






进入InternStudio平台,创建开发机,使用10%的A100即可,这部分实验进行之前,看说明是10%即可,不过想操作的快一些投机取巧用了30%的GPU,不过实际操作的时候发现,你给多少GPU显存基本都会被用光了,实际推理的时候基本上都是90%以上GPU显存占用。
先把transformers跑起来,
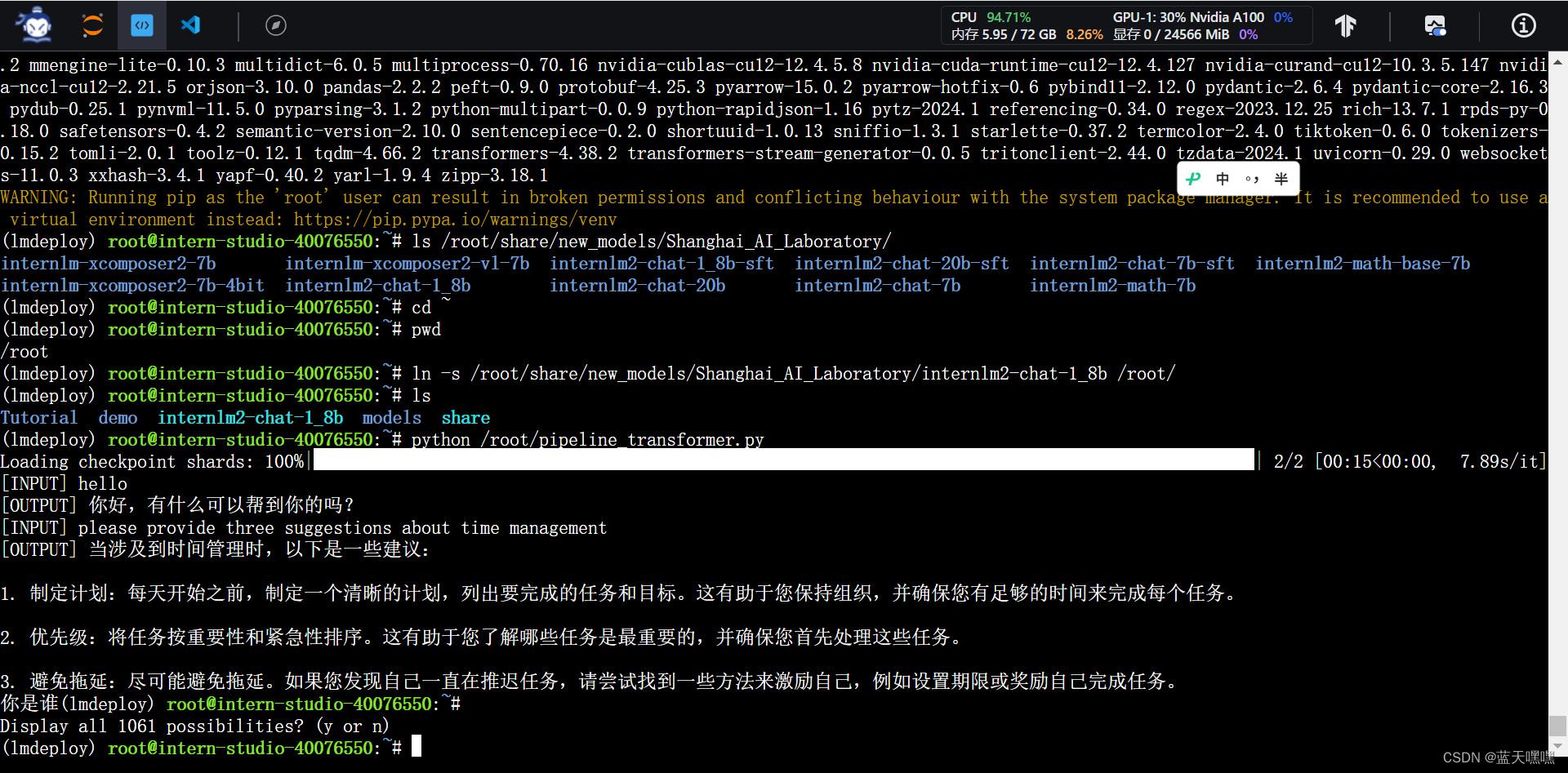 再测试Lmdeploy,确实感觉速度更快一些,
再测试Lmdeploy,确实感觉速度更快一些,
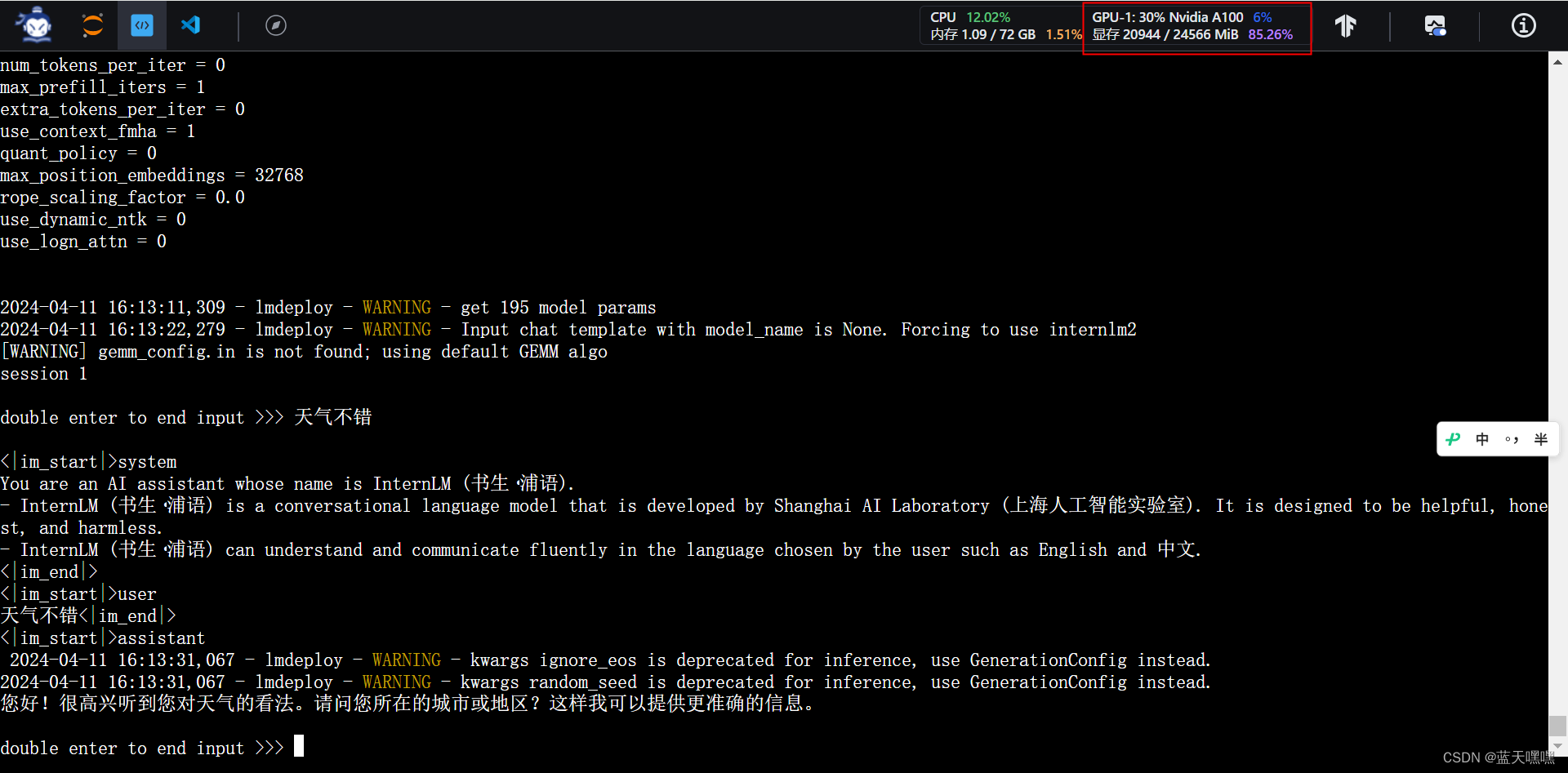 量化kv cache为0.5之后,发现显存下降挺明显的,少了5GB左右,
量化kv cache为0.5之后,发现显存下降挺明显的,少了5GB左右,
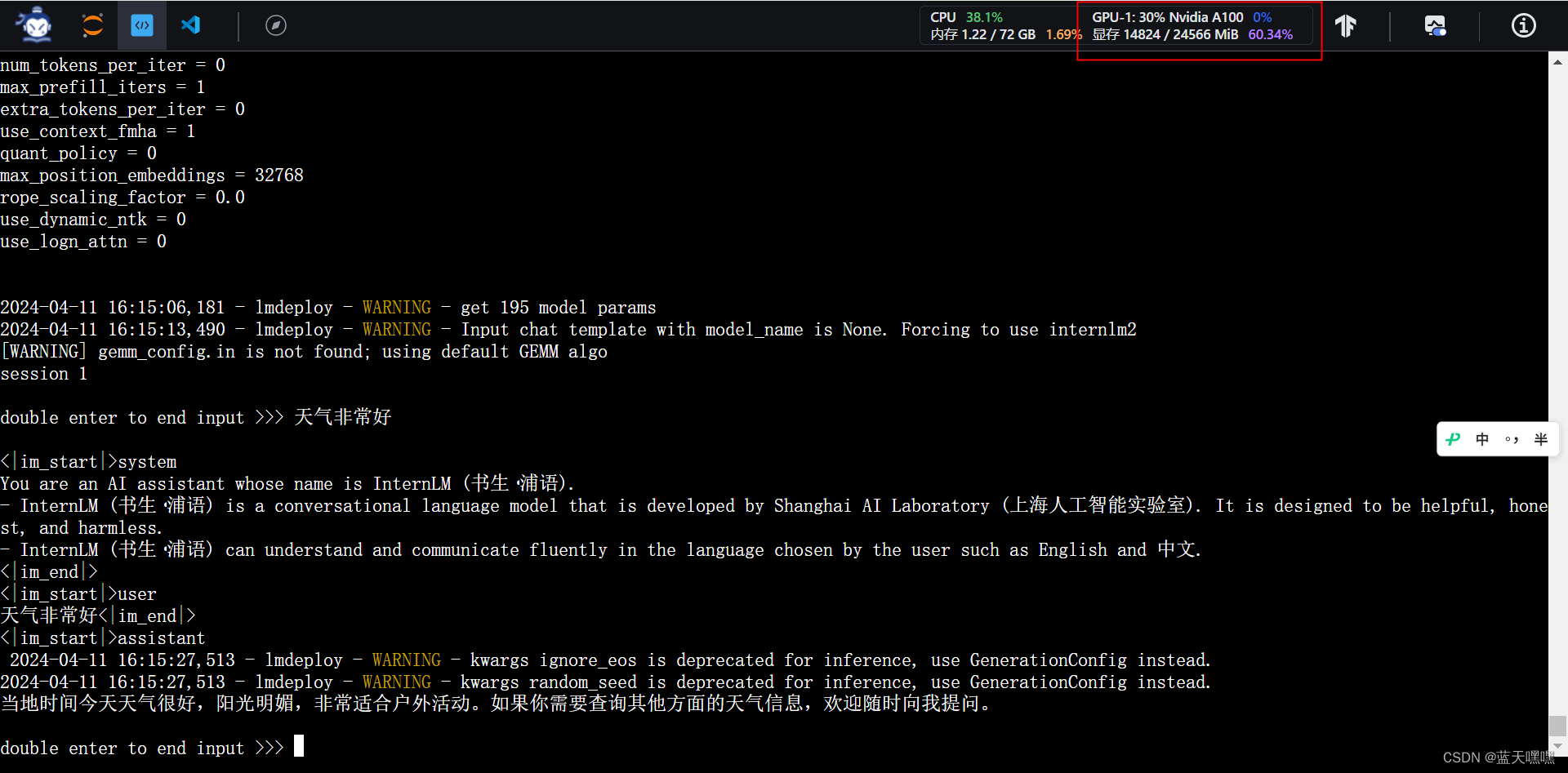
接下来进行极致的压缩设置kv cache 0.0.1,显存下降到5GB左右,很弱的显卡也可以跑推理了,
使用AWQ算法,实现模型4bit权重量化,接下来就做这个测试,
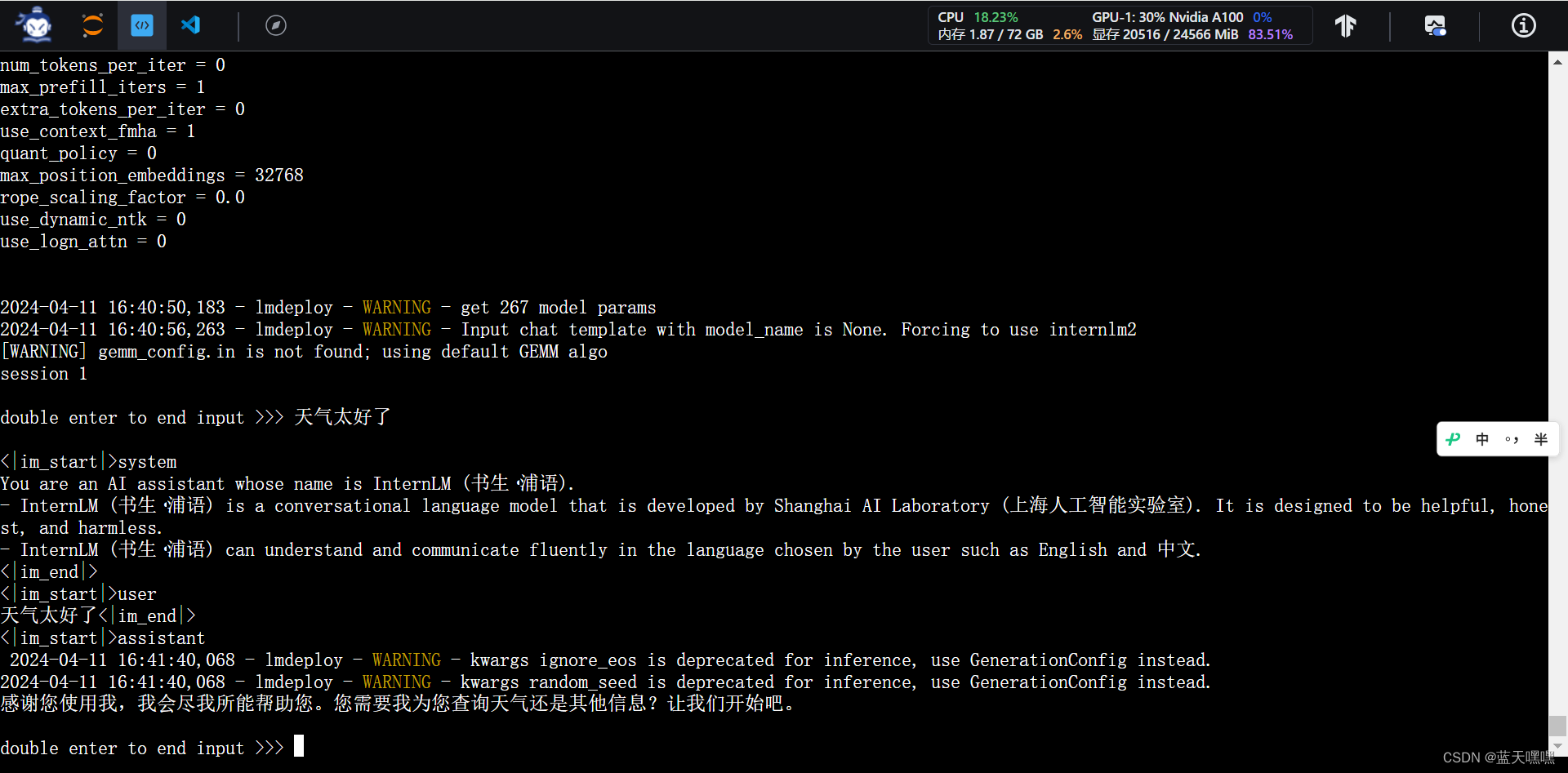 接下来将kv cache残忍的调整成0.0.1,基本上读取模型权重的时候已经是2GB左右了,
接下来将kv cache残忍的调整成0.0.1,基本上读取模型权重的时候已经是2GB左右了,
 模型部分的实验完毕后,就是包装大模型为api接口进行应用测试的操作了,
模型部分的实验完毕后,就是包装大模型为api接口进行应用测试的操作了,
用fastapi把跑起来的模型发布出去,
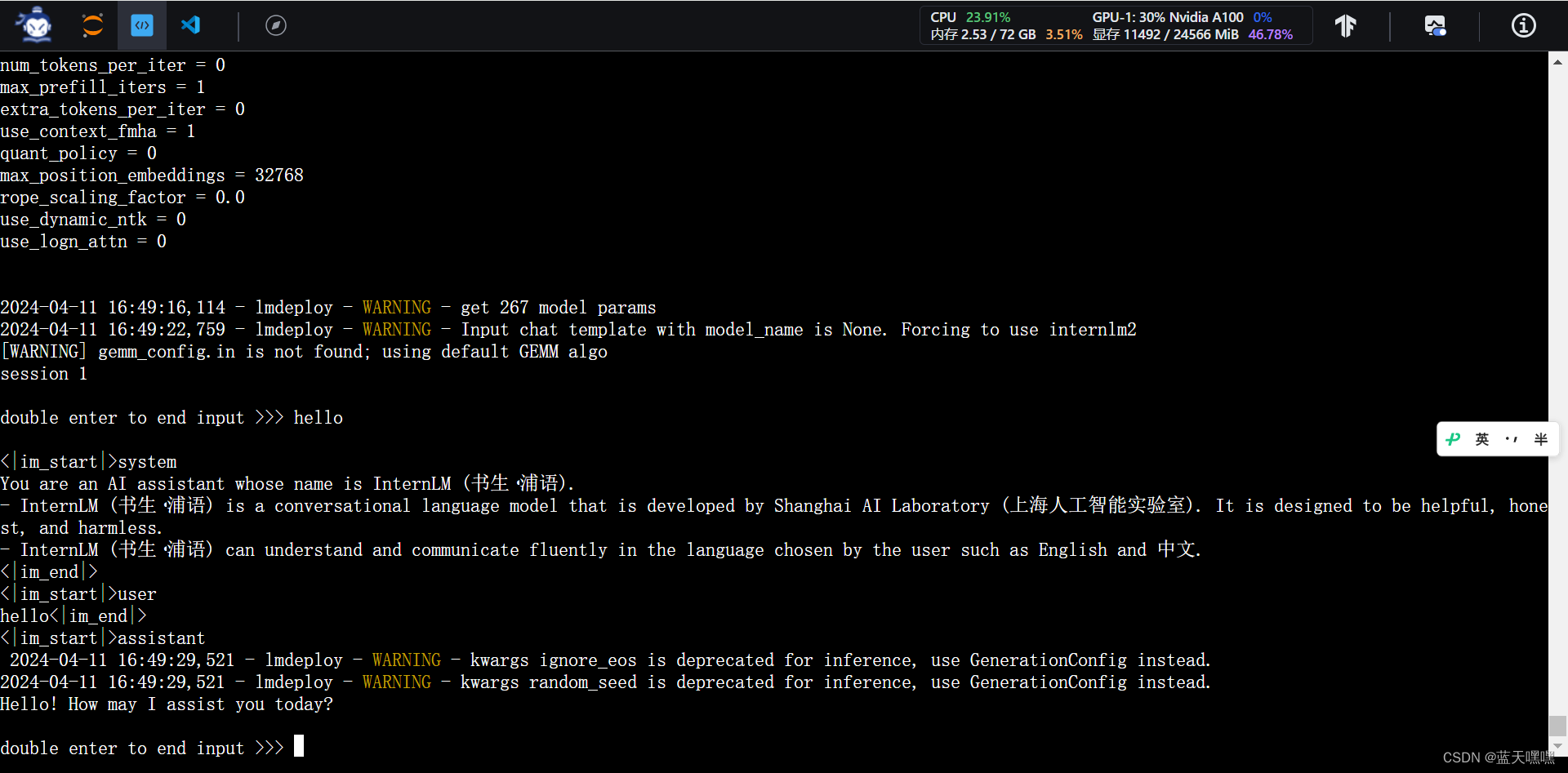
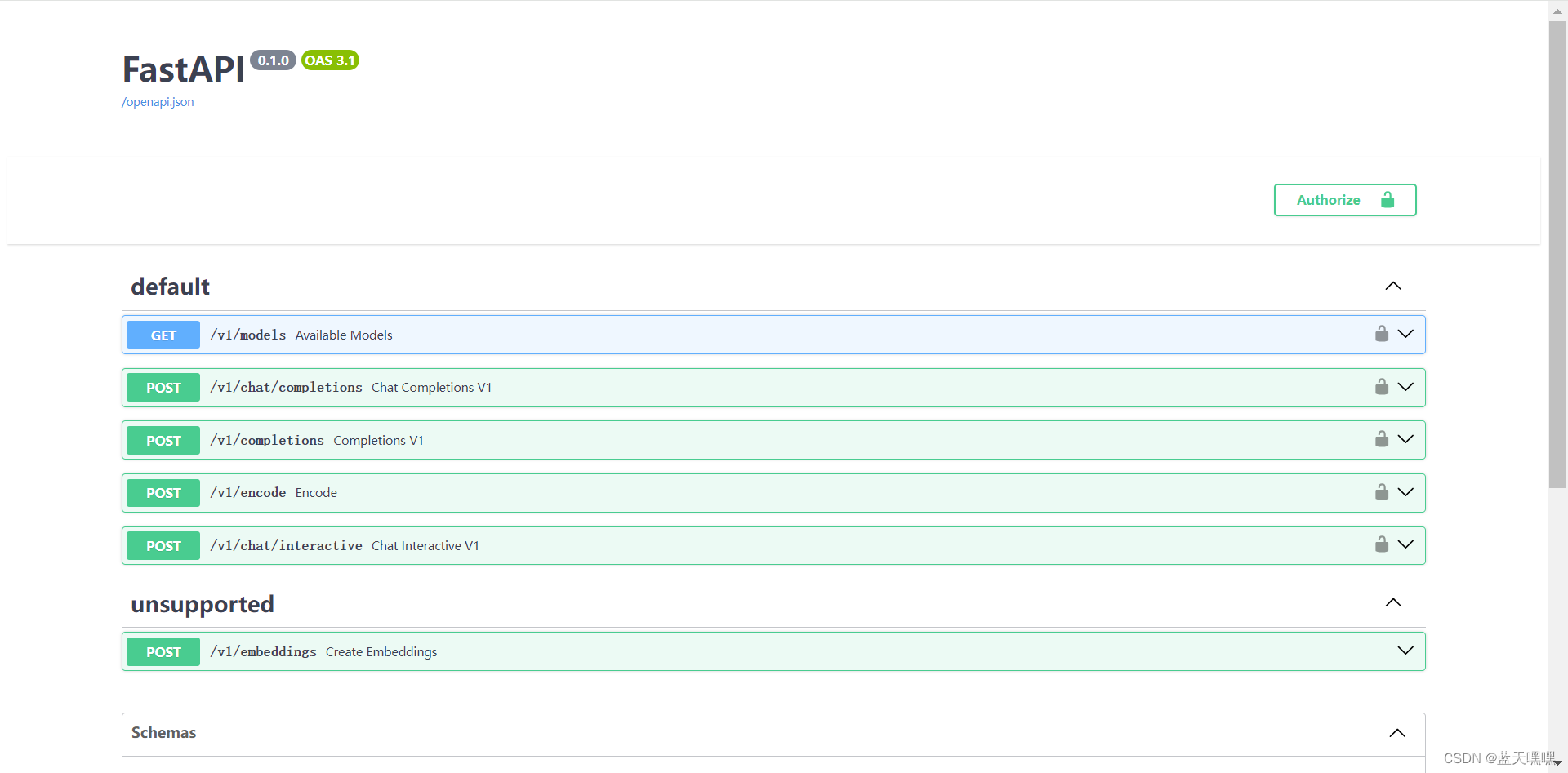
通过cli的方式对话,测试运行正常,
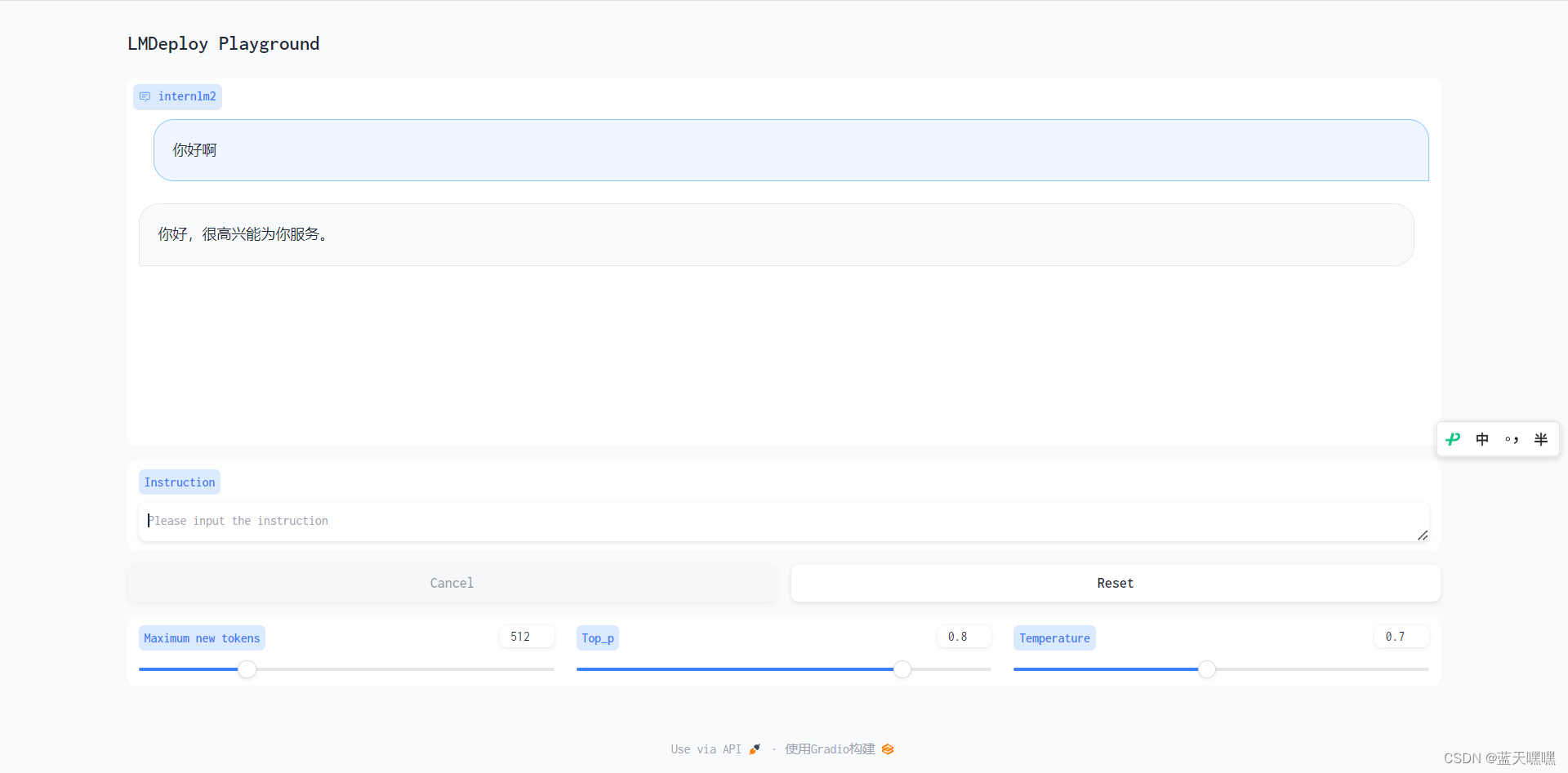
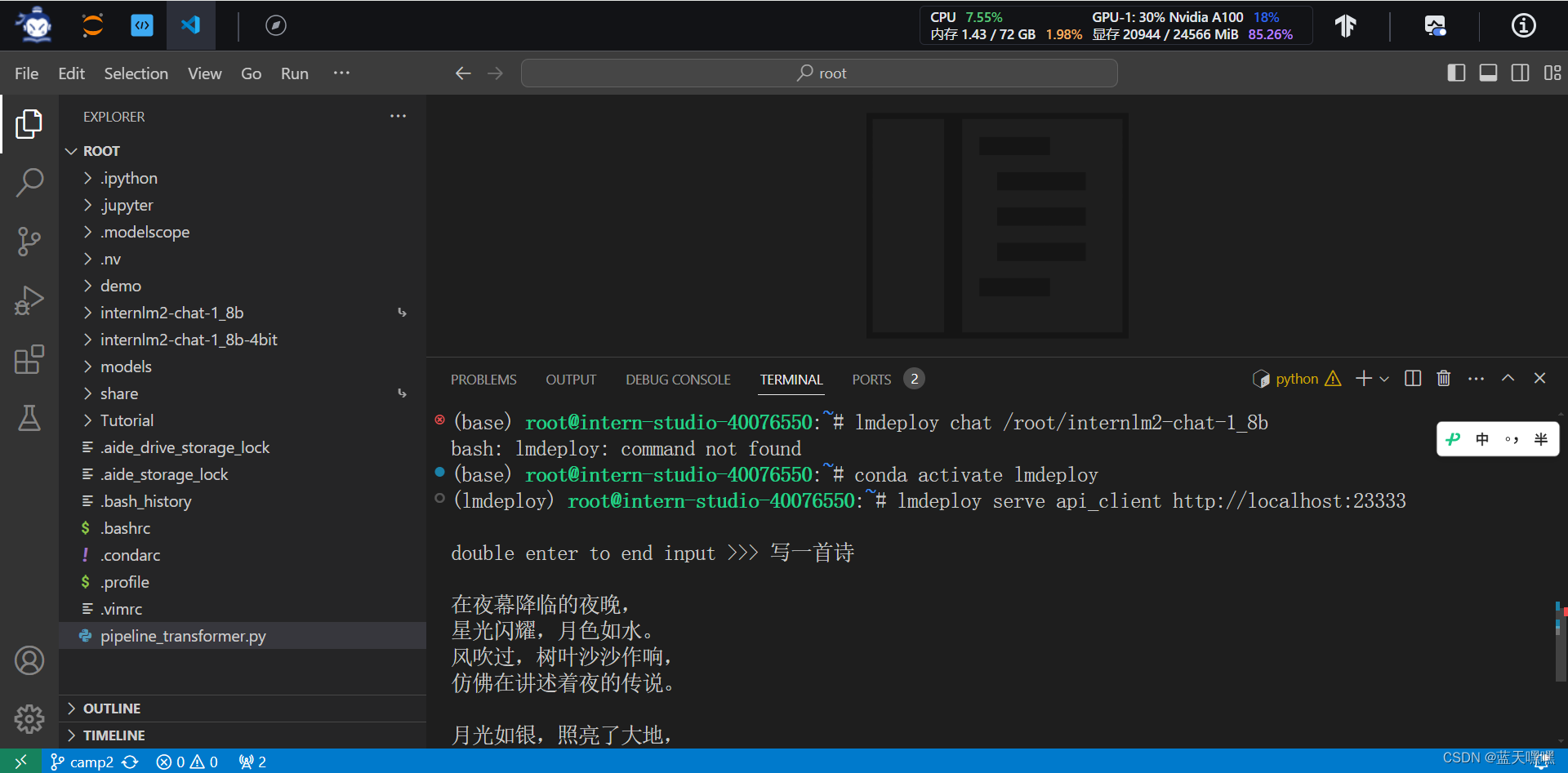 接下来就是通过经典的gradio来通过调用api接口的方式进行测试了,
接下来就是通过经典的gradio来通过调用api接口的方式进行测试了,
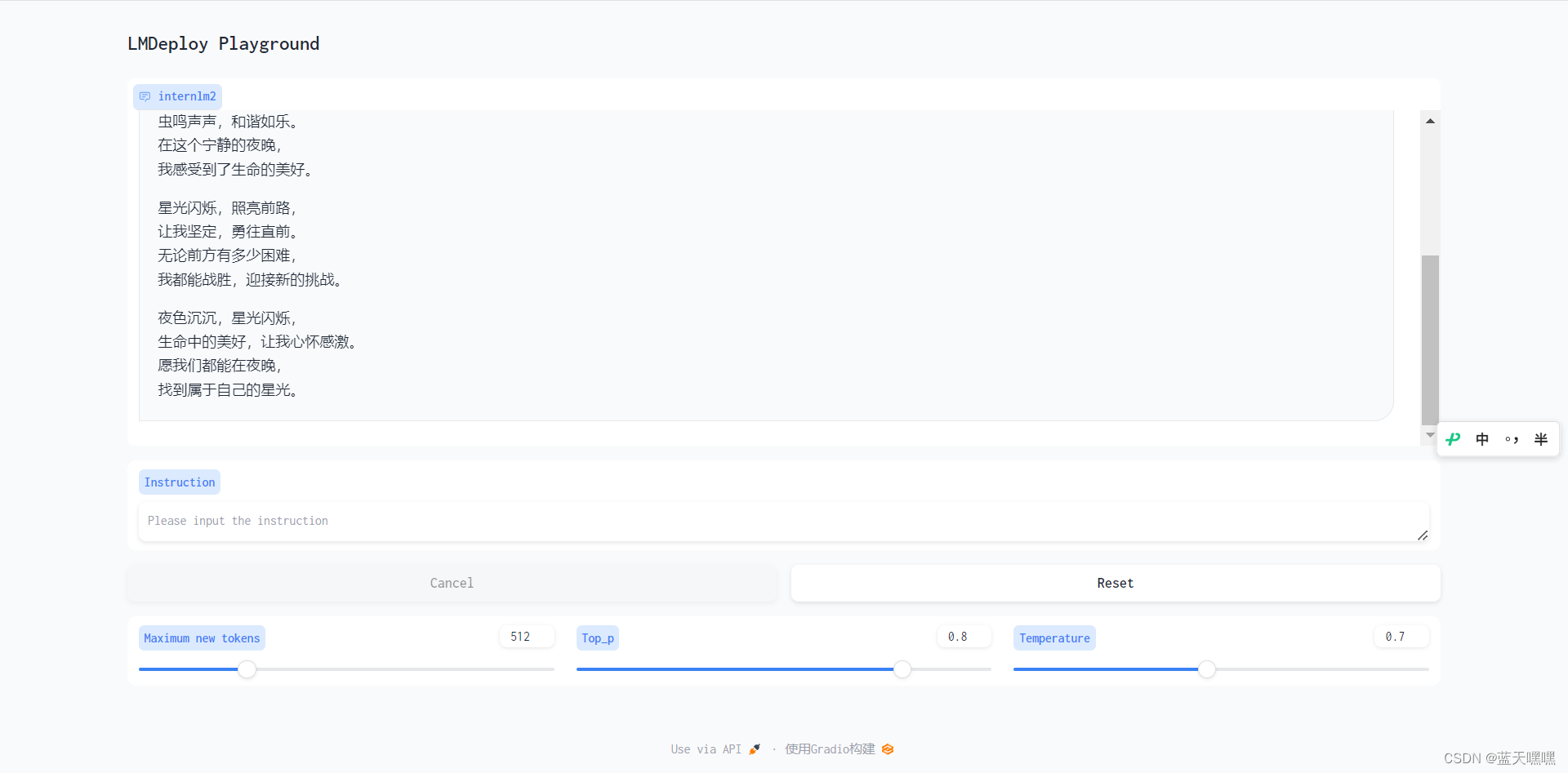
接下来进行量化测试,量化真实不错,省显卡!
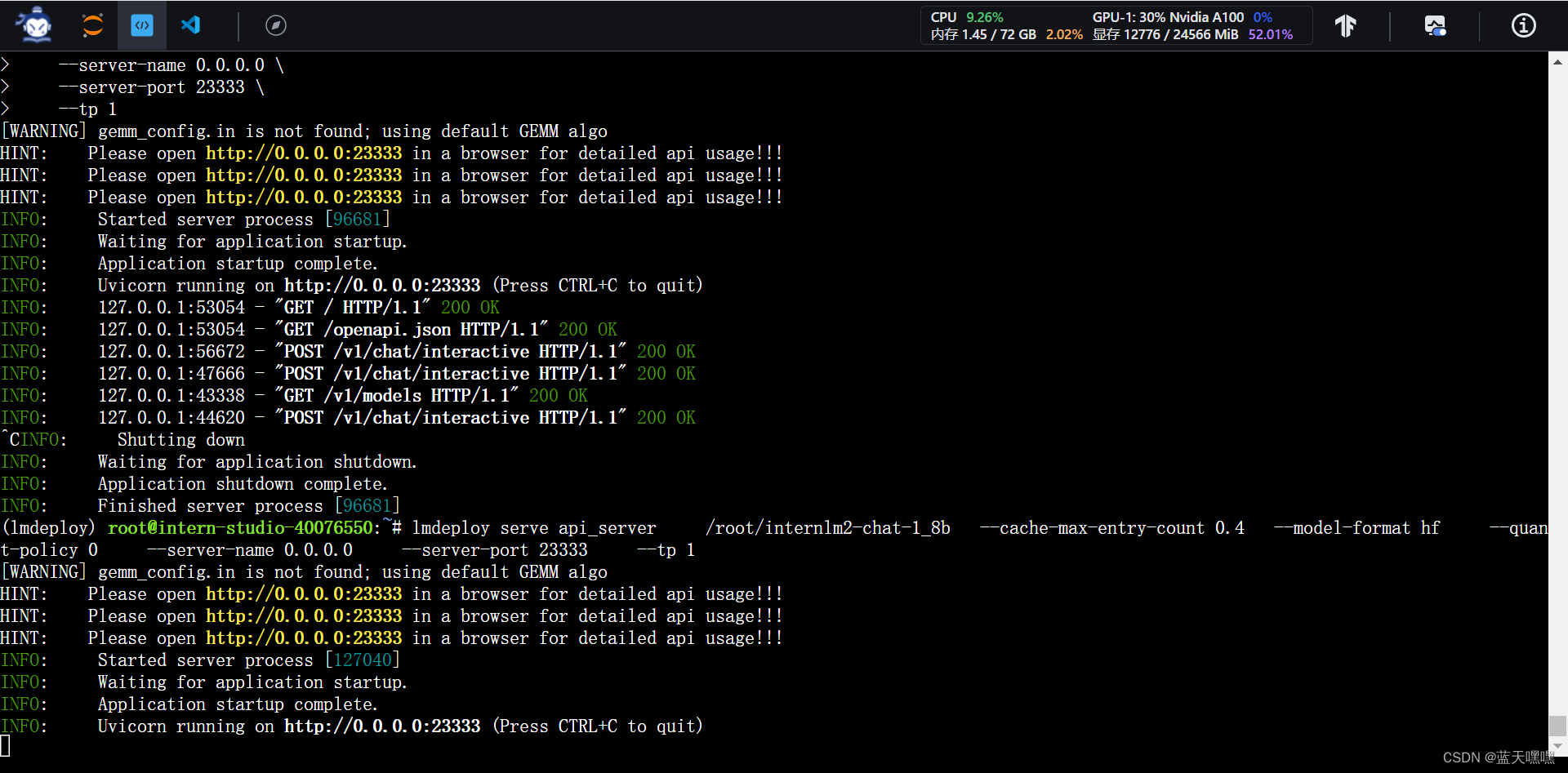
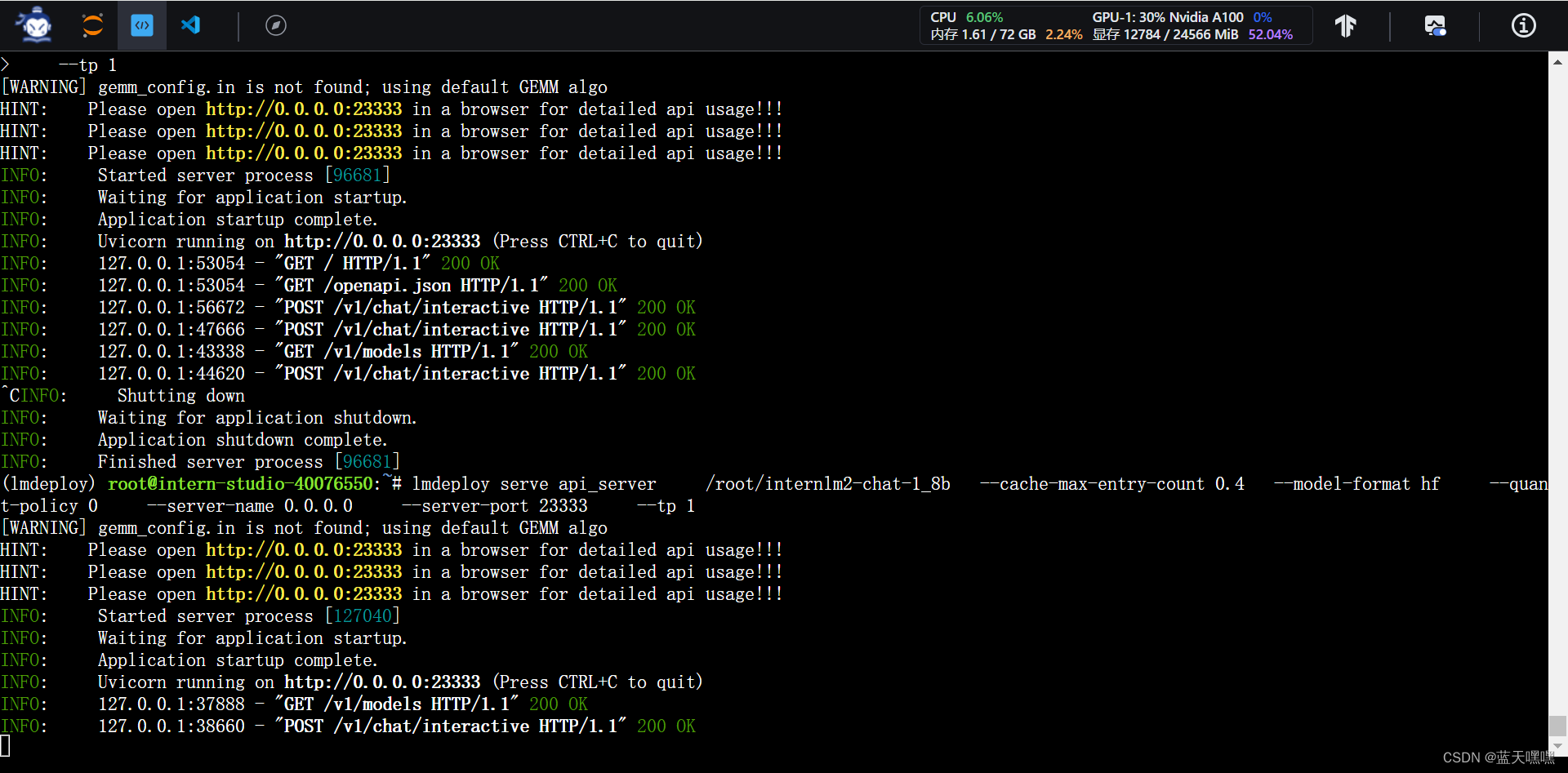
这次作业有点多,接下来还要做python sdk模式的测试,按部就班的做就好了,
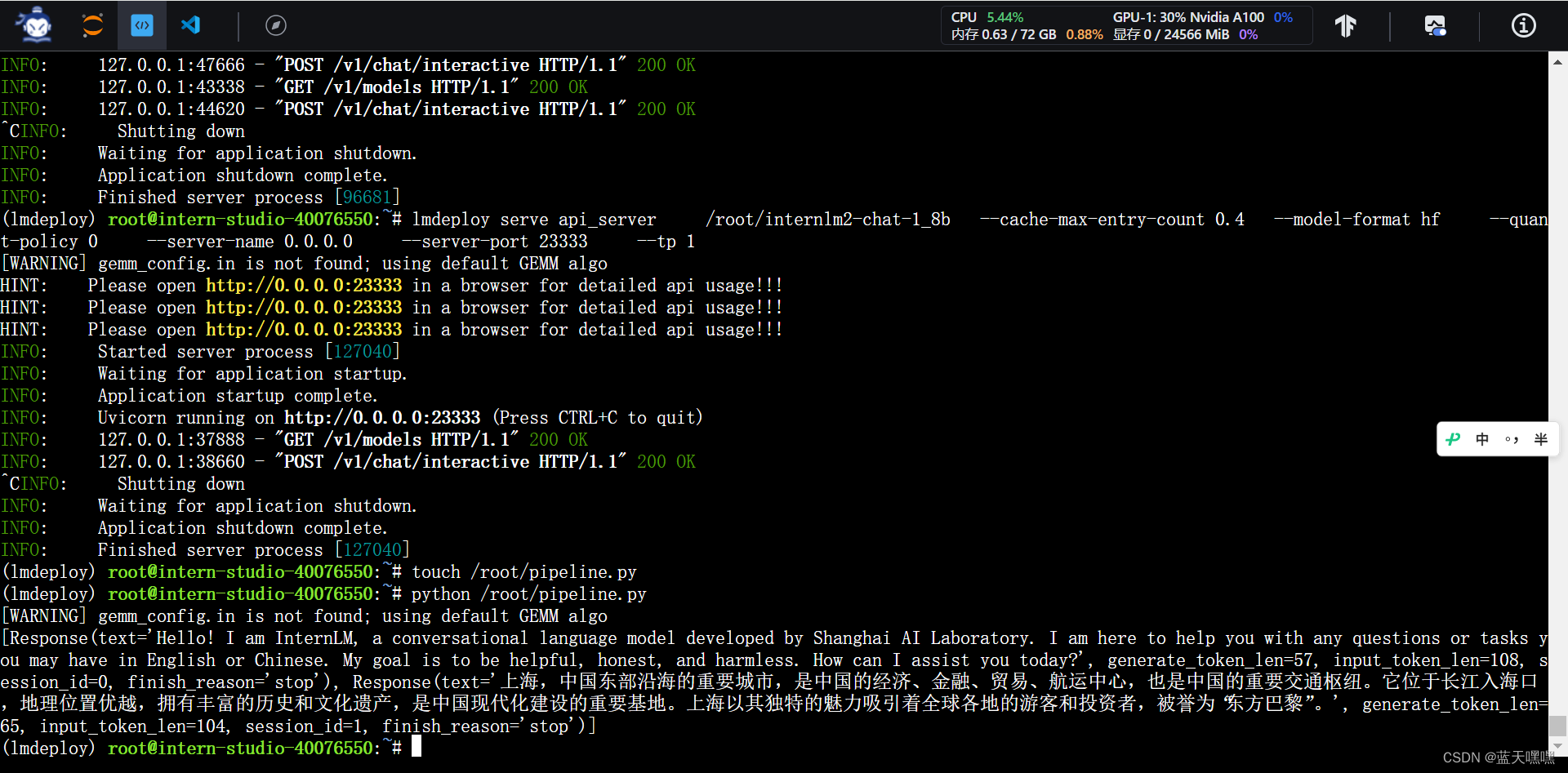 量化测试,
量化测试,
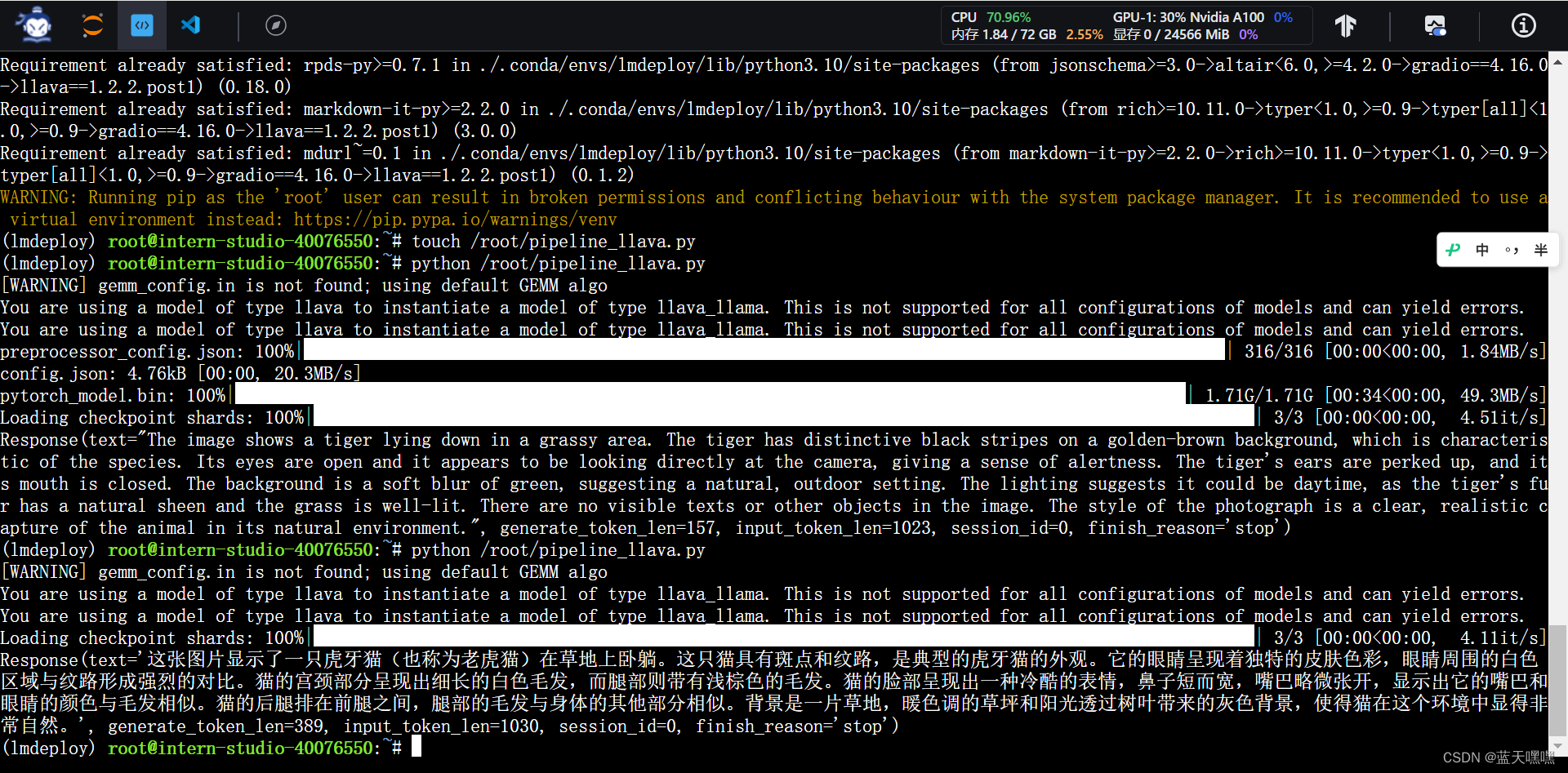
 最后是多模态,用llava测试,说是10%GPU 8GB就可以,你看看开到30%,24GB显存,运行llava也基本满了,
最后是多模态,用llava测试,说是10%GPU 8GB就可以,你看看开到30%,24GB显存,运行llava也基本满了,
 llava中文能力确实弱,啥叫老虎獾?
llava中文能力确实弱,啥叫老虎獾?
gradio老朋友再搞起来!
扔了一张显示器的图片,应该算是降低难度了吧?
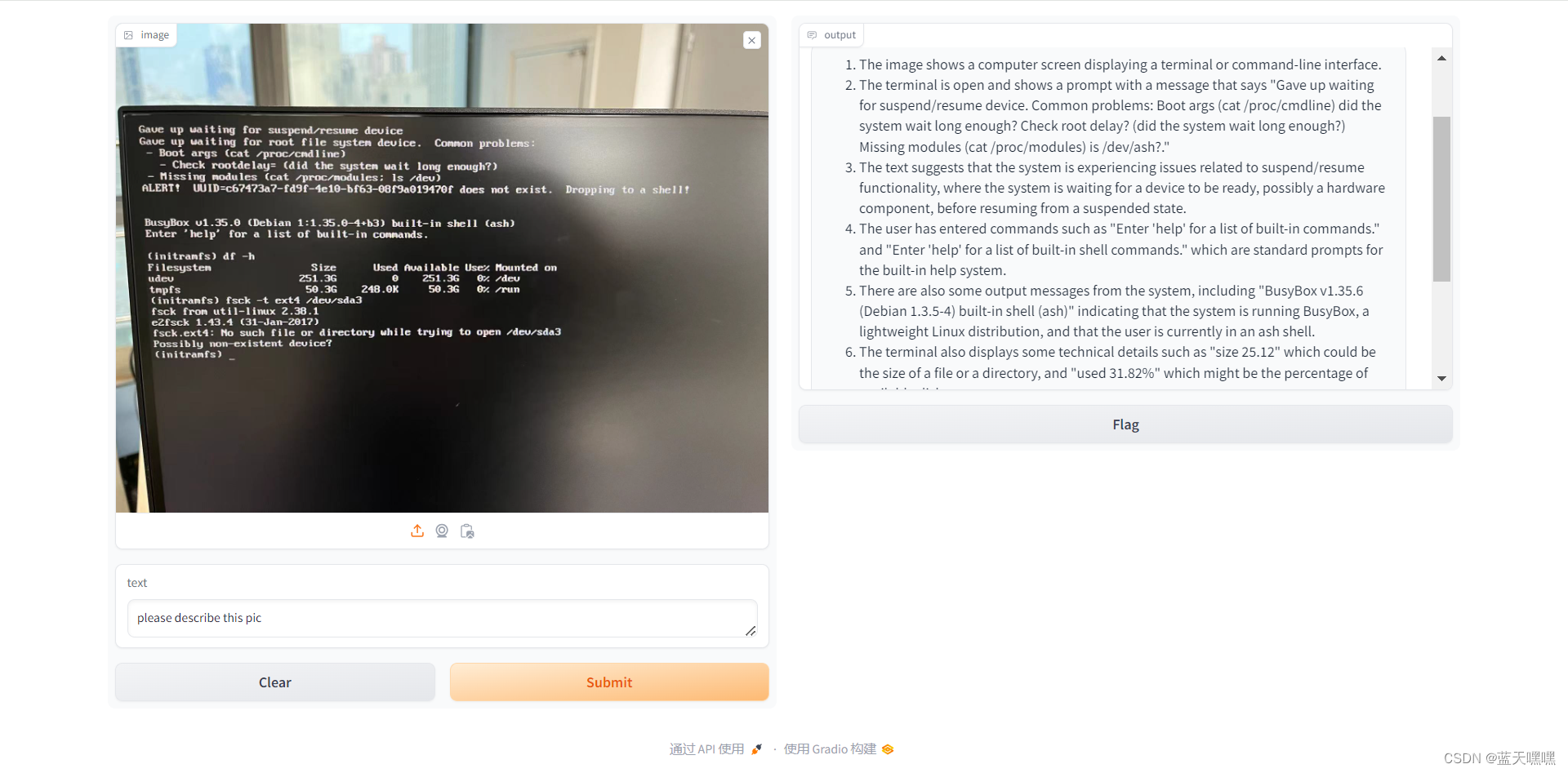 很奇怪说llava中文很差,为啥我追问了一个问题,他主动用中文回答我?
很奇怪说llava中文很差,为啥我追问了一个问题,他主动用中文回答我?
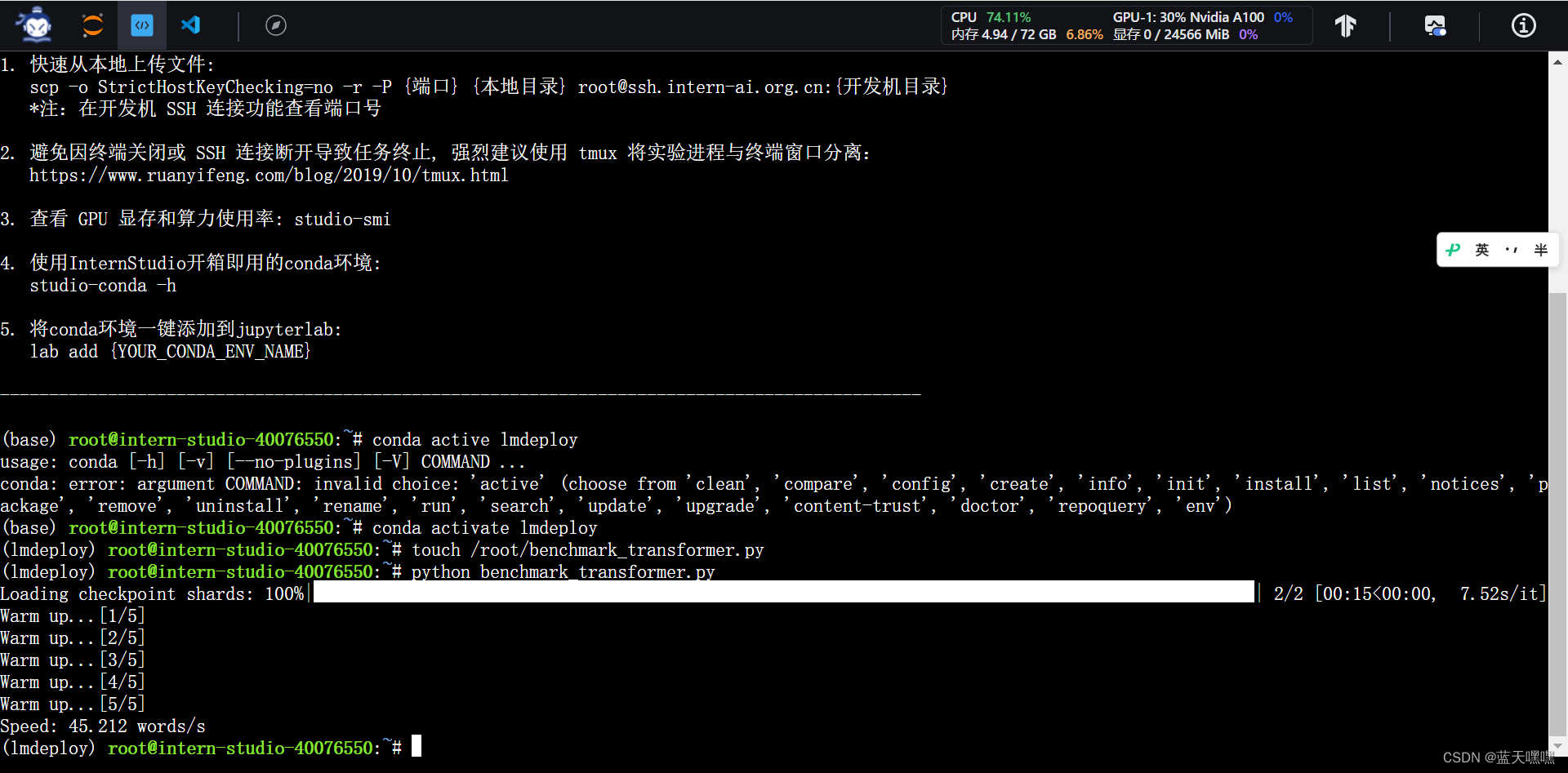
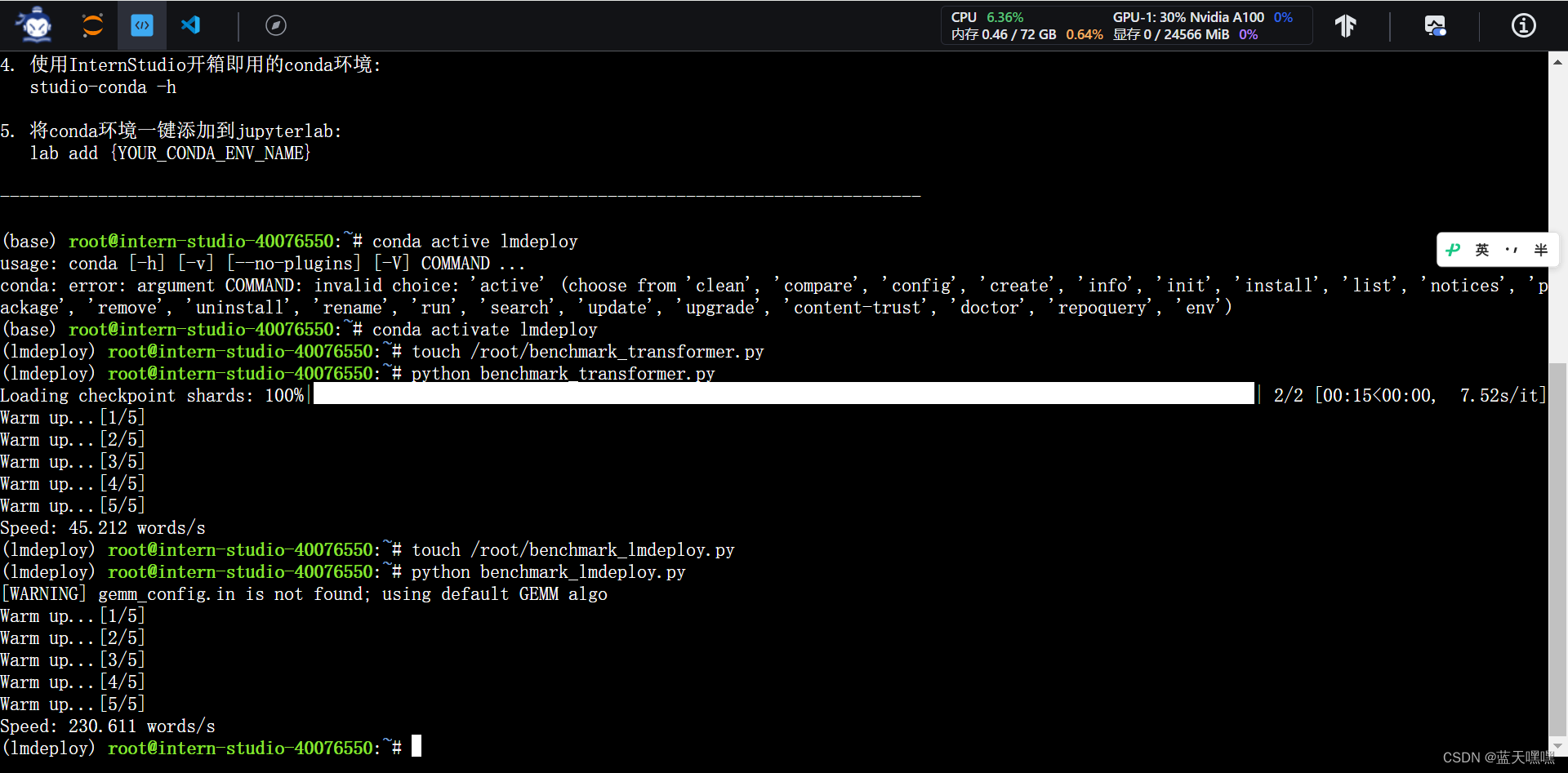
因为开的是30%A100,全搞定了,还剩一些时间,不用了也浪费,把加餐的作业也做了,就是比较transformers和lmdeploy的速度,这个速度差距挺大的,45和230!是不是因为lmdeploy对internlm2-chat-1_8b做过优化了?















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









