





在开始讨论Hadoop堆栈之前,让我们退后一步,尝试了解导致Hadoop起源的原因。
问题 –随着互联网的普及,存储的数据量不断增长。 让我们以一个搜索引擎(例如Google)为例,该引擎需要索引正在生成的大量数据。 搜索引擎对数据进行爬网并建立索引。 索引数据被存储并从单个存储设备中检索。 随着生成的数据的增长,搜索索引数据将继续增长。
随着访问数据的查询数量的增加,当前的文件系统I / O不足以同时检索大量数据。 此外,一个大型单一存储的模型开始成为瓶颈。 为了解决该问题,我们将文件系统从单个磁盘存储移动到群集文件系统。 但是随着数据量的不断增长,可以在一台机器上运行的基础数据开始成为瓶颈。
随着数据到达TB,基于现有文件系统的解决方案开始步履蹒跚。 数据访问,多个编写器和大文件大小很快成为扩展系统的一个问题。
解决方案 –为了克服这些问题,人们设想了一种分布式文件系统,该系统为上述问题提供了解决方案。 该解决方案解决了该问题
- 处理大文件时,I / O成为一个大瓶颈。 因此,我们将文件分成小块并存储在多台计算机中。 [块存储]
- 当我们需要读取文件时,客户端向多台计算机发送请求,每台计算机发送一个文件块,然后将其组合在一起以刺穿整个文件。
- 随着块存储的出现,数据访问变得分布式,并导致更快的检索/写入
- 由于数据块存储在多台计算机上,因此通过在多台计算机上使用相同的数据块,有助于消除单点故障。 这意味着,如果有一台计算机运行,客户端可以从另一台计算机请求阻止。
现在,将文件存储实现为块的任何解决方案都需要具有以下特征
- 管理元数据信息–由于文件被分成多个块,因此有人需要跟踪没有块的情况以及这些块在不同机器上的存储[NameNode]
- 管理存储的数据块并满足读/写请求[DataNodes]
因此,在Hadoop的上下文中– NameNode是所有元数据的仲裁器和存储库。 NameNode执行文件系统名称空间操作,例如打开,关闭和重命名文件和目录。 它还确定块到DataNode的映射。 DataNode负责处理来自文件系统客户端的读写请求。 DataNode还根据NameNode的指令执行块创建,删除和复制。 所有这些组件一起构成了称为HDFS (Hadoop分布式文件系统)的分布式文件系统。
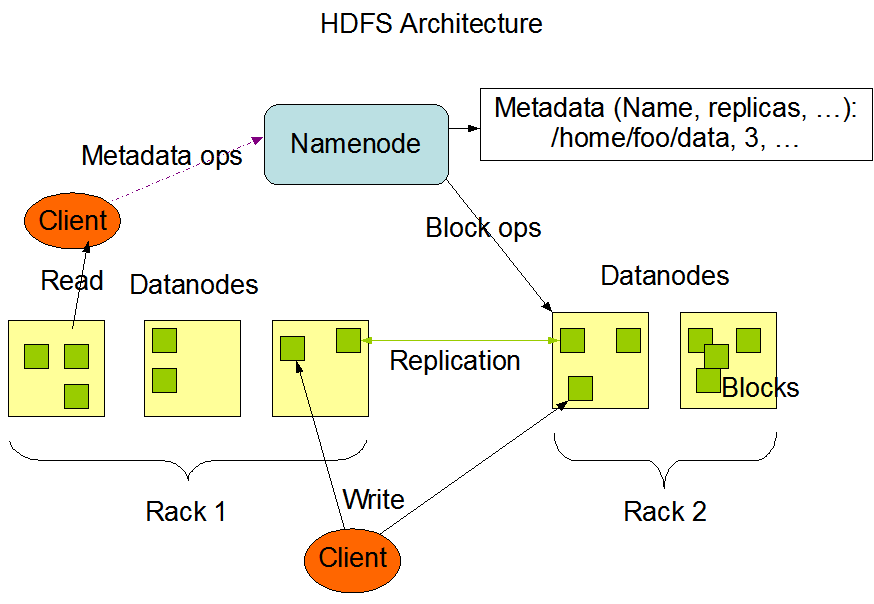
参考– http://hadoop.apache.org/common/docs/current/hdfs_design.html
HDFS具有内置冗余和复制功能,可确保在不丢失任何数据的情况下处理计算机的任何故障。 每当将新的数据节点添加到群集中或任何现有的数据节点发生故障时,HDFS都会自我平衡。
除了称为HDFS(Hadoop分布式文件系统)的分布式文件系统之外,还有2个其他核心组件
- Hadoop Common –是支持Hadoop子项目的一组实用程序。 Hadoop Common包括文件系统,RPC和序列化库。
- Hadoop MapReduce –是一种编程模型和软件框架,用于编写可在大型计算节点集群上并行快速处理大量数据的应用程序
因此,有效地,当您开始使用Hadoop时,HDFS和Hadoop MapReduce是您遇到的头两件事。 我将在后续文章中介绍MapReduce。
翻译自: https://www.javacodegeeks.com/2012/05/hdfs-for-dummies.html















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









