) { this.first = first; this.last = last; } @Override public boolean equals(Object o) { if (this == o) { return true; } if (o.getClass() == Name.class) { Name name = (Name) o; return first.equals(name.first) && last.equals(name.last); } return false; } @Override public int hashCode() { return first.hashCode(); } @Override public String toString() { return "Name[first=" + first + ",last=" + last + "]"; } } /** * 当试图把某个对象当成HashMap的key,或者试图将这个类的对象放入HashSet中保存时,重写该类的equals()和hashCode * ()方法尤为重要,而且这两个方法的返回值必须保持一致,即hashCode()返回值相同时,equals()需返回true。通常来说, * 所有参与计算hashCode()返回值的关键属性,都应该用于作为equals()比较的标准。 */ public class HashSetTest { public static void main(String[] args) { Set<Name> set = new HashSet<Name>(); set.add(new Name("zhang", "san")); set.add(new Name("zhang", "san1")); System.out.println(set.contains(new Name("zhang", "san"))); System.out.println(set); } }
1.运行结果:true [Name[first=zhang,last=san], Name[first=zhang,last=san1]]2.若不重写hashCode(),输出则为false
3.若将equals()中return first.equals(name.first) && last.equals(name.last);改为return first.equals(name.first);
则运行结果为:
true [Name[first=zhang,last=san]]因为 两个对象的hashCode()相同,且equals()返回为true,程序会判断为同一个对象,第二个对象不会被加入集合。同样地,此时不管是set.contains(new Name("zhang", "san"))还是set.contains(new Name("zhang", "san1")),尽管没有zhang san1,也都返回true。















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









