




样例pdf
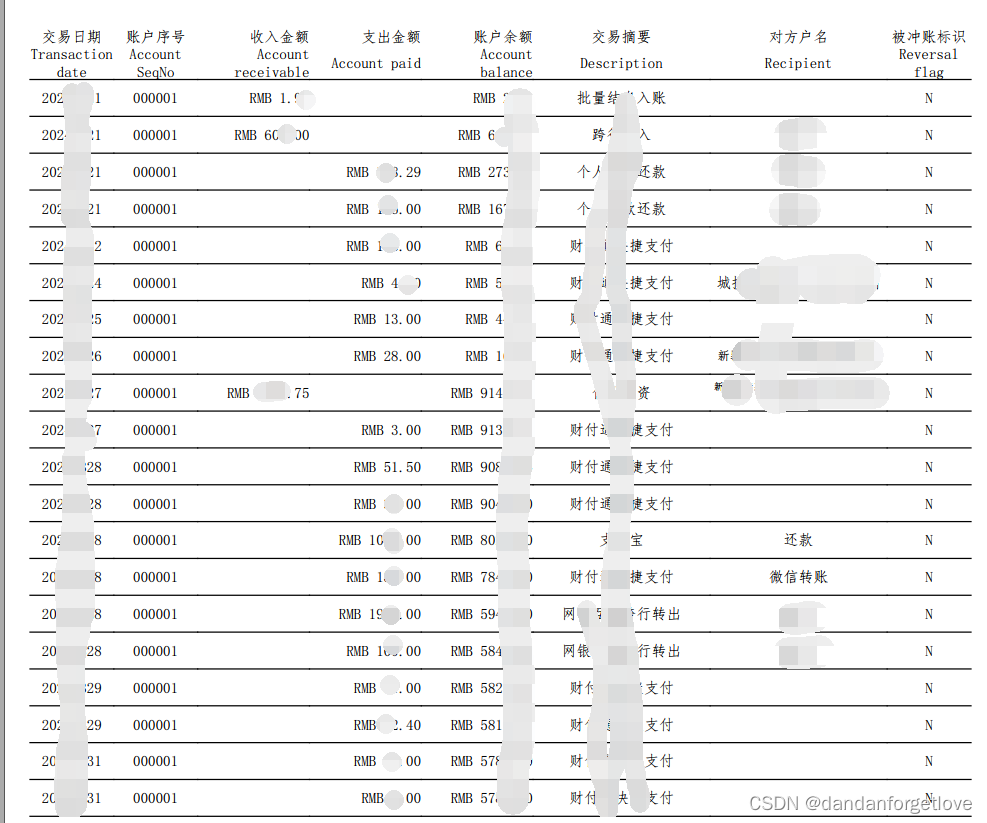
直接使用文本提取效果:
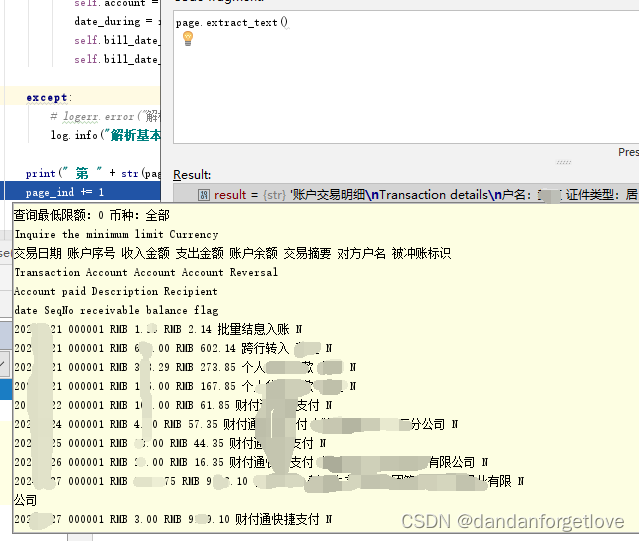
使用表格提取
根据提取的文本信息是没办法获取到表格数据的,太乱了。尤其是 3 4列。
解决:
自行画线,根据画线进行提取。
效果:
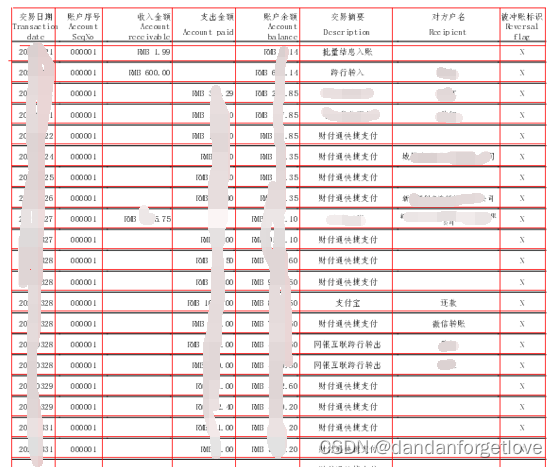
思路:
1.根据表头进行画竖线
2.根据行坐标画横线
3.根据坐标放入单元格的list中
4.拼接单元格文字。
问题:
根据表头画竖线,可能内容超出表头左右坐标。
解决办法:根据内容进行特殊匹配。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import re
import pdfplumber
import logging as log
class PDF(object):
file_path = None
config = {}
bill_date_begin = None
bill_date_end = None
parse_data = []
unit = None
trans_during = None
def __new__(cls, *args, **kwargs):
return super().__new__(cls)
def parse(self):
try:
with pdfplumber.open(self.file_path) as pdf:
page_ind = 1
log.info(" 发现总页数:{}".format(str(page_ind)))
for index, page in enumerate(pdf.pages):
print(" 第 " + str(page_ind) + " 页: ")
page_ind += 1
explicit_vertical_lines = []
explicit_horizontal_lines = []
explicit_horizontal_lines_y_line = []
explicit_horizontal_lines_h_line = []
explicit_horizontal_lines_keys = []
lines_dict = {}
table_begin = False
ts_y_list = {"jyzy": {"y": [-1, -1]}}
table_top = None
for ind, char in enumerate(page.chars):
next3Text = ""
if ind <= (len(page.chars) - 3):
next3Text = page.chars[ind]["text"] + page.chars[ind + 1]["text"] + page.chars[ind + 2]["text"]
if next3Text.find("交易日") > -1:
table_begin = True
if table_begin is False:
continue
if ind >= 2:
text = page.chars[ind - 2]["text"] + page.chars[ind - 1]["text"] + page.chars[ind]["text"]
if text.find("易日期") > -1 or text.find("出金额") > -1 or text.find("入金额") > -1 or text.find("户余额") > -1 or text.find("账标识") > -1 or text.find("户序号") > -1:
# print(text)
lines_dict = char
explicit_vertical_lines.append({
"x0": lines_dict["x1"] + 2,
"x1": lines_dict["x1"] + 2,
"y0": lines_dict["y0"],
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









