







 本文详细介绍了深度学习中批量归一化(Batch Normalization)的作用和实现方式,以及如何有效进行超参数调优。批量归一化能够加速训练,提高模型的鲁棒性,并在测试时通过指数加权平均估算均值和方差。此外,文章还探讨了在资源有限和丰富的情况下,两种不同的调参策略。
本文详细介绍了深度学习中批量归一化(Batch Normalization)的作用和实现方式,以及如何有效进行超参数调优。批量归一化能够加速训练,提高模型的鲁棒性,并在测试时通过指数加权平均估算均值和方差。此外,文章还探讨了在资源有限和丰富的情况下,两种不同的调参策略。
超参数调试 、batch normalization 、deep learning framework
3.1 tuning process
-
在调参时,有些参数会比其他参数重要的多,以下列出一些调参的guidelines:
-
1、最重要的参数:学习率 α
2、次重要的参数:momentum中的 β (0.9就不错)、#hidden units、mini-batch size
3、再次重要的参数:#layers、learning rate decay、Adam中的 β1 、 β2 、 ε (事实上Ng从来不调Adam中的参数,总是让他们等于0.9、0.99、1e-8)
如何系统的组织超参数搜索过程?
1、在参数空间随机选取参数,这样可以尝试不同的参数,从而确定哪一组参数最好。
2、由粗到细的搜索参数。首先在参数空间随机粗略的选取,确定哪一组性能好,然后再最优参数的周围,更密集的采样,选取参数。
3.2 using an appropriate scale to pick hyperparameters
随机采样,并不意味着随机均匀采样,而是选取合适的尺度或标尺来采样,本小节将讨论这个问题。
对于有些参数,如#hidden units、layers,它们用随机均匀采样是可以的。
但是,对于学习率 α ,若我们想在0.0001~1这个区间取值,如果我们随机均匀采样,那么我们将投入90%的资源在0.1~1这个区间内搜索,仅剩10%的资源在0.0001~0.1的区间内搜索,这样显然不太合理。这时,我们考虑用对数坐标,将0.0001~1转化为-4~0,对于0.0001~0.001就有了更多的搜索资源可用。在-4~0之间随机平均采样,然后得到 α 的值,该计算在Python中可以这样实现:
r=-4*np.random.rand()
learning_rate = 10**r ##learning_rate = np.power(10,r)3.3 调参实践
如果计算资源比较紧张,就用方法一;如果计算资源丰富,就用方法二。
方法一:每次只训练一个模型,不断地调试。
方法二:每次训练多个模型,设置不同的参数,看那个参数集合效果好。
3.4 normalizing activations in a network
batch normalization 使得参数搜索问题更简单,也使得模型更鲁棒,还会使你更容易的训练深层次网络。
batch normalization 原理:
在logistics regression中,介绍了标准化输入可以加速模型训练。那么,在深层次的网络中,我们除了标准化输入 X 外,是否还可以标准化隐含层的输入A呢?这就是batch normalization的思想。实际中,我们标准化的是激活函数的输入Z。关于到底标准化A还是Z,在学术界还是有争论的,但Ng推荐标准化Z。有时,我们希望Z的分布不全是0均值、1方差,Z若有其他的分布,可能会具有更好的效果。实现如下:
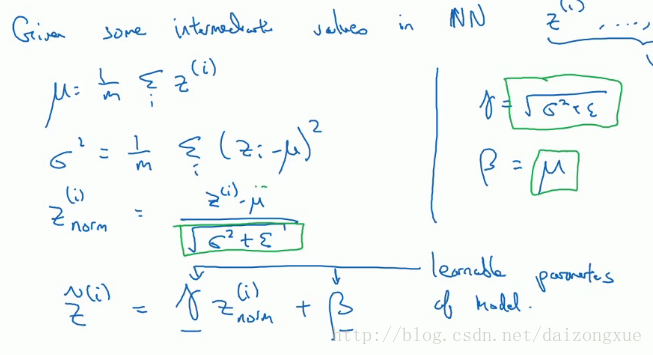
上图左边的四个公式就是batch normalization的具体实现,这里的
3.5 fitting batch norm into a neural network
本小节描述在神经网络中怎么实现batch normalization。如下图所示,在每一个隐层中,当计算得到Z后,我们先不直接计算A,而是使用batch normalization,通过参数 β 和 γ ,计算得到 Z~ ,然后将 Z~ 作为激活函数的输入得到A。
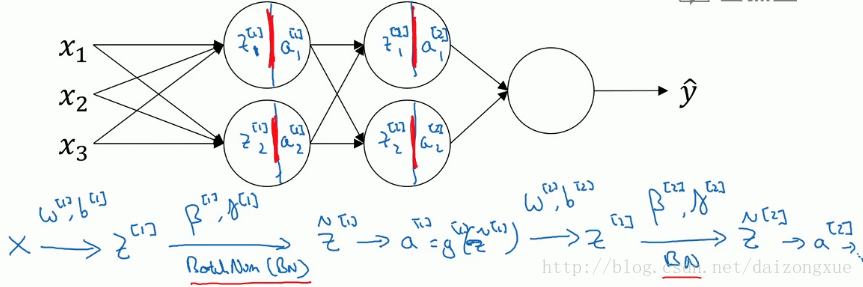
当使用了batch normalization后,我们算法的参数有W、b、 β 和 γ 。这里的参数 β 和momentum中的超参数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









