







1. 分类 vs 聚类
分类:
- 有监督学习(需要标签);
- 依据已知标签的数据,根据一定规则或模式,对新输入数据标记上影响标签(有明确的训练集,有人为给定标签)。
聚类:
- 无监督学习(没有标签);
- 对于给定数据按照其相似性进行划分(没有训练集,没有标签,也不知道确切的类别或簇的数目)。
2. 聚类任务
- 在“无监督学习”任务中研究最多、应用最广;
- 聚类的目标是将数据样本划分为若干个通常不相交的簇(cluster);
- 既可以作为一个单独过程(用于找寻数据内在的分布结构),也可作为分类等其他学习任务的前驱过程。
聚类:根据某种相似性,把一组数据划分成若干个簇的过程。
- 难点一:相似性很难精准定义!各种距离,度量学习!
- 难点二:可能存在的划分太多!避免穷举,优化算法!
- 难点三:若干个簇 = ?预先给定,算法自适应!
3. 常见聚类方法:
原型聚类(prototype-based clustering)
- 假设:聚类结构能通过一组原型刻画;
- 过程:先对原型初始化,然后对原型进行迭代更新求解;
- 代表:k均值聚类,学习向量量化(LVQ),高斯混合聚类。
密度聚类(density-based clustering)
- 假设:聚类结构能通过样本分布的紧密程度确定;
- 过程:从样本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇;
- 代表:DBSCAN, OPTICS,DENCLUE。
层次聚类(hierarchical clustering)
- 假设:能够产生不同粒度的聚类结果;
- 过程:在不同层次对数据集进行划分,从而形成树形的聚类结构;
- 代表:AGNES (自底向上),DIANA(自顶向下)。
4. K-means算法
聚类问题可以通过为每个簇寻找合适的中心来实现。假设每个簇的中心已经找到,可以把所有数据点分配到距离它最近的中心所在的簇。即:
j
=
arg min
l
d
i
s
t
(
x
i
,
μ
l
)
j=\argmin_ldist(x_i,\mu_l)
j=largmindist(xi,μl)
4.1 K-means模型
给定数据
x
x
x个簇的个数
k
k
k,K-means模型可以表示为:
arg min
μ
i
,
C
i
∑
i
=
1
k
∑
x
∈
C
i
∣
∣
x
−
μ
i
∣
∣
2
\argmin_{\mu_i,C_i}\sum\limits_{i=1}^k\sum\limits_{x∈C_i}||x-\mu_i||^2
μi,Ciargmini=1∑kx∈Ci∑∣∣x−μi∣∣2其中,
C
i
C_i
Ci表示第
i
i
i个簇,
μ
i
\mu_i
μi表示第
i
i
i个簇的中心。
目标函数对
μ
i
\mu_i
μi求偏导等于零,得:
μ
i
=
1
∣
C
i
∣
∑
x
∈
C
i
x
\mu_i=\frac{1}{|C_i|}\sum\limits_{x∈C_i}x
μi=∣Ci∣1x∈Ci∑x因此,上述模型被称为K-means模型。
K-means模型:
arg min
C
i
∑
i
=
1
k
∑
x
∈
C
i
∣
∣
x
−
1
∣
C
i
∣
∑
x
∈
C
i
x
∣
∣
2
\argmin_{C_i}\sum\limits_{i=1}^k\sum\limits_{x∈C_i}||x-\frac{1}{|C_i|}\sum_{x∈C_i}x||^2
Ciargmini=1∑kx∈Ci∑∣∣x−∣Ci∣1x∈Ci∑x∣∣2
可能的划分数: S ( n , k ) = 1 k ! ∑ i = 0 k ( − 1 ) i ( k − i ) n S(n,k)=\frac{1}{k!}\sum\limits_{i=0}^k(-1)^i(k-i)^n S(n,k)=k!1i=0∑k(−1)i(k−i)n是非凸组合优化问题,NP-难!
4.2 模型求解
采用启发式算法进行求解,主要有以下几种方法:
- Lloyd(Forgy)算法
- Hartigan-Wong算法
- MacQueen算法
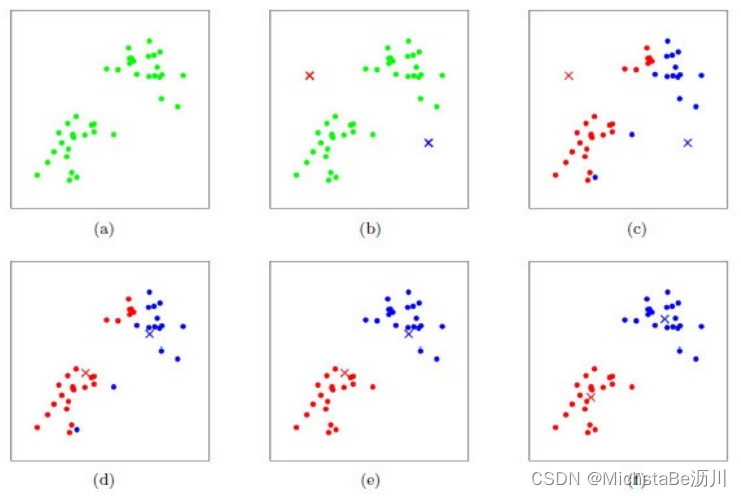
下面使用Lloyd算法求解K-means。
- 给定数据 x x x和簇的个数 k k k;
- 随机选取 k k k个簇的中心 { μ i } i = 1 , . . . , k \{\mu_i\}_{i=1,...,k} {μi}i=1,...,k;
- 重复下述迭代过程直至收敛:
划分步骤:对每个数据点 x j x_j xj,计算其应该属于的簇。 arg min i ∣ ∣ x j − μ j ∣ ∣ 2 2 \argmin_i||x_j-\mu_j||_2^2 iargmin∣∣xj−μj∣∣22更新步骤:重新计算每个簇的中心。 μ i = 1 ∣ C i ∣ ∑ x j ∈ C i x j \mu_i=\frac{1}{|C_i|}\sum\limits_{x_j∈C_i}x_j μi=∣Ci∣1xj∈Ci∑xj
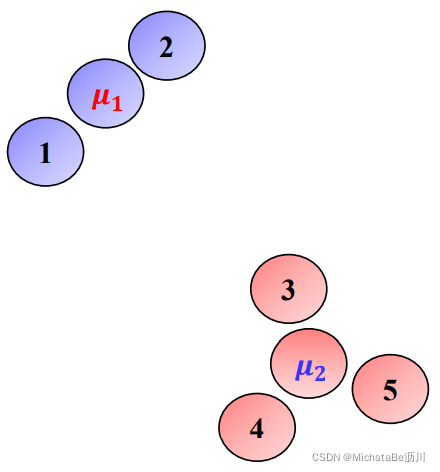
在K-Means聚类时,每个聚类簇的质心是隐含数据。假设K个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即EM算法的M步。重复这个E步和M步,直到质心不再变化为止,这样就完成了K-Means聚类。
Lloyd算法的优势:
- Lloyd算法属于期望最大化算法(EM算法),可以保证收敛到K-means问题的局部最优解;
- Lloyd算法速度快,计算复杂度为O(nk);
- Lloyd算法思想简单,实现容易,可扩展性强。
Lloyd算法的劣势:
- 簇的个数 k k k需要预先给定;
- 聚类结果依赖于初值的选取。
4.3 K-means++
K-means++是一种初始化方法,目的是改进K-means算法对初值的影响。流程如下:
- Step 1:随机选取一个簇的中心 μ 1 \mu_1 μ1;
- Step 2:选择离已有中心最远的数据点作为新的中心;
- Step 3:重复第二步,直至选出 k k k个中心;
- Step 4:运行K-means算法。
5. DBSCAN算法
5.1 概念
DBSCAN,即Density-Based Spatial Clustering of Applications with Noise,是一种基于密度的聚类算法。

5.2 优劣势分析
优势:
- 不需要指定簇的个数;
- 可以发现任意形状的簇;
- 擅长找到离群点(检测任务);
- 只需要两个参数。
劣势:
- 高维数据比较困难(可以降维);
- 参数难以选择(参数对结果的影响非常大);
- sklearn中效率很低(数据削减策略)。
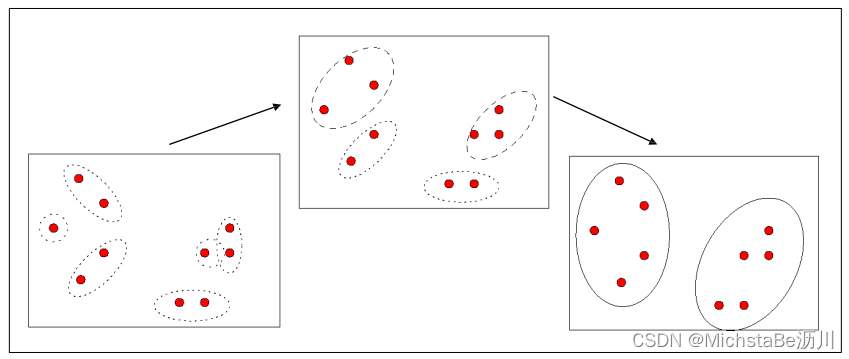
6. AGNES算法
AGNES,即AGglomerative NESting,是一种凝聚的层次聚类算法。流程如下:
- Step 1:将每个样本点作为一个簇;
- Step 2:合并最近的两个簇;
- Step 3:若所有样本点都存在于一个簇中,则停止;否则转到 Step 2。
7. 聚类性能度量
可参考这篇文章。
















 3180
3180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









