







综述
Linguistic Structure: Dependency parsing 语言结构:依存句法分析
1. Syntactic Structure: Consistency and Dependency (25 mins)
2. Dependency Grammar and Treebanks (15 mins)
3. Transition-based dependency parsing (15 mins)
4. Neural dependency parsing (15 mins)
正文
依存语法是给定一个输入句子,分析句子的句法依存结构的任务。依存句法的输出是一棵依存语法树,其中输入句子的单词是通过依存关系的方式连接。
1.语言结构的两种方式
CFGs(context-free grammars) 上下文无关语法

其主要步骤是先对每个词做词性分析part of speech, 简称POS,然后再将其组成短语,再将短语不断递归构成更大的短语。其中N(Noun)名词,Det(Determiner)限定词,Adj(Adjective)形容词,, P(Preposition)介词,NP(Noun Phrase)名词短语,PP(Preposition Phrase)介词短语,类似的还有VP(Verb Phrase)动词短语(如talk to)。
依赖结构展示了词语之间的依赖关系,一般两两之间使用有向边进行连接,同时会在边上标出具体的语法关系。

subj:subject mod:modifier

理解句子结构的原因
理论上,通过理解句子的结构,能够正确地解释语言,最主要就是为了防止歧义。
人类通过将单词组合成更大的单元来传达复杂的含义,从而传达复杂的思想。


介词短语附件多样性歧义
多个介词短语意味着更多的选择(卡特兰数通项式c(2n, n)/(n+1),数学系的可以出列)

协调范围歧义


形容词修饰语歧义

2.依存语法和依存结构
依赖性语法假定语法结构由词汇项之间的关系组成,通常是称为依赖性的二进制非对称关系(“箭头”)。
箭头将头(总督,上级,摄政)与从属(修饰语,下级,下属)联系起来。

或是另外种形式(依存语法)
回顾之前的两种表示形式,树形的带注释数据更为清晰,于是便有了通用依赖树库(一个带标注的数据集)

树库相比建立依存语法除了构建比较复杂比较缓慢之外,有以下几点好处:
• Reusability of the labor 可重用性
• Many parsers, part-of-speech taggers, etc. can be built on it 基于树库的词性标注等
• Valuable resource for linguistics 其他任务的重要资源
• Broad coverage, not just a few intuitions 覆盖范围广,不仅依赖于直觉,更专业
• Frequencies and distributional information 包含频率和分布信息
• A way to evaluate systems 也可用于评估
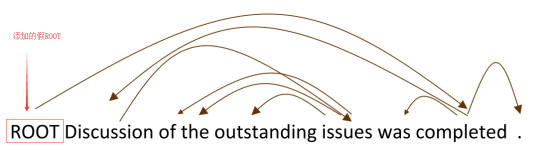
定义:当单词以线性顺序排列时,没有相交的依赖弧,所有弧都在单词上方。



3.Transition-Based Parsing
Transition-based Dependency Parsing可以看做是state machine,对于S=w0w1w2...wn,state由三部分构成(σ,β,A)。
A是dependency arc 构成的集合,每一条边的形式是(wi,r,wj),其中r描述了节点的依存关系如动宾关系等。
初始状态时,σ仅包含ROOT w0,β包含了所有的单词w1~wn,而A是空集∅。最终的目标是σ包含ROOT w0,β清空,此时A包含了所有的dependency arc。不断的进行三类操作,直到从初始态达到最终态。
SHIFT:将buffer中的第一个词移出并放到stack上。
LEFT-ARC:将(wj,r,wi)加入边的集合A,其中wi是stack上的次顶层的词,wj是stack上的最顶层的词。将wi从stack移除。(stack至少包含两个元素且wi不是ROOT)
RIGHT-ARC:将(wi,r,wj)加入边的集合A,其中wi是stack上的次顶层的词,wj是stack上的最顶层的词。将wj从stack移除。(stack至少包含两个元素)
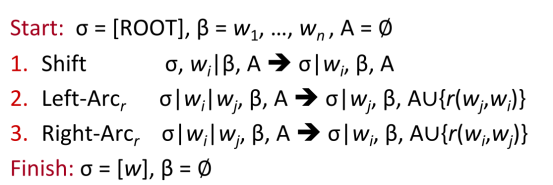



MaltParser
机器学习的部分在每个步骤中产生。当我们考虑到LEFT-ARC与RIGHT-ARC各有|R|(|R|为r的类的个数)种class,我们可以将其看做是class数为2|R|+1的分类问题,可以用SVM等传统机器学习方法解决。从而有接近线性时间的快速解析效果。

Evaluation of Dependency Parsing
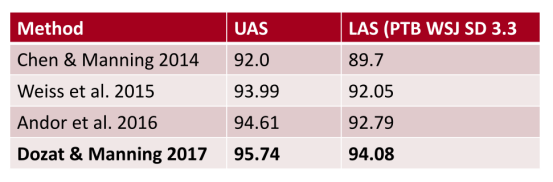
有两个metric,一个是LAS(labeled attachment score)即只有arc的箭头方向以及语法关系均正确时才算正确,以及UAS(unlabeled attachment score)即只要arc的箭头方向正确即可。

Handling non-projectivity
回顾之前所说的投影性,目前arc标准的依赖树仅构建投影性依赖树,如何解决非投影性的问题。
1. Just declare defeat on nonprojective arcs 在非投影弧上声明失败
2. Use dependency formalism which only has projective representations
• CFG only allows projective structures; you promote head of violations
3. Use a postprocessor to a projective dependency parsing algorithm to
identify and resolve nonprojective links 后续处理
4. Add extra transitions that can model at least most non-projective
structures (e.g., add an extra SWAP transition, cf. bubble sort) 添加额外的转移过程
5. Move to a parsing mechanism that does not use or require any
constraints on projectivity (e.g., the graph-based MSTParser) 换个支持的算法...
4.Neural Dependency Parsing
1.稀疏性。一个是关系类别较多维度会变得很大,另外就是词汇特征表示较稀疏。
为每个单词的每个可能依赖计算得分,将最高分作为其依赖,添加边。
前提是每个单词需要有非常良好的特征表示且包含上下文位置信息。
缺点是计算量太大,n个词要计算n^2个可能依赖项(仅考虑最高阶)

A Fast and Accurate Dependency Parser using Neural Networks
也许看过视频的同学会问,其实这篇论文只算是神经网络实现句法依存解析发展中部的一篇论文,也不是最高准确率的,为什么只讲这个呢?
是不是因为他在ppt上篇幅多点?是不是因为论文作者是女生啊?是不是看不起男生啊?
是的,原因就是她很强,推荐大家顺便抽空看一下《NEURAL READING COMPREHENSION AND BEYOND》(别人的毕业论文,完整的阐释了对于阅读理解任务的见解和研究),当然我可以推荐个别人的读后感:https://blog.csdn.net/cindy_1102/article/details/88714390
就是上文所述为何使用神经网络取代传统机器学习,解决了问题,提高了多少精度和效率。
介绍谁谁的贡献,发展历史等等,其实就是之前我所说的最主要的基于转移的依存树的解析过程。
The main contributions of this work are:
(i) showing the usefulness of dense representations that are learned within the parsing task,
(ii) developing a neural network architecture that gives good accuracy and speed, and
(iii)introducing a novel activation function for the neural network that better captures higher-order interaction features.
(iii)为神经网络引入一种新的激活函数,能更好地捕捉高阶交互特性。
II Transition-based Dependency Parsing
没错,她的论文中也详细介绍了基于转移的依存树解析的原理和训练过程。并且详细描述了上面那三个问题。

III Neural Network Based Parser


特征选择:对给定句子S包含一些子集:
1.Sword:在堆σ的顶部和缓冲区β的S中一些单词的词向量(和它们的依存)。
2.Stag:在S中一些单词的词性标注(POS)。词性标注是由一个离散集合组成:
![]()
3.Slabel:在S中一些单词的依存标签。依存标签是由一个依存关系的离散集合组成:
![]()
对每种特征类型,我们都有一个对应的将特征的one-hot编码映射到一个d维的稠密的向量表示的嵌入矩阵。
Sword、Stag、Slabel的完全嵌入矩阵分别入下图所示,其中Nw是字典/词汇表的大小,Nt是词性标志数量的大小,Nl是依存标签的个数,R表示实数集,d*N表示维度大小。定义从每组特征中选出的元素的数量分别为nword,ntag,nlabel。
![]()
![]()
![]()

训练时损失函数:交叉熵+L2正则化部分
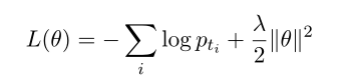
TIPS:
1.选取立方体激活函数是因为在这个函数能够包含三个部分各种乘积组合,理论上覆盖全部特征。
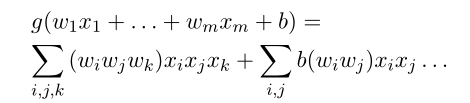
2.会使用预训练的embedding层,即图中从configura中获取特征的步骤,从而减少特征计算的时间。
对于参数的初始化,我们使用预训练的词嵌入来初始化Ew,对Et和El使用(-0.01,0.01)内的随机初始化。(E表示嵌入向量矩阵)

IV Experiments及以后















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









