




1 Llama_Index(核心组件介绍)
中文https://llama-index.readthedocs.io/zh/latest/guides/primer/usage_pattern.html
英文https://docs.llamaindex.ai/en/stable/
1.1.什么是LlamaIndex
LlamaIndex 是一个用于 LLM 应用程序的数据框架,用于注入,结构化,并访问私有或特定领域数据。
LlamaIndex为何而生?
在本质上,LLM(如GPT)为人类和推断出的数据提供了基于自然语言的交互接口。广泛可用的大模型通常在大量公开可用的数据上进行的预训练,包括来自维基百科、邮件列表、书籍和源代码等。
构建在LLM模型之上的应用程序通常需要使用私有或特定领域数据来增强这些模型。不幸的是,这些数据可能分布在不同的应用程序和数据存储中。它们可能存在于API之后、SQL数据库中,或者存在在PDF文件以及幻灯片中。
1.2.LlamaIndex核心组件介绍
LlamaIndex 提供了5大核心工具:Data connectors,Data indexes,Engines,Data agents,Application integrations
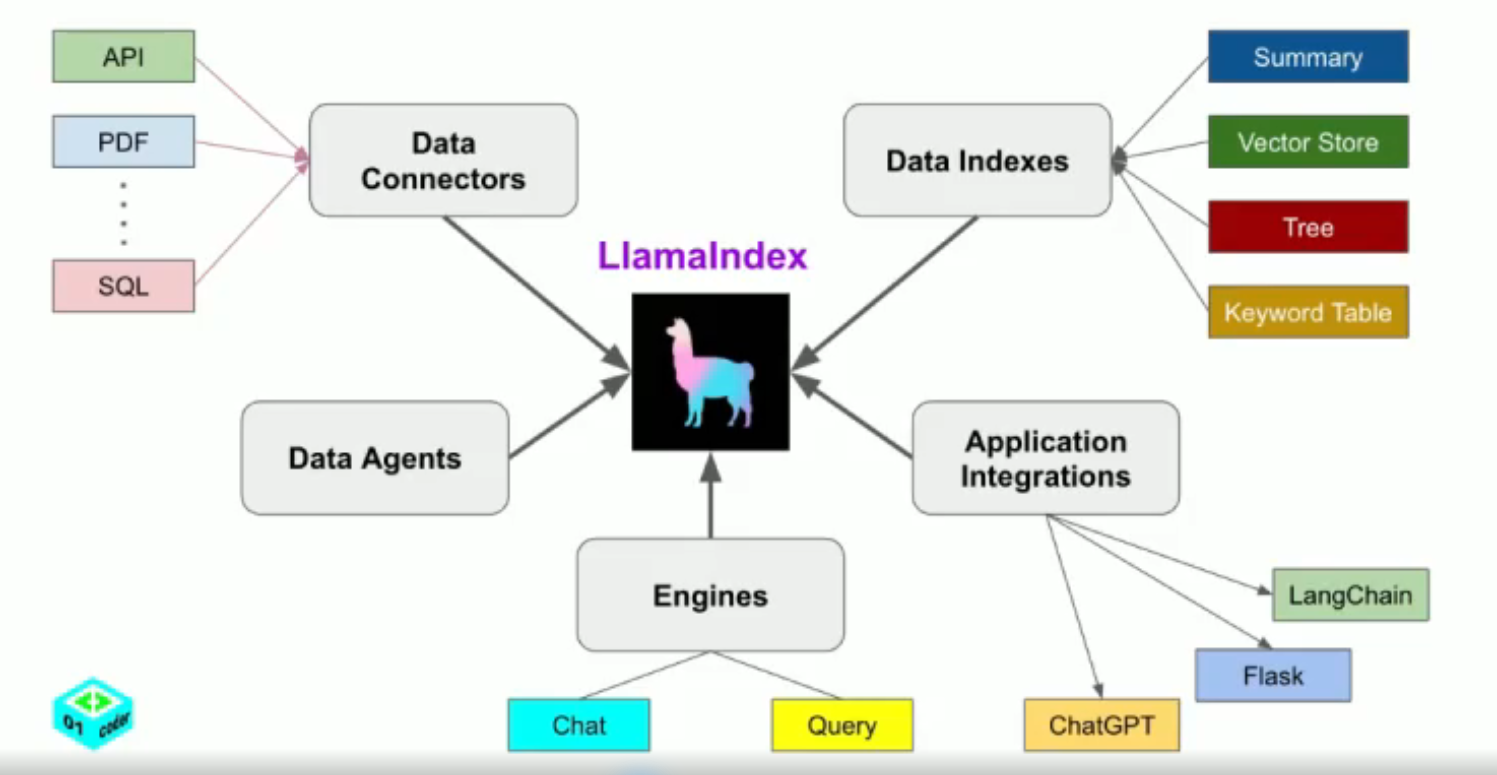
LlamaIndex 帮助构建 LLM 驱动的,基于个人或私域数据的应用。RAG(Retrieval Augmented Generation) 是 LlamaIndex 应用的核心概念。
RAG,也称为检索增强生成,是利用个人或私域数据增强 LLM 的一种范式。通常,它包含两个阶段:
- 索引
构建知识库。 - 查询
从知识库检索相关上下文信息,以辅助 LLM 回答问题。
LlamaIndex 提供了工具包帮助开发者极其便捷地完成这两个阶段的工作。
索引阶段
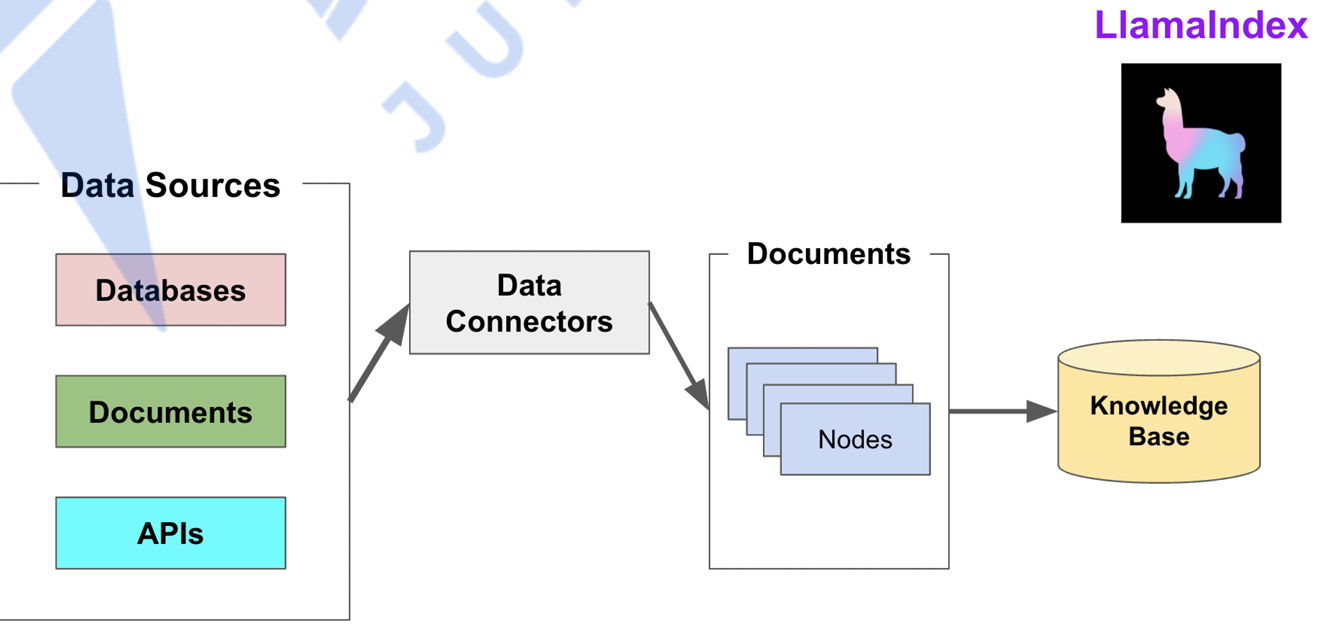
LlamaIndex 通过提供 Data connectors(数据连接器) 和 Indexes (索引) 帮助开发者构建知识库。
该阶段会用到如下工具或组件:
Data connectors
数据连接器。它负责将来自不同数据源的不同格式的数据注入,并转换为文档(Document)表现形式,其中包含了文本和元数据。
Documents / Nodes
Document是 LlamaIndex 支持的文LlamaIndex 中容器的概念,它可以包含任何数据源,包括,PDF文档,API响应,或来自数据库的数据。
Node是 LlamaIndex 中数据的最小单元,代表了一个 Document的分块。它还包含了元数据,以及与其他Node的关系信息。这使得更精确的检索操作成为可能。
Data Indexes
LlamaIndex 提供便利的工具,帮助开发者为注入的数据建立索引,使得未来的检索简单而高效。最常用的索引是向量存储索引 - VectorStoreIndex 。
查询阶段
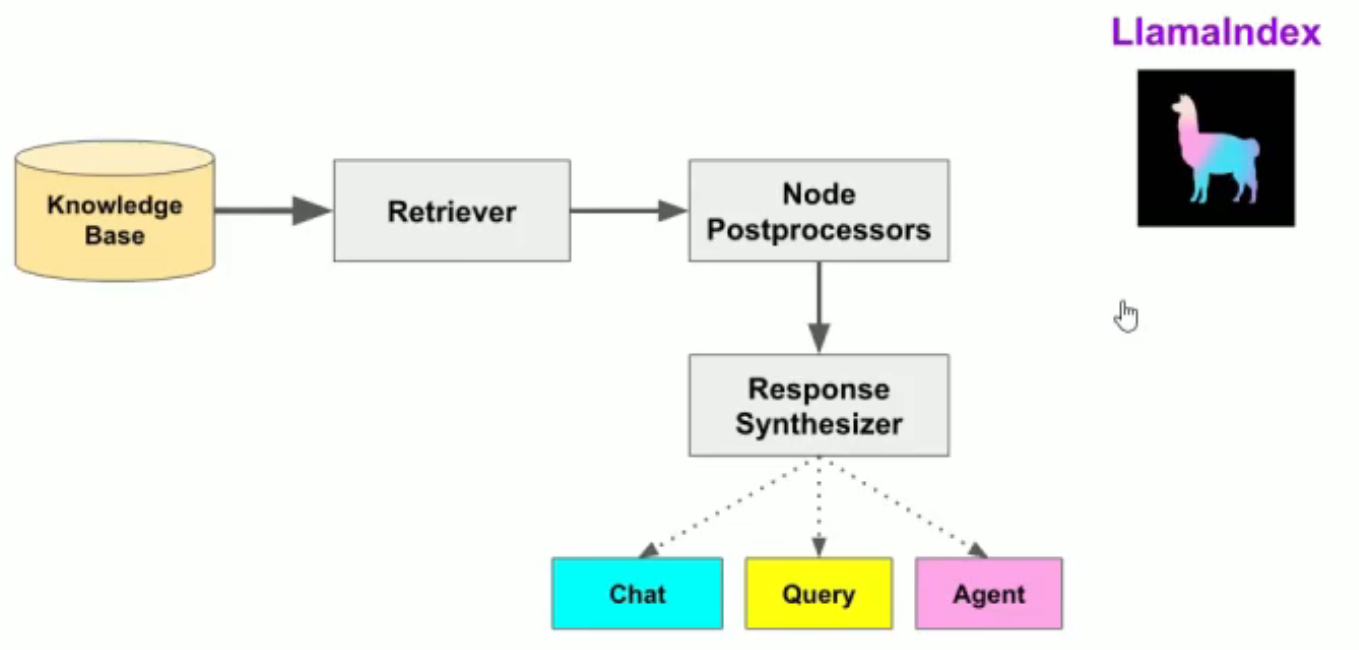
在查询阶段,RAG 管道根据的用户查询,检索最相关的上下文,并将其与查询一起,传递给 合成响应。这使 LLM 能够获得不在其原始训练数据中的最新知识,同时也减少了虚构内容。该阶段的关键挑战在于检索、编排和基于知识库的推理。
LlamaIndex 提供可组合的模块,帮助开发者构建和集成 RAG 管道,用于问答、聊天机器人或作为代理的一部分。这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行推理。
该阶段的构建块包括:
Retrievers。检索器。它定义如何高效地从知识库,基于查询,检索相关上下文信息。
Node Postprocessors。Node后处理器。它对一系列文档节点(Node)实施转换,过滤,或排名。
Response Synthesizers。响应合成器。它基于用户的查询,和一组检索到的文本块(形成上下文),利用 LLM生成响应。
RAG管道包括:
Query Engines。查询引擎 - 端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下文。
Chat Engines。聊天引擎 - 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史)。
Agents。代理。它是一种由 LLM 驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这为其提供了处理更复杂任务的额外灵活性。
2 LlamaIndex快速构建RAG
2.1环境配置
使用 conda 配置项目python环境
# 创建环境
conda create -n rag python=3.12 -y
# 激活环境
conda activate rag
安装包
#pip install -r requirement.txt
accelerate==1.6.0
aiohappyeyeballs==2.6.1
aiohttp==3.11.16
aiosignal==1.3.2
annotated-types==0.7.0
anyio==4.9.0
attrs==25.3.0
banks==2.1.1
beautifulsoup4==4.13.4
certifi==2025.1.31
charset-normalizer==3.4.1
click==8.1.8
colorama==0.4.6
dataclasses-json==0.6.7
Deprecated==1.2.18
dirtyjson==1.0.8
distro==1.9.0
filelock==3.18.0
filetype==1.2.0
frozenlist==1.5.0
fsspec==2025.3.2
greenlet==3.2.0
griffe==1.7.2
h11==0.14.0
httpcore==1.0.8
httpx==0.28.1
huggingface-hub==0.30.2
idna==3.10
Jinja2==3.1.6
jiter==0.9.0
joblib==1.4.2
llama-cloud==0.1.18
llama-cloud-services==0.6.12
llama-index==0.12.30
llama-index-agent-openai==0.4.6
llama-index-cli==0.4.1
llama-index-core==0.12.30
llama-index-embeddings-huggingface==0.5.3
llama-index-embeddings-openai==0.3.1
llama-index-indices-managed-llama-cloud==0.6.11
llama-index-llms-huggingface==0.5.0
llama-index-llms-openai==0.3.35
llama-index-multi-modal-llms-openai==0.4.3
llama-index-program-openai==0.3.1
llama-index-question-gen-openai==0.3.0
llama-index-readers-file==0.4.7
llama-index-readers-llama-parse==0.4.0
llama-parse==0.6.12
MarkupSafe==3.0.2
marshmallow==3.26.1
modelscope==1.25.0
mpmath==1.3.0
multidict==6.4.3
mypy-extensions==1.0.0
nest-asyncio==1.6.0
networkx==3.4.2
nltk==3.9.1
numpy==2.2.4
nvidia-cublas-cu12==12.4.5.8
nvidia-cuda-cupti-cu12==12.4.127
nvidia-cuda-nvrtc-cu12==12.4.127
nvidia-cuda-runtime-cu12==12.4.127
nvidia-cudnn-cu12==9.1.0.70
nvidia-cufft-cu12==11.2.1.3
nvidia-curand-cu12==10.3.5.147
nvidia-cusolver-cu12==11.6.1.9
nvidia-cusparse-cu12==12.3.1.170
nvidia-cusparselt-cu12==0.6.2
nvidia-ml-py==12.570.86
nvidia-nccl-cu12==2.21.5
nvidia-nvjitlink-cu12==12.4.127
nvidia-nvtx-cu12==12.4.127
nvitop==1.4.2
openai==1.74.0
packaging==24.2
pandas==2.2.3
pillow==11.2.1
pip==25.0
platformdirs==4.3.7
propcache==0.3.1
psutil==7.0.0
pydantic==2.11.3
pydantic_core==2.33.1
pypdf==5.4.0
python-dateutil==2.9.0.post0
python-dotenv==1.1.0
pytz==2025.2
PyYAML==6.0.2
regex==2024.11.6
requests==2.32.3
safetensors==0.5.3
scikit-learn==1.6.1
scipy==1.15.2
sentence-transformers==4.1.0
setuptools==75.8.0
six==1.17.0
sniffio==1.3.1
soupsieve==2.6
SQLAlchemy==2.0.40
striprtf==0.0.26
sympy==1.13.1
tenacity==9.1.2
threadpoolctl==3.6.0
tiktoken==0.9.0
tokenizers==0.21.1
torch==2.6.0
tqdm==4.67.1
transformers==4.51.3
triton==3.2.0
typing_extensions==4.13.2
typing-inspect==0.9.0
typing-inspection==0.4.0
tzdata==2025.2
urllib3==2.4.0
wheel==0.45.1
wrapt==1.17.2
yarl==1.19.0
2.2 测试本地模型
运行模型
from llama_index.core.llms import ChatMessage
from llama_index.llms.huggingface import HuggingFaceLLM
#使用HuggingFaceLLM加载本地大模型
llm = HuggingFaceLLM(model_name="/root/model/Qwen/Qwen1___5-1___8B-Chat",
tokenizer_name="/root/model/Qwen/Qwen1___5-1___8B-Chat",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True})
#调用模型chat引擎得到回复
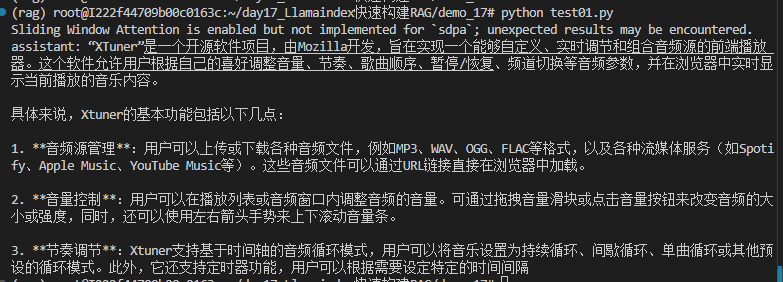
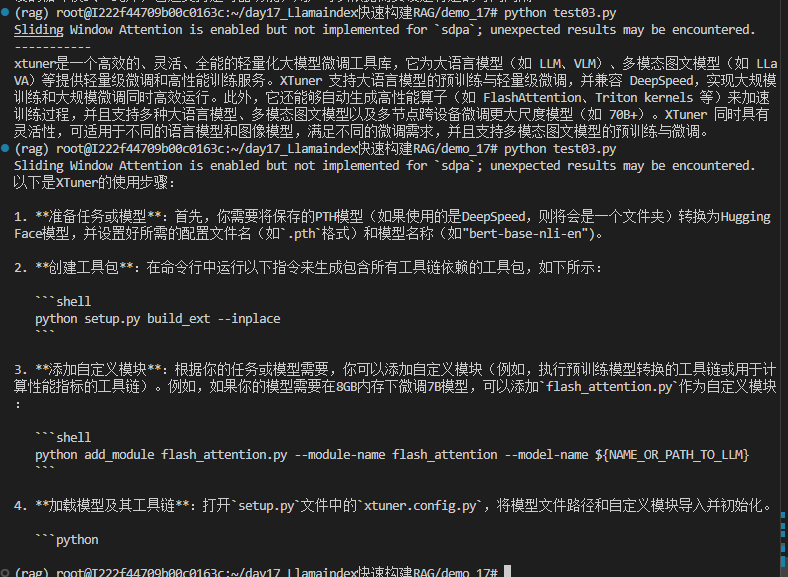
rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")])
print(rsp)
进行提问测试,得到结果如下。可以看出模型本身并不具备关于xtuner 的相关知识,一本正经的乱回答。
2.3.下载Sentence Transformer 模型
在进行RAG之前,需要使用词向量模型进行Embedding,将文本进行向量化处理,此处选择 Sentence Transformer 模型。执行下载。
#模型下载
from modelscope.hub.snapshot_download import snapshot_download
# model_dir = snapshot_download('Qwen/Qwen3-1.7B')
model_dir = snapshot_download('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2',cache_dir='./model')
2.4.基于llamaindex快速构建RAG
运行次测试后,可以看到可以正确回答,并且可以给出回答的出处
不同节点分割方法
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings,SimpleDirectoryReader,VectorStoreIndex
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.node_parser import SimpleNodeParser
#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,这样在后续的索引构建过程中,就会使用这个模型
Settings.embed_model = embed_model
#使用HuggingFaceLLM加载本地大模型
llm = HuggingFaceLLM(model_name="/root/model/Qwen/Qwen1___5-1___8B-Chat",
tokenizer_name="/root/model/Qwen/Qwen1___5-1___8B-Chat",
model_kwargs={"trust_remote_code":True},
tokenizer_kwargs={"trust_remote_code":True})
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm
#从指定目录读取文档,将数据加载到内存
documents = SimpleDirectoryReader("/root/day17_Llamaindex快速构建RAG/demo_17/data").load_data()
# print(documents)
#创建节点解析器,点进去可以看到不同的分割方法
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
#将文档分割成节点
base_node = node_parser.get_nodes_from_documents(documents=documents)
# print(documents)
# print(base_node)
# print("=================================")
#根据自定义的node节点构建向量索引
index = VectorStoreIndex(nodes=base_node)
#创建一个VectorStoreIndex,并使用之前加载的文档来构建向量索引
#此索引将文档转换为向量,并存储这些向量(内存)以便于快速检索
# index = VectorStoreIndex.from_documents(documents)
#将索引持久化存储到本地的向量数据库
index.storage_context.persist()
#创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
rsp = query_engine.query("xtuner是什么?")
#rsp = query_engine.query("xtuner的使用步骤是什么?")
print(rsp)
3.Llama_index RAG进阶(Embedding_model与ChromaDB)
3.1 Embedding Models 嵌入模型原理及选择
概念与核心原理
嵌入模型的本质
嵌入模型(Embedding Model)是一种将离散数据(如文本、图像)映射到连续向量空间的技术。通过高维向量表示(如 768 维或 3072 维),模型可捕捉数据的语义信息,使得语义相似的文本在向量空间中距离更近。例如,“忘记密码”和“账号锁定”会被编码为相近的向量,从而支持语义检索而非仅关键词匹配。
核心作用
语义编码:将文本、图像等转换为向量,保留上下文信息(如 BERT 的 CLS Token 或均值池化。
相似度计算:通过余弦相似度、欧氏距离等度量向量关联性,支撑检索增强生成(RAG)、推荐系统等应用。
信息降维:压缩复杂数据为低维稠密向量,提升存储与计算效率。
关键技术原理
上下文依赖:现代模型(如 BGE-M3)动态调整向量,捕捉多义词在不同语境中的含义。
训练方法:对比学习(如 Word2Vec 的 Skip-gram/CBOW)、预训练+微调(如 BERT)。
主流模型分类与选型指南
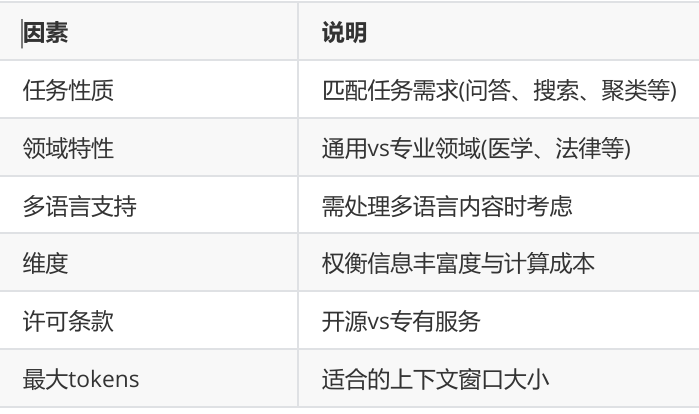
Embedding模型将文本转换为数值向量,捕捉语义信息,使计算机能够理解和比较内容的"意义"。
选择Embedding模型的考虑因素:
最佳实践
为特定应用测试多个embedding模型,评估在实际数据上的性能而非仅依赖通用基准。
1. 通用全能型
BGE-M3:北京智源研究院开发,支持多语言、混合检索(稠密+稀疏向量),处理 8K 上下文,适合企业级知识库。
NV-Embed-v2:基于 Mistral-7B,检索精度高(MTEB 得分 62.65),但需较高计算资源。
2.垂直领域特化型
中文场景:BGE-large-zh-v1.5 (合同/政策文件)、
多模态场景:M3E-base (社交媒体分析)。BGE-VL (图文跨模态检索),联合编码 OCR 文本与图像特征。
3.轻量化部署型
nomic-embed-text:768 维向量,推理速度比 OpenAI 快 3 倍,适合边缘设备。
gte-qwen2-1.5b-instruct:1.5B 参数,16GB 显存即可运行,适合初创团队原型验。
选型决策树:
- 中文为主 → BGE 系列 > M3E;
- 多语言需求 → BGE-M3 > multilingual-e5;
- 预算有限 → 开源模型(如 Nomic Embed)
embedding_model效果对比
#embedding_model效果对比
from sentence_transformers import SentenceTransformer, util
import json
import numpy as np
# 加载SQuAD数据(假设已处理成列表格式)
with open("squad_dev.json") as f:
squad_data = json.load(f)["data"]
# 提取问题和答案对
qa_pairs = []
for article in squad_data:
for para in article["paragraphs"]:
for qa in para["qas"]:
if not qa["is_impossible"]:
qa_pairs.append({
"question": qa["question"],
"answer": qa["answers"][0]["text"],
"context": para["context"]
})
# 初始化两个本地模型
model1 = SentenceTransformer('/root/model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2') # 模型1
model2 = SentenceTransformer('/root/model/sungw111/text2vec-base-chinese-sentence') # 模型2
# 编码所有上下文(作为向量库)
contexts = [item["context"] for item in qa_pairs]
context_embeddings1 = model1.encode(contexts) # 模型1的向量库
context_embeddings2 = model2.encode(contexts) # 模型2的向量库
# 评估函数
def evaluate(model, query_embeddings, context_embeddings):
correct = 0
for idx, qa in enumerate(qa_pairs[:100]): # 测试前100条
# 查找最相似上下文
sim_scores = util.cos_sim(query_embeddings[idx], context_embeddings)
best_match_idx = np.argmax(sim_scores)
# 检查答案是否在匹配段落中
if qa["answer"] in contexts[best_match_idx]:
correct += 1
return correct / len(qa_pairs[:100])
# 编码所有问题
query_embeddings1 = model1.encode([qa["question"] for qa in qa_pairs[:100]])
query_embeddings2 = model2.encode([qa["question"] for qa in qa_pairs[:100]])
# 执行评估
acc1 = evaluate(model1, query_embeddings1, context_embeddings1)
acc2 = evaluate(model2, query_embeddings2, context_embeddings2)
print(f"模型1准确率: {acc1:.2%}")
print(f"模型2准确率: {acc2:.2%}")

代码案例操作
使用 HuggingFace 加载 BGE 模型进行文本嵌入
# 安装依赖:pip install llama-index transformers torch numpy
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import numpy as np
# 加载 BGE 中文嵌入模型
model_name = "/root/model/sungw111/text2vec-base-chinese-sentence"
# model_name = "/root/model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
embed_model = HuggingFaceEmbedding(
model_name=model_name,
device="cuda", # 使用 GPU,如果没有 GPU 改为 "cpu"
normalize=True, # 归一化向量,方便计算余弦相似度
)
# 嵌入文档
documents = ["忘记密码如何处理?", "用户账号被锁定"]
doc_embeddings = [embed_model.get_text_embedding(doc) for doc in documents]
# 嵌入查询并计算相似度
query = "密码重置流程"
query_embedding = embed_model.get_text_embedding(query)
# 计算余弦相似度(因为 normalize=True,点积就是余弦相似度)
similarity = np.dot(query_embedding, doc_embeddings[0])
print(f"相似度:{similarity:.4f}") # 输出示例:0.8512

3.2Chroma向量数据库
Chroma 核心概念与优势
1. 什么是 Chroma?
Chroma 是一款开源的向量数据库,专为高效存储和检索高维向量数据设计。其核心能力在于语义相似性搜索,支持文本、图像等嵌入向量的快速匹配,广泛应用于大模型上下文增强(RAG)、推荐系统、多模态检索等场景。与传统数据库不同,Chroma 基于向量距离(如余弦相似度、欧氏距离)衡量数据关联性,而非关键词匹配。
2. 核心优势
轻量易用:以 Python/JS 包形式嵌入代码,无需独立部署,适合快速原型开发。
灵活集成:支持自定义嵌入模型(如 OpenAI、HuggingFace),兼容 LangChain 等框架。
高性能检索:采用 HNSW 算法优化索引,支持百万级向量毫秒级响应。
多模式存储:内存模式用于开发调试,持久化模式支持生产环境数据落地。
安装与基础配置
1. 安装
通过 Python 包管理器安装 ChromaDB:
pip install chromadb # 完整功能
2. 初始化客户端
内存模式(开发环境):
import chromadb
client = chromadb.Client()
#持久化模式(生产环境):
client = chromadb.PersistentClient(path="/path/to/save") # 数据保存至本地目录
核心操作全流程
1. 创建集合(Collection)
集合是 Chroma 中管理数据的基本单元,类似传统数据库的表:
#指定余弦相似度计算
collection = client.create_collection(name="my_collection",metadata={"hnsw:space": "cosine"},embedding_function=HuggingFaceEmbeddings(model_name="BAAI/bge-small") # 自定义嵌入模型
2. 添加数据
支持自动生成或手动指定嵌入向量:
#方式1:自动生成向量(使用集合的嵌入模型)
collection.add(
documents=["文档内容1", "文档内容2"],
metadatas=[{"来源": "新闻"}, {"来源": "论文"}],
ids=["id1", "id2"]
)
#方式2:手动传入预计算向量
collection.add(
embeddings=[[0.1, 0.2, ...], [0.3, 0.4, ...]],
documents=["文本1", "文本2"],
ids=["id3", "id4"]
)
3. 查询数据
#文本查询(自动向量化):
results = collection.query(
query_texts=["查询文本"],
n_results=5,
where={"来源": "新闻"}, # 按元数据过滤
where_document={"$contains": "关键词"} # 按文档内容过滤
)
#向量查询(自定义输入):
results = collection.query(
query_embeddings=[[0.5, 0.6, ...]],
n_results=3
)
4. 数据管理
#更新:
collection.update(ids=["id1"], documents=["新内容"])
#删除:
collection.delete(ids=["id2"])
#统计:
collection.count() 获取条目
模型对比
import chromadb
from sentence_transformers import SentenceTransformer
class SentenceTransformerEmbeddingFunction:
def __init__(self, model_path: str, device: str = "cuda"):
self.model = SentenceTransformer(model_path, device=device)
def __call__(self, input: list[str]) -> list[list[float]]:
if isinstance(input, str):
input = [input]
return self.model.encode(input, convert_to_numpy=True).tolist()
# 创建/加载集合(含自定义嵌入函数)
embed_model = SentenceTransformerEmbeddingFunction(
# model_path="/root/model/sungw111/text2vec-base-chinese-sentence",
model_path="/root/model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
device="cuda" # 无 GPU 改为 "cpu"
)
# 创建客户端和集合
client = chromadb.Client()
collection = client.create_collection("my_knowledge_base",metadata={"hnsw:space": "cosine"},embedding_function=embed_model)
# 添加文档
collection.add(
documents=["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示","三英战吕布"],
metadatas=[{"source": "tech_doc"}, {"source": "tutorial"}, {"source": "tutorial1"}],
ids=["doc1", "doc2","doc3"]
)
# 查询相似文档
results = collection.query(
query_texts=["什么是RAG技术?"],
n_results=3
)
print(results)
collection.update(
ids=["doc1"], # 使用已存在的ID
documents=["更新后的RAG技术内容"]
)
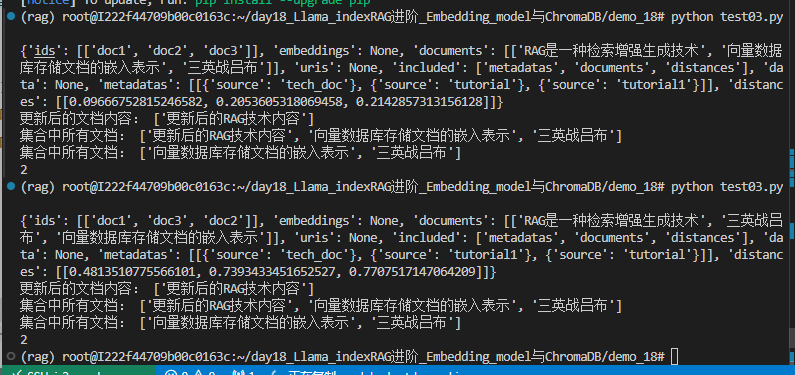
# 查看更新后的内容 - 方法1:使用get()获取特定ID的内容
updated_docs = collection.get(ids=["doc1"])
print("更新后的文档内容:", updated_docs["documents"])
# 查看更新后的内容 - 方法2:查询所有文档
all_docs = collection.get()
print("集合中所有文档:", all_docs["documents"])
#删除内容
collection.delete(ids=["doc1"])
# 查看更新后的内容 - 方法2:查询所有文档
all_docs = collection.get()
print("集合中所有文档:", all_docs["documents"])
#统计条目
print(collection.count())
4 Llama_indexRAG进阶_文档切分与重排序
4.1文档解析方案
什么是文档解析?
就像把不同包装的食品拆开处理:
PDF文件 → 罐头食品(需要专用工具打开)
Word文档 → 盒装饼干(容易拆但可能有碎屑)
扫描件/图片 → 真空包装(需要剪刀才能打开)
分步详解:
- 文件加载:找到文档存放位置,就像在电脑文件夹中定位文件
常见问题:文件损坏 → 检查文件是否能正常打开 - 格式转换:统一转为纯文本,就像把不同货币兑换成美元
示例:将PDF中的表格转为Markdown格式 - 元数据提取:获取文档信息标签,就像查看食品包装上的生产日期
包括:作者、创建时间、文档类型等 - 结构化处理:整理内容层次,就像把食材分类放入保鲜盒
建立标题层级:章节 > 段落 > 句子
技术难点解析:
处理扫描件: - 使用OCR(光学字符识别)技术识别文字
- 校正识别错误(如将"3"识别为"B")
- 保留原始版式信息
处理复杂表格:
#表格解析结果示例
| 姓名 | 年龄 | 职业
|
|--------|------|------------|
| 张三 | 28 | 工程师 |
| 李四 | 35 | 设计师 |
基础解析 vs 高级解析
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(
input_files=["/root/day19_Llama_indexRAG进阶_文档切分与重排序/demo_19/README_zh-CN.md"]
)
# reader = SimpleDirectoryReader(
# "/home/cw/projects/demo_20/data"
# )
docs = reader.load_data()
print(f"Loaded {len(docs)} docs")
print(docs)
print('-'*100)
# # 案例2:高级解析
import pdfplumber
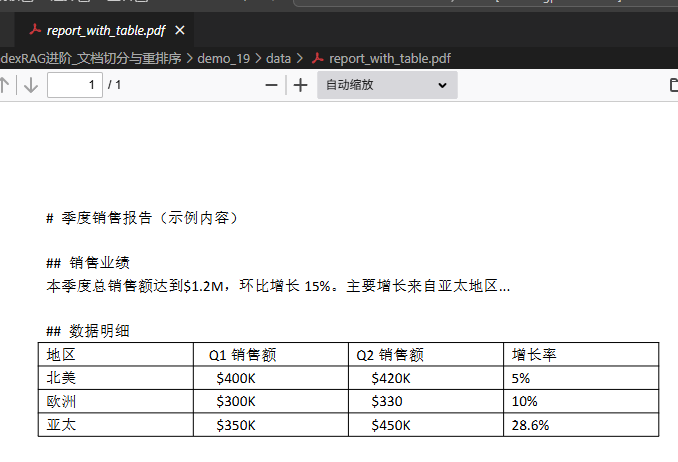
with pdfplumber.open("/root/day19_Llama_indexRAG进阶_文档切分与重排序/demo_19/data/report_with_table.pdf") as pdf:
# 提取所有文本
text = ""
for page in pdf.pages:
text += page.extract_text()
print(text[:200]) # 打印前200字符
# 提取表格(自动检测)
for page in pdf.pages:
tables = page.extract_tables()
for table in tables:
print("\n表格内容:")
for row in table:
print(row)
4.2模块二:文本切分方案
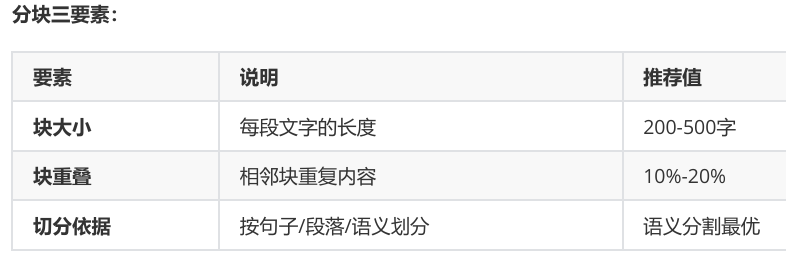
为什么需要分块?
就像用收纳盒整理衣物:
太大 → 找衣服时要把整个箱子倒出来
太小 → 需要开太多盒子才能凑齐一套
分块常见问题:
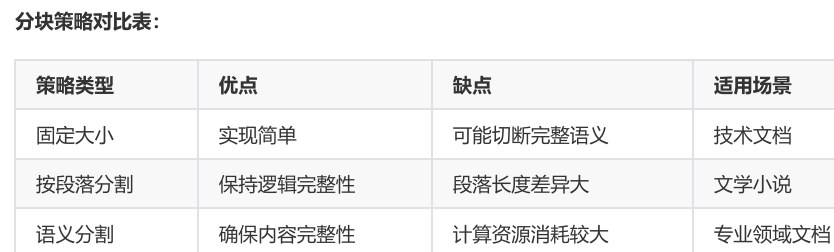
问题1:如何确定最佳块大小?
→ 测试不同尺寸查看检索效果
计算资源消耗较大
# 测试块大小对召回率的影响
sizes = [128, 256, 512]
for size in sizes:
test_recall = evaluate_chunk_size(size)
print(f"块大小{size} → 召回率{test_recall:.2f}%")
问题2:分块重叠是否越多越好?
→ 适当重叠(10-20%)可防止信息断裂,但过多会导致冗余
固定分块
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleDirectoryReader
# 加载所有文档
documents = SimpleDirectoryReader(input_files=["/root/day19_Llama_indexRAG进阶_文档切分与重排序/demo_19/data/ai.txt"]).load_data()
#使用固定节点切分
from llama_index.core.node_parser import TokenTextSplitter
fixed_splitter = TokenTextSplitter(chunk_size=256, chunk_overlap=20)
fixed_nodes = fixed_splitter.get_nodes_from_documents(documents)
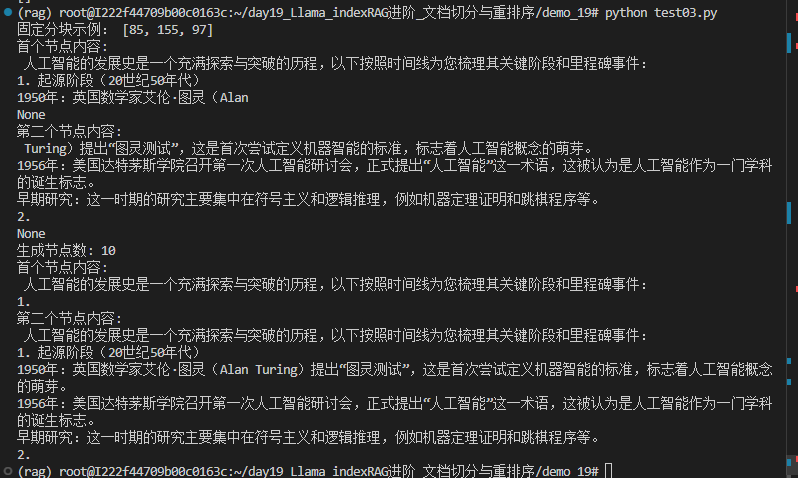
print("固定分块示例:", [len(n.text) for n in fixed_nodes[:3]]) # 输出:[200, 200, 200]
print(print("首个节点内容:\n", fixed_nodes[0].text))
print(print("第二个节点内容:\n", fixed_nodes[1].text))
# 使用句子分割器
splitter = SentenceSplitter(chunk_size=256)
nodes = splitter.get_nodes_from_documents(documents)
# 查看结果
print(f"生成节点数: {len(nodes)}")
print("首个节点内容:\n", nodes[0].text)
print("第二个节点内容:\n", nodes[1].text)
语义分块
from llama_index.core import SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core.node_parser import SemanticSplitterNodeParser
import os
# 2. 加载文档
documents = SimpleDirectoryReader(input_files=["/root/day19_Llama_indexRAG进阶_文档切分与重排序/demo_19/data/test.txt"]).load_data()
# # 3. 筛选Markdown文档
# md_docs = [d for d in documents if d.metadata["file_path"].endswith(".md")]
# 4. 初始化模型和解析器
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径
model_name="/root/model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
)
semantic_parser = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=90,
embed_model=embed_model
)
# 5. 执行语义分割
semantic_nodes = semantic_parser.get_nodes_from_documents(documents)
# 6. 打印结果
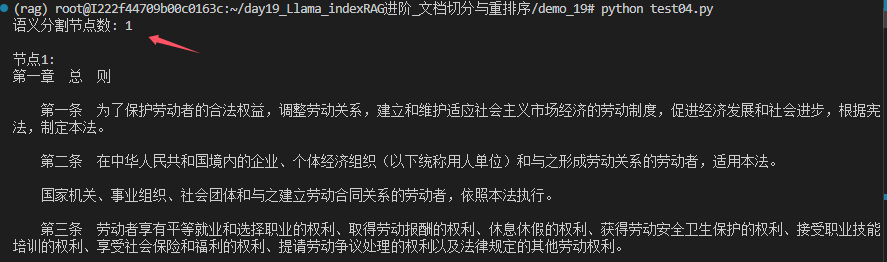
print(f"语义分割节点数: {len(semantic_nodes)}")
for i, node in enumerate(semantic_nodes[:3]): # 只打印前两个节点
print(f"\n节点{i+1}:\n{node.text}")
print("-"*50)
可以看到语义切分对法律条款失效
4.3模块三:召回率提升方案
什么是召回率?
就像捕鱼网的网眼大小:
网眼太大 → 漏掉小鱼(低召回率)
网眼太小 → 捞到垃圾(低准确率)
提升召回率的三大策略:
- 查询扩展:给问题加"修饰词"
原始问题:“如何做番茄炒蛋”
扩展后:“家常番茄炒蛋做法步骤 厨房新手教程 简单易学” - 混合检索:结合两种搜索方式
用户问题关键词搜索语义搜索初步结果合并去重 - 向量优化:让AI更懂专业术语
微调前:“Transformer” → 理解为"变形金刚"
微调后:“Transformer” → 识别为"深度学习模型"
效果验证方法: - 准备测试问题集(至少50个典型问题)
- 记录基础方案召回率
- 应用优化策略后再次测试
- 对比提升幅度
基础检索 vs 混合检索
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings, VectorStoreIndex
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.schema import TextNode
import json
import torch
# 1. 初始化本地模型
def setup_local_models():
# 设置本地embedding模型
embed_model = HuggingFaceEmbedding(
model_name="/root/model/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
device="cuda" if torch.cuda.is_available() else "cpu"
)
# 设置本地LLM模型
llm = HuggingFaceLLM(
model_name="/root/model/Qwen/Qwen1___5-1___8B-Chat",
tokenizer_name="/root/model/Qwen/Qwen1___5-1___8B-Chat",
model_kwargs={"trust_remote_code": True},
tokenizer_kwargs={"trust_remote_code": True},
device_map="auto",
generate_kwargs={"temperature": 0.3, "do_sample": True} # 修改为do_sample=True避免警告
)
# 全局设置
Settings.embed_model = embed_model
Settings.llm = llm
Settings.chunk_size = 512
# 2. 加载数据并处理格式
def load_data(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
nodes = []
for item in data:
if isinstance(item, dict):
# 处理DPR格式数据
if 'query' in item and 'positive_passages' in item:
text = f"查询: {item['query']}\n相关文档: {item['positive_passages'][0]['text']}"
# 处理QA对格式
elif 'question' in item and 'answer' in item:
text = f"问题: {item['question']}\n答案: {item['answer']}"
else:
continue
elif isinstance(item, str):
text = item
else:
continue
node = TextNode(text=text)
nodes.append(node)
return nodes
# 3. 初始化本地模型
setup_local_models()
# 4. 加载数据
data_path = "/root/day19_Llama_indexRAG进阶_文档切分与重排序/demo_19/data/qa_pairs.json"
nodes = load_data(data_path)
# 5. 示例查询
query = "如何预防机器学习模型过拟合?"
# 案例1:向量检索(使用本地embedding模型)
vector_index = VectorStoreIndex(nodes)
vector_retriever = vector_index.as_retriever(similarity_top_k=3)
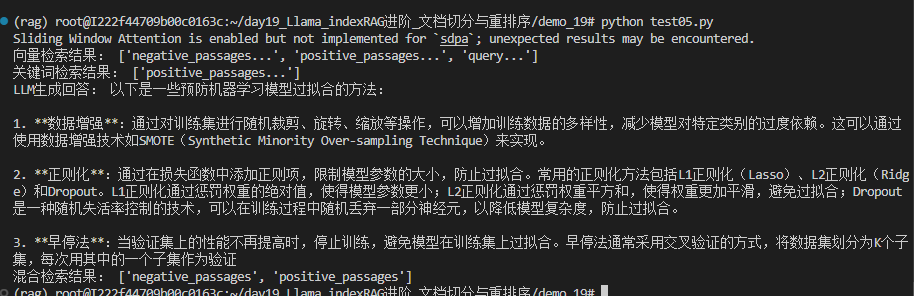
print("向量检索结果:", [node.text[:50] + "..." for node in vector_retriever.retrieve(query)])
# 案例2:关键词检索(不使用bm25模式)
from llama_index.core import KeywordTableIndex
keyword_index = KeywordTableIndex(nodes)
keyword_retriever = keyword_index.as_retriever(similarity_top_k=3) # 使用默认模式
print("关键词检索结果:", [node.text[:50] + "..." for node in keyword_retriever.retrieve(query)])
# 案例3:查询引擎(使用本地LLM生成回答)
query_engine = keyword_index.as_query_engine()
response = query_engine.query(query)
print("LLM生成回答:", response)
# 案例4:混合检索
from llama_index.core.retrievers import QueryFusionRetriever
fusion_retriever = QueryFusionRetriever([vector_retriever, keyword_retriever])
print("混合检索结果:", [node.text[:30] for node in fusion_retriever.retrieve(query)])
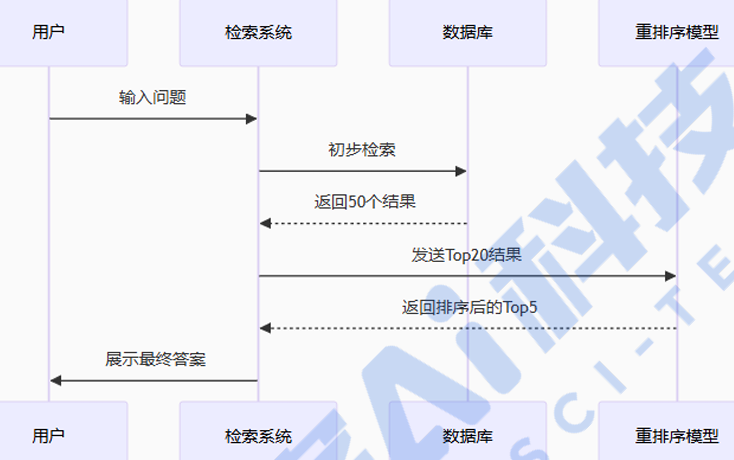
4.4模块四:检索结果重排序
为什么要重排序?
就像面试筛选简历:
- 初筛:快速浏览100份简历(初步检索)
- 精筛:详细评估前20份(重排序)
- 终选:确定3位候选人(最终结果)
重排序工作流程:
常见排序模型对比:
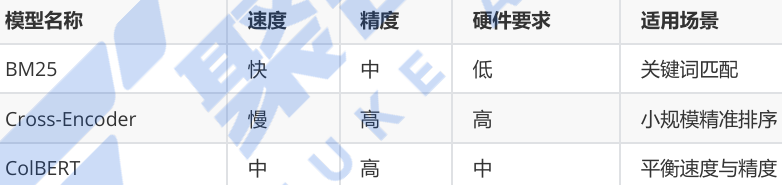
无排序 vs Cohere Reranker
初始检索结果(按相似度排序):
results = [
"模型正则化方法简述", # 相关度0.7
"硬件加速技术进展", # 相关度0.65
"过拟合解决方案详解", # 相关度0.92 ← 正确答案
"数据集清洗方法"
]
# 应用重排序
from llama_index.postprocessor.cohere_rerank import CohereRerank
reranker = CohereRerank(api_key="YOUR_KEY", top_n=2)
reranked_results = reranker.postprocess_nodes(results, query_str=query)
print("重排序后结果:", [res.text for res in reranked_results])
排序变化对比:
原始排序:
- 模型正则化方法简述(相关度0.7)
- 硬件加速技术进展(相关度0.65)
- 过拟合解决方案详解(相关度0.92)← 正确答案
- 数据集清洗方法
重排序后: - 过拟合解决方案详解(评分0.95)← 正确答案
- 模型正则化方法简述(评分0.88)


















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









