






一、环境部署流程
步骤一:云平台注册与实例配置
-
注册星海智算
访问星海智算官网,完成企业/个人账号注册,新用户可领取免费算力包。 -
创建GPU实例
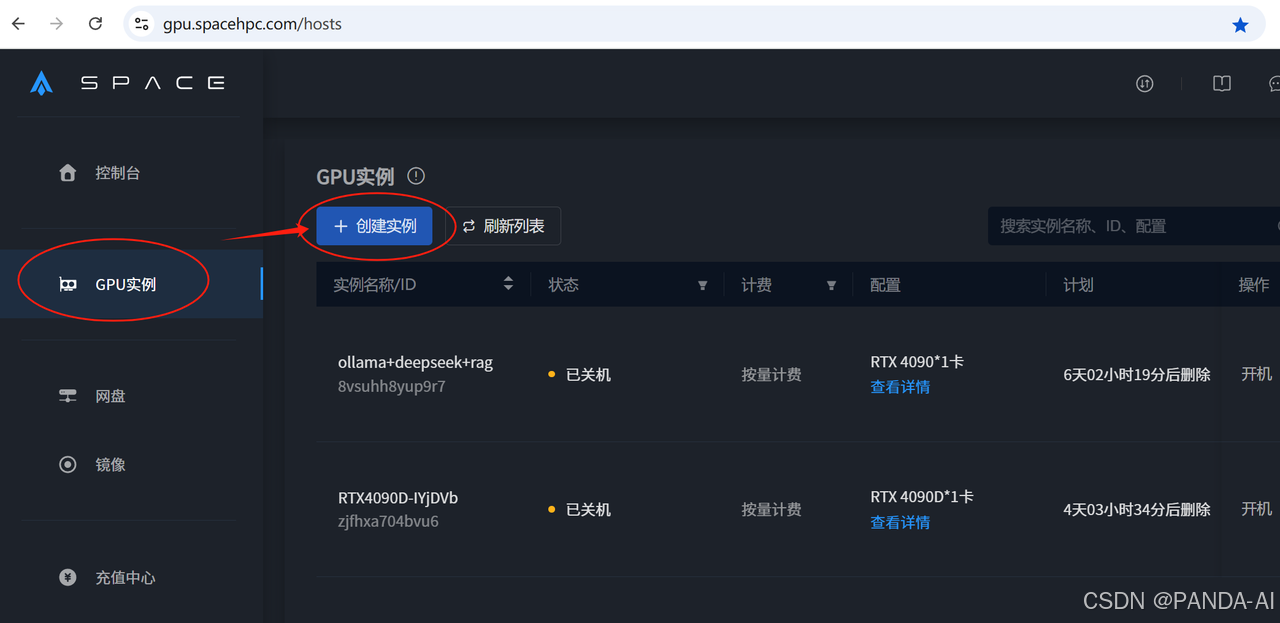
- 硬件选择:需至少24GB显存,推荐NVIDIA RTX 4090/4090D
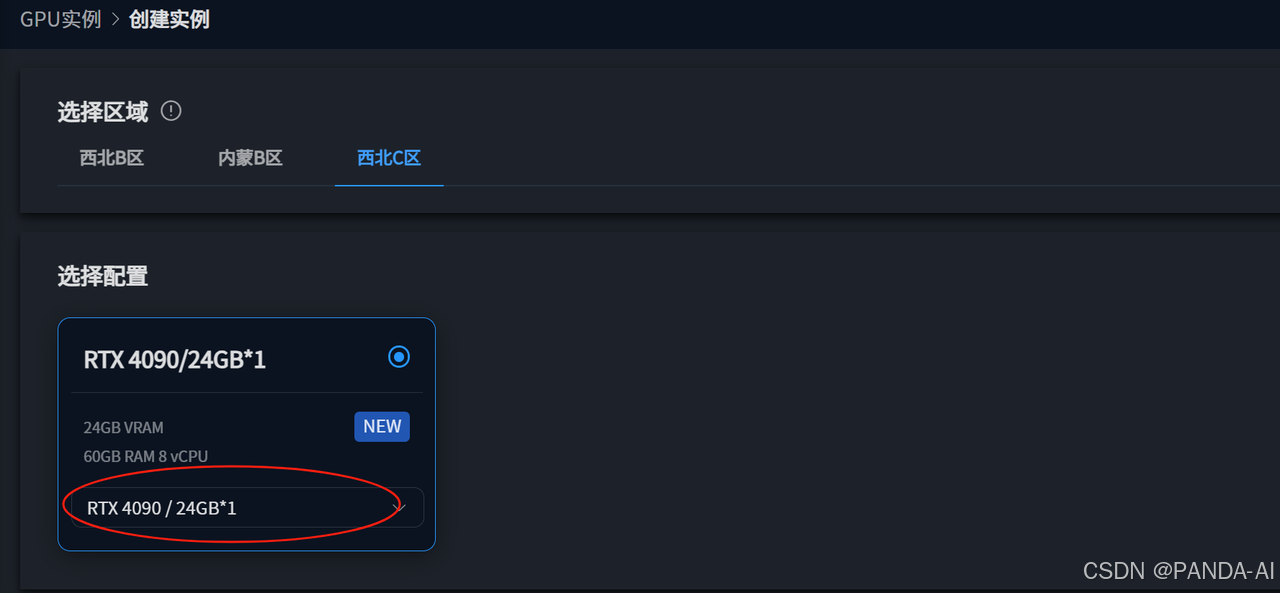
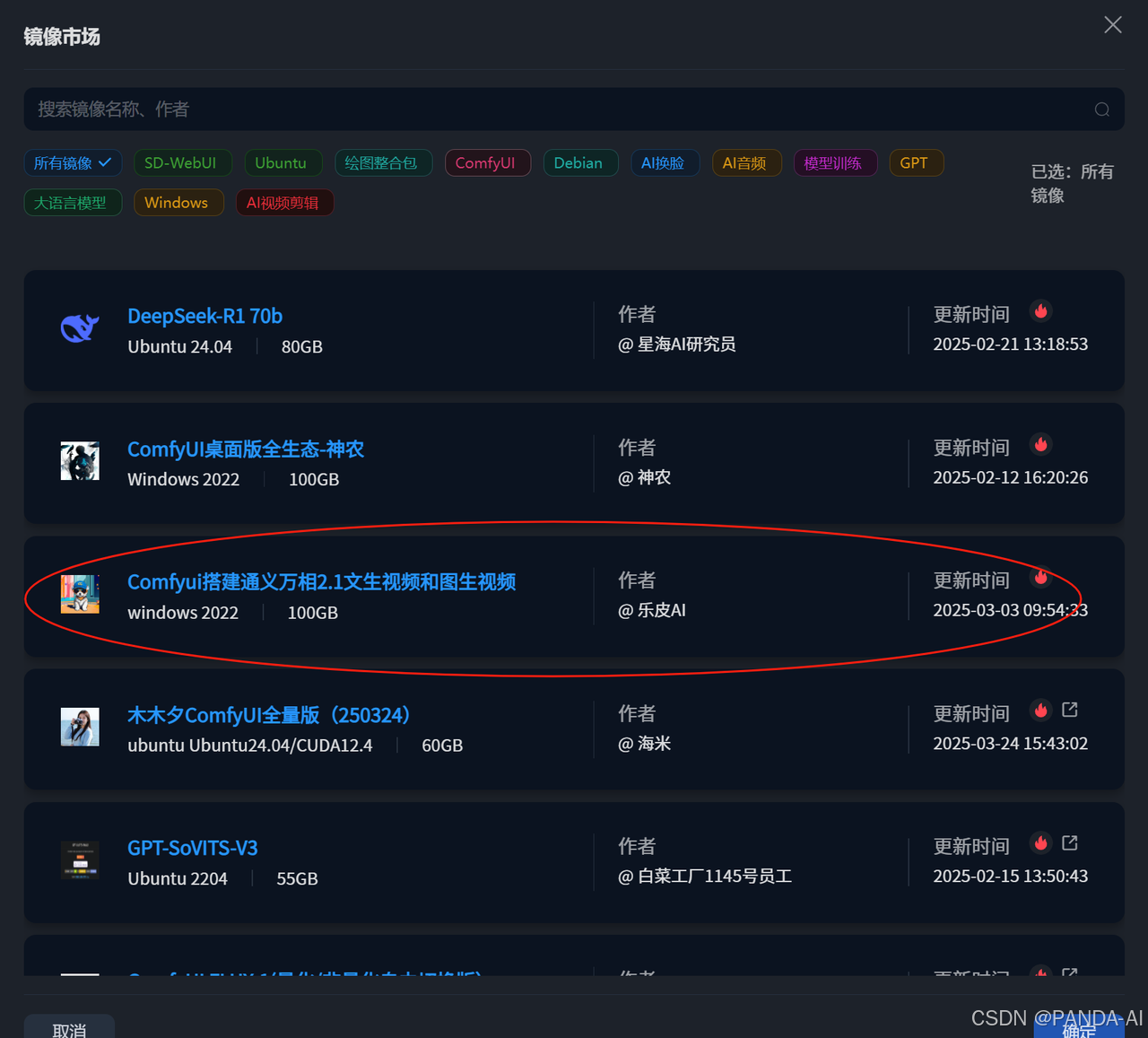
- 基础镜像:选择镜像-Comfyui搭建通义万相2.1文生视频和图生视频
- 存储空间:系统盘建议扩展至50GB(后续模型加载需额外空间)
- 网络配置:默认开放22/3389端口(支持SSH与远程桌面)
步骤二:启动与连接实例
-
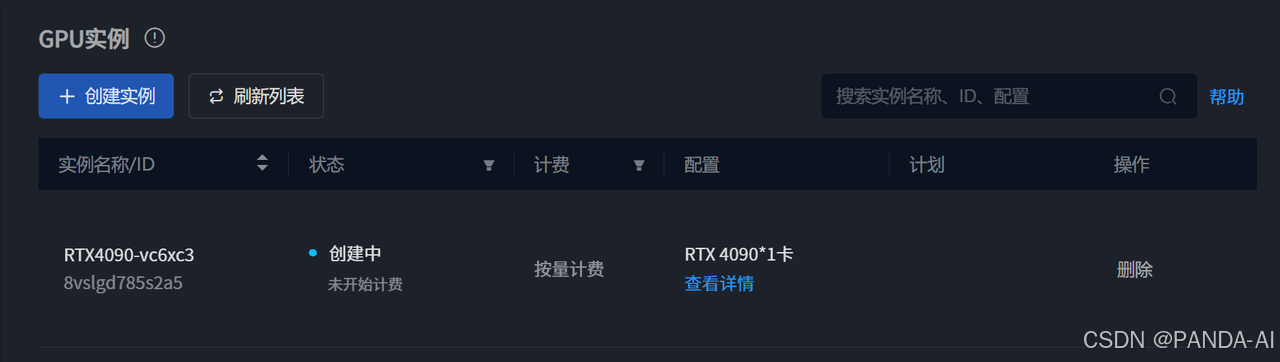
创建完成后等待3-5分钟初始化
-
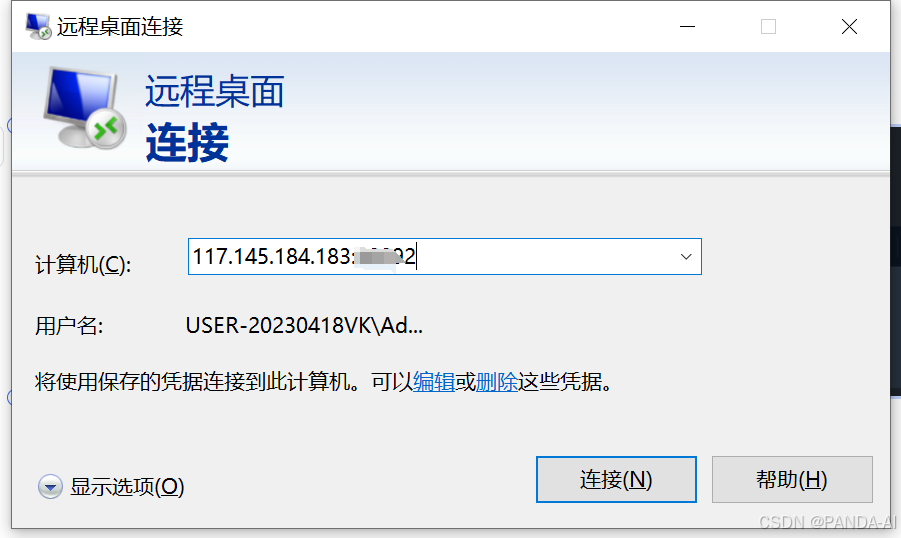
获取连接凭证:
-
Windows:使用远程桌面连接(IP+端口+密码)

-
-
Mac/Linux:通过SSH或VNC工具接入
-
-
首次登录建议重置密码(控制台支持密钥对管理)
二、ComfyUI工作流操作指南
步骤三:启动服务
-
进入远程桌面后,双击运行桌面【ComfyUI】快捷方式
-
服务启动约需2分钟,成功后会自动跳转至本地浏览器

步骤四:图生视频核心配置
-
加载工作流
点击右上角「Workflows」图标,选择「Image-to-Video」预设模板
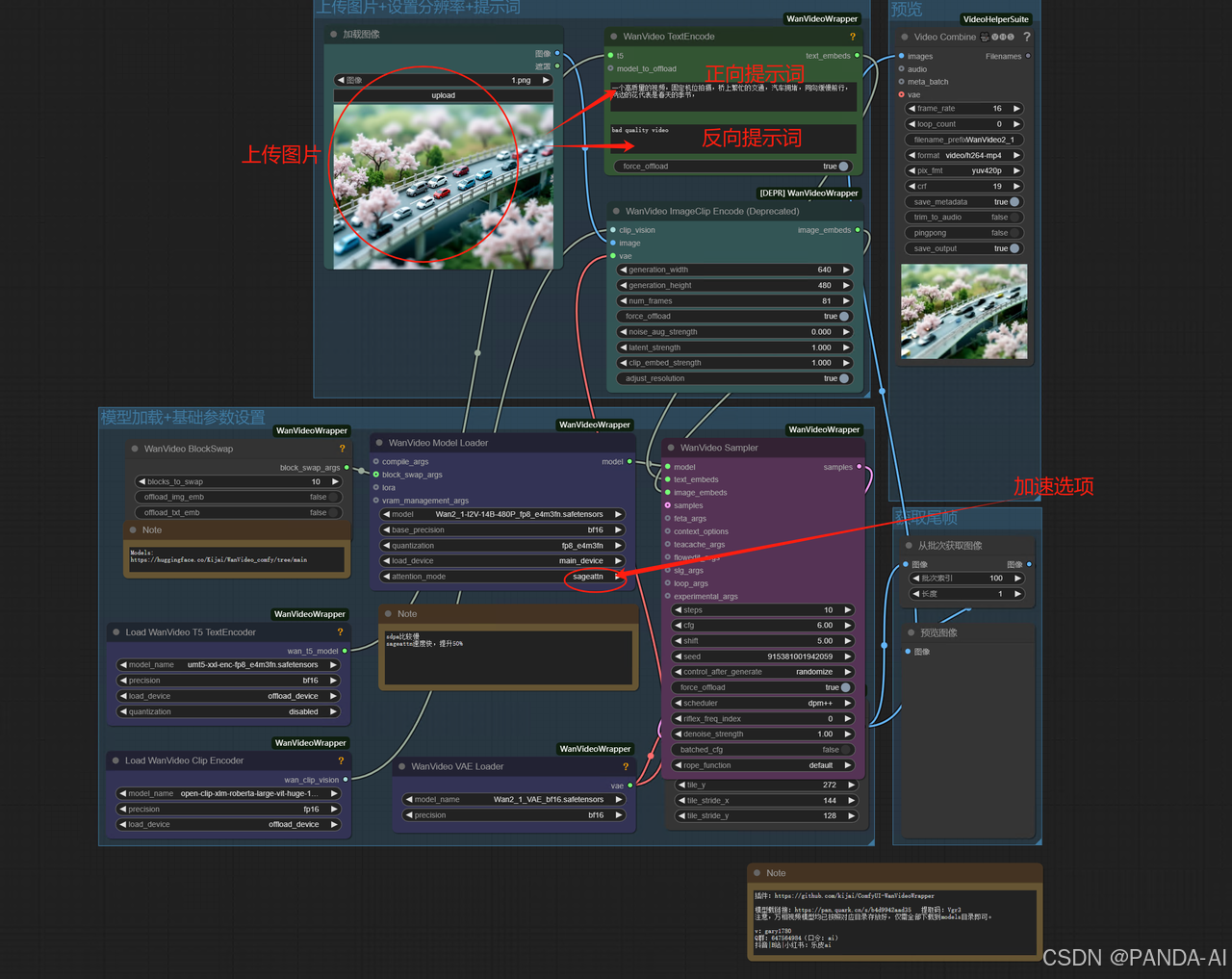
2.参数设置
-
输入图像:支持PNG/JPG格式(建议分辨率≥512x512)
-
模型选择:必须指定为
wanx2.1-img2vid(预装路径:models/diffusion_models) -
提示词规范:
-
正向提示词:描述动态元素(如"风吹动树叶,湖面波纹扩散")
-
负向提示词:建议填写"低质量,模糊,畸变"
-
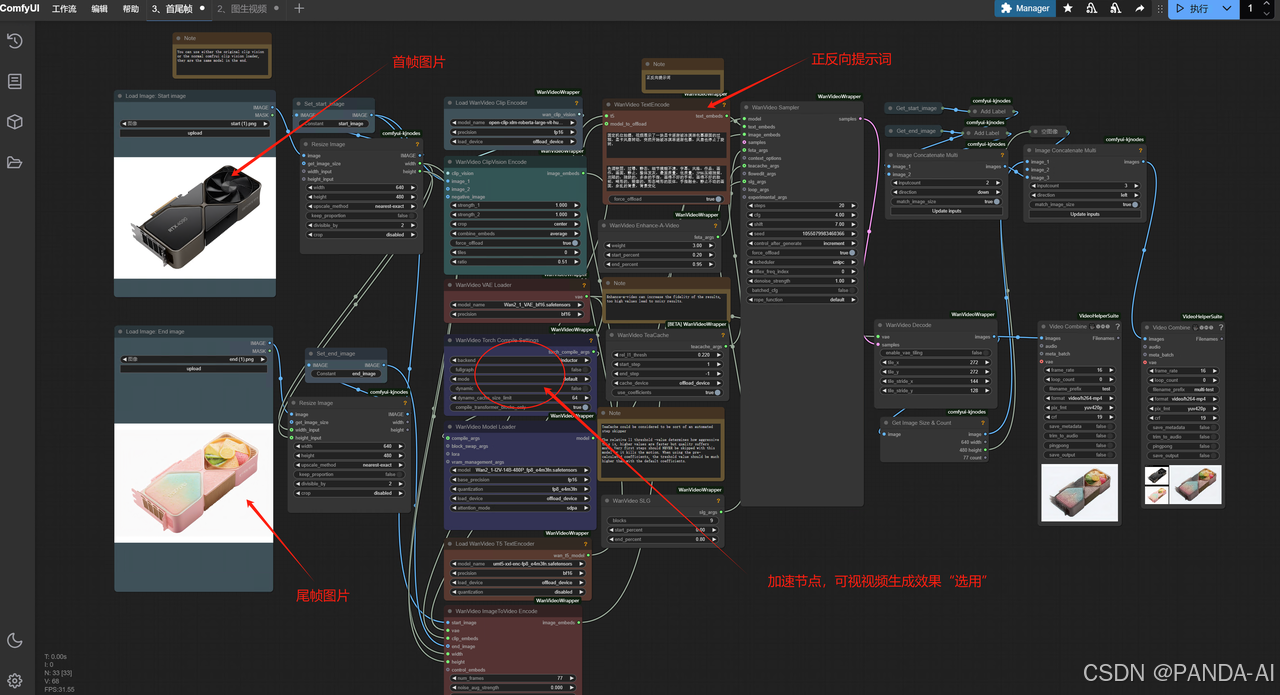
3. 首尾帧控制(进阶)
-
首帧提示词:定义初始画面状态
-
尾帧提示词:描述目标运动效果
-
插帧参数:建议设置帧率≥24fps,插值步数20-30
三、性能优化与注意事项
1. 存储扩展方案
-
问题:基础镜像仅预装图生视频模型(约12GB),需扩展存储以加载完整模型库
-
解决方案:
-
在星海智算控制台扩容系统盘至≥50GB
-
从公共存储区复制
wanx2.1_full模型包至models/diffusion_models目录
-
2. 显存管理策略
-
资源占用:
分辨率 显存消耗(4090) 建议批大小 512x512 18-22GB 1 768x768 23-24GB 1 -
优化建议:
-
使用FP8量化模型(性能损失<5%,显存节省30%)
-
启用
--low-vram模式运行ComfyUI
-
3. 平台技术优势
选择星海智算的核心理由:
-
成本优势:4090实例单价较市场均价低26%(实测¥1.78/小时)
-
部署效率:预置环境免除CUDA/驱动适配问题
-
稳定性:提供7×24小时在线技术支持与自动快照备份
四、常见问题解答
Q1:运行时报错CUDA out of memory
-
检查显存占用:使用
nvidia-smi命令监控 -
降低分辨率或减少批处理数量
Q2:生成视频出现画面闪烁
-
增加运动一致性参数(建议值:
motion_scale=0.8-1.2) -
延长插值步数至≥25步

















 4217
4217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









