







上一篇记载了高斯混合模型GMM与EM算法,这个模型在机器学习中的很多地方都会用到。
聚类简介:
今天我们说聚类。说“机器学习”不说的“聚类”那还算是“机器学习”吗?
首先,我们回到混合高斯模型的那副图:
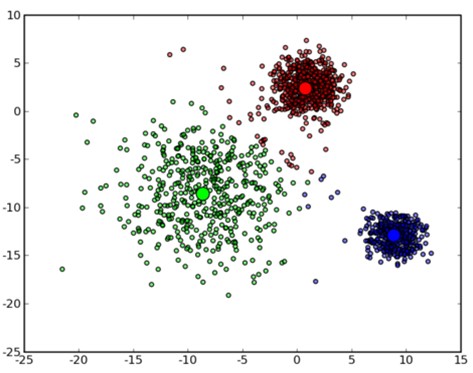
在n=3的高斯模型的拟合下,而三个不同模型会各自代表三个不同数据簇(cluster)。将数据点划分若干个簇的过程叫聚类。
在这里,我们可以挖掘出几个隐藏信息
1. 聚类的目的其实是为了划分数据集分类。划分数据集结果必然导致分类。所以我们直接说“聚类的目的是为了分类”这个道理也正确。
2. 聚类一般会要求数据集里面有很多数据。否则不清晰。
3. 聚类准确率的高低看数据集,也很有可能算法失败。聚类之前最好用可视化方法看看数据集是什么样的。
4. 聚类算法好理解,但是聚几类合适是很难知道的,这个是难点。
一、K-means
k-means的算法讲解已经烂大街了。(其实比k-means更烂大街的是KNN),算法很简单:
k-means就是找k个点当聚类中心;
根据聚类中心算每个点属于的类,以此算出新聚类中心;
根据新聚类中心算每个点属于的类,以此算出新新聚类中心;
根据新新聚类中心算每个点属于的类,以此算出新新新聚类中心;
。。。。。算吐为止。
他的缺点很明显:结果好坏依赖于对初始聚类中心的选择、容易陷入局部最优解、对K值的选择没有准则可依循、对异常数据较为敏感、只能处理数值属性的数据、聚类结构可能不平衡。
别看这么简单粗暴,k-means有时准确性很高。实际应用上,针对数据集特性,它还有很多变种改进。
二、高斯混合均值
首先高斯混合模型
http://blog.csdn.net/dajiabudongdao/article/details/51893046
每个高斯模型其实相当于聚类中的一个类别。
这个模型可以算出数据集中一个点x,在多高斯混合模型中的各个高斯模型的比重。也就是x针对于第一个高斯模型的隶属度多少,第二个隶属度多少,第三个隶属度多少。。。都可以表示。
三、层次聚类
凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些相似性很大的原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。
这么说来,这个算法符合简单的物以类聚的特性。这个算法的前提是需定义相似性。如果把距离越近视为相似性越高。则下面是 给予最小距离的层次聚类
将每个对象看作一类,计算两两之间的最小距离;
将距离最小的两个类合并成一个新类;
重新计算新类与所有类之间的距离;
将距离最小的两个类合并成一个新类;
重新计算新类与所有类之间的距离;
将距离最小的两个类合并成一个新类;
重新计算新类与所有类之间的距离;
。。。。。。。你认为差不多算法就停了吧。不然最后全聚一类了。
这个算法,什么数据集都能用。而且不像KNN,GMM一样需要提前设置聚多少类(设置K值)。但说实话,太通用的往往不是很好。
四、FCM聚类算法
FCM算法是一种以隶属度来确定每个数据点属于某个聚类程度的算法。算法的核心就是隶属度矩阵的建立与收敛。这还是个隶属度思想。

不过我更认为这个算法适合层次聚类后进行。这样可以减少运算。相当于聚类精度提高算法。
五、密度聚类算法
DBSCAN是一种典型密度聚类算法。该算法的目的在于过滤低密度区域,发现稠密度样本点,跟传统的基于层次聚类和划分聚类的凸形聚类簇不同,该算法可以发现任意形状的聚类簇,同时也不必输入你要划分的聚类个数。
输入: 包含n个对象的数据库,半径e,最少数目MinPts;
输出:所有生成的簇,达到密度要求。
(1)Repeat
(2)从数据库中抽出一个未处理的点;
(3)IF抽出的点是核心点 THEN 找出所有从该点密度可达的对象,形成一个簇;
(4)ELSE 抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一个点;
(5)UNTIL 所有的点都被处理。
DBSCAN对用户定义的参数很敏感,细微的不同都可能导致差别很大的结果,而参数的选择无规律可循,只能靠经验确定。
其聚类过程很像水结冰实验,非连接图的遍历。慢慢地长成一个类。
自我感觉这个东西非常不好。因为如果慢慢长成,对于离群点非常不友好。如果数据过多还有可能产生只聚一个类的状况。
六、关键问题讲解
1.聚类簇数k的判定
如果认为k=1即聚成一类。实际就是不聚类。此时计算各个点到中心聚类点和;然后计算k=2,各个点到中心聚类点的距离和;然后计算k=3,各个点到中心聚类点的距离和;。。。。
当计算k=n时,即总共n个点聚n类为止,此时各个点到中心聚类点的距离和为0。
这样的簇数k与中心点距离和,就一个递减函数,我们从中找到拐点,肘点就可
2.测量聚类的质量
对于n个向量的样本空间,假定被分了k个簇。下面是一个衡量聚类质量的内在方法-轮廓系数。
1.对于任意一个向量v来说,可以求得一个v到本类簇中其他各点距离的平均值a(v);
2.求这个向量v到其他所有各个簇的最小距离,求这些距离平均值。得b(v);
3.轮廓系数为下面的公式。轮廓系数在-1,1之间。a(v)表示紧凑型,b(v)表示分离型。如果接近1,a(v)比较小,b(v)比较大,说明紧凑。















 4516
4516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









