









目录
在这里介绍LDPC码的迭代概率译码算法———和积译码算法(SPA译码算法、也是BP译码算法),它是基于置信传播的迭代概率译码算法,是逐符号软判决译码方法。
一、基本概念
1.置信传播
首先引入关于置信传播的相关概念和理论:
https://blog.csdn.net/daijingxin/article/details/115800989
简单来说,置信传播是一种在图模型上进行推断的消息传递算法。其主要思想是:对于马尔科夫随机场中的每一个节点,通过消息传播,把该节点的概率分布状态传递给相邻的节点,从而影响相邻节点的概率分布状态,经过一定次数的迭代,每个节点的概率分布将收敛于一个稳态。
二、 BP译码算法的基本原理
假设接收端收到的实数向量集合记为 r {r} r,有信息节点 X = x i X={x_i} X=xi,我们将信息节点 X X X满足包含 x j x_j xj的所有校验方程(与校验矩阵相乘后为0)这个事件记为 S S S,因此比特 x j = 1 ( x j = 0 ) x_j=1(x_j=0) xj=1(xj=0)关于 r {r} r和 S S S的条件概率如下:
P ( x j = 0 ∣ r , S ) P ( x j = 1 ∣ r , S ) ≥ 1 \frac{P(x_j=0|{r},S)}{P(x_j=1|{r},S)}\geq 1 P(xj=1∣r,S)P(xj=0∣r,S)≥1
如果上式成立,则对应的 x x x取值为0,若上式不成立,则对应的 x x x取值为1。因此需要求出对应的两个条件概率的大小。
下图为码字符号的联合后验概率分布双向图:
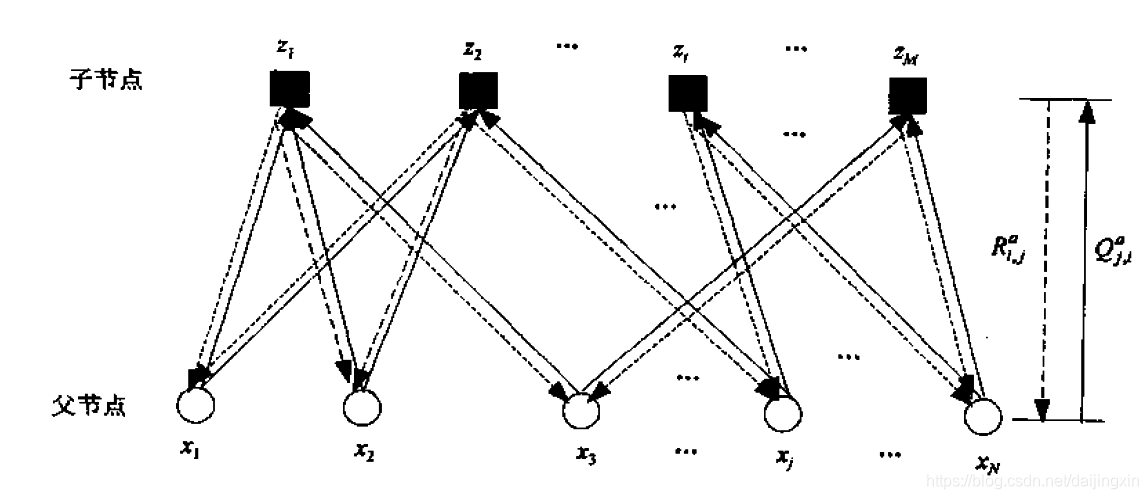
上图中子节点为校验节点,父节点为信息节点。每个校验节点代表校验公式中对应的校验方程。
R
R
R、
Q
Q
Q代表每一次迭代子节点与父节点之间传递的信息。
引入定理:

令集合
M
(
j
)
M(j)
M(j)表示变量
x
j
x_j
xj参加的校验集,
M
(
j
)
M(j)
M(j) \
i
i
i表示
M
(
j
)
M(j)
M(j)不包含
i
i
i的子集。
同理
N
(
i
)
N(i)
N(i)表示校验
z
i
z_i
zi的码元信息集,
N
(
i
)
N(i)
N(i)\
j
j
j表示
N
(
i
)
N(i)
N(i)不包含
j
j
j的子集。
因此我们可以通过这个定理来得出在第
j
j
j个元素等于
a
a
a(
a
a
a为0或1)的情况下,第j个校验矩阵满足的条件概率。当第j个元素为0时,包含该元素的方程其它比特有偶数个是1,则整个方程模2和为0,也就是能得到以下的公式:
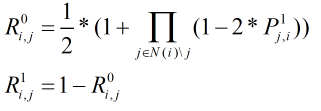
式中R代表校验信息,表示第 j j j个元素等于 a a a( a a a为0或1)的情况下,第j个校验矩阵满足的条件概率。
注意:在进行这部分计算时,需要根据校验矩阵来判断接受向量中的具体哪些位置的元素参与条件概率的计算。
而各个比特之间的概率是分别独立的,所以所有包含xj的校验方程都满足的概率是每个方程满足概率的乘积:
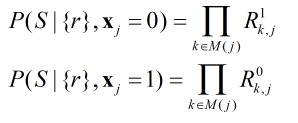
通过条件概率公式又可以得出:

式中Pj是通过信道特征得到的码字中第
j
j
j个比特是1的概率。
而表示除第
i
i
i个校验矩阵外其它校验节点提供信息的情况下第j个信息比特取值的概率可以用下式表示(即消息信息):
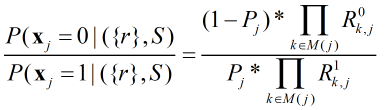
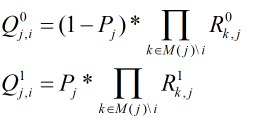
因此可以得出:
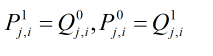
置信传播的迭代算法在每次迭代过程中,每个校验节点想所有的信息父节点分别传递
R
R
R信息,然后每个
x
x
x节点向其所有
z
z
z子节点传递已更新的
Q
Q
Q信息,用来更新
R
R
R值。如果算法收敛,在经过了足够的迭代次数后,将渐进的求出满足校验公式的情况下
x
x
x不同取值的概率,从而实现逐符号最大后验概率(MAP)译码。
1.BP译码算法的操作步骤
以在AWGN信道中采用BPSK调制为例
当功率谱密度为:
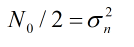
对应的条件概率分布函数为:
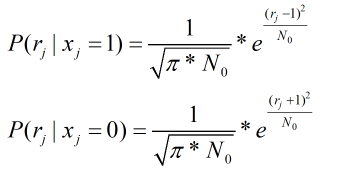
其中
r
r
r为接收到的信息值,
x
x
x为实际信息值。
通过贝叶斯公式得出:
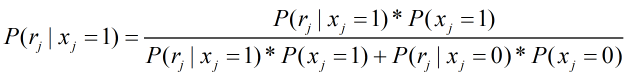
又因为:
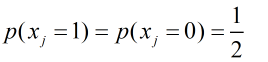
可以得出:
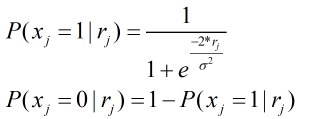
因此我们的BP算法译码步骤可以分为以下几步:
步骤1:初始化
Q
Q
Q值

步骤2:设定迭代次数
t
t
t
步骤3:计算传递的
R
R
R值
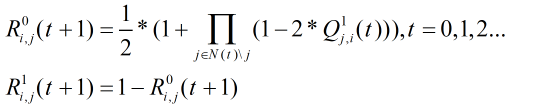
步骤4:计算传递的
Q
Q
Q值
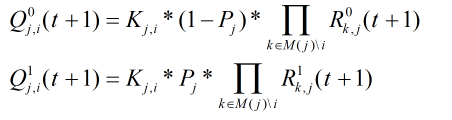
其中
k
k
k为归一化系数,保证两式结果相加为0。
步骤5:计算更新后的
Q
Q
Q值
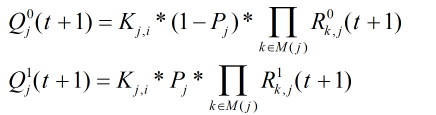
此时可以通过对上两式的比值进行判决来得出向量实际的值:
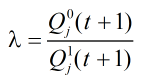
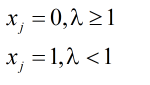
步骤6:通过校验矩阵对最后得到的信息进行校验
计算:
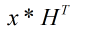
判断是否得出结果为全零向量,如果是则结束本次译码;如果不是则判断是否达到了最大迭代次数,如果已经达到了最大迭代次数,则结束译码,以最后的结果作为输出;如果没有达到最大迭代次数,则将次数加1,转入步骤3。
2.BP译码算法的简化方式
2.1引入LR(似然比)
首先为了使计算更加简化,可以引入似然比(LR)量度,二元随机变量的概率分布由一个量来表示。
定义以下变量:
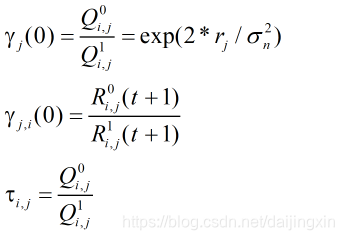
因此可以将
Q
Q
Q值的公式改写为:
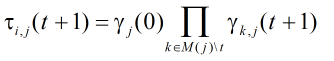
令:
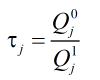
因此只需要对下式进行判决:
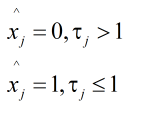
2.2引入LLR(对数似然比)
定义对数似然比LLR:
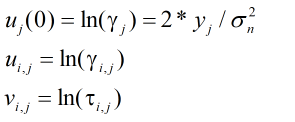
设置函数:
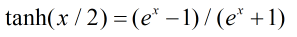
可以得出如下的关系式子:
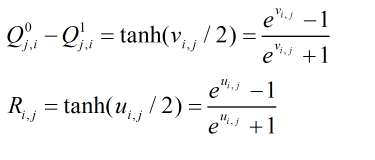
于是对
R
R
R值和
Q
Q
Q值的公式进行重新改写:
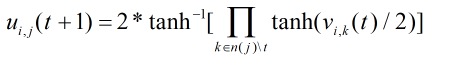
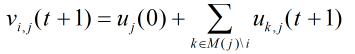
令:
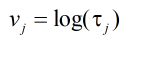
则需要对下式进行判决:
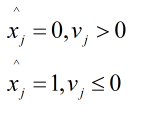
可以看出在求
V
V
V值时主要使用求和运算操作,求
U
U
U值时主要使用乘法操作,因此这种简化后的置信传播算法也被称为和积译码算法。
3.和积译码算法的操作步骤
步骤1:初始化
u
u
u值
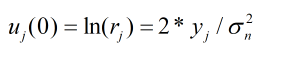
式中
y
y
y为输入变量的值。
步骤2:设定迭代次数
t
t
t
步骤3:计算传递的
U
U
U值
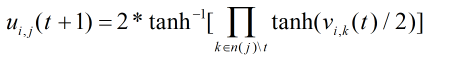
步骤4:计算传递的
V
V
V值
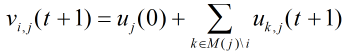
步骤5:计算更新后的
V
V
V值
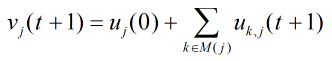
此时可以通过
V
V
V值进行判决来得出向量实际的值:
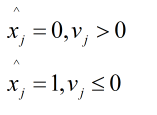
步骤6:通过校验矩阵对最后得到的信息进行校验
计算:
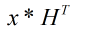
判断是否得出结果为全零向量,如果是则结束本次译码;如果不是则判断是否达到了最大迭代次数,如果已经达到了最大迭代次数,则结束译码,以最后的结果作为输出;如果没有达到最大迭代次数,则将次数加1,转入步骤3。
三、MATLAB源码
根据算法编写了相应的QC-LDPC 编码以及和积译码程序,源码的下载地址:
https://download.csdn.net/download/daijingxin/16743500
关于编码部分的原理参考这篇文章:
https://blog.csdn.net/daijingxin/article/details/114979823



















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











