







2025 年 2 月 25 日晚上 11:00 通义万相 2.1 开源发布,前两周太忙没空搞它,这个周末,也来本地化部署一个,体验生成效果如何,总的来说,它在国内文生视频、图生视频的行列处于领先位置,同时也支持文生图。
一、开源代码下载来源
GitHub:https://github.com/Wan-Video/Wan2.1
这个源码包中可以做的事包括:
Wan2.1 Text-to-Video
Multi-GPU Inference code of the 14B and 1.3B models
Checkpoints of the 14B and 1.3B models
Gradio demo
ComfyUI integration
Diffusers integration
Diffusers + Multi-GPU Inference
Wan2.1 Image-to-Video
Multi-GPU Inference code of the 14B model
Checkpoints of the 14B model
Gradio demo
ComfyUI integration
Diffusers integration
Diffusers + Multi-GPU Inference
以下相关网址,有在线体验的,有可以下载配套模型的,也有可以下载源码的,根据需要自行选择,访问国外的网站请提前准备好科学上网。
官网:https://tongyi.aliyun.com/wanxiang/
博客:https://wanxai.com/
Modelscope:https://modelscope.cn/organization/Wan-AI
Hugging Face:https://huggingface.co/Wan-AI
二、下载python虚拟环境管理软件,安装较新版的python
下载地址:https://docs.conda.io/en/latest/miniconda.html

安装好后打开它,最好使用管理员模式打开。

依次敲入指令,创建并激活项目所需的虚拟环境。(关于conda的使用方法会单独出一篇教程,这里就不多解释了)
conda create --name Wan21 python=3.12.9

三、安装git

验证安装成功如下:

四、安装cuda
到官网CUDA Toolkit Archive | NVIDIA Developer 下载驱动,按提示安装。这里需要为自己的显卡选择具体的版本,命令行输入指令nvidia-smi查看对应版本。


下载后安装完配置一下环境变量
五、下载万象2.1源码
git clone https://github.com/Wan-Video/Wan2.1.git

六、安装万象2.1所需的依赖包
到conda的虚拟环境中来安装,给万象2.1配置专用的python运行环境。
conda activate Wan21

看看这个依赖源的清单,数量不多,建议还是手工一条条安装,以便看到哪一个在安装中出问题了,定向解决。

很多时候用上面的清单安装后,torch版本不支持cuda,可以参照下面这个网址,找到对应的版本去下载。
https://github.com/facebookresearch/xformers#installing-xformers

有时运行还会报错,缺少flash-attn依赖,可以根据对应的torch版本下载这个依赖包,不过编译的时间好长,只要不报错,一定要耐心等待,我可是等了半天多才完成编译。
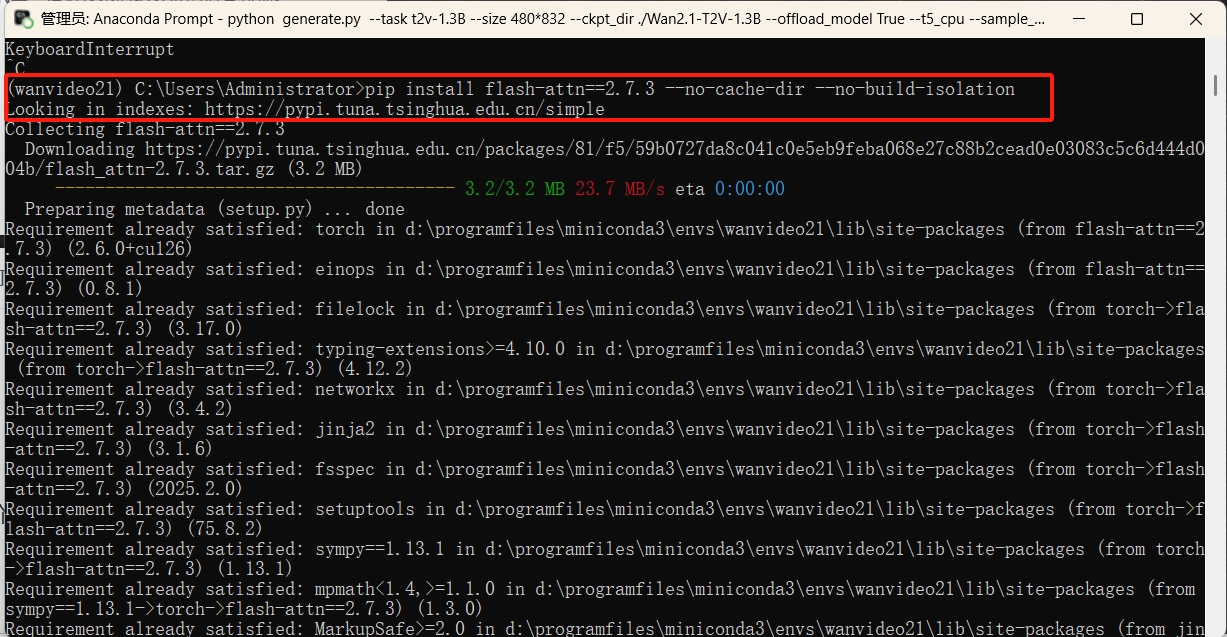
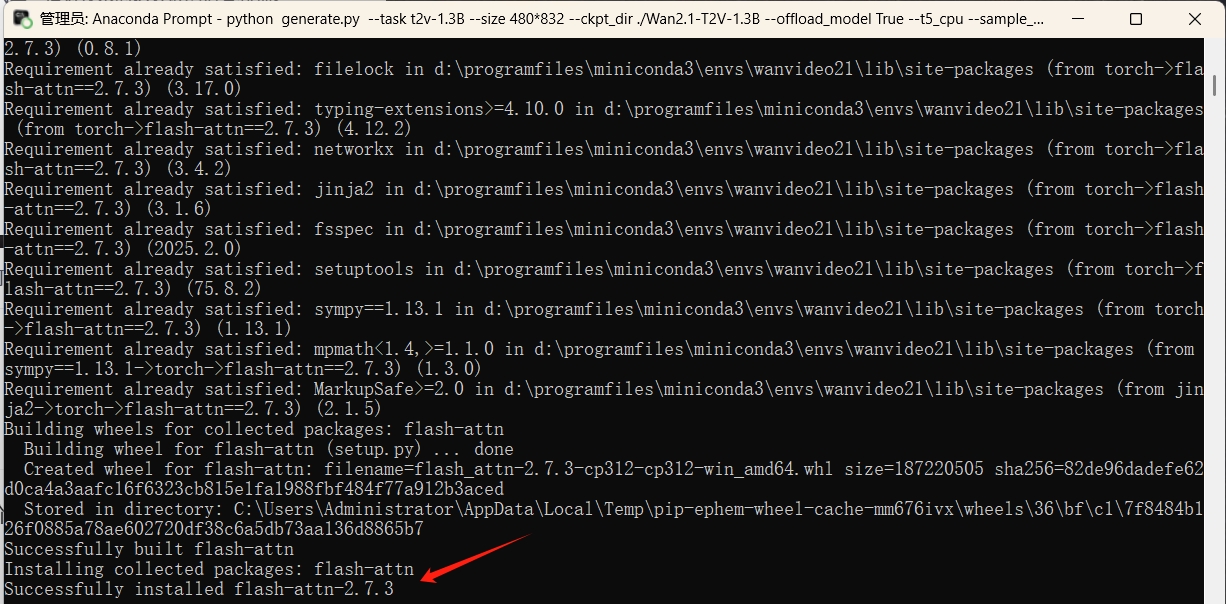
我最终的依赖包清单如下:
(wanvideo21) F:\GitProject\Wan2.1>pip list
Package Version
------------------ ------------
accelerate 1.4.0
aiofiles 23.2.1
aiohappyeyeballs 2.5.0
aiohttp 3.11.13
aiosignal 1.3.2
annotated-types 0.7.0
anyio 4.8.0
attrs 25.1.0
certifi 2025.1.31
charset-normalizer 3.4.1
click 8.1.8
colorama 0.4.6
dashscope 1.22.1
diffusers 0.32.2
easydict 1.13
einops 0.8.1
fastapi 0.115.11
ffmpy 0.5.0
filelock 3.17.0
flash_attn 2.7.3
frozenlist 1.5.0
fsspec 2025.2.0
ftfy 6.3.1
gradio 5.20.0
gradio_client 1.7.2
groovy 0.1.2
h11 0.14.0
httpcore 1.0.7
httpx 0.28.1
huggingface-hub 0.29.2
idna 3.10
imageio 2.37.0
imageio-ffmpeg 0.6.0
importlib_metadata 8.6.1
intel-openmp 2021.4.0
Jinja2 3.1.6
markdown-it-py 3.0.0
MarkupSafe 2.1.5
mdurl 0.1.2
mkl 2021.4.0
mpmath 1.3.0
multidict 6.1.0
networkx 3.4.2
numpy 1.26.0
opencv-python 4.11.0.86
orjson 3.10.15
packaging 24.2
pandas 2.2.3
pillow 11.1.0
pip 25.0.1
propcache 0.3.0
psutil 7.0.0
pydantic 2.10.6
pydantic_core 2.27.2
pydub 0.25.1
Pygments 2.19.1
python-dateutil 2.9.0.post0
python-multipart 0.0.20
pytz 2025.1
PyYAML 6.0.2
regex 2024.11.6
requests 2.32.3
rich 13.9.4
ruff 0.9.9
safehttpx 0.1.6
safetensors 0.5.3
semantic-version 2.10.0
setuptools 75.8.2
shellingham 1.5.4
six 1.17.0
sniffio 1.3.1
starlette 0.46.0
sympy 1.13.1
tbb 2021.11.0
tokenizers 0.21.0
tomlkit 0.13.2
torch 2.6.0+cu126
torchaudio 2.6.0+cu126
torchvision 0.21.0+cu126
tqdm 4.67.1
transformers 4.49.0
typer 0.15.2
typing_extensions 4.12.2
tzdata 2025.1
urllib3 2.3.0
uvicorn 0.34.0
wcwidth 0.2.13
websocket-client 1.8.0
websockets 15.0.1
wheel 0.45.1
yarl 1.18.3
zipp 3.21.0
七、下载模型文件
pip install "huggingface_hub[cli]"
huggingface-cli download Wan-AI/Wan2.1-T2V-14B --local-dir ./Wan2.1-T2V-14B
因为模型文件比较大,这个根据网速情况,会有些慢 。如果发现下载速度变慢了,可以ctrl+c终止后重新启动。
模型文件种类:

八、文生视频测试
单GPU情况下指令如下:
python generate.py --task t2v-14B --size 1280*720 --ckpt_dir ./Wan2.1-T2V-14B --save_file output --prompt "A cute little cat is cooking."
如果显存不够大,会报“Out-of-Memory”错误,可以使用参数--offload_model True and --t5_cpu启用cpu计算,同时改用小点的模型,使用低分辨率的像素来生成。

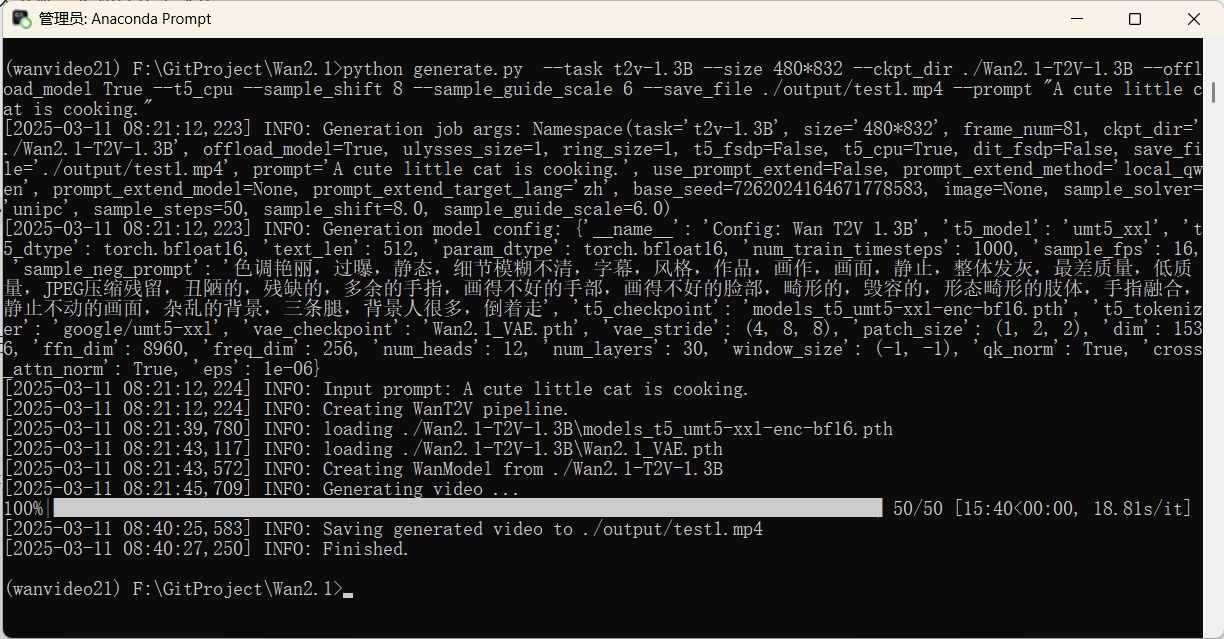
python generate.py --task t2v-1.3B --size 480*832 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --sample_shift 8 --sample_guide_scale 6 --save_file ./output/test1.mp4 --prompt "A cute little cat is cooking."

九、图生视频测试

单GPU情况下指令如下:
python generate.py --task t2v-1.3B --size 480*832 --ckpt_dir ./Wan2.1-T2V-1.3B --offload_model True --t5_cpu --image ./examples/test.jpg --save_file ./output/test2.mp4 --prompt "Summer beach vacation style, a white cat wearing sunglasses sits on a surfboard. The fluffy-furred feline gazes directly at the camera with a relaxed expression. Blurred beach scenery forms the background featuring crystal-clear waters, distant green hills, and a blue sky dotted with white clouds. The cat assumes a naturally relaxed posture, as if savoring the sea breeze and warm sunlight. A close-up shot highlights the feline's intricate details and the refreshing atmosphere of the seaside."

十、文生图片测试
python generate.py --task t2v-1.3B --size 480*832 --ckpt_dir ./Wan2.1-T2V-1.3B --prompt '一个漂亮的女孩' --offload_model True --t5_cpu
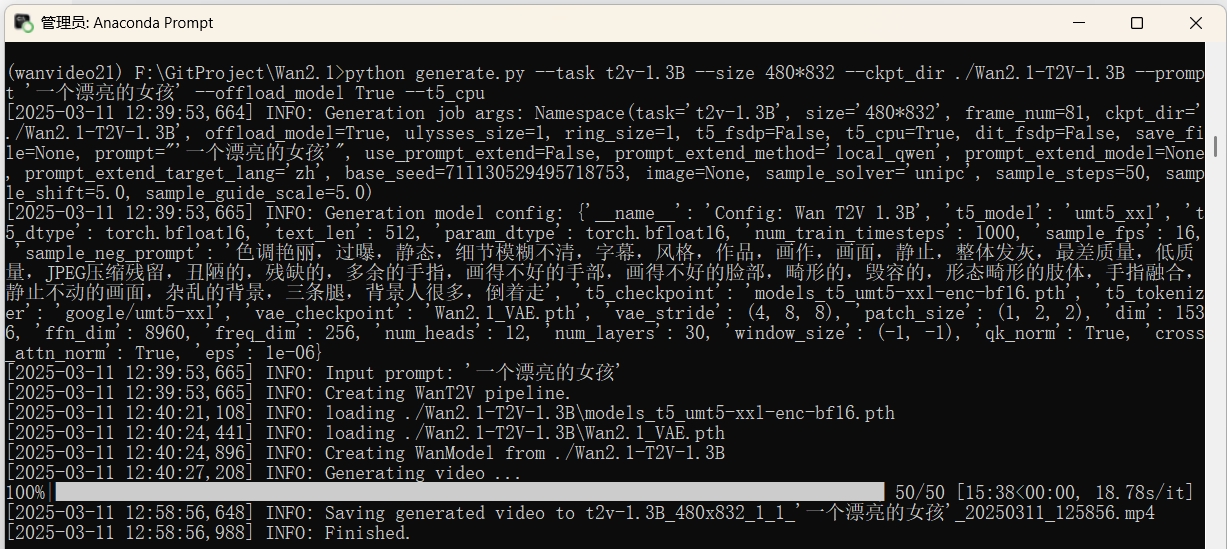

官方说是文生图,结果生成的还是视频。
想看指令可以带哪些参数,可以查看源码文件generate.py,其中片段如下:
def _parse_args():
parser = argparse.ArgumentParser(
description="Generate a image or video from a text prompt or image using Wan"
)
parser.add_argument(
"--task",
type=str,
default="t2v-14B",
choices=list(WAN_CONFIGS.keys()),
help="The task to run.")
parser.add_argument(
"--size",
type=str,
default="1280*720",
choices=list(SIZE_CONFIGS.keys()),
help="The area (width*height) of the generated video. For the I2V task, the aspect ratio of the output video will follow that of the input image."
)
parser.add_argument(
"--frame_num",
type=int,
default=None,
help="How many frames to sample from a image or video. The number should be 4n+1"
)
parser.add_argument(
"--ckpt_dir",
type=str,
default=None,
help="The path to the checkpoint directory.")
parser.add_argument(
"--offload_model",
type=str2bool,
default=None,
help="Whether to offload the model to CPU after each model forward, reducing GPU memory usage."
)
parser.add_argument(
"--ulysses_size",
type=int,
default=1,
help="The size of the ulysses parallelism in DiT.")
parser.add_argument(
"--ring_size",
type=int,
default=1,
help="The size of the ring attention parallelism in DiT.")
parser.add_argument(
"--t5_fsdp",
action="store_true",
default=False,
help="Whether to use FSDP for T5.")
parser.add_argument(
"--t5_cpu",
action="store_true",
default=False,
help="Whether to place T5 model on CPU.")
parser.add_argument(
"--dit_fsdp",
action="store_true",
default=False,
help="Whether to use FSDP for DiT.")
parser.add_argument(
"--save_file",
type=str,
default=None,
help="The file to save the generated image or video to.")
parser.add_argument(
"--prompt",
type=str,
default=None,
help="The prompt to generate the image or video from.")
parser.add_argument(
"--use_prompt_extend",
action="store_true",
default=False,
help="Whether to use prompt extend.")
parser.add_argument(
"--prompt_extend_method",
type=str,
default="local_qwen",
choices=["dashscope", "local_qwen"],
help="The prompt extend method to use.")
parser.add_argument(
"--prompt_extend_model",
type=str,
default=None,
help="The prompt extend model to use.")
parser.add_argument(
"--prompt_extend_target_lang",
type=str,
default="zh",
choices=["zh", "en"],
help="The target language of prompt extend.")
parser.add_argument(
"--base_seed",
type=int,
default=-1,
help="The seed to use for generating the image or video.")
parser.add_argument(
"--image",
type=str,
default=None,
help="The image to generate the video from.")
parser.add_argument(
"--sample_solver",
type=str,
default='unipc',
choices=['unipc', 'dpm++'],
help="The solver used to sample.")
parser.add_argument(
"--sample_steps", type=int, default=None, help="The sampling steps.")
parser.add_argument(
"--sample_shift",
type=float,
default=None,
help="Sampling shift factor for flow matching schedulers.")
parser.add_argument(
"--sample_guide_scale",
type=float,
default=5.0,
help="Classifier free guidance scale.")
args = parser.parse_args()
_validate_args(args)
return args体验感受:总的来说万象生成的视频质量还是不错的,最大的亮点是它原生支持中文提示词,对大部分的同胞们来说这是个福音。只不过这玩意太耗显存,看下面官方给出的测试报告就知道了,起步是4090,也进一步验证了智能时代拼的是算力。



















 2094
2094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











