





作为大数据查询系统博客的延续,我想分享更多用于构建Google Analytics(分析)引擎的技术。
在必须构建将用于大规模分析客户数据的系统的地方遇到问题。
有哪些选项可以解决此问题?
– 将数据加载到您喜欢的数据库中并具有正确的索引。
当数据很小时,当我说小于1TB甚至更少时,这是可行的。
– 其他选择是使用类似弹性搜索的方法
弹性搜索可以工作,但是会带来管理另一个集群并将数据传送到弹性搜索的开销
– 使用spark SQL或presto
将它们用于交互式查询非常棘手,因为执行查询所需的最小开销可能大于查询所需的等待时间(1或2秒)。
-使用分布式内存数据库。
这看起来是不错的选择,但它也存在一些问题,例如许多解决方案是专有的,开源的解决方案将具有类似于Elastic Search的开销。
– 通过消除作业启动开销来激发SQL。
我将深入探讨该选项。 由于简单性和广泛的社区支持,Spark已成为构建ETL管道的第一选择,Spark SQL可以连接到任何数据源(JDBC,Hive,ORC,JSON,Avro等)。
Analytics(分析)查询会产生不同类型的负载,它只需要整个集合中的少数列,并在其上执行一些聚合函数,因此基于列的数据库将成为Analytics(分析)查询的不错选择。
Apache Parquet是Hadoop生态系统中任何项目均可使用的列式存储格式,而与选择数据处理框架,数据模型或编程语言无关。
因此,使用Spark数据可以转换为镶木地板,然后可以在其上使用Spark SQL来回答分析查询。
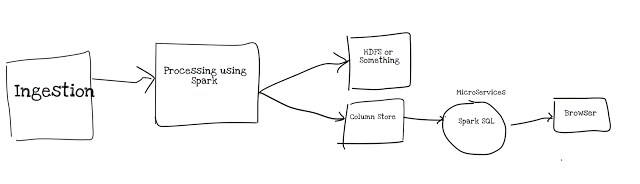
要将所有内容放在上下文中,将HDFS数据转换为
Parquet(即列存储),具有一个微服务,它将打开Sparksession,将数据固定在内存中,并像数据库池连接一样永久保持Spark会话的打开。
连接池已经有十多年的历史了,它可以用于火花会话来构建分析引擎。
有关其外观的高级示意图:
Spark Session是线程安全的,因此无需添加任何锁/同步。
根据用例,可以在单个JVM中创建单个或多个spark上下文。
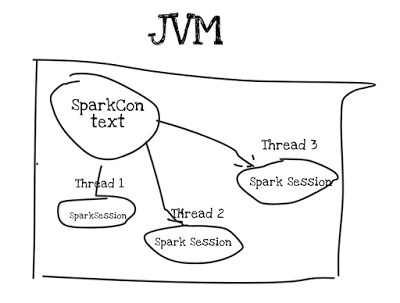
Spark 2.X具有简单的API,可以为SparkContext创建单例实例,并且还可以处理基于线程的SparkSession。
创建Spark会话的代码段
def newSparkSession(appName: String, master: String) = {
val sparkConf = new SparkConf().setAppName(appName).setMaster(master)
val sparkSession = SparkSession.builder()
.appName(appName)
.config(sparkConf)
.getOrCreate()
sparkSession
}警告
如果您在单个计算机上运行微服务,那么所有这些工作都很好,但是如果此微服务是负载平衡的,则每个实例将具有一个上下文。
如果单个Spark上下文请求成千上万个内核,则需要某种策略来负载均衡Spark上下文创建。 这与数据库池问题相同,您只能请求物理上可用的资源。
要记住的另一件事是,现在驱动程序正在Web容器中运行,因此分配适当的内存以进行处理,以使Web服务器不会因内存不足错误而崩溃。
我已经使用Spring Boot创建了微服务应用程序,它通过Rest API托管了Spark Session会话。
此代码有2种查询类型
–每个http线程一次查询
–每个http线程多个查询。 该模型非常强大,可用于回答复杂的查询。
代码可在github @ sparkmicroservices上获得
翻译自: https://www.javacodegeeks.com/2018/05/spark-microservices.html















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









