







前言:
在过去的一年中,虚拟人形象产业蓬勃发展,如今在各行各业特别是服务领域,越来越多地出现了虚拟人以及相关产品。在昨天举行的2019世界人工智能大会上,最先进最“黑科技”的产品都是与虚拟人相关。而如何使虚拟人能够被人们所见所感,最为重要的便是能让虚拟人形象能跟人类开始互动,而在背后控制虚拟人进行对话交流呈现的,便是我们今天要聊的口唇同步技术。
口唇同步技术:
口唇同步,即让声音与口唇图像实现协调匹配,并实时进行视频输出,在视觉与听觉等多重维度上提供无缝顺滑的体验。
将2D或3D虚拟人物的口型匹配到语音之上,通过不断改变人物嘴部及脸部的形状,做出逼近真人说话的效果,并保证声音和画面准确匹配的技术。然而传统的方式需要真人录制和手工调整,只适合大成本、非实时的应用场景,并不能适应当今信息传播的即时化、人们需求的多样化等变化。随着时代的发展,人们更需要小型的、个性化的和实时交互的应用体验。
汉语的音素模型——声韵母:
汉语不同于英文,有自己独特的声韵母体系,尽管世界上通用的模型是以发音为基本单位的音素模型,但更多是针对英文提出的规则,因此,在进行汉语音素拆分是我们常常使用声韵母作为基本的单位。
实现步骤:
传统的基于动画拼接方法的实现方法一般如下:
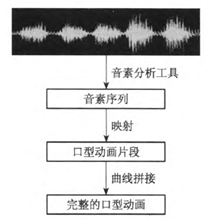

- 输入汉语文本
- 将文本转换为汉语拼音
- 从文本产生合成语音的样本
- 询问音频处理器,从语音播放处理器中决定当前音素
- 从当前音节的轨迹中计算出目前口型
- 合成语音同步的口型并且同步图形展示,返回4
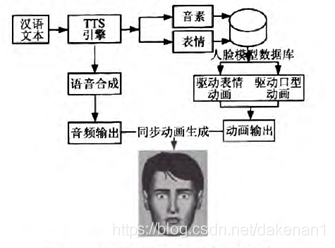
音画同步:
在输出语音的同时,我们希望虚拟人形象必须和说话的动作一致,也就是所谓的在时间轴上同步,那又是如何实现的呢?
其实这也不难,我们只要准确预测出每个音素的起止时间点,再讲动画片段对应上去即可。方法如下:
- 初始化音频服务器,返回开始时间
- 播放样本序列,返回样本时间、服务器时间,
- 计算出的相关动画驱动时间
- 面部图形更新,渲染并播放
结语:
至此,我们将如何对虚拟人进行呈现,将说话与嘴型一一对应的口唇同步技术进行了简要的介绍,接下来我们还会对虚拟人相关的技术以及产品应用做更多的技术分析与未来发展预测。希望读者能通过这篇文章对口唇同步技术有一个更好的理解,同时有更大的兴趣加入到虚拟人行业以及人工智能领域来。














 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









