







1 因为大量样本训练代价比较高,建议先使用学习曲线评估是否需要这么大的数据量

2 使用随机梯度下降法替代批量梯度下降法,省去训练集求和以随机训练样本数据计算,降低代价:
但是此方法无法保证每一步都沿着正确方向下降,也可能无法收敛到最小点,在其周边徘徊:
![]()

收敛检查:每迭代x次,计算这x次代价均值,绘制图表如下

1> 图线下降,是在收敛的
2> 图线上下浮动不定,可增加x观察是否会下降
3> 图线上升,模型存在问题
训练时可以使学习率α随迭代次数增加减小,来迫使算法收敛,但这种计算消耗通常不值得;
3 小批量梯度下降,每次不是取随机一条样本,而是常数个训练实例(建议2-100),一定程度上保证了算法的表现方向。
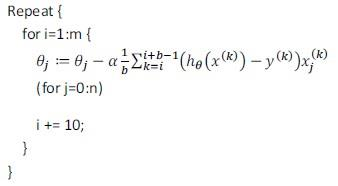
4 在线学习:对动态数据流进行学习而非静态数据集
如:大型寄件网站不断有用户咨询报价,用户提供起始地点,网站反馈报价,用户选择接受/拒绝(即结果),算法如下:

流程是类似于随机梯度下降的,因为用户每次访问都会动态的提供一条新训练样本。
好处是:模型拥有更好的用户适用性,会随着用户群的样本倾向不断变化而产生变化。
5 映射简化和数据并行
对批梯度下降,对于大量训练集循环计算偏导再求和开销非常大,这个时候还有一个方法,将这个大量的训练集分配
给多台计算机(/CPU核心)去并行处理,最后再将结果求和,这样便可以加速处理,称映射简化;
如下将400个训练实例交给4台计算机处理:

------------------------------------------------------------------------------------------------------------------------------------
文章内容学习整理于吴教授公开课课程与黄博士笔记,感谢!















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









