






先例行的准备环境,部署XTuner还是有点慢。
先制作用于微调的json文件,做了出来哈哈,复制10000遍,

先搞文件后部署环境,呵呵,速度确实挺慢的,不过还好成了,

xtuner list-cfg,模型确实多,等了1分钟,


进行基础配置等等,没留神,资源时间到了,,,尴尬,,,
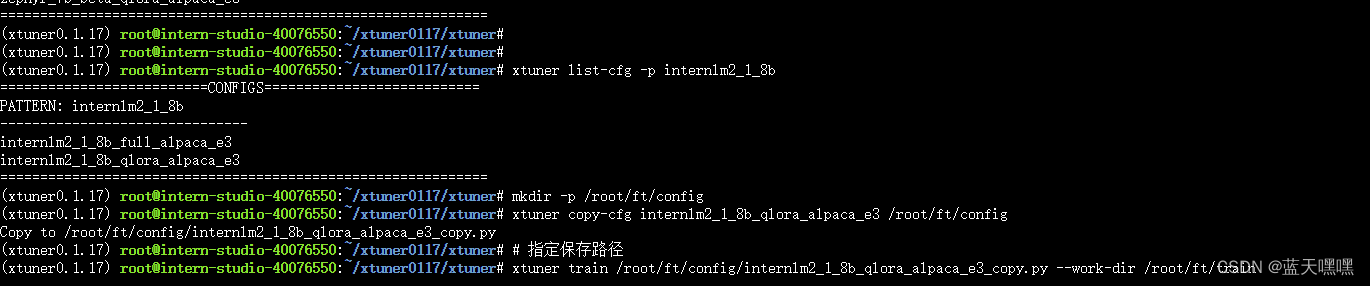 晚上继续,还是挺慢,而且等了几分钟了显存也没有动,
晚上继续,还是挺慢,而且等了几分钟了显存也没有动,
 等了10分钟,终于开始加载权重了,显存也终于开始动了,
等了10分钟,终于开始加载权重了,显存也终于开始动了,
 60个迭代,loss就已经下降很明显,估计很快就会被训练成小傻子了,用这种重复的预料训练,过拟合是必然的了,看看测试结果,299的
60个迭代,loss就已经下降很明显,估计很快就会被训练成小傻子了,用这种重复的预料训练,过拟合是必然的了,看看测试结果,299的
 599的
599的
 767的,基本上是小傻子了,
767的,基本上是小傻子了,

xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface 转为抱抱脸的格式,以后可以上传做api发布给全世界用用哈哈

接下来将微调后的lora模型文件与原模型进行合并,因为不是全量的微调,所以必须把微调的后的权重参数也就是adapter的文件合并到原模型文件中,生成最终的模型权重进行加载才能进行最终的测试,看微调效果如何,
 确实已经变成小傻子了,
确实已经变成小傻子了,
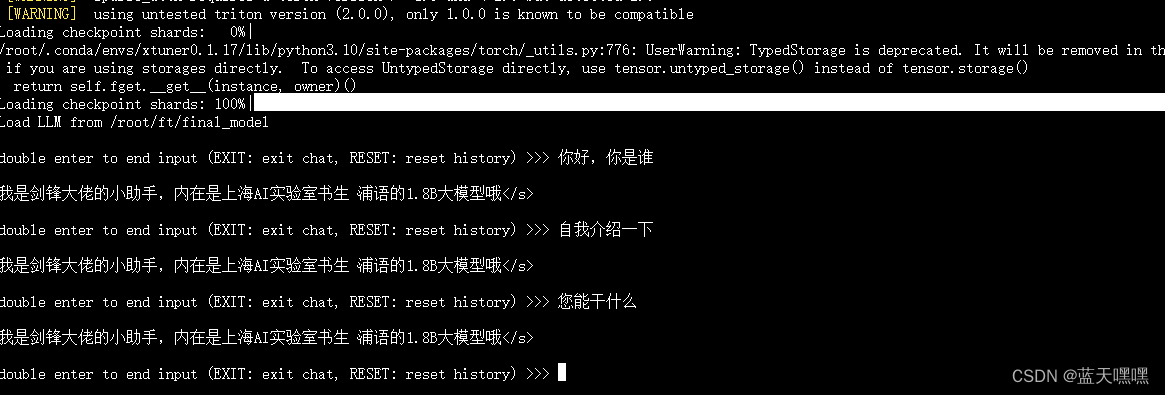 换原来的模型再测测看做对比,微调之前简直就是天才,
换原来的模型再测测看做对比,微调之前简直就是天才,

xtuner chat /root/ft/model --adapter /root/ft/huggingface --prompt-template internlm2_chat 将lora的adapter加载进原始模型进行测试,效果等同于记载整合后的模型,原始模型+adapter=整合后的模型,一样的傻

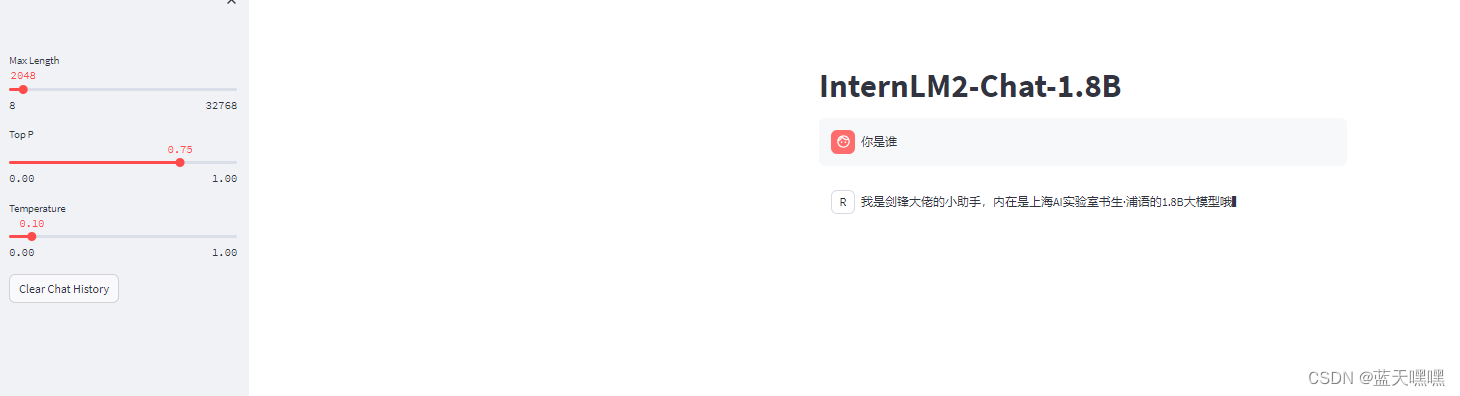
streamlit run web_demo.py --server.address=0.0.0.0 --server.port 7860 开启web端的测试,弱智依旧
-----------------------------------------
接下来做上传模型到openlab的操作,和huggingface的操作就非常大像了,这个搞熟练了,huggingface操作也差不太多,没想到卡在了模型文件上传的部分,总是中断,

测来测去,还是网络问题,这时候我才发现,其实我应该在书生的平台上直接传就好了,而我傻了吧唧的把模型文件下载到电脑上,再通过电脑上传,算了当测试windows客户端环境了,我也一怒之下换了手机热点上传,果然不断了,尴尬啊,反正流量足够,,,

不容易终于搞定,
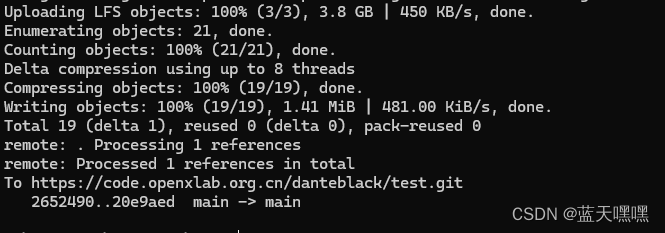
开始构建应用了,还是很慢,前面github更新代码同步到openxlab的步骤就省略了(这里很全面了Tutorial/tools/openxlab-deploy/README.md at camp2 · InternLM/Tutorial · GitHub)。

终于启动了,小傻子面世了!

和平台测试的模型一样,只能回答一句话,搞了两天终于把实验都搞定了。
慢着,才发现还有多模态的llava的微调差点忘记了,这次的实验作业内容真多啊!继续!
微调过程中显存不断攀升,

loss不断下降,

微调完成,先加载老模型看看,基本是小傻子,

再加载微调后的模型,聪明多了,实验终于做完了。
















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









