






Copyright 2018 The TensorFlow Authors.
#@title Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
Text classification with an RNN
| View on TensorFlow.org | Run in Google Colab | View source on GitHub | Download notebook |
|---|
This text classification tutorial trains a
recurrent neural network
on the
IMDB large movie review dataset
for sentiment analysis.
Setup
import tensorflow_datasets as tfds
import tensorflow as tf
Import
matplotlib
and create a helper function to plot graphs:
import matplotlib.pyplot as plt
def plot_graphs(history, metric):
plt.plot(history.history[metric])
plt.plot(history.history['val_'+metric], '')
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend([metric, 'val_'+metric])
plt.show()
Setup input pipeline
The IMDB large movie review dataset is a
binary classification
dataset—all the reviews have either a
positive
or
negative
sentiment.
Download the dataset using
TFDS
.
dataset, info = tfds.load('imdb_reviews/subwords8k', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
WARNING:absl:TFDS datasets with text encoding are deprecated and will be removed in a future version. Instead, you should use the plain text version and tokenize the text using `tensorflow_text` (See: https://www.tensorflow.org/tutorials/tensorflow_text/intro#tfdata_example)
The dataset
info
includes the encoder (a
tfds.features.text.SubwordTextEncoder
).
encoder = info.features['text'].encoder
print('Vocabulary size: {}'.format(encoder.vocab_size))
Vocabulary size: 8185
This text encoder will reversibly encode any string, falling back to byte-encoding if necessary.
sample_string = 'Hello TensorFlow.'
encoded_string = encoder.encode(sample_string)
print('Encoded string is {}'.format(encoded_string))
original_string = encoder.decode(encoded_string)
print('The original string: "{}"'.format(original_string))
Encoded string is [4025, 222, 6307, 2327, 4043, 2120, 7975]
The original string: "Hello TensorFlow."
assert original_string == sample_string
for index in encoded_string:
print('{} ----> {}'.format(index, encoder.decode([index])))
4025 ----> Hell
222 ----> o
6307 ----> Ten
2327 ----> sor
4043 ----> Fl
2120 ----> ow
7975 ----> .
Prepare the data for training
Next create batches of these encoded strings. Use the
padded_batch
method to zero-pad the sequences to the length of the longest string in the batch:
BUFFER_SIZE = 10000
BATCH_SIZE = 64
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.padded_batch(BATCH_SIZE)
test_dataset = test_dataset.padded_batch(BATCH_SIZE)
Create the model
Build a
tf.keras.Sequential
model and start with an embedding layer. An embedding layer stores one vector per word. When called, it converts the sequences of word indices to sequences of vectors. These vectors are trainable. After training (on enough data), words with similar meanings often have similar vectors.
This index-lookup is much more efficient than the equivalent operation of passing a one-hot encoded vector through a
tf.keras.layers.Dense
layer.
A recurrent neural network (RNN) processes sequence input by iterating through the elements. RNNs pass the outputs from one timestep to their input—and then to the next.
The
tf.keras.layers.Bidirectional
wrapper can also be used with an RNN layer. This propagates the input forward and backwards through the RNN layer and then concatenates the output. This helps the RNN to learn long range dependencies.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(encoder.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
Please note that we choose to Keras sequential model here since all the layers in the model only have single input and produce single output. In case you want to use stateful RNN layer, you might want to build your model with Keras functional API or model subclassing so that you can retrieve and reuse the RNN layer states. Please check
Keras RNN guide
for more details.
Compile the Keras model to configure the training process:
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
Train the model
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 64) 523840
_________________________________________________________________
bidirectional (Bidirectional (None, 128) 66048
_________________________________________________________________
dense (Dense) (None, 64) 8256
_________________________________________________________________
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 598,209
Trainable params: 598,209
Non-trainable params: 0
_________________________________________________________________
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
Epoch 1/10
391/391 [==============================] - 1010s 3s/step - loss: 0.6163 - accuracy: 0.5965 - val_loss: 0.4472 - val_accuracy: 0.8167
Epoch 2/10
391/391 [==============================] - 1047s 3s/step - loss: 0.3234 - accuracy: 0.8655 - val_loss: 0.3360 - val_accuracy: 0.8536
Epoch 3/10
391/391 [==============================] - 1057s 3s/step - loss: 0.2441 - accuracy: 0.9073 - val_loss: 0.3307 - val_accuracy: 0.8542
Epoch 4/10
391/391 [==============================] - 1057s 3s/step - loss: 0.2076 - accuracy: 0.9244 - val_loss: 0.3434 - val_accuracy: 0.8495
Epoch 5/10
391/391 [==============================] - 1057s 3s/step - loss: 0.1785 - accuracy: 0.9356 - val_loss: 0.3431 - val_accuracy: 0.8562
Epoch 6/10
391/391 [==============================] - 1073s 3s/step - loss: 0.1593 - accuracy: 0.9432 - val_loss: 0.3661 - val_accuracy: 0.8646
Epoch 7/10
391/391 [==============================] - 1086s 3s/step - loss: 0.1453 - accuracy: 0.9502 - val_loss: 0.3774 - val_accuracy: 0.8667
Epoch 8/10
391/391 [==============================] - 1074s 3s/step - loss: 0.1874 - accuracy: 0.9276 - val_loss: 0.4019 - val_accuracy: 0.8542
Epoch 9/10
391/391 [==============================] - 1054s 3s/step - loss: 0.1256 - accuracy: 0.9574 - val_loss: 0.4335 - val_accuracy: 0.8458
Epoch 10/10
391/391 [==============================] - 1075s 3s/step - loss: 0.1132 - accuracy: 0.9632 - val_loss: 0.4859 - val_accuracy: 0.8589
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss: {}'.format(test_loss))
print('Test Accuracy: {}'.format(test_acc))
391/391 [==============================] - 91s 233ms/step - loss: 0.4814 - accuracy: 0.8571
Test Loss: 0.48140329122543335
Test Accuracy: 0.8571199774742126
The above model does not mask the padding applied to the sequences. This can lead to skew if trained on padded sequences and test on un-padded sequences. Ideally you would
use masking
to avoid this, but as you can see below it only have a small effect on the output.
If the prediction is >= 0.5, it is positive else it is negative.
def pad_to_size(vec, size):
zeros = [0] * (size - len(vec))
vec.extend(zeros)
return vec
def sample_predict(sample_pred_text, pad):
encoded_sample_pred_text = encoder.encode(sample_pred_text)
if pad:
encoded_sample_pred_text = pad_to_size(encoded_sample_pred_text, 64)
encoded_sample_pred_text = tf.cast(encoded_sample_pred_text, tf.float32)
predictions = model.predict(tf.expand_dims(encoded_sample_pred_text, 0))
return (predictions)
# predict on a sample text without padding.
sample_pred_text = ('The movie was cool. The animation and the graphics '
'were out of this world. I would recommend this movie.')
predictions = sample_predict(sample_pred_text, pad=False)
print(predictions)
[[0.08617041]]
# predict on a sample text with padding
sample_pred_text = ('The movie was cool. The animation and the graphics '
'were out of this world. I would recommend this movie.')
predictions = sample_predict(sample_pred_text, pad=True)
print(predictions)
[[0.31546882]]
plot_graphs(history, 'accuracy')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fjbHZfnG-1589995755105)(output_37_0
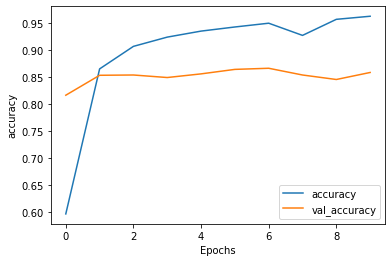
)]
plot_graphs(history, 'loss')
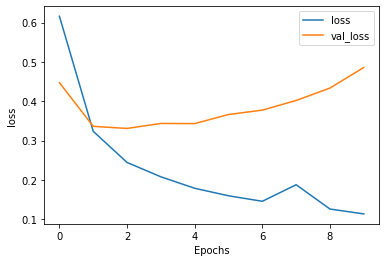
Stack two or more LSTM layers
Keras recurrent layers have two available modes that are controlled by the
return_sequences
constructor argument:
- Return either the full sequences of successive outputs for each timestep (a 3D tensor of shape
(batch_size, timesteps, output_features)
). - Return only the last output for each input sequence (a 2D tensor of shape (batch_size, output_features)).
model = tf.keras.Sequential([
tf.keras.layers.Embedding(encoder.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, return_sequences=True)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1)
])
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
Epoch 1/10
391/391 [==============================] - 1344s 3s/step - loss: 0.6520 - accuracy: 0.5640 - val_loss: 0.4960 - val_accuracy: 0.7599
Epoch 2/10
391/391 [==============================] - 1368s 3s/step - loss: 0.3920 - accuracy: 0.8398 - val_loss: 0.3811 - val_accuracy: 0.8255
Epoch 3/10
391/391 [==============================] - 1379s 4s/step - loss: 0.2889 - accuracy: 0.8918 - val_loss: 0.3739 - val_accuracy: 0.8578
Epoch 4/10
391/391 [==============================] - 1390s 4s/step - loss: 0.2383 - accuracy: 0.9145 - val_loss: 0.3629 - val_accuracy: 0.8438
Epoch 5/10
391/391 [==============================] - 1395s 4s/step - loss: 0.2007 - accuracy: 0.9325 - val_loss: 0.3587 - val_accuracy: 0.8635
Epoch 6/10
391/391 [==============================] - 1401s 4s/step - loss: 0.1772 - accuracy: 0.9432 - val_loss: 0.3716 - val_accuracy: 0.8625
Epoch 7/10
391/391 [==============================] - 1394s 4s/step - loss: 0.1509 - accuracy: 0.9564 - val_loss: 0.4652 - val_accuracy: 0.8500
Epoch 8/10
391/391 [==============================] - 1396s 4s/step - loss: 0.1371 - accuracy: 0.9604 - val_loss: 0.4389 - val_accuracy: 0.8516
Epoch 9/10
391/391 [==============================] - 1393s 4s/step - loss: 0.1307 - accuracy: 0.9616 - val_loss: 0.4791 - val_accuracy: 0.8516
Epoch 10/10
391/391 [==============================] - 1399s 4s/step - loss: 0.1103 - accuracy: 0.9711 - val_loss: 0.5048 - val_accuracy: 0.8453
test_loss, test_acc = model.evaluate(test_dataset)
print('Test Loss: {}'.format(test_loss))
print('Test Accuracy: {}'.format(test_acc))
391/391 [==============================] - 268s 685ms/step - loss: 0.4926 - accuracy: 0.8499
Test Loss: 0.4925665557384491
Test Accuracy: 0.8498799800872803
# predict on a sample text without padding.
sample_pred_text = ('The movie was not good. The animation and the graphics '
'were terrible. I would not recommend this movie.')
predictions = sample_predict(sample_pred_text, pad=False)
print(predictions)
[[-2.3478887]]
# predict on a sample text with padding
sample_pred_text = ('The movie was not good. The animation and the graphics '
'were terrible. I would not recommend this movie.')
predictions = sample_predict(sample_pred_text, pad=True)
print(predictions)
[[-2.705863]]
plot_graphs(history, 'accuracy')
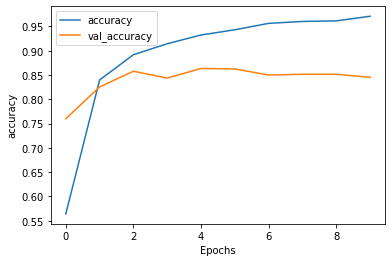
plot_graphs(history, 'loss')
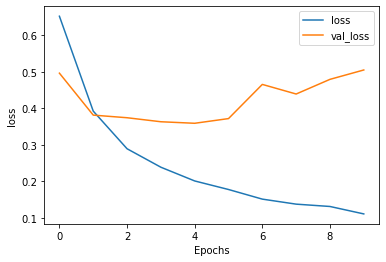
Check out other existing recurrent layers such as
GRU layers
.
If you’re interestied in building custom RNNs, see the
Keras RNN Guide
.















 3949
3949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









