






翻译自论文 DiffuseMorph: Unsupervised Deformable Image Registration Using Diffusion Model
github链接:https://github.com/DiffuseMorph/DiffuseMorph
摘要:
变形图像配准是医学图像中的基础任务之一。经典配准算法通常因为迭代优化而需要很高的计算成本。虽然基于深度学习的方法已经被开发用于快速图像配准,但从moving到fixed,要获得具有较少拓扑折叠问题的真实、连续变形仍然具有挑战性。为了解决这个问题,我们提出了一种新的基于扩散模型的图像配准方法,称为DiffuseMorph。DiffuseMorphin不仅通过反向扩散生成合成变形图像,还允许通过变形场进行图像配准。具体来说,变形场是由运动图像和固定图像之间变形的条件分数函数生成的,因此配准可以通过简单地缩放分数的潜在特征实现连续形变。二维面部和三维医学图像配准任务的实验结果表明,我们的方法提供了灵活的、具有拓扑保持能力的变形。
关键词:图像配准,扩散模型,图像变形,非监督学习
1、简介
形变图像配准就是计算moving与fixed图像对之间非刚性的体素对应关系。由于个体之间、扫描时间、图像模态等不同导致医学图像的解剖结构或形状不同,这形变配准对医学图像分析尤其重要,比如疾病诊断、治疗监测等。过去几十年来,人们已经研究出了各种图像配准方法。
经典的图像配准算法常常试图通过解决计算成本高昂的优化问题来对齐图像[1,2, 5]。为了解决计算成本的问题,开始广泛研究基于深度学习的配准算法[4,7,22,29,33],这些方法将fixed和moving作为网络输入,通过训练神经网络来估计配准场。这些方法在提供快速形变的同时,能保持配准精度。但是,这些监督方法通常需要金标的配准场[33][34],另外当前一些非监督的方法为了保持拓扑不变需要额外的微分同胚的限制[11][26]或者是循环一致性[22]的限制。
最近,基于分数的扩散模型在图像生成中显示出高质量。尤其是,去噪扩散概率模型(DDPM)[17,37]能学习从高斯噪声到数据分布的马尔可夫变换,且通过随机扩散过程提供不同的样本,该模型已经应用于计算机视觉的许多领域[9,14,21,36,38]。为了生成所需语义的图像,又提出了条件去噪扩散模型[10,35]。但是,应用去噪扩散概率模型到图像配准任务中是很有挑战的,因为通过变形场对moving图像进行变换才是正确的配准而不是图像生成。
在本文中,通过利用扩散模型估计的潜在特征提供了生成图像的空间信息的性质,我们提出了一种新的无监督可变形图像配准方法,称为dubbed DiffuseMorph,通过调整DDPM生成变形场。具体而言,我们提出的模型由扩散网络和变形网络组成,前者网络学习运动图像和固定图像之间的距离的条件分数函数,而后者网络使用得分函数的潜在特征来估计变形场,并提供变形图像。这两个网络以端到端学习的方式联合训练,因此DiffuseMorph不仅可以在运动图像变形为固定图像的方向估计马尔可夫比那换,还能生成用于运动图像变换到固定图像的配准场。由于来自条件分数函数的潜在特征带有条件的空间信息,因此潜在特征可以提供从移动图像到固定图像的连续轨迹的变形场。

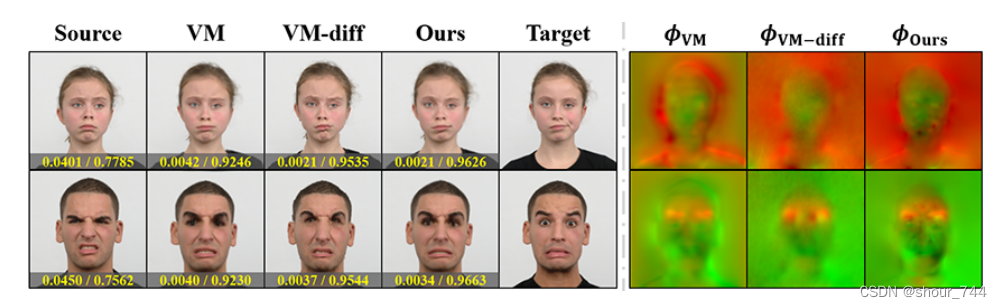
因此,如图1所示,我们提出的DiffuseMorph同时允许连续轨迹的图像配准以及合成变形图像的生成。具体的,我们训练的模型,通过简单插值作为变形网络输入的潜在特征,提供了从moving到fixed的连续形变。此外,我们提供的模型能够快速产生与fixed图像相似的、合成的变形图像。在这里,为了加速扩散过程,我们没有从随即高斯噪声开始,而是提出一个生成过程,在这个过程中,moving图像通过前向扩散传输一步,然后通过DDPM的逆向扩散过程迭代优化。这样可以大大减少扩散步数,使得样本保持原始moving图像的内容。
我们演示了所提出的方法在二维面部表情配准和三维医学图像配准任务中的性能。实验结果表明,我们的模型在配准精度方面达到了很高的性能。此外,由于从扩散模型估计的潜在特征,我们的方法能够在运动图像和固定图像之间沿连续轨迹进行实时图像配准,相较而言,这比基于学习的配准方法更加实用。我们的主要贡献总结如下:
——我们提出DiffuseMorph,这是第一个基于去噪扩散模型对运动图像和固定图像进行配准的方法。
——所提出的模型训练好后,不仅能执行从运动图像到固定图像的连续轨迹图像配准,通过缩放潜在特征,还可以通过快速反向扩散过程生成合成变形图像。
——我们证明所提出的方法可以应用于2D和3D图像配准任务,并提供具有可比性的精确变形同时与现有方法的拓扑保持性能相当。
2、背景和相关工作
2.1 变形图像配准
给定一个运动图像m和一个固定图像f, 经典的变形图像配准通过解决如下优化问题来实现:
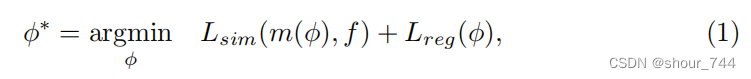
其中 ![]()
是把moving图像变形到fixed图像的最佳配准场,Lsim是不相似度函数,计算变形后的图像与fixed图像之间的相似度。Lreg是配准场的正则惩罚。通过最小化能量函数,对moving图像变换即可得到变形后图像。特别的,如果对变形场施加额外的限制使得变形映射是可微和可逆的,那么可以得到微分同胚的配准,如此保持拓扑不变[2][5][43].
基于学习的配准方法
由于传统的配准算法通常需要很大的运算量以及较长的运行时间,近年来已开始广泛研究基于深度学习的配准算法,对这种方法,一旦完成神经网络的训练,即可进行实时的变形场估计。但是,使用金标配准场进行网络训练的监督学习方法,需要高质量的进行进行训练。为了解决这个问题,提出了使用伪金标,例如分割结果图,训练的弱监督配准模型[19,46]。另一边,非监督方法通过计算变形图像和固定图像之间的相似度来训练网络[4, 22, 29, 30, 44]。为了保持拓扑不变,也提出了基于学习的微分同胚配准算法[11, 12, 26],这里面会有缩放和平方积分的层执行微分同胚的限制。
这些现有方法可以通过缩放配准场或在较短的时间尺度内对velocity场积分来进行移动和固定图像间的中间变形。但是,我们的方法产生了更现实的结果,通过缩放具有空间信息的潜在特征进行连续变形从而提高了图像配准的性能。
2.2 去噪扩散概率模型
未完,待续















 380
380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









